Package 'Tidycensus'
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2019 TIGER/Line Shapefiles Technical Documentation
TIGER/Line® Shapefiles 2019 Technical Documentation ™ Issued September 2019220192018 SUGGESTED CITATION FILES: 2019 TIGER/Line Shapefiles (machine- readable data files) / prepared by the U.S. Census Bureau, 2019 U.S. Department of Commerce Economic and Statistics Administration Wilbur Ross, Secretary TECHNICAL DOCUMENTATION: Karen Dunn Kelley, 2019 TIGER/Line Shapefiles Technical Under Secretary for Economic Affairs Documentation / prepared by the U.S. Census Bureau, 2019 U.S. Census Bureau Dr. Steven Dillingham, Albert Fontenot, Director Associate Director for Decennial Census Programs Dr. Ron Jarmin, Deputy Director and Chief Operating Officer GEOGRAPHY DIVISION Deirdre Dalpiaz Bishop, Chief Andrea G. Johnson, Michael R. Ratcliffe, Assistant Division Chief for Assistant Division Chief for Address and Spatial Data Updates Geographic Standards, Criteria, Research, and Quality Monique Eleby, Assistant Division Chief for Gregory F. Hanks, Jr., Geographic Program Management Deputy Division Chief and External Engagement Laura Waggoner, Assistant Division Chief for Geographic Data Collection and Products 1-0 Table of Contents 1. Introduction ...................................................................................................................... 1-1 1. Introduction 1.1 What is a Shapefile? A shapefile is a geospatial data format for use in geographic information system (GIS) software. Shapefiles spatially describe vector data such as points, lines, and polygons, representing, for instance, landmarks, roads, and lakes. The Environmental Systems Research Institute (Esri) created the format for use in their software, but the shapefile format works in additional Geographic Information System (GIS) software as well. 1.2 What are TIGER/Line Shapefiles? The TIGER/Line Shapefiles are the fully supported, core geographic product from the U.S. Census Bureau. They are extracts of selected geographic and cartographic information from the U.S. -

Development of Traffic Safety Zones and Integrating Macroscopic and Microscopic Safety Data Analytics for Novel Hot Zone Identification
University of Central Florida STARS Electronic Theses and Dissertations, 2004-2019 2014 Development of Traffic Safety Zones and Integrating Macroscopic and Microscopic Safety Data Analytics for Novel Hot Zone Identification JaeYoung Lee University of Central Florida Part of the Civil Engineering Commons Find similar works at: https://stars.library.ucf.edu/etd University of Central Florida Libraries http://library.ucf.edu This Doctoral Dissertation (Open Access) is brought to you for free and open access by STARS. It has been accepted for inclusion in Electronic Theses and Dissertations, 2004-2019 by an authorized administrator of STARS. For more information, please contact [email protected]. STARS Citation Lee, JaeYoung, "Development of Traffic Safety Zones and Integrating Macroscopic and Microscopic Safety Data Analytics for Novel Hot Zone Identification" (2014). Electronic Theses and Dissertations, 2004-2019. 4619. https://stars.library.ucf.edu/etd/4619 DEVELOPMENT OF TRAFFIC SAFETY ZONES AND INTEGRATING MACROSCOPIC AND MICROSCOPIC SAFETY DATA ANALYTICS FOR NOVEL HOT ZONE IDENTIFICATION by JAEYOUNG LEE B. Eng. Ajou University, Korea, 2007 M.S. Ajou University, Korea, 2009 A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Civil, Environmental and Construction Engineering in the College of Engineering and Computer Science at the University of Central Florida Orlando, Florida Spring Term 2014 Major Professor: Mohamed Abdel-Aty © 2014 JAEYOUNG LEE ii ABSTRACT Traffic safety has been considered one of the most important issues in the transportation field. With consistent efforts of transportation engineers, Federal, State and local government officials, both fatalities and fatality rates from road traffic crashes in the United States have steadily declined from 2006 to 2011.Nevertheless, fatalities from traffic crashes slightly increased in 2012 (NHTSA, 2013). -

Zipcoder: Data & Functions for Working with US ZIP Codes
Package ‘zipcodeR’ September 22, 2021 Title Data & Functions for Working with US ZIP Codes Version 0.3.3 Description Make working with ZIP codes in R painless with an inte- grated dataset of U.S. ZIP codes and functions for working with them. Search ZIP codes by multiple geographies, includ- ing state, county, city & across time zones. Also included are functions for relating ZIP codes to Census data, geocoding & distance calculations. License GPL-3 URL https://github.com/gavinrozzi/zipcodeR/, https://www.gavinrozzi.com/project/zipcoder/ BugReports https://github.com/gavinrozzi/zipcodeR/issues/ Encoding UTF-8 LazyData true RoxygenNote 7.1.2 Imports rlang, stringr, raster, tidycensus, tidyr, dplyr, jsonlite, httr, curl, RSQLite, DBI Depends R (>= 3.5.0) Suggests knitr, rmarkdown, markdown, readr, testthat (>= 3.0.0), covr VignetteBuilder knitr, rmarkdown Config/testthat/edition 3 NeedsCompilation no Author Gavin Rozzi [aut, cre] (<https://orcid.org/0000-0002-9969-8175>) Maintainer Gavin Rozzi <[email protected]> Repository CRAN Date/Publication 2021-09-22 04:30:02 UTC 1 2 download_zip_data R topics documented: download_zip_data . .2 geocode_zip . .3 get_cd . .3 get_tracts . .4 is_zcta . .4 normalize_zip . .5 reverse_zipcode . .5 search_cd . .6 search_city . .6 search_county . .7 search_fips . .8 search_radius . .8 search_state . .9 search_tz . 10 zcta_crosswalk . 10 zip_code_db . 11 zip_distance . 12 zip_to_cd . 12 Index 14 download_zip_data Download updated data files needed for library functionality to the package’s data directory. To be -

C2KBASIC.QXD (Page 1)
Census 2000 Basics Issued September 2002 MSO/02-C2KB U.S. Department of Commerce U S C E N S U S B U R E A U Economics and Statistics Administration U.S. CENSUS BUREAU Helping You Make Informed Decisions 1902-2002 ACKNOWLEDGMENTS This report was prepared by Andrea Sevetson under the general direction of John Kavaliunas, Chief, Marketing Services Office and Joanne Dickinson, Chief, Marketing Branch. Kim D. Ottenstein, Bernadette J. Gayle, and Laurene V. Qualls of the Administrative and Customer Services Division, Walter C. Odom, Chief, pro- vided publications and printing manage- ment, graphics design and composition, and editorial review for print and elec- tronic media. General direction and production management were provided by Gary J. Lauffer, Chief, Publications Services Branch. Census 2000 Basics Issued September 2002 MSO/02-C2KB U.S. Department of Commerce Donald L. Evans, Secretary Samuel W. Bodman, Deputy Secretary Economics and Statistics Administration Kathleen B. Cooper, Under Secretary for Economic Affairs U.S. CENSUS BUREAU Charles Louis Kincannon, Director SUGGESTED CITATION U.S. CENSUS BUREAU Census 2000 Basics U.S. Government Printing Office, Washington DC, 2002 ECONOMICS AND STATISTICS ADMINISTRATION Economics and Statistics Administration Kathleen B. Cooper, Under Secretary for Economic Affairs U.S. CENSUS BUREAU Charles Louis Kincannon, Director William G. Barron, Jr., Deputy Director and Chief Operating Officer Cynthia Z.F. Clark, Acting Principal Associate Director for Programs Preston Jay Waite, Associate Director for Decennial Census Gloria Gutierrez, Assistant Director for Marketing and Customer Liaison CONTENTS I. Importance of the Census: What it is used for and why .......................... 1 II. -
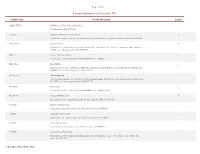
Layout Summary of Geocode File
Page 1 of 6 Layout Summary of Geocode File Variable Name Variable Description Length ADDR_TYPE USPS Record, Type of Record Matched 1 This data comes from HUD file. APT_NO Apartment Number (Address Line 2) 8 Contains the Apartment number (secondary address) portion of the street address. This data comes from HUD file. APT_TYPE Apartment Type 4 Contains the secondary address type abbreviation (Apt = Apartment, Ste = Suite, # = Apartment, RM = Room, FL = Floor, etc..). This data comes from HUD file. BG2K Census 2000 Block Group 1 It is the first character of the block ID (BLOCK2K) in the HUD file. BLK_FLG Block ID flag 1 This flag value identifies if HUD and NHIS block ID disagree. BLOCK2K is the block ID from the HUD file and COMBBLK is the block ID from the NHIS UCF file. BLKG_FLG Block group flag 1 This flag value identifies if HUD and NHIS block group disagree. BG2K is the block group from the HUD file and BLKGRP is the block group from the NHIS UCF file. BLKGRP Block Group 1 It is the first character of the block ID (COMBBLK) in the NHIS UCF file. BLOCK2K Census 2000 Block ID 4 First character is the census block group, it comes from the HUD geocoded file. C1PARC Apartment Return Code 1 Postal matcher apartment return codes. This data comes from HUD file. C1PDRC Directional Return Code 1 Postal matcher directional return codes. This data comes from HUD file. C1PGRC General Return Code 1 Postal matcher general return codes. This data comes from HUD file. C1PPRB Address Match Probability 1 Postal matcher address match probability return codes. -

Data Book 2019 Table Number Table Name
Table Number Table Name (Click on the table number to go to corresponding table) (To return to this "Titles" worksheet, you must select this worksheet again) Narrative 01.01 Population of Counties: 1831 to 2010 01.02 Characteristics of the Population: 1831 to 2010 01.03 Resident Population, by Military Status: 2010 to 2019 01.04 Resident and De Facto Population, by Residence Status: 2000 to 2019 01.05 Resident Population of Islands: 1970 to 2014-2018 01.06 Resident Population, by County: 2000 to 2019 01.07 Percentage Change in Resident Population, by County: 2000 to 2019 01.08 County Population as a Share of the State Total: 2000 to 2019 01.09 De Facto Population, by County: 2000 to 2019 01.10 Population, Land Area and Population Density, by County and Island: 2010 01.11 Resident Population of Counties and Judicial Districts: 1990 to 2014-2018 01.12 Resident Population and Number of Households, by Island and Census Designated Place: 2014-2018 01.13 Population and Percentage Change Rankings: 2010 and 2019 01.14 Resident Population for Oahu Neighborhoods: 2010 and 2014-2018 01.15 Population Characteristics of Oahu Neighborhoods: 2014-2018 01.16 Resident Population and Households, by Island and Census Tract: 2014-2018 01.17 Resident Population of Hawaiian Home Lands, by Island: 2014-2018 01.18 Resident Population, by Island and Zip Code Tabulation Area: 2014-2018 01.19 Resident and De Facto Population and Employed Persons, for Waikiki: 1970 to 2010 01.20 Urban and Rural Areas, by County: 2010 01.21 Centers of Population, by County: 1990 to -

1. GEOGRAPHIC AREAS COVERED in the ACS for Reporting Purposes, the U.S
1. GEOGRAPHIC AREAS COVERED IN THE ACS For reporting purposes, the U.S. Census Bureau divides Geographic areas are organized in a hierarchy (see the nation into two main types of geographic areas, Figure 1.1). Larger units, such as states, include smaller legal and statistical. Legal areas are defined specifi- units such as counties and census tracts. This structure cally by law, and include state, local, and tribal govern- is derived from the legal, administrative, or areal rela- ment units, and some specially defined administrative tionships of the entities. In the American Community areas like congressional districts. Many, but not all of Survey (ACS), block groups are the lowest (smallest) these areas, are represented by elected officials. An level of geography published. Block group data are example of a legal area is New York State. only available in the ACS 5-year data products. The ACS does not produce data at the block level. Statistical areas are defined directly by the Census Bureau and state, regional, or local authorities for the In Figure 1.1, the geographic types connected by lines purpose of presenting data. Examples of statistical are nested within each other. For example, a line areas include census designated places, census tracts, extends from counties to census tracts because a urban areas, and metropolitan statistical areas (such as county is completely comprised of census tracts, and a the Boston-Cambridge-Newton, MA-NH Metropolitan single census tract cannot cross a county boundary. Statistical Area). Figure 1.1. Hierarchy of Select Geographic Entities in the ACS NATION American Indian Areas/ Alaska Native Areas/ Hawaiian Home Lands ZIP Code Tabulation Areas REGIONS (ZCTA)** Urban Areas DIVISIONS Metropolitan and Micropolitan Areas School Districts STATES Places Congressional Districts Counties Public Use Microdata Areas Alaska Native Regional Areas County Subdivisions State Legislative Districts* Census Tracts* Block Groups* * Five-year estimates only. -

Guam Demographic Profile Summary File: Technical Documentation U.S
Guam Demographic Profile Summary File Issued March 2014 2010 Census of Population and Housing DPSFGU/10-3 (RV) Technical Documentation U.S. Department of Commerce Economics and Statistics Administration U.S. CENSUS BUREAU For additional information concerning the files, contact the Customer Liaison and Marketing Services Office, Customer Services Center, U.S. Census Bureau, Washington, DC 20233, or phone 301-763-INFO (4636). For additional information concerning the technical documentation, contact the Administrative and Customer Services Division, Electronic Products Development Branch, U.S. Census Bureau, Wash- ington, DC 20233, or phone 301-763-8004. Guam Demographic Profile Summary File Issued March 2014 2010 Census of Population and Housing DPSFGU/10-3 (RV) Technical Documentation U.S. Department of Commerce Penny Pritzker, Secretary Vacant, Deputy Secretary Economics and Statistics Administration Mark Doms, Under Secretary for Economic Affairs U.S. CENSUS BUREAU John H. Thompson, Director SUGGESTED CITATION 2010 Census of Population and Housing, Guam Demographic Profile Summary File: Technical Documentation U.S. Census Bureau, 2014 (RV). ECONOMICS AND STATISTICS ADMINISTRATION Economics and Statistics Administration Mark Doms, Under Secretary for Economic Affairs U.S. CENSUS BUREAU John H. Thompson, Director Nancy A. Potok, Deputy Director and Chief Operating Officer Frank A. Vitrano, Acting Associate Director for Decennial Census Enrique J. Lamas, Associate Director for Demographic Programs William W. Hatcher, Jr., Associate Director for Field Operations CONTENTS CHAPTERS 1. Abstract ............................................... 1-1 2. How to Use This Product ................................... 2-1 3. Subject Locator .......................................... 3-1 4. Summary Level Sequence Chart .............................. 4-1 5. List of Tables (Matrices) .................................... 5-1 6. Data Dictionary .......................................... 6-1 7. -

Data.Census.Gov Release Notes
data.census.gov Release Notes April 20, 2021 data.census.gov Release Notes Table of Contents data.census.gov Release Notes ..................................................................................................... 1 Purpose........................................................................................................................................... 3 Latest Updates ............................................................................................................................... 3 Features .......................................................................................................................................... 5 Single Search Bar ................................................................................................... 5 Advanced Search .................................................................................................... 5 Geography Filters ................................................................................................... 6 Navigation .............................................................................................................. 6 Tables ...................................................................................................................... 7 Download, Export, Copy/Paste, and Print .............................................................. 7 Save Your Search and Results ................................................................................ 8 Mapping ................................................................................................................. -

Revealing the Unequal Burden of COVID-19 by Income, Race/Ethnicity, and Household Crowding: US County Vs
Working Paper Series Revealing the unequal burden of COVID-19 by income, race/ethnicity, and household crowding: US county vs. ZIP code analyses Jarvis T. Chen, ScD1, Nancy Krieger, PhD2 April 21, 2020 HCPDS Working Paper Volume 19, Number 1 The views expressed in this paper are those of the author(s) and do not necessarily reflect those of the Harvard Center for Population and Development Studies. Affiliations 1. Department of Social and Behavioral Sciences, Harvard T.H. Chan School of Public Health 2. Department of Social and Behavioral Sciences, Harvard T.H. Chan School of Public Health Corresponding Author Jarvis T. Chen, ScD, Research Scientist, Department of Social and Behavioral Sciences, Harvard T.H. Chan School of Public Health Email: [email protected] Abstract No national, state, or local public health monitoring data in the US currently exist regarding the unequal economic and social burden of COVID-19. To address this gap, we draw on methods of the Public Health Disparities Geocoding Project, whereby we merge county-level cumulative death counts with population counts and area-based socioeconomic measures (ABSMs: % below poverty, % crowding, and % population of color, and the Index of Concentration at the Extremes) and compute rates, rate differences, and rate ratios by category of county- level ABSMs. To illustrate the performance of the method at finer levels of geographic aggregation, we analyze data on (a) confirmed cases in Illinois ZIP codes and (b) positive test results in New York City ZIP codes with ZIP code level ABSMs. We detect stark gradients though complex gradients in COVID-19 deaths by county-level ABSMs, with dramatically increased risk of death observed among residents of the most disadvantaged counties. -

Geographic Programs Update: Post-2010 Census Geographic Areas
2010 State Data Center Annual Training Conference Geographic Programs Update: Post-2010 Census Geographic Areas Michael Ratcliffe Geography Division October 14, 2010 Overview • Public Use Microdata Areas (PUMAs) • ZIP Code Tabulation Areas (ZCTAs) • Urban / Rural (Urban Areas) • Traffic Analysis Zones (TAZs) 2 Proposed Criteria for PUMAs • Standard PUMAs (one level) • Place-of-Work (POW) PUMAs and Migration (MIG) PUMAs • State-based • Minimum population threshold of 100,000 throughout decade • Counties and standard census tracts as building blocks • Contiguity 3 Population Threshold for PUMAs • Each PUMA must have a minimum 2010 Census population of 100,000 • The minimum population must be met at the time of delineation and maintained throughout the decade – In areas expected to experience population decline, define PUMAs above the minimum threshold to ensure at least 100,000 population throughout the decade – PUMAs that fall “substantially below” the 100,000 person threshold will be combined with one or more adjacent PUMAs 4 PUMA Types • Only one level of “standard” PUMA • Place-of-work PUMAs (POW PUMAs) and migration PUMAs (MIG PUMAs) are proposed to be county based, consisting of: – a single PUMA for county-based PUMAs – a combination of adjacent tract based-PUMAs so that together the PUMAs compose one or more complete counties Boundary Symbology PUMA 1 PUMA 2 County B County Tract-based PUMA County A PUMA 3 POW PUMA & MIG PUMA 5 POW PUMA I and MIG PUMA I PUMA Composition • All PUMA types (standard, POW, and MIG) must nest within states • PUMAs will be based on aggregations of counties and census tracts only • Tract-based PUMAs may cross county boundaries as long as each county part contains at least 2,400 people • Incorporated places and MCDs will not be used as building blocks for 2010 PUMAs. -
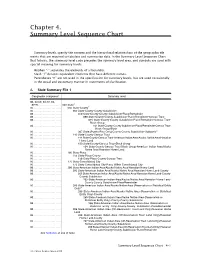
Chapter 4. Summary Level Sequence Chart
Chapter 4. Summary Level Sequence Chart Summary levels specify the content and the hierarchical relationships of the geographic ele- ments that are required to tabulate and summarize data. In the Summary Level Sequence Chart that follows, the summary level code precedes the summary level area, and symbols are used with special meaning for summary levels. Hyphen ‘‘-’’ separates the elements of a hierarchy. Slash ‘‘/’’ denotes equivalent elements that have different names. Parentheses ‘‘()’’ are not used in the specification for summary levels, but are used occasionally in the usual and customary manner in statements of clarification. A. State Summary File 1 Geographic component Summary level 00, 52-59, 64-79, 84, 89-95 . 040 State1 00 . 050 State-County2 00 . 060 State-County-County Subdivision 00 . 070 State-County-County Subdivision-Place/Remainder 00 . 080 State-County-County Subdivision-Place/Remainder-Census Tract 00 . 091 State-County-County Subdivision-Place/Remainder-Census Tract- Block Group 00 . 101 State-County-County Subdivision-Place/Remainder-Census Tract- Block Group-Block 00 . 067 State [Puerto Rico Only]-County-County Subdivision-Subbarrio3 00 . 140 State-County-Census Tract 00 . 144 State-County-Census Tract-American Indian Area/Alaska Native Area/Hawaiian Home Land 00 . 150 State-County-Census Tract-Block Group 00 . 154 State-County-Census Tract-Block Group-American Indian Area/Alaska Native Area/Hawaiian Home Land 00 . 160 State-Place 00 . 155 State-Place-County 00 . 158 State-Place-County-Census Tract 00 . 170 State-Consolidated City 00 . 172 State-Consolidated City-Place Within Consolidated City 00 . 280 State-American Indian Area/Alaska Native Area/Hawaiian Home Land 00 .