Hugo Musso Gualandi the Pallene Programming Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CST8207 – Linux O/S I
Mounting a Filesystem Directory Structure Fstab Mount command CST8207 - Algonquin College 2 Chapter 12: page 467 - 496 CST8207 - Algonquin College 3 The mount utility connects filesystems to the Linux directory hierarchy. The mount point is a directory in the local filesystem where you can access mounted filesystem. This directory must exist before you can mount a filesystem. All filesystems visible on the system exist as a mounted filesystem someplace below the root (/) directory CST8207 - Algonquin College 4 can be mounted manually ◦ can be listed in /etc/fstab, but not necessary ◦ all mounting information supplied manually at command line by user or administrator can be mounted automatically on startup ◦ must be listed /etc/fstab, with all appropriate information and options required Every filesystem, drive, storage device is listed as a mounted filesystem associated to a directory someplace under the root (/) directory CST8207 - Algonquin College 5 CST8207 - Algonquin College 6 Benefits Scalable ◦ As new drives are added and new partitions are created, further filesystems can be mounted at various mount points as required. ◦ This means a Linux system does not need to worry about running out of disk space. Transparent ◦ No application would stop working if transferred to a different partition, because access to data is done via the mount point. ◦ Also transparent to user CST8207 - Algonquin College 7 All known filesystems volumes are typically listed in the /etc/fstab (static information about filesystem) file to help automate the mounting process If it is not listed in the /etc/fstab file, then all appropriate information about the filesystem needs to be listed manually at the command line. -

File System, Files, and *Tab /Etc/Fstab
File system, files, and *tab File system files directories volumes, file systems mounting points local versus networked file systems 1 /etc/fstab Specifies what is to be mounted where and how fs_spec: describes block special device for remote filesystem to be mounted fs_file: describes the mount point fs_vfstype: describes the type of file system fs_mntops: describes the mount options associated with the filesystem 2 /etc/fstab cont. fs_freq: used by the dump command fs_passno: used by fsck to determine the order in which checks are done at boot time. Root file systems should be specified as 1, others should be 2. Value 0 means that file system does not need to be checked 3 /etc/fstab 4 from blocks to mounting points metadata inodes directories superblocks 5 mounting file systems mounting e.g., mount -a unmounting manually or during shutdown umount 6 /etc/mtab see what is mounted 7 Network File System Access file system (FS) over a network looks like a local file system to user e.g. mount user FS rather than duplicating it (which would be a disaster) Developed by Sun Microsystems (mid 80s) history for NFS: NFS, NFSv2, NFSv3, NFSv4 RFC 3530 (from 2003) take a look to see what these RFCs are like!) 8 Network File System How does this actually work? server needs to export the system client needs to mount the system server: /etc/exports file client: /etc/fstab file 9 Network File System Security concerns UID GID What problems could arise? 10 Network File System example from our raid system (what is a RAID again?) Example of exports file from -

Dynamic Extension of Typed Functional Languages
Dynamic Extension of Typed Functional Languages Don Stewart PhD Dissertation School of Computer Science and Engineering University of New South Wales 2010 Supervisor: Assoc. Prof. Manuel M. T. Chakravarty Co-supervisor: Dr. Gabriele Keller Abstract We present a solution to the problem of dynamic extension in statically typed functional languages with type erasure. The presented solution re- tains the benefits of static checking, including type safety, aggressive op- timizations, and native code compilation of components, while allowing extensibility of programs at runtime. Our approach is based on a framework for dynamic extension in a stat- ically typed setting, combining dynamic linking, runtime type checking, first class modules and code hot swapping. We show that this framework is sufficient to allow a broad class of dynamic extension capabilities in any statically typed functional language with type erasure semantics. Uniquely, we employ the full compile-time type system to perform run- time type checking of dynamic components, and emphasize the use of na- tive code extension to ensure that the performance benefits of static typing are retained in a dynamic environment. We also develop the concept of fully dynamic software architectures, where the static core is minimal and all code is hot swappable. Benefits of the approach include hot swappable code and sophisticated application extension via embedded domain specific languages. We instantiate the concepts of the framework via a full implementation in the Haskell programming language: providing rich mechanisms for dy- namic linking, loading, hot swapping, and runtime type checking in Haskell for the first time. We demonstrate the feasibility of this architecture through a number of novel applications: an extensible text editor; a plugin-based network chat bot; a simulator for polymer chemistry; and xmonad, an ex- tensible window manager. -

Filesystem Considerations for Embedded Devices ELC2015 03/25/15
Filesystem considerations for embedded devices ELC2015 03/25/15 Tristan Lelong Senior embedded software engineer Filesystem considerations ABSTRACT The goal of this presentation is to answer a question asked by several customers: which filesystem should you use within your embedded design’s eMMC/SDCard? These storage devices use a standard block interface, compatible with traditional filesystems, but constraints are not those of desktop PC environments. EXT2/3/4, BTRFS, F2FS are the first of many solutions which come to mind, but how do they all compare? Typical queries include performance, longevity, tools availability, support, and power loss robustness. This presentation will not dive into implementation details but will instead summarize provided answers with the help of various figures and meaningful test results. 2 TABLE OF CONTENTS 1. Introduction 2. Block devices 3. Available filesystems 4. Performances 5. Tools 6. Reliability 7. Conclusion Filesystem considerations ABOUT THE AUTHOR • Tristan Lelong • Embedded software engineer @ Adeneo Embedded • French, living in the Pacific northwest • Embedded software, free software, and Linux kernel enthusiast. 4 Introduction Filesystem considerations Introduction INTRODUCTION More and more embedded designs rely on smart memory chips rather than bare NAND or NOR. This presentation will start by describing: • Some context to help understand the differences between NAND and MMC • Some typical requirements found in embedded devices designs • Potential filesystems to use on MMC devices 6 Filesystem considerations Introduction INTRODUCTION Focus will then move to block filesystems. How they are supported, what feature do they advertise. To help understand how they compare, we will present some benchmarks and comparisons regarding: • Tools • Reliability • Performances 7 Block devices Filesystem considerations Block devices MMC, EMMC, SD CARD Vocabulary: • MMC: MultiMediaCard is a memory card unveiled in 1997 by SanDisk and Siemens based on NAND flash memory. -

Mv-Ch650-90Tm
MV-CH650-90TM 65 MP CMOS 10 GigE Area Scan Camera Introduction Available Model MV-CH650-90TM camera adopts Gpixel GMAX3265 sensor to M58-mount with fan, mono: MV-CH650- provide high-quality image. It uses 10 GigE interface to transmit 90TM-M58S-NF non-compressed image in real time, and its max. frame rate can F-mount with fan, mono: MV-CH650-90TM- reach 15.5 fps in full resolution. F-NF Key Feature Applicable Industry Resolution of 9344 × 7000, and pixel size of 3.2 μm × 3.2 μm. PCB AOI, FPD, railway related applications, etc. Adopts 10 GigE interface providing max. transmission Sensor Quantum Efficiency distance of 100 meters without relay. Supports auto or manual adjustment for gain, exposure time, and manual adjustment for Look-Up Table (LUT), Gamma correction, etc. Compatible with GigE Vision Protocol V2.0, GenlCam Standard, and third-party software based on protocols. Dimension M58-mount with fan: F-mount with fan: Specification Model MV-CH650-90TM Camera Sensor type CMOS, global shutter Sensor model Gpixel GMAX3265 Pixel size 3.2 µm × 3.2 µm Sensor size 29.9 mm × 22.4 mm Resolution 9344 × 7000 Max. frame rate 15.5 fps @9344 × 7000 Dynamic range 66 dB SNR 40 dB Gain 1.25X to 6X Exposure time 15 μs to 10 sec Exposure mode Off/Once/Continuous exposure mode Mono/color Mono Pixel format Mono 8/10/10p/12/12p Binning Supports 1 × 1, 1 × 2, 1 × 4, 2 × 1, 2 × 2, 2 × 4, 4 × 1, 4 × 2, 4 × 4 Decimation Supports 1 × 1, 1 × 2, 1 × 4, 2 × 1, 2 × 2, 2 × 4, 4 × 1, 4 × 2, 4 × 4 Reverse image Supports horizontal and vertical reverse image output Electrical features Data interface 10 Gigabit Ethernet, compatible with Gigabit Ethernet Digital I/O 12-pin Hirose connector provides power and I/O, including opto-isolated input × 1 (Line 0), opto-isolated output × 1 (Line 1), bi-directional non-isolated I/O × 1 (Line 2), and RS-232 × 1 Power supply 9 VDC to 24 VDC Power consumption Typ. -
![How to Setup NFS File System Guide ID: 3 - Release: Initial Revision [Major] 2015-08-14](https://docslib.b-cdn.net/cover/5995/how-to-setup-nfs-file-system-guide-id-3-release-initial-revision-major-2015-08-14-825995.webp)
How to Setup NFS File System Guide ID: 3 - Release: Initial Revision [Major] 2015-08-14
How to setup NFS file system Guide ID: 3 - Release: Initial revision [major] 2015-08-14 How to setup NFS file system Configuration of SCO Unix shared drive in order to share printer tasks. Written By: Petr Roupec This document was generated on 2020-11-19 05:38:51 AM (MST). © 2020 omlex.dozuki.com/ Page 1 of 7 How to setup NFS file system Guide ID: 3 - Release: Initial revision [major] 2015-08-14 INTRODUCTION This guide is describing use of SCO scoadmin program to setup mount /volumes/bmprint remote drive on your OT computer. This document was generated on 2020-11-19 05:38:51 AM (MST). © 2020 omlex.dozuki.com/ Page 2 of 7 How to setup NFS file system Guide ID: 3 - Release: Initial revision [major] 2015-08-14 Step 1 — SCO Admin - Starting program Switch user on local console. Please note character "-" on command line - this load right environment for root user From remote computer use telnet connection Start scoadmin program This document was generated on 2020-11-19 05:38:51 AM (MST). © 2020 omlex.dozuki.com/ Page 3 of 7 How to setup NFS file system Guide ID: 3 - Release: Initial revision [major] 2015-08-14 Step 2 — SCO Admin - File System Manager SCO Admin - File Manager Select FileSystems Open Filesystem Manager Use TAB and arrows on your keyboard to move between the fields This document was generated on 2020-11-19 05:38:51 AM (MST). © 2020 omlex.dozuki.com/ Page 4 of 7 How to setup NFS file system Guide ID: 3 - Release: Initial revision [major] 2015-08-14 Step 3 — Start NFS file system mounting wizard Select Mount from menu Scroll down and select "Add Mount Configuration" Choose remote Use TAB and arrows on your keyboard to move between the fields Step 4 — NFS Share - Configuration details Enter IP address of your printer server Enter name of remote directory of your print server Enter name of local directory on computer you are configuring Don't forget Advanced Mount Option - Failure to configure these correctly might stop your server in case of printer server shutdown This document was generated on 2020-11-19 05:38:51 AM (MST). -

UNIX (Solaris/Linux) Quick Reference Card Logging in Directory Commands at the Login: Prompt, Enter Your Username
UNIX (Solaris/Linux) QUICK REFERENCE CARD Logging In Directory Commands At the Login: prompt, enter your username. At the Password: prompt, enter ls Lists files in current directory your system password. Linux is case-sensitive, so enter upper and lower case ls -l Long listing of files letters as required for your username, password and commands. ls -a List all files, including hidden files ls -lat Long listing of all files sorted by last Exiting or Logging Out modification time. ls wcp List all files matching the wildcard Enter logout and press <Enter> or type <Ctrl>-D. pattern Changing your Password ls dn List files in the directory dn tree List files in tree format Type passwd at the command prompt. Type in your old password, then your new cd dn Change current directory to dn password, then re-enter your new password for verification. If the new password cd pub Changes to subdirectory “pub” is verified, your password will be changed. Many systems age passwords; this cd .. Changes to next higher level directory forces users to change their passwords at predetermined intervals. (previous directory) cd / Changes to the root directory Changing your MS Network Password cd Changes to the users home directory cd /usr/xx Changes to the subdirectory “xx” in the Some servers maintain a second password exclusively for use with Microsoft windows directory “usr” networking, allowing you to mount your home directory as a Network Drive. mkdir dn Makes a new directory named dn Type smbpasswd at the command prompt. Type in your old SMB passwword, rmdir dn Removes the directory dn (the then your new password, then re-enter your new password for verification. -

Regent: a High-Productivity Programming Language for Implicit Parallelism with Logical Regions
REGENT: A HIGH-PRODUCTIVITY PROGRAMMING LANGUAGE FOR IMPLICIT PARALLELISM WITH LOGICAL REGIONS A DISSERTATION SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE AND THE COMMITTEE ON GRADUATE STUDIES OF STANFORD UNIVERSITY IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY Elliott Slaughter August 2017 © 2017 by Elliott David Slaughter. All Rights Reserved. Re-distributed by Stanford University under license with the author. This work is licensed under a Creative Commons Attribution- Noncommercial 3.0 United States License. http://creativecommons.org/licenses/by-nc/3.0/us/ This dissertation is online at: http://purl.stanford.edu/mw768zz0480 ii I certify that I have read this dissertation and that, in my opinion, it is fully adequate in scope and quality as a dissertation for the degree of Doctor of Philosophy. Alex Aiken, Primary Adviser I certify that I have read this dissertation and that, in my opinion, it is fully adequate in scope and quality as a dissertation for the degree of Doctor of Philosophy. Philip Levis I certify that I have read this dissertation and that, in my opinion, it is fully adequate in scope and quality as a dissertation for the degree of Doctor of Philosophy. Oyekunle Olukotun Approved for the Stanford University Committee on Graduate Studies. Patricia J. Gumport, Vice Provost for Graduate Education This signature page was generated electronically upon submission of this dissertation in electronic format. An original signed hard copy of the signature page is on file in University Archives. iii Abstract Modern supercomputers are dominated by distributed-memory machines. State of the art high-performance scientific applications targeting these machines are typically written in low-level, explicitly parallel programming models that enable maximal performance but expose the user to programming hazards such as data races and deadlocks. -
TS ODBC Dataserver Quick Start
TS ODBC DataServerTM Quick Start Multiple-Tier Introduction This Multiple-Tier product includes 3 components. Follow the instructions below for each Windows workstation and DataServer Host component. Multiple-Tier components can be found by platform in a folder on the TS ODBC DataServer CD-ROM. Use these instructions for the TS ODBC Gateway for Windows version of the Multiple-Tier software. TS ODBC DataServer Server UNIX Server Install the Server on your UNIX Host system from cpio distribution media. This installation is required only once no matter how many workstations are connected. Logon as root. 1. Create and change (cd) to a base directory for the TS ODBC DataServer (For example, /usr/local/tsodbc). 2. Copy the distribution media to the system using cpio. (See Mounting UNIX CD-ROM devices on the reverse.) This example is for Linux (kernel 2.6.16+). Substitute the appropriate values for your environment. umask 0 cpio -icvBmud </mountpoint/linux2616/tsod_srv/tsod (for Linux use –ivBmud above) 3. Execute the install script. ./install 4. Activate the server (Refer to the Installation and Activation Guide). Windows Server Before continuing, review the updated installation instructions provided in the installation manual. NOTE: All Thoroughbred Windows based products prior to Version 8.7.0 must first be uninstalled and then the 8.7.1 release installed. Only 8.7.0 can be upgraded to 8.7.1 and only 8.7.0 and 8.7.1 can co-exist on the same system. If you are upgrading a pre 8.7.0 release, BEFORE continuing with this installation, please see the TS ODBC Installation and Activation Guide for complete instructions to properly prepare your system for 8.7.1. -
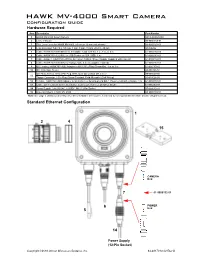
HAWK MV-4000 Configuration Guide Ethernet Configuration with Flying Leads
HAWK MV-4000 Smart Camera Configuration Guide Hardware Required Item Description Part Number 1 HAWK MV-4000 Smart Camera 8X1X-XXX0-010X 2 Lens, C-Mount 98-90001XX-01 3 IP67 Lens Cover for HAWK MV-4000, 50 mm or 70 mm (not shown) 98-900015X-01 4 Lens Extension Tube Set, 0.5 mm, 1 mm, 5 mm, 10 mm, 20 mm, 40 mm 98-CO206 5 Cable, HAWK MV-4000 Ethernet, X-CODE / RJ45 CAT 6A, 1 m, 3 m, or 5 m 61-9000134-0X 6 Cable, HAWK MV-4000 M12 to USB Socket or VGA / USB, 1 m 61-900014X-01 7 Cable, Adapter, HAWK MV-4000 to Accessory Cables / Power Supply (supplied with camera) 61-9000132-01 8 Cable, HAWK MV-4000 M12 to Flying Leads, 3 m (no adapter required) 61-9000151-01 9 QX Cordset, HAWK MV-4000 Adapter to QX-1 M12 Plug (Screw-On), 1 m or 3 m 61-0001XX-02 10 QX-1 Interface Device 98-000103-02 QX Photo Sensor, M12 4-Pin Plug, NPN, Dark On or Dark Off, 2 m or 99-000020-0X 11 Trigger Connector, 4-Pin Plug (Screw Terminal, Field-Wireable) (Self-Wiring) 20-610024-01 12 Y Cable, HAWK MV-4000 Adapter to Smart Series Illuminator and QX-1, Power or On/Off or Strobe, 1 m 61-900013X-01 13 Cable, QX-1 to Smart Series Illuminator, Continuous Power or On/Off or Strobe 61-0002XX-01 14 Power Supply, 100-240VAC, +24VDC, M12 12-Pin Socket 97-000012-01 15 Universal Mount, HAWK MV-4000 98-9000209-01 Note: See page 5 of this document for a full list of available accessories, numbered to correspond with this table and the diagrams below. -

Exercise University of Oklahoma, May 13Th – 17Th 2019 J.D
Linux Clusters Institute: Lustre Hands On Exercise University of Oklahoma, May 13th – 17th 2019 J.D. Maloney | Storage Engineer National Center for Supercomputing Applications (NCSA) [email protected] This document is a result of work by volunteer LCI instructors and is licensed under CC BY-NC 4.0 (https://creativecommons.org/licenses/by-nc/4.0/). Goal of Hands on Exercise • Create Lustre File System with 1 MDT & 6 OSTs • Bring in Sample Data • Configure Quotas • Test how stripe width works May 13th-17th 2019 2 Lay of the Land • You should have 4 storage servers; 1 for metadata, 3 for data • Each have 2 5GB volumes • Root SSH between all nodes in cluster • Chronyd keeping time in sync May 13th-17th 2019 3 Creating Lustre File System • Add Lustre Repos to Servers & Compute Nodes (create /etc/yum.repos.d/lustre.repo) [lustre-server] name=CentOS-$releasever - Lustre baseurl=https://downloads.hpdd.intel.com/public/lustre/latest-feature-release/el7/server/ gpgcheck=0 [e2fsprogs] name=CentOS-$releasever - Ldiskfs baseurl=https://downloads.hpdd.intel.com/public/e2fsprogs/latest/el7/ gpgcheck=0 [lustre-client] name=CentOS-$releasever - Lustre baseurl=https://downloads.hpdd.intel.com/public/lustre/latest-feature-release/el7/client/ gpgcheck=0 May 13th-17th 2019 4 Creating Lustre File System • Update/Install these packages on the four storage nodes yum upgrade -y e2fsprogs yum install -y lustre-tests • Create /etc/modprobe.d/lnet.conf and add the following on all four storage nodes options lnet networks=tcp0(eth0) • Reboot all four storage -

C Programming Tutorial
C Programming Tutorial C PROGRAMMING TUTORIAL Simply Easy Learning by tutorialspoint.com tutorialspoint.com i COPYRIGHT & DISCLAIMER NOTICE All the content and graphics on this tutorial are the property of tutorialspoint.com. Any content from tutorialspoint.com or this tutorial may not be redistributed or reproduced in any way, shape, or form without the written permission of tutorialspoint.com. Failure to do so is a violation of copyright laws. This tutorial may contain inaccuracies or errors and tutorialspoint provides no guarantee regarding the accuracy of the site or its contents including this tutorial. If you discover that the tutorialspoint.com site or this tutorial content contains some errors, please contact us at [email protected] ii Table of Contents C Language Overview .............................................................. 1 Facts about C ............................................................................................... 1 Why to use C ? ............................................................................................. 2 C Programs .................................................................................................. 2 C Environment Setup ............................................................... 3 Text Editor ................................................................................................... 3 The C Compiler ............................................................................................ 3 Installation on Unix/Linux ............................................................................