Climate Scenarios Developed from Statistical Downscaling Methods. IPCC
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Point Downscaling of Surface Wind Speed for Forecast Applications
MARCH 2018 T A N G A N D B A S S I L L 659 Point Downscaling of Surface Wind Speed for Forecast Applications BRIAN H. TANG Department of Atmospheric and Environmental Sciences, University at Albany, State University of New York, Albany, New York NICK P. BASSILL New York State Mesonet, Albany, New York (Manuscript received 23 May 2017, in final form 26 December 2017) ABSTRACT A statistical downscaling algorithm is introduced to forecast surface wind speed at a location. The down- scaling algorithm consists of resolved and unresolved components to yield a time series of synthetic wind speeds at high time resolution. The resolved component is a bias-corrected numerical weather prediction model forecast of the 10-m wind speed at the location. The unresolved component is a simulated time series of the high-frequency component of the wind speed that is trained to match the variance and power spectral density of wind observations at the location. Because of the stochastic nature of the unresolved wind speed, the downscaling algorithm may be repeated to yield an ensemble of synthetic wind speeds. The ensemble may be used to generate probabilistic predictions of the sustained wind speed or wind gusts. Verification of the synthetic winds produced by the downscaling algorithm indicates that it can accurately predict various fea- tures of the observed wind, such as the probability distribution function of wind speeds, the power spectral density, daily maximum wind gust, and daily maximum sustained wind speed. Thus, the downscaling algo- rithm may be broadly applicable to any application that requires a computationally efficient, accurate way of generating probabilistic forecasts of wind speed at various time averages or forecast horizons. -

Downscaling of General Circulation Models for Regionalisation of Water
Climate Change Causes and Hydrologic Predictive Capabilities V.V. Srinivas Associate Professor Department of Civil Engineering Indian Institute of Science, Bangalore [email protected] 1 2 Overview of Presentation Climate Change Causes Effects of Climate Change Hydrologic Predictive Capabilities to Assess Impacts of Climate Change on Future Water Resources . GCMs and Downscaling Methods . Typical case studies Gaps where more research needs to be focused 3 Weather & Climate Weather Definition: Condition of the atmosphere at a particular place and time Time scale: Hours-to-days Spatial scale: Local to regional Climate Definition: Average pattern of weather over a period of time Time scale: Decadal-to-centuries and beyond Spatial scale: Regional to global Climate Change Variation in global and regional climates 4 Climate Change – Causes Variation in the solar output/radiation Sun-spots (dark patches) (11-years cycle) (Source: PhysicalGeography.net) Cyclic variation in Earth's orbital characteristics and tilt - three Milankovitch cycles . Change in the orbit shape (circular↔elliptical) (100,000 years cycle) . Changes in orbital timing of perihelion and aphelion – (26,000 years cycle) . Changes in the tilt (obliquity) of the Earth's axis of rotation (41,000 year cycle; oscillates between 22.1 and 24.5 degrees) 5 Climate Change - Causes Volcanic eruptions Ejected SO2 gas reacts with water vapor in stratosphere to form a dense optically bright haze layer that reduces the atmospheric transmission of incoming solar radiation Figure : Ash column generated by the eruption of Mount Pinatubo. (Source: U.S. Geological Survey). 6 Climate Change - Causes Variation in Atmospheric GHG concentration Global warming due to absorption of longwave radiation emitted from the Earth's surface Sources of GHGs . -

Downscaling Climate Modelling for High-Resolution Climate Information and Impact Assessment
HANDBOOK N°6 Seminar held in Lecce, Italy 9 - 20 March 2015 Euro South Mediterranean Initiative: Climate Resilient Societies Supported by Low Carbon Economies Downscaling Climate Modelling for High-Resolution Climate Information and Impact Assessment Project implemented by Project funded by the AGRICONSULTING CONSORTIUM EuropeanA project Union funded by Agriconsulting Agrer CMCC CIHEAM-IAM Bari the European Union d’Appolonia Pescares Typsa Sviluppo Globale 1. INTRODUCTION 2. DOWNSCALING SCENARIOS 3. SEASONAL FORECASTS 4. CONCEPTS & EXAMPLES 5. CONCLUSIONS 6. WEB LINKS 7. REFERENCES DISCLAIMER The information and views set out in this document are those of the authors and do not necessarily reflect the offi- cial opinion of the European Union. Neither the European Union, its institutions and bodies, nor any person acting on their behalf, may be held responsible for the use which may be made of the information contained herein. The content of the report is based on presentations de- livered by speakers at the seminars and discussions trig- gered by participants. Editors: The ClimaSouth team with contributions by Neil Ward (lead author), E. Bucchignani, M. Montesarchio, A. Zollo, G. Rianna, N. Mancosu, V. Bacciu (CMCC experts), and M. Todorovic (IAM-Bari). Concept: G.H. Mattravers Messana Graphic template: Zoi Environment Network Graphic design & layout: Raffaella Gemma Agriconsulting Consortium project directors: Ottavio Novelli / Barbara Giannuzzi Savelli ClimaSouth Team Leader: Bernardo Sala Project funded by the EuropeanA project Union funded by the European Union Acronyms | Disclaimer | CS website 2 1. INTRODUCTION 2. DOWNSCALING SCENARIOS 3. SEASONAL FORECASTS 4. CONCEPTS & EXAMPLES 5. CONCLUSIONS 6. WEB LINKS 7. REFERENCES FOREWORD The Mediterranean region has been identified as a cli- ernment, the private sector and civil society. -

Challenges in the Paleoclimatic Evolution of the Arctic and Subarctic Pacific Since the Last Glacial Period—The Sino–German
challenges Concept Paper Challenges in the Paleoclimatic Evolution of the Arctic and Subarctic Pacific since the Last Glacial Period—The Sino–German Pacific–Arctic Experiment (SiGePAX) Gerrit Lohmann 1,2,3,* , Lester Lembke-Jene 1 , Ralf Tiedemann 1,3,4, Xun Gong 1 , Patrick Scholz 1 , Jianjun Zou 5,6 and Xuefa Shi 5,6 1 Alfred-Wegener-Institut Helmholtz-Zentrum für Polar- und Meeresforschung Bremerhaven, 27570 Bremerhaven, Germany; [email protected] (L.L.-J.); [email protected] (R.T.); [email protected] (X.G.); [email protected] (P.S.) 2 Department of Environmental Physics, University of Bremen, 28359 Bremen, Germany 3 MARUM Center for Marine Environmental Sciences, University of Bremen, 28359 Bremen, Germany 4 Department of Geosciences, University of Bremen, 28359 Bremen, Germany 5 First Institute of Oceanography, Ministry of Natural Resources, Qingdao 266061, China; zoujianjun@fio.org.cn (J.Z.); xfshi@fio.org.cn (X.S.) 6 Pilot National Laboratory for Marine Science and Technology, Qingdao 266061, China * Correspondence: [email protected] Received: 24 December 2018; Accepted: 15 January 2019; Published: 24 January 2019 Abstract: Arctic and subarctic regions are sensitive to climate change and, reversely, provide dramatic feedbacks to the global climate. With a focus on discovering paleoclimate and paleoceanographic evolution in the Arctic and Northwest Pacific Oceans during the last 20,000 years, we proposed this German–Sino cooperation program according to the announcement “Federal Ministry of Education and Research (BMBF) of the Federal Republic of Germany for a German–Sino cooperation program in the marine and polar research”. Our proposed program integrates the advantages of the Arctic and Subarctic marine sediment studies in AWI (Alfred Wegener Institute) and FIO (First Institute of Oceanography). -

Cccma CMIP6 Model Updates
CCCma CMIP6 Model Updates CanESM2! CanESM5! CMIP5 CMIP6 AGCM4.0! AGCM5! CTEM NEW COUPLER CTEM5 CMOC LIM2 CanOE OGCM4.0! Model Improvements NEMO3.4! Atmosphere Ocean − model levels increased from 35 to 49 − new ocean model based on NEMO3.4 (ORCA1) st nd − aerosol updates (1 and 2 indirect effects) − LIM2 sea-ice component − improved treatment of volcanic aerosol − new in-house coupler developed − improved aerosol radiative effects for black and organic carbon Ocean Biogeochemistry − subgrid scale lakes added (FLAKE) − new parameterization, the Canadian Ocean Ecosystem model, CanOE Land Surface − double the number of biogeochemical tracers − land-surface scheme updated CLASS2.7→CLASS3.6 − increase number of classes of phytoplankton, − improved treatment of snow and snow albedo zooplankton and detritus from one to two − land biogeochemistry → wetlands added with − prognostic iron cycle methane emissions CanESM Functionality − new mineral dust parameterization − new “relaxed CO2” option for specified CO2 concentration simulations Other issues: 1. We are currently in the process of migrating to a new supercomputing system – being installed now and should be running on it over the next few months. 2. Global climate model development is integrated with development of operational seasonal prediction system, decadal prediction system, and regional climate downscaling system. 3. We are also increasingly involved in aspects of ‘climate services’ – providing multi-model climate scenario information to impact and adaptation users, decision-makers, -

A Performance Evaluation of Dynamical Downscaling of Precipitation Over Northern California
sustainability Article A Performance Evaluation of Dynamical Downscaling of Precipitation over Northern California Suhyung Jang 1,*, M. Levent Kavvas 2, Kei Ishida 3, Toan Trinh 2, Noriaki Ohara 4, Shuichi Kure 5, Z. Q. Chen 6, Michael L. Anderson 7, G. Matanga 8 and Kara J. Carr 2 1 Water Resources Research Center, K-Water Institute, Daejeon 34045, Korea 2 Department of Civil and Environmental Engineering, University of California, Davis, CA 95616, USA; [email protected] (M.L.K.); [email protected] (T.T.); [email protected] (K.J.C.) 3 Department of Civil and Environmental Engineering, Kumamoto University, Kumamoto 860-8555, Japan; [email protected] 4 Department of Civil and Architectural Engineering, University of Wyoming, Laramie, WY 82071, USA; [email protected] 5 Department of Environmental Engineering, Toyama Prefectural University, Toyama 939-0398, Japan; [email protected] 6 California Department of Water Resources, Sacramento, CA 95814, USA; [email protected] 7 California Department of Water Resources, Sacramento, CA 95821, USA; [email protected] 8 US Bureau of Reclamation, Sacramento, CA 95825, USA; [email protected] * Correspondence: [email protected]; Tel.: +82-42-870-7413 Received: 29 June 2017; Accepted: 9 August 2017; Published: 17 August 2017 Abstract: It is important to assess the reliability of high-resolution climate variables used as input to hydrologic models. High-resolution climate data is often obtained through the downscaling of Global Climate Models and/or historical reanalysis, depending on the application. In this study, the performance of dynamically downscaled precipitation from the National Centers for Environmental Prediction (NCEP) and the National Center for Atmospheric Research (NCAR) reanalysis data (NCEP/NCAR reanalysis I) was evaluated at point scale, watershed scale, and regional scale against corresponding in situ rain gauges and gridded observations, with a focus on Northern California. -

Statistical Downscaling
Statistical downscaling of the Community Climate System Model (CCSM) monthly temperature and precipitation projections White Paper by Tim Hoar and Doug Nychka (IMAGe/NCAR) April 2008 Statistical Downscaling The outputs from the Community Climate System Model (CCSM) may be relatively coarse for applications on regional and local scales. This results from an attempt to balance the computational cost of producing many long simulations and the cost of running at higher resolutions. W hile useful for their intended purpose, it is also desirable to use this information at a local scale. The spatial resolution of climate change datasets generated from the CCSM runs is approximately 1.4 x 1.4 degrees (Figure 1). Figure 1: Centroids of CCSM grid cells at approximately 1.4 degree spatial resolution Downscaling is the general name for a procedure to take information known at large scales to make predictions at local scales. Statistical downscaling is a two-step process consisting of i) the development of statistical relationships between local climate variables (e.g., surface air temperature and precipitation) and large-scale predictors (e.g., pressure fields), and ii) the application of such relationships to the output of Global Climate Model (GCM) experiments to simulate local climate characteristics in the future. Statistical downscaling may be used in climate impacts assessment at regional and local scales and when suitable observed data are available to derive the statistical relationships. A variety of statistical downscaling methods have been developed, ranging from seasonal and monthly to daily and hourly climate and weather simulations on a local scale. The majority of methods have been developed for the US, European and Japanese locations, where long-term observed data are available for model calibration and verification. -

Climate Scenario Development
13 Climate Scenario Development Co-ordinating Lead Authors L.O. Mearns, M. Hulme Lead Authors T.R. Carter, R. Leemans, M. Lal, P. Whetton Contributing Authors L. Hay, R.N. Jones, R. Katz, T. Kittel, J. Smith, R. Wilby Review Editors L.J. Mata, J. Zillman Contents Executive Summary 741 13.4.1.3 Applications of the methods to impacts 752 13.1 Introduction 743 13.4.2 Temporal Variability 752 13.1.1 Definition and Nature of Scenarios 743 13.4.2.1 Incorporation of changes in 13.1.2 Climate Scenario Needs of the Impacts variability: daily to interannual Community 744 time-scales 752 13.4.2.2 Other techniques for incorporating 13.2 Types of Scenarios of Future Climate 745 extremes into climate scenarios 754 13.2.1 Incremental Scenarios for Sensitivity Studies 746 13.5 Representing Uncertainty in Climate Scenarios 755 13.2.2 Analogue Scenarios 748 13.5.1 Key Uncertainties in Climate Scenarios 755 13.2.2.1 Spatial analogues 748 13.5.1.1 Specifying alternative emissions 13.2.2.2 Temporal analogues 748 futures 755 13.2.3 Scenarios Based on Outputs from Climate 13.5.1.2 Uncertainties in converting Models 748 emissions to concentrations 755 13.2.3.1 Scenarios from General 13.5.1.3 Uncertainties in converting Circulation Models 748 concentrations to radiative forcing 755 13.2.3.2 Scenarios from simple climate 13.5.1.4 Uncertainties in modelling the models 749 climate response to a given forcing 755 13.2.4 Other Types of Scenarios 749 13.5.1.5 Uncertainties in converting model response into inputs for impact 13.3 Defining the Baseline 749 studies 756 -
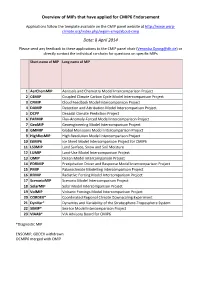
Overview of Mips That Have Applied for CMIP6 Endorsement Date: 8
Overview of MIPs that have applied for CMIP6 Endorsement Applications follow the template available on the CMIP panel website at http://www.wcrp‐ climate.org/index.php/wgcm‐cmip/about‐cmip Date: 8 April 2014 Please send any feedback to these applications to the CMIP panel chair ([email protected]) or directly contact the individual co‐chairs for questions on specific MIPs Short name of MIP Long name of MIP 1 AerChemMIP Aerosols and Chemistry Model Intercomparison Project 2 C4MIP Coupled Climate Carbon Cycle Model Intercomparison Project 3 CFMIP Cloud Feedback Model Intercomparison Project 4 DAMIP Detection and Attribution Model Intercomparison Project 5 DCPP Decadal Climate Prediction Project 6 FAFMIP Flux‐Anomaly‐Forced Model Intercomparison Project 7 GeoMIP Geoengineering Model Intercomparison Project 8 GMMIP Global Monsoons Model Intercomparison Project 9 HighResMIP High Resolution Model Intercomparison Project 10 ISMIP6 Ice Sheet Model Intercomparison Project for CMIP6 11 LS3MIP Land Surface, Snow and Soil Moisture 12 LUMIP Land‐Use Model Intercomparison Project 13 OMIP Ocean Model Intercomparison Project 14 PDRMIP Precipitation Driver and Response Model Intercomparison Project 15 PMIP Palaeoclimate Modelling Intercomparison Project 16 RFMIP Radiative Forcing Model Intercomparison Project 17 ScenarioMIP Scenario Model Intercomparison Project 18 SolarMIP Solar Model Intercomparison Project 19 VolMIP Volcanic Forcings Model Intercomparison Project 20 CORDEX* Coordinated Regional Climate Downscaling Experiment 21 DynVar* Dynamics -

Statistical Downscaling of General Circulation Model Outputs to Catchment Streamflows
19th International Congress on Modelling and Simulation, Perth, Australia, 12–16 December 2011 http://mssanz.org.au/modsim2011 Statistical Downscaling of General Circulation Model Outputs to Catchment Streamflows D.A. Sachindraa, F. Huanga, A.F. Barton a,b, and B.J.C. Pereraa aVictoria University, P.O. Box 14428, Melbourne, Victoria 8001 bGrampians Wimmera Mallee Water Corporation, P.O. Box 481, Horsham, Victoria, 3402 Email: [email protected] Abstract: Since the latter half of the 20th century, many regions of Australia experienced a drop in average rainfall, causing low inflows to reservoirs. Until the recent heavy rainfalls of late 2010 and early 2011, Victoria suffered a severe drought commencing 1997. This resulted in a reduction of annual average inflows to Melbourne's main water supply reservoirs of about 38%, during the period 1997-2008. The Grampians Wimmera Mallee Water (GWMWater) supply system in north-western Victoria also experienced a drop in annual inflows to its reservoirs of about 75%, from the long term average since 1997. Already being the driest inhabited continent in the world, this drop in inflows to reservoirs was of significant concern to water managers across much of Australia. Such a significant deviation from the long term average highlights the importance of being able to reliably predict streamflows considering the likely future climate change and variability, which will ultimately aid in future planning of the water supply systems. General Circulation Models (GCMs) are the most advanced tools available for the simulation of future climate. However, the coarse spatial resolution of GCMs does not allow for hydroclimatic predictions at the catchment scale. -

Does Dynamical Downscaling Introduce Novel Information in Climate Model Simulations of Precipitation Change Over a Complex Topography Region?
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln NASA Publications National Aeronautics and Space Administration 2011 Does dynamical downscaling introduce novel information in climate model simulations of precipitation change over a complex topography region? George Tselioudis Center for Atmospheric Physics and Climatology of the Academy of Athens, [email protected] Costas Douvis Center for Atmospheric Physics and Climatology of the Academy of Athens Christos Zerefos Center for Atmospheric Physics and Climatology of the Academy of Athens Follow this and additional works at: https://digitalcommons.unl.edu/nasapub Tselioudis, George; Douvis, Costas; and Zerefos, Christos, "Does dynamical downscaling introduce novel information in climate model simulations of precipitation change over a complex topography region?" (2011). NASA Publications. 124. https://digitalcommons.unl.edu/nasapub/124 This Article is brought to you for free and open access by the National Aeronautics and Space Administration at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in NASA Publications by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. INTERNATIONAL JOURNAL OF CLIMATOLOGY Int. J. Climatol. 32: 1572–1578 (2012) Published online 6 May 2011 in Wiley Online Library (wileyonlinelibrary.com) DOI: 10.1002/joc.2360 Does dynamical downscaling introduce novel information in climate model simulations of precipitation change over a complex topography region? George -

Development and Evaluation of Statistical Downscaling Models for Monthly Precipitation
Earth Interactions d Volume 18 (2014) d Paper No. 18 d Page 1 Copyright Ó 2014, Paper 18-018; 62175 words, 13 Figures, 0 Animations, 12 Tables. http://EarthInteractions.org Development and Evaluation of Statistical Downscaling Models for Monthly Precipitation Aneesh Goly* RADISE International, Riviera Beach, Florida Ramesh S. V. Teegavarapu Department of Civil Engineering, Florida Atlantic University, Boca Raton, Florida Arpita Mondal Department of Civil Engineering, Indian Institute of Science, Bangalore, India Received 24 February 2014; in final form 30 June 2014 ABSTRACT: Several statistical downscaling models have been developed in the past couple of decades to assess the hydrologic impacts of climate change by projecting the station-scale hydrological variables from large-scale atmo- spheric variables simulated by general circulation models (GCMs). This paper presents and compares different statistical downscaling models that use mul- tiple linear regression (MLR), positive coefficient regression (PCR), stepwise regression (SR), and support vector machine (SVM) techniques for estimating monthly rainfall amounts in the state of Florida. Mean sea level pressure, air * Corresponding author address: Aneesh Goly, RADISE International, 4152 W. Blue Heron Blvd., Suite 228, Riviera Beach, FL 33404. E-mail address: [email protected]; [email protected]; [email protected] DOI: 10.1175/EI-D-14-0024.1 Unauthenticated | Downloaded 10/06/21 04:45 PM UTC Earth Interactions d Volume 18 (2014) d Paper No. 18 d Page 2 temperature, geopotential height, specific humidity, U wind, and V wind are used as the explanatory variables/predictors in the downscaling models. Data for these variables are obtained from the National Centers for Environmental Prediction–National Center for Atmospheric Research (NCEP–NCAR) re- analysis dataset and the Canadian Centre for Climate Modelling and Analysis (CCCma) Coupled Global Climate Model, version 3 (CGCM3) GCM simula- tions.