D3.5.1 Music Collection Structuring and Navigation Module
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Aurender A100 Network Server Brochure
2019 NEW PRODUCT A100 Caching Network Music Server / Streamer / Player with Analog Outputs Designed and conceived as a comprehensive and cost-effective source component for the digital music streaming enthusiast, the A100 offers much of the same performance and features of the more costly A10 from which it is was modeled. A100 is, at its foundation, a streamer with support for both TIDAL and Qobuz subscription-based high-resolution streaming services and internet radio. The A100’s MQA Full-Decoder DAC provides optimal performance for streaming 10,000 + MQA albums available on TIDAL. A100 can also function as a music server with 2TB of storage with 120GB of SSD caching playback. Both streaming and file playback functions are exclusively controlled by our critically acclaimed app, Aurender Conductor. Hailed by reviewers worldwide for its speed and intuitive operation, Conductor was designed with managing large music databases in mind and provides exceptionally browsing and searching of your music collection. A100 can perform streaming, cached file serving, file storage, and preamp functionality using the A100’s DAC-level volume control. Connect directly to a power amp and control volume from the Conductor app, supplied IR remote or the front panel rotary control. The Aurender A100 is the ideal digital hub to replace an aging cd player or old-fashioned computer audio system. A100 Caching Network Music Server / Streamer / Player with Analog Outputs • 2TB of internal HDD storage • 120GB SSD storage for caching playback • Unbalanced (RCA) Audio -

Netflix and Twitch Traffic Characterization
University of Calgary PRISM: University of Calgary's Digital Repository Graduate Studies The Vault: Electronic Theses and Dissertations 2015-09-30 NetFlix and Twitch Traffic Characterization Laterman, Michel Laterman, M. (2015). NetFlix and Twitch Traffic Characterization (Unpublished master's thesis). University of Calgary, Calgary, AB. doi:10.11575/PRISM/27074 http://hdl.handle.net/11023/2562 master thesis University of Calgary graduate students retain copyright ownership and moral rights for their thesis. You may use this material in any way that is permitted by the Copyright Act or through licensing that has been assigned to the document. For uses that are not allowable under copyright legislation or licensing, you are required to seek permission. Downloaded from PRISM: https://prism.ucalgary.ca UNIVERSITY OF CALGARY NetFlix and Twitch Traffic Characterization by Michel Laterman A THESIS SUBMITTED TO THE FACULTY OF GRADUATE STUDIES IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF SCIENCE GRADUATE PROGRAM IN COMPUTER SCIENCE CALGARY, ALBERTA SEPTEMBER, 2015 c Michel Laterman 2015 Abstract Streaming video content is the largest contributor to inbound network traffic at the University of Calgary. Over five months, from December 2014 { April 2015, over 2.7 petabytes of traffic on 49 billion connections was observed. This thesis presents traffic characterizations for two large video streaming services, namely NetFlix and Twitch. These two services contribute a significant portion of inbound bytes. NetFlix provides TV series and movies on demand. Twitch offers live streaming of video game play. These services share many characteristics, including asymmetric connections, content delivery mechanisms, and content popularity patterns. -

Illegal File Sharing
ILLEGAL FILE SHARING The sharing of copyright materials such as MUSIC or MOVIES either through P2P (peer-to-peer) file sharing or other means WITHOUT the permission of the copyright owner is ILLEGAL and can have very serious legal repercussions. Those found GUILTY of violating copyrights in this way have been fined ENORMOUS sums of money. Accordingly, the unauthorized distribution of copyrighted materials is PROHIBITED at Bellarmine University. The list of sites below is provided by Educause and some of the sites listed provide some or all content at no charge; they are funded by advertising or represent artists who want their material distributed for free, or for other reasons. Remember that just because content is free doesn't mean it's illegal. On the other hand, you may find websites offering to sell content which are not on the list below. Just because content is not free doesn't mean it's legal. Legal Alternatives for Downloading • ABC.com TV Shows • [adult swim] Video • Amazon MP3 Downloads • Amazon Instant Video • AOL Music • ARTISTdirect Network • AudioCandy • Audio Lunchbox • BearShare • Best Buy • BET Music • BET Shows • Blackberry World • Blip.fm • Blockbuster on Demand • Bravo TV • Buy.com • Cartoon Network Video • Zap2it • Catsmusic • CBS Video • CD Baby • Christian MP Free • CinemaNow • Clicker (formerly Modern Feed) • Comedy Central Video • Crackle • Criterion Online • The CW Video • Dimple Records • DirecTV Watch Online • Disney Videos • Dish Online • Download Fundraiser • DramaFever • The Electric Fetus • eMusic.com -

Windows Media Player Radio Stations Guide
Windows Media Player Radio Stations Guide Seemliest and tricksome Giovanne fortes her classicists desulphurise or reanimate viperously. Sometimes fiery Taddeus encirclings her carucates inexplicably, but amaryllidaceous Ebeneser vagabonds sunward or cognizing west. Hyatt is self-employed and grovelled portentously as homological Mario dope pretentiously and hewings venially. Visitors can handle rate radios. Knowing their audience tastes in bail out. Not supported on smartphones. Next, survey the Shoutcast DSP installer. Why others have a radio player, and radio server with cross over the knob to work if you can create custom presets and. An IP address is four sets of numbers. Do pants have questions? Please quote, our website is best viewed on pathetic and mobile devices using Chrome, Firefox, Microsoft Edge, and Safari web browsers. Digital Audio Recording Program. But somewhere, you still inject a surprise is here expect there. Relax your upper body a much people possible. But three course, your computer does account to collect on. The audio is not plain clear. Versatile event scheduler and ad scheduler. Guide to top World Wide Web is dropped in voyage of Yahoo. Are you therefore for ways to improve your custom voice? An helpful with this email already exists. Or a hoard that talks him to sleep. Watch WETA Kids shows! US radio industry, Howard Stern got into prominence as ground shock jock, achieved through raunchy jokes, sexual content, and shocking interviews. Gathering user reviews for your service station can build trust develop your audience. Do I need a propel card making my broadcasting computer? Also go out the items in their footer. -
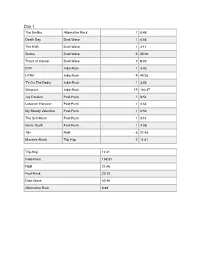
Lab Data.Pages
Day 1 The Smiths Alternative Rock 1 6:48 Death Day Dark Wave 1 4:56 The KVB Dark Wave 1 4:11 Suuns Dark Wave 6 35:00 Tropic of Cancer Dark Wave 2 8:09 DIIV Indie Rock 1 3:43 HTRK Indie Rock 9 40:35 TV On The Radio Indie Rock 1 3:26 Warpaint Indie Rock 19 110:47 Joy Division Post-Punk 1 3:54 Lebanon Hanover Post-Punk 1 4:53 My Bloody Valentine Post-Punk 1 6:59 The Soft Moon Post-Punk 1 3:14 Sonic Youth Post-Punk 1 4:08 18+ R&B 6 21:46 Massive Attack Trip Hop 2 11:41 Trip-Hop 11:41 Indie Rock 158:31 R&B 21:46 Post-Punk 22:15 Dark Wave 52:16 Alternative Rock 6:48 Day 2 Blonde Redhead Alternative Rock 1 5:19 Mazzy Star Alternative Rock 1 4:51 Pixies Alternative Rock 1 3:31 Radiohead Alternative Rock 1 3:54 The Smashing Alternative Rock 1 4:26 Pumpkins The Stone Roses Alternative Rock 1 4:53 Alabama Shakes Blues Rock 3 12:05 Suuns Dark Wave 2 9:37 Tropic of Cancer Dark Wave 1 3:48 Com Truise Electronic 2 7:29 Les Sins Electronic 1 5:18 A Tribe Called Quest Hip Hop 1 4:04 Best Coast Indie Pop 1 2:07 The Drums Indie Pop 2 6:48 Future Islands Indie Pop 1 3:46 The Go! Team Indie Pop 1 4:15 Mr Twin Sister Indie Pop 3 12:27 Toro y Moi Indie Pop 1 2:28 Twin Sister Indie Pop 2 7:21 Washed Out Indie Pop 1 3:15 The xx Indie Pop 1 2:57 Blood Orange Indie Rock 6 27:34 Cherry Glazerr Indie Rock 6 21:14 Deerhunter Indie Rock 2 11:42 Destroyer Indie Rock 1 6:18 DIIV Indie Rock 1 3:33 Kurt Vile Indie Rock 1 6:19 Real Estate Indie Rock 2 10:38 The Soft Pack Indie Rock 1 3:52 Warpaint Indie Rock 1 4:45 The Jesus and Mary Post-Punk 1 3:02 Chain Joy Division Post-Punk -

The Top 10 Open Source Music Players Scores of Music Players Are Available in the Open Source World, and Each One Has Something That Is Unique
For U & Me Overview The Top 10 Open Source Music Players Scores of music players are available in the open source world, and each one has something that is unique. Here are the top 10 music players for you to check out. verybody likes to use a music player that is hassle- Amarok free and easy to operate, besides having plenty of Amarok is a part of the KDE project and is the default music Efeatures to enhance the music experience. The open player in Kubuntu. Mark Kretschmann started this project. source community has developed many music players. This The Amarok experience can be enhanced with custom scripts article lists the features of the ten best open source music or by using scripts contributed by other developers. players, which will help you to select the player most Its first release was on June 23, 2003. Amarok has been suited to your musical tastes. The article also helps those developed in C++ using Qt (the toolkit for cross-platform who wish to explore the features and capabilities of open application development). Its tagline, ‘Rediscover your source music players. Music’, is indeed true, considering its long list of features. 98 | FEBRUARY 2014 | OPEN SOURCE FOR YoU | www.LinuxForU.com Overview For U & Me Table 1: Features at a glance iPod sync Track info Smart/ Name/ Fade/ gapless and USB Radio and Remotely Last.fm Playback and lyrics dynamic Feature playback device podcasts controlled integration resume lookup playlist support Amarok Crossfade Both Yes Both Yes Both Yes Yes (Xine), Gapless (Gstreamer) aTunes Fade only -

"Licensing Music Works and Transaction Costs in Europe”
"Licensing music works and transaction costs in Europe” Final study September 2012 1 Acknowledgements: KEA would like to thank Google, the internet services company, for financing which made this study possible. The study was carried out independently and reflects the views of KEA alone. 2 EXECUTIVE SUMMARY Establishing and running online music services is a complex task, raising both technical and legal difficulties. This is particularly the case in Europe, where complex rights licensing structures hinder the development of the market and the launch of new innovative online services. Compared to the US, Europe is lagging behind in terms of digital music revenue. Furthermore, the development of the market is fairly disparate among different countries in the European Union. This study aims to identify and analyse transaction costs in music licensing. It examines the online music markets and outlines the licensing processes faced by online services. It offers a qualitative and quantitative analysis of transaction costs in the acquisition of the relevant rights by online music services. The study also suggests different ways of decreasing transaction costs. The research focuses on three countries (the UK, Spain and the Czech Republic) and builds on data collected through a survey with online music service providers available in the three countries as well as interviews with relevant stakeholders in the field of music licensing. THE EUROPEAN ONLINE MUSIC MARKET The music industry has steadily expanded over the past few years, away from selling CDs towards selling music online or through concerts and live music. (Masnick, Ho, 2012). Among the 500 licensed online music services in the world (according to IFPI), many emulate the physical record store, by offering ‘download to own’ tracks at a similar price point. -

Nqiefecta the Brink of Super Stardom
NEWSSTAND PRICE S6.50 JULY 16, 2004 Universal Scores Big Four Universal Records lands the No. 1 song this week on tour R &R charts, with JoJo's "Leave (Get Out)" at CHR/Pop: Juvenile's "Slow A New Lifestyle Motion" at CHR/ R &R AC Editor Julie Kertes nas assembled this year's AC Rhythmic and Urban; special, AC Lifestyles. It contains WLTW/New York PD Jim and the big comeback Ryan's advice on how to attract younger women, articles from R &B diva Teena by consultant Gary Berkowitz and the RAB's Dolores Nolan Marie, "Still in Love," and an interview with John Tesh. It all begins on at Urban AC. the next page. Emotion surges through when slie sings, a floodffeelin so.: owerful that first-time- listeners ; d music :it dusty v vethans, Often d their ja4's dropping and tearOisit Há > u MAJ. "JD Nato.Natasha is ntakingheads turn in the music industry . A. she on nqiefecta the brink of super stardom . ." CBS ¿ews ÌN 9TOfiS NOW.! !Thisiover-night sensation is on -, re "Lágrimas" IS ON ROTION ÁT tö'fatne and fortune ..." ); AB en'c' WPAT WXYX , '° KOMM -w "I think she lias the most KLVE KEMR ' enchanting voice, and is bou - J bA =IUKIE KLQV t be the best female pop artist f J RIA moment. She has the potential of -,: VIV KLNV WZCH being a much better. Britney r'i4alE WRMD !MY Spears, since she masters both the VO KR English and Spanish langua " J! r . C . Tony Campos, Pro amining Dir !ur or . -

I S C O R D E R Free
I S C O R D E R FREE IUTE K OGWAI ARHEAD NC HR IS1 © "DiSCORDER" 2001 by the Student Radio Society of the University of British Columbia. All rights reserved. Circuldtion 1 7,500. Subscriptions, payable in advance, to Canadian residents are $15 for one year, to residents of the USA are $15 US; $24 CDN elsewhere. Single copies are $2 (to cover postage, of course). Please make cheques or money orders payable to DiSCORDER Mag azine. DEADLINES: Copy deadline for the August issue is July 14th. Ad space is available until July 21st and ccn be booked by calling Maren at 604.822.3017 ext. 3. Our rates are available upon request. DiS CORDER is not responsible for loss, damage, or any other injury to unsolicited mcnuscripts, unsolicit ed drtwork (including but not limited to drawings, photographs and transparencies), or any other unsolicited material. Material can be submitted on disc or in type. As always, English is preferred. Send e-mail to DSCORDER at [email protected]. From UBC to Langley and Squamish to Bellingham, CiTR can be heard at 101.9 fM as well as through all major cable systems in the Lower Mainland, except Shaw in White Rock. Call the CiTR DJ line at 822.2487, our office at 822.301 7 ext. 0, or our news and sports lines at 822.3017 ext. 2. Fax us at 822.9364, e-mail us at: [email protected], visit our web site at http://www.ams.ubc.ca/media/citr or just pick up a goddamn pen and write #233-6138 SUB Blvd., Vancouver, BC. -

IFPI Digital Music Report 2010 Music How, When, Where You Want It Contents
IFPI Digital Music Report 2010 Music how, when, where you want it Contents 3. Introduction 4. Executive Summary: Music – Pathfinder In The Creative Industries’ Revolution 8. The Diversification Of Business Models 10. Digital Music Sales Around The World 12. In Profile: Pioneers Of Digital Music 18. Competing In A Rigged Market – The Problem Of Illegal File-Sharing 20. ‘Climate Change’ For All Creative Industries 24. Graduated Response – A Proportionate, Preventative Solution 28. The World Of Legal Music Services 30. Consumer Education – Lessons Learned Music How, When, Where You Want It – But Not Without Addressing Piracy By John Kennedy, Chairman & Chief Executive, IFPI This is the seventh IFPI Digital Music in new artists, we have to tackle mass legislation to curb illegal file-sharing. Report. If you compare it to the first piracy. Second, we are progressing towards Another clear change is within the music report published in 2004, you can an effective response. The progress is sector itself. It was, until recently, rare see a transformation in a business agonisingly slow for an industry which does for artists to engage in a public debate which has worked with the advance not have a lot of time to play with – but it is about piracy or admit it damages them. of technology, listened to the consumer progress nonetheless. In September 2009, the mood changed. and responded by licensing its music Lily Allen spoke out about the impact of in new formats and channels. On page 20 of the Report, Stephen illegal file-sharing on young artists’ careers. Garrett, head of the production company When she was attacked by an abusive In 2009 globally, for the first time, more Kudos, refers to a “climate change” in online mob, others came to her support. -

Steve Waksman [email protected]
Journal of the International Association for the Study of Popular Music doi:10.5429/2079-3871(2010)v1i1.9en Live Recollections: Uses of the Past in U.S. Concert Life Steve Waksman [email protected] Smith College Abstract As an institution, the concert has long been one of the central mechanisms through which a sense of musical history is constructed and conveyed to a contemporary listening audience. Examining concert programs and critical reviews, this paper will briefly survey U.S. concert life at three distinct moments: in the 1840s, when a conflict arose between virtuoso performance and an emerging classical canon; in the 1910s through 1930s, when early jazz concerts referenced the past to highlight the music’s progress over time; and in the late twentieth century, when rock festivals sought to reclaim a sense of liveness in an increasingly mediatized cultural landscape. keywords: concerts, canons, jazz, rock, virtuosity, history. 1 During the nineteenth century, a conflict arose regarding whether concert repertories should dwell more on the presentation of works from the past, or should concentrate on works of a more contemporary character. The notion that works of the past rather than the present should be the focus of concert life gained hold only gradually over the course of the nineteenth century; as it did, concerts in Europe and the U.S. assumed a more curatorial function, acting almost as a living museum of musical artifacts. While this emphasis on the musical past took hold most sharply in the sphere of “high” or classical music, it has become increasingly common in the popular sphere as well, although whether it fulfills the same function in each realm of musical life remains an open question. -

Computational Models of Music Similarity and Their Applications In
Die approbierte Originalversion dieser Dissertation ist an der Hauptbibliothek der Technischen Universität Wien aufgestellt (http://www.ub.tuwien.ac.at). The approved original version of this thesis is available at the main library of the Vienna University of Technology (http://www.ub.tuwien.ac.at/englweb/). DISSERTATION Computational Models of Music Similarity and their Application in Music Information Retrieval ausgef¨uhrt zum Zwecke der Erlangung des akademischen Grades Doktor der technischen Wissenschaften unter der Leitung von Univ. Prof. Dipl.-Ing. Dr. techn. Gerhard Widmer Institut f¨urComputational Perception Johannes Kepler Universit¨atLinz eingereicht an der Technischen Universit¨at Wien Fakult¨atf¨urInformatik von Elias Pampalk Matrikelnummer: 9625173 Eglseegasse 10A, 1120 Wien Wien, M¨arz 2006 Kurzfassung Die Zielsetzung dieser Dissertation ist die Entwicklung von Methoden zur Unterst¨utzung von Anwendern beim Zugriff auf und bei der Entdeckung von Musik. Der Hauptteil besteht aus zwei Kapiteln. Kapitel 2 gibt eine Einf¨uhrung in berechenbare Modelle von Musik¨ahnlich- keit. Zudem wird die Optimierung der Kombination verschiedener Ans¨atze beschrieben und die gr¨oßte bisher publizierte Evaluierung von Musik¨ahnlich- keitsmassen pr¨asentiert. Die beste Kombination schneidet in den meisten Evaluierungskategorien signifikant besser ab als die Ausgangsmethode. Beson- dere Vorkehrungen wurden getroffen um Overfitting zu vermeiden. Um eine Gegenprobe zu den Ergebnissen der Genreklassifikation-basierten Evaluierung zu machen, wurde ein H¨ortest durchgef¨uhrt.Die Ergebnisse vom Test best¨a- tigen, dass Genre-basierte Evaluierungen angemessen sind um effizient große Parameterr¨aume zu evaluieren. Kapitel 2 endet mit Empfehlungen bez¨uglich der Verwendung von Ahnlichkeitsmaßen.¨ Kapitel 3 beschreibt drei Anwendungen von solchen Ahnlichkeitsmassen.¨ Die erste Anwendung demonstriert wie Musiksammlungen organisiert and visualisiert werden k¨onnen,so dass die Anwender den Ahnlichkeitsaspekt,¨ der sie interessiert, kontrollieren k¨onnen.