Fault Detection on Power System Transmission Line Using Artificial Neural Network (A Comparative Case Study of Onitsha – Awka – Enugu Transmission Line
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PRESS RELEASE June 25, 2021 for Immediate Release U.S. Embassy
United States Diplomatic Mission to Nigeria, Public Affairs Section Plot 1075, Diplomatic Drive, Central Business District, Abuja Telephone: 09-461-4000. Website at http://nigeria.usembassy.gov PRESS RELEASE June 25, 2021 For Immediate Release U.S. Embassy Abuja Partners Channels Academy to Train Conflict Reporters The U.S. Embassy Abuja, in partnership with Channels Academy, has trained over 150 journalists on Conflict Reporting and Peace Journalism. In her opening remarks, the U.S. Embassy Spokesperson/Press Attaché Jeanne Clark noted that the United States recognized that security challenges exist in many forms throughout the country, and that journalists are confronted with responsibility to prioritize physical safety in addition to meeting standards of objectivity and integrity in conflict. She urged the journalists to share their experiences throughout the course of the three-day seminar and encouraged participants to identify new ways to address these security challenges. The trainer Professor Steven Youngblood from the U.S. Center for Global Peace Journalism – Park University defined and presented principles for peace journalism in conflict reporting. He cautioned journalists to refrain from what he termed war journalism. He said, "war journalism is a pattern of media coverage that includes overvaluing violent, reactive responses to conflict while undervaluing non-violent, developmental responses.” The Provost of Channels Academy, Mr Kingsley Uranta, showed appreciation for the continuous partnership with the U.S. Embassy and for bringing such training opportunities to Nigerian journalists. He also called on conflict reporters to be peace ambassadors. The training took place virtually via Zoom on June 22 – 24, 2021. Journalists converged in American Spaces in Abuja, Kano, Bauchi Sokoto, Maiduguri, Awka, and Ibadan. -

A Study of Awka Metropolis Anambra State, Nigeria
International Journal of Business and Social Science Vol. 7, No. 5; May 2016 Urban Poverty Incidence in Nigeria: A Study of Awka Metropolis Anambra State, Nigeria Mbah, Stella I., Ph.D Department of Business Administration Chukwuemeka Odumegwu Ojukwu University Igbariam, Anambra State Nigeria Mgbemena, Gabriel C. Department of Business Administration Chukwuemeka Odumegwu Ojukwu University Igbariam, Anambra State Nigeria Ejike, Daniel C. Department of Business Administration Chukwuemeka Odumegwu Ojukwu University Igbariam, Anambra State Nigeria Abstract This study examined poverty situation in Awka metropolis of Anambra State, Nigeria, using the P-alpha class of poverty measure. To achieve this objective, a structured questionnaire was administered to 399 heads of households selected from mixed socio-economic backgrounds. The study revealed that 49 percent of the respondents were considered to be poor, with 0.17 poverty gap index and a 0.03 severity of poverty index. However, the indicators were considered to be modest when compared with the national rates. The causes of poverty in Awka metropolis include: lack or inadequate supply of some identified basic necessities of life such as shelter, potable water, and sanitation, basic healthcare services, electricity and educational services. As a result of these inadequacies, there are psychological distress, increase in destitution, child labour, violent crime, and prostitution. It was therefore recommended among others that government should step up public investment in urban infrastructure, provision of credit facilities, involvement of the people in development decision that affects their lives or participatory budgetary process and most especially, good governance at the municipal level with accountability and transparency to stamp out corrupt tendencies which has inhibited past developmental efforts of the government. -

Nigeria's Constitution of 1999
PDF generated: 26 Aug 2021, 16:42 constituteproject.org Nigeria's Constitution of 1999 This complete constitution has been generated from excerpts of texts from the repository of the Comparative Constitutions Project, and distributed on constituteproject.org. constituteproject.org PDF generated: 26 Aug 2021, 16:42 Table of contents Preamble . 5 Chapter I: General Provisions . 5 Part I: Federal Republic of Nigeria . 5 Part II: Powers of the Federal Republic of Nigeria . 6 Chapter II: Fundamental Objectives and Directive Principles of State Policy . 13 Chapter III: Citizenship . 17 Chapter IV: Fundamental Rights . 20 Chapter V: The Legislature . 28 Part I: National Assembly . 28 A. Composition and Staff of National Assembly . 28 B. Procedure for Summoning and Dissolution of National Assembly . 29 C. Qualifications for Membership of National Assembly and Right of Attendance . 32 D. Elections to National Assembly . 35 E. Powers and Control over Public Funds . 36 Part II: House of Assembly of a State . 40 A. Composition and Staff of House of Assembly . 40 B. Procedure for Summoning and Dissolution of House of Assembly . 41 C. Qualification for Membership of House of Assembly and Right of Attendance . 43 D. Elections to a House of Assembly . 45 E. Powers and Control over Public Funds . 47 Chapter VI: The Executive . 50 Part I: Federal Executive . 50 A. The President of the Federation . 50 B. Establishment of Certain Federal Executive Bodies . 58 C. Public Revenue . 61 D. The Public Service of the Federation . 63 Part II: State Executive . 65 A. Governor of a State . 65 B. Establishment of Certain State Executive Bodies . -

Civil War 1968-1970
Copyright by Roy Samuel Doron 2011 The Dissertation Committee for Roy Samuel Doron Certifies that this is the approved version of the following dissertation: Forging a Nation while losing a Country: Igbo Nationalism, Ethnicity and Propaganda in the Nigerian Civil War 1968-1970 Committee: Toyin Falola, Supervisor Okpeh Okpeh Catherine Boone Juliet Walker H.W. Brands Forging a Nation while losing a Country: Igbo Nationalism, Ethnicity and Propaganda in the Nigerian Civil War 1968-1970 by Roy Samuel Doron B.A.; M.A. Dissertation Presented to the Faculty of the Graduate School of The University of Texas at Austin in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy The University of Texas at Austin August 2011 Forging a Nation while losing a Country: Igbo Nationalism, Ethnicity and Propaganda in the Nigerian Civil War 1968-1970 Roy Samuel Doron, PhD The University of Texas at Austin, 2011 Supervisor: Toyin Falola This project looks at the ways the Biafran Government maintained their war machine in spite of the hopeless situation that emerged in the summer of 1968. Ojukwu’s government looked certain to topple at the beginning of the summer of 1968, yet Biafra held on and did not capitulate until nearly two years later, on 15 January 1970. The Ojukwu regime found itself in a serious predicament; how to maintain support for a war that was increasingly costly to the Igbo people, both in military terms and in the menacing face of the starvation of the civilian population. Further, the Biafran government had to not only mobilize a global public opinion campaign against the “genocidal” campaign waged against them, but also convince the world that the only option for Igbo survival was an independent Biafra. -

Purple Hibiscus
1 A GLOSSARY OF IGBO WORDS, NAMES AND PHRASES Taken from the text: Purple Hibiscus by Chimamanda Ngozi Adichie Appendix A: Catholic Terms Appendix B: Pidgin English Compiled & Translated for the NW School by: Eze Anamelechi March 2009 A Abuja: Capital of Nigeria—Federal capital territory modeled after Washington, D.C. (p. 132) “Abumonye n'uwa, onyekambu n'uwa”: “Am I who in the world, who am I in this life?”‖ (p. 276) Adamu: Arabic/Islamic name for Adam, and thus very popular among Muslim Hausas of northern Nigeria. (p. 103) Ade Coker: Ade (ah-DEH) Yoruba male name meaning "crown" or "royal one." Lagosians are known to adopt foreign names (i.e. Coker) Agbogho: short for Agboghobia meaning young lady, maiden (p. 64) Agwonatumbe: "The snake that strikes the tortoise" (i.e. despite the shell/shield)—the name of a masquerade at Aro festival (p. 86) Aja: "sand" or the ritual of "appeasing an oracle" (p. 143) Akamu: Pap made from corn; like English custard made from corn starch; a common and standard accompaniment to Nigerian breakfasts (p. 41) Akara: Bean cake/Pea fritters made from fried ground black-eyed pea paste. A staple Nigerian veggie burger (p. 148) Aku na efe: Aku is flying (p. 218) Aku: Aku are winged termites most common during the rainy season when they swarm; also means "wealth." Akwam ozu: Funeral/grief ritual or send-off ceremonies for the dead. (p. 203) Amaka (f): Short form of female name Chiamaka meaning "God is beautiful" (p. 78) Amaka ka?: "Amaka say?" or guess? (p. -

South – East Zone
South – East Zone Abia State Contact Number/Enquires ‐08036725051 S/N City / Town Street Address 1 Aba Abia State Polytechnic, Aba 2 Aba Aba Main Park (Asa Road) 3 Aba Ogbor Hill (Opobo Junction) 4 Aba Iheoji Market (Ohanku, Aba) 5 Aba Osisioma By Express 6 Aba Eziama Aba North (Pz) 7 Aba 222 Clifford Road (Agm Church) 8 Aba Aba Town Hall, L.G Hqr, Aba South 9 Aba A.G.C. 39 Osusu Rd, Aba North 10 Aba A.G.C. 22 Ikonne Street, Aba North 11 Aba A.G.C. 252 Faulks Road, Aba North 12 Aba A.G.C. 84 Ohanku Road, Aba South 13 Aba A.G.C. Ukaegbu Ogbor Hill, Aba North 14 Aba A.G.C. Ozuitem, Aba South 15 Aba A.G.C. 55 Ogbonna Rd, Aba North 16 Aba Sda, 1 School Rd, Aba South 17 Aba Our Lady Of Rose Cath. Ngwa Rd, Aba South 18 Aba Abia State University Teaching Hospital – Hospital Road, Aba 19 Aba Ama Ogbonna/Osusu, Aba 20 Aba Ahia Ohuru, Aba 21 Aba Abayi Ariaria, Aba 22 Aba Seven ‐ Up Ogbor Hill, Aba 23 Aba Asa Nnetu – Spair Parts Market, Aba 24 Aba Zonal Board/Afor Une, Aba 25 Aba Obohia ‐ Our Lady Of Fatima, Aba 26 Aba Mr Bigs – Factory Road, Aba 27 Aba Ph Rd ‐ Udenwanyi, Aba 28 Aba Tony‐ Mas Becoz Fast Food‐ Umuode By Express, Aba 29 Aba Okpu Umuobo – By Aba Owerri Road, Aba 30 Aba Obikabia Junction – Ogbor Hill, Aba 31 Aba Ihemelandu – Evina, Aba 32 Aba East Street By Azikiwe – New Era Hospital, Aba 33 Aba Owerri – Aba Primary School, Aba 34 Aba Nigeria Breweries – Industrial Road, Aba 35 Aba Orie Ohabiam Market, Aba 36 Aba Jubilee By Asa Road, Aba 37 Aba St. -

Growth of the Catholic Church in the Onitsha Province Op Eastern Nigeria 1905-1983 V 14
THE CONTRIBUTION OP THE LAITY TO THE GROWTH OF THE CATHOLIC CHURCH IN THE ONITSHA PROVINCE OP EASTERN NIGERIA 1905-1983 V 14 - I BY REV. FATHER VINCENT NWOSU : ! I i A THESIS SUBMITTED FOR THE DOCTOR OP PHILOSOPHY , DEGREE (EXTERNAL), UNIVERSITY OF LONDON 1988 ProQuest Number: 11015885 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a com plete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest ProQuest 11015885 Published by ProQuest LLC(2018). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States C ode Microform Edition © ProQuest LLC. ProQuest LLC. 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106- 1346 s THE CONTRIBUTION OF THE LAITY TO THE GROWTH OF THE CATHOLIC CHURCH IN THE ONITSHA PROVINCE OF EASTERN NIGERIA 1905-1983 By Rev. Father Vincent NWOSU ABSTRACT Recent studies in African church historiography have increasingly shown that the generally acknowledged successful planting of Christian Churches in parts of Africa, especially the East and West, from the nineteenth century was not entirely the work of foreign missionaries alone. Africans themselves participated actively in p la n tin g , sustaining and propagating the faith. These Africans can clearly be grouped into two: first, those who were ordained ministers of the church, and secondly, the lay members. -

Analysis of Nigerian Hydrometeorological Data
Nigerian Journal of Technology, Vol. 22, No. 1, March 2003 Dike & Nwachukwu 29 ANALYSIS OF NIGERIAN HYDROMETEOROLOGICAL DATA By Dike, B. U. and Nwachukwu, B.A. Department of Civil Engineering Federal University of Technology, Owerri ABSTRACT Rainfall and runoff like most hydrologic events are governed by the laws of chance; hence, their predictions cannot be done in absolute terms. Since there is no universally accepted method for determining the likelihood of a certain magnitude of rainfall or runoff, common probabilistic models were used in this research to predict the magnitude and frequency of their occurrence. Missing records were determined by the mass curve analysis for rainfall and regression analysis for runoff involving runoff data at neighbouring site. Tests on time homogeneity, showed that the annual rainfall records at Port Harcourt, Enugu and Lokoja were stationary and random, the annual runoff records of River Niger at Onitsha, Lokoja and Baro were non-stationary, showing a decreasing trend of mean annual runoff. Various models were tested for suitability in predictions of annual rainfall at Port Harcourt, Enugu and Lokoja, also for annual runoff of River Niger at Onitsha, Lokoja and Baro. The mean annual rainfall was found to diminish from the coast to inland with values' of 2, 400, 1, 700, and 1,200mm for Port Harcourt, Enugu and Lokoja respectively. The mean annual runoff for River Niger at Onitsha, Lokoja and Baro were 117, 000, 169, 300, and 60, 525 Mm3 respectively. The application of the models showed that the lognormal distribution should be adopted for predictions of annual rainfall at Port Harcourt and Lokoja and annual runoff of River Niger at Onitsha and Lokoja, The normal distribution should be adopted for predictions of annual rainfall at Enugu and annual runoff of River Niger at Baro. -

THE ARCHITECTURE of the URBAN FRONTS, the CASE of URBAN EXPERIENCE and PRESSURE on the INFRASTRUCTURE -- Bons N
Mgbakoigba, Journal of African Studies. Vol.7, No.2. June 2018 THE ARCHITECTURE OF THE URBAN FRONTS, THE CASE OF URBAN EXPERIENCE AND PRESSURE ON THE INFRASTRUCTURE -- Bons N. Obiadi, Nzewi, N.U. The Architecture of the Urban Fronts, the Case of Urban Experience and Pressure on the Infrastructure. Bons N. Obiadi Department of Architecture Nnamdi Azikiwe University, Awka and Nzewi, N.U. Department of Architecture Nnamdi Azikiwe University, Awka Abstract: A generalized perception of Architecture locates the discipline within the narrow boundaries of design and erection of buildings. While this may be acceptable in certain quarters, the fact remains that the spatial emergence and generic function guiding the relationship between human beings and space have, for centuries, guided the architecture of cities. Architecture, according to definitions, is practiced by licensed professionals in the industry however; literature has proven that almost everyone practices architecture in different ways and not, exclusively limiting to the design and erection of buildings. The dumping of communities solid wastes redefine the configuration of the area's environment and it is architectural, and deals with human beings and spaces. The design, construction and erection of roads, bridges and community street security gates are architectural and negatively impacting on the environment and particularly, architecture of the area. Objectively, the aim of this study is to create awareness and point to the fact, that the Nigerian players (policy makers) have in the past, designed models to direct positive growth and development in the country, but failed to properly implement the programmes and that is detrimental to the country's built environment and especially, architecture and infrastructure. -
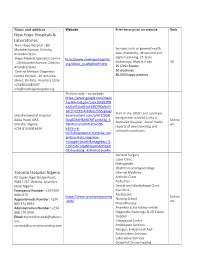
LIST-OF-ONITSHA-HOSPITALS.Pdf
Name and address Website Brief description on website Beds New Hope Hospitals & Laboratories New Hope Hospital - 80 Modebe Avenue, Onitsha, Services such as general health Anambra State. care, maternity, ultrasound and digital scanning, CT-Scan, Hope Medical Specialist Centre http://www.newhopehospital. Endoscopy, Mobile X-ray 30 - 104 Modebe Avenue, Onitsha, org/about_us.php#overview Anambra State. 35 Clinic Rooms Onitsha Medical Diagnostic 30 machines Centre Limited - 26 Umunna 85,000 happy patients Street, Onitsha, Anambra State. +2348033045697 [email protected] Pictures only – no website https://www.google.com/maps /uv?hl=en&pb=!1s0x104392ff8 ea21ef3:0xc93a53987f90d9e5! 3m1!7e115!4shttps://lh5.googl Built in the 1950’s and attempts Onitsha General Hospital eusercontent.com/p/AF1QipN being made to build it into a Awka Road, GRA Oav0OAeH3jkRCRJTyadzd3g_A Unkno Specialist Hospital. Social media Onitsha, Nigeria F8nWoz-jmeRn%3Dw585- wn reports of overcrowding and +234 816 908 6619 h393-n-k- unhealth conditions. no!5shospitals+in+Onitsha,+an ambra+state,+nigeria+- +Google+Search&imagekey=!1 e10!2sAF1QipNOav0OAeH3jkR CRJTyadzd3g_AF8nWoz-jmeRn General Surgery Laser Clinic Orthopedics Obstetrics and Gynecology Toronto Hospital Nigeria Internal Medicine #2 Upper Niger Bridge Road, Arthritis Clinic PMB 1767, Onitsha, Anambra Pediatrics State Nigeria Dental and Maxillofacial Clinic Emergency Number: +234 909 Eye Clinic Restaurant 000 0379 https://www.torontohospitalng Unkno Nursing School Appointments Number: +234 .com/ wn 803 374 6994 -

Climate Change and Groundwater Resources of Part of Lower Niger Sub- Basin Around Onitsha, Nigeria Okoyeh, E.I., Okeke, H.C., Nwokeabia, C.N., Ezenwa, S.O
International Journal of Scientific & Engineering Research, Volume 6, Issue 9, Septeber-2015 1463 ISSN 2229-5518 Climate Change and Groundwater Resources of Part of Lower Niger Sub- Basin around Onitsha, Nigeria Okoyeh, E.I., Okeke, H.C., Nwokeabia, C.N., Ezenwa, S.O. and Enekwechi, E.K. Abstract— The impact of climate change on water resources and the environment is on the increase and has resulted to the increased de- pendence on unprotected surface and groundwater resources. The study tends to evaluate the aquifer behaviour of the Benin Formation of Southeastern, Nigeria with the view of establishing the impact of the climate change on groundwater resources of part of lower Niger Sub- Basin. Since the hydrology of aquifer and health of the ecosystem are closely connected, understanding the water resources of a system will enable its management in an integrated manner to ensure the sustainability of the ecosystem and the water it provides. The water bearing formation of the study area consist mostly of continental sands and gravels with hydraulic conductivity ranging from 4.9m/day to 33.99m/day. This forms the major aquifer in parts of the Lower Niger Sub Basin. The depth to the watertable lies between 2m and 8m near the coast and deepens inland to over 150m. The Niger River with a discharge of about 4000m3/s at Onitsha recharges the aquifer in the month of September than other times of the year. Increasing rate of erosion in the coastal areas of the Lower Niger Sub-Basin along the Niger River and Anambra River around Onitsha with its socioeconomic consequences is attributed to climate change and requires urgent attention. -

Dictionary of Ò,Nì,Chà Igbo
Dictionary of Ònìchà Igbo 2nd edition of the Igbo dictionary, Kay Williamson, Ethiope Press, 1972. Kay Williamson (†) This version prepared and edited by Roger Blench Roger Blench Mallam Dendo 8, Guest Road Cambridge CB1 2AL United Kingdom Voice/ Fax. 0044-(0)1223-560687 Mobile worldwide (00-44)-(0)7967-696804 E-mail [email protected] http://www.rogerblench.info/RBOP.htm To whom all correspondence should be addressed. This printout: November 16, 2006 TABLE OF CONTENTS Abbreviations: ................................................................................................................................................. 2 Editor’s Preface............................................................................................................................................... 1 Editor’s note: The Echeruo (1997) and Igwe (1999) Igbo dictionaries ...................................................... 2 INTRODUCTION........................................................................................................................................... 4 1. Earlier lexicographical work on Igbo........................................................................................................ 4 2. The development of the present work ....................................................................................................... 6 3. Onitsha Igbo ................................................................................................................................................ 9 4. Alphabetization and arrangement..........................................................................................................