Aleksandar Janjić FRAMEWORK FOR
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Kinky King's Heath Press Release
Press Release King's Heath gets Kinda Kinky! Special Concert on Sunday 7 July will celebrate The Kinks' famous Ritz Ballroom Performance Fans of The Kinks are being invited to come and get Kinky in King's Heath on Sunday 7 July and celebrate a legendary performance by the group at the former Ritz Ballroom that was gutted by fire earlier this year. Brothers Ray and Dave Davies brought The Kinks to the Ritz in June 1966 and included in their line-up for the first time was John Dalton after regular bass guitarist Pete Quaife broke his leg in a car accident. Appearing only two days after being recruited, John had virtually no time to practice. Three years later he would re-join as a permanent member. The Kinks' appearance at The Ritz came just after they released "Sunny Afternoon" which became their third No. 1 hit in the UK singles charts. The group went on to have a total of seventeen Top Twenty singles including “Dedicated Follower of Fashion”, “Waterloo Sunset” and “Lola” and five Top Ten albums starting with “Kinda KInks” Fletchers Bar on York Road directly opposite the former ballroom on York Road, King's Heath will host the “All Things Kinky” event from 4 p.m. to 7 p.m. Top and emerging local musicians including Ben Calvert, Mr Apollo, Robert Lane, James Connolly and Harriet Harkcom will give their own unique interpretation of their favourite Kinks' songs. Advance tickets are now on sale and cost just £2.50 from the Kitchen Garden Cafe on York Road or www.wegottickets.com . -

The Carroll News
John Carroll University Carroll Collected The aC rroll News Student 4-29-1977 The aC rroll News- Vol. 59, No. 17 John Carroll University Follow this and additional works at: http://collected.jcu.edu/carrollnews Recommended Citation John Carroll University, "The aC rroll News- Vol. 59, No. 17" (1977). The Carroll News. 568. http://collected.jcu.edu/carrollnews/568 This Newspaper is brought to you for free and open access by the Student at Carroll Collected. It has been accepted for inclusion in The aC rroll News by an authorized administrator of Carroll Collected. For more information, please contact [email protected]. VOL. 59, NO. 17 APR. 29, 1977 The Carroll Nevvs John Carroll University University Heights, Ohio 44118 British politics discussed By John F. Kostyo several acts of Parliament re- Speaking of the increasing News Editor garding the exploration and influence of the Scotish Na As thousands of gallons of exploitation of oil reserves in Uonalist Party, "Scotland," crude oil continued to pour the North Sea, Douglas enter· Douglas said, "would be more from a blownout drilling plat tained his audience with viable than Wales as a nation form in the North Sea off the numerous jokes and keen in- state." coast of Norway, the Political sights into contemporary Brit "What the Party is saying," Science Club presented Mr. ish politics. continued Douglas, "is that if Richard Douglas, a specialist "A benefit of North Sea oil," we get a majority of seats, we on Noth Sea oil, who spoke on said Douglas, "is at least 30 wilJ sue for independence." several related topics Tuesday years of self-sufficiency for Voicing his disapproval of the afternoon in the Jardine the United Kingdom." He was plan, Douglas warned that a Room. -

October 18, 1979
OCTO ' BE~ 18, 1979 ISSUE 353 '- _. UNIVERSITY Of MISSOURI/SAINT LOUIS - Homecoming not ready for burial "The only thing we are not Rick.Jackoway going to have is a dinner," Blanton explained. Also the tra In a grave message to UMSL ditional soccer game will not be students, a tombstone was e involved in this year's festivities. rected last week near the out This year, Blanton said, the . door basketball court. homecoming will be part of a Etched on the tombstone are spirit week from Nov. 26 to 3~. the words " R.LP./UMSLlHC/ There will be some sort of social 1979/ Do you care?" Much spec· function where the king and ulation centered over who or Queen of homecoming will be what is He. But for some people announced, he said. But the the meaning was quite clear. traditional dinner/ dance will not For the past few months there be included because of lack of has been much concern about funds. the future of homecoming at The Student Budget Commit UMSL. The tombstone caused tee, Blanton explained, cut out more vocal discussion of home dinner subsidies for all organiza coming. tions. But, to abuse an old line, the Blanton said the Second An . reports of homecomings death nual Boat Race, an intercollegate .. PAYING HOMAGE: Curious students view a grave marldng the rumored death of UMSL Homecoming are ·greatly exagerated, accord tug-of-war, and other activities activities. Despite the monument's ImpUcations, such activities will be held this year [photo by WOey ing to Rick Blanton, director ' of will be included during Spirit PrIce]. -

THE ORCHESTRA in BILBAO by Victor Barba Gomez
THE ORCHESTRA IN BILBAO by Victor Barba Gomez Last August 27th, the band played in Bilbao City situated in the North of Spain. It was the Festivities of the city, called ASTE NAGUSIA, and every day of the week were concerts in the city, in different stages and THE ORCHESTRA played in the main stage, in front of almost 8.000 people. This show was the main of the week, closing the Festivities. After the Fireworks, people were arriving to enjoy the wonderful sound of the guys that began at 12.00 in the night in a big stage with two screens. In charge of the sound was Dennis with the local crew. It was the first time that the band was playing in Bilbao, but not for Mik, who played in 1975 with ELO in his first tour in Spain. Before the sound check, the three vocalists Eric, Hux and Glen, were rehearsing together. While the band was in the rehearsals, some fans and public were approaching the stage to see the band, as a prelude of the massive attendance that later came to the show. There were press, TV cameras photographs, waiting the magic moment Opening the show with the intro and Twilight, soon the audience was handed over to the band’s songs. Glen, in Basque language, said hello to the attendance. The audience thanked this gesture. After Twilight, came All Over the World, R&R is King, Evil Woman, Sweet Talking Woman, Hold on Tight, Mama Belle, Showdown and Rockaria. Then was moment for the Intros, and Hux presented the members of the band. -

Entertain Ent 'Gatsby' a Spectacular Disappointment and a Case of Mistaken Identity Premonition Was Correct
Pa.ge 14, The Retriever, April 22, 1974 Entertain_ent 'Gatsby' a spectacular disappointment and a case of mistaken identity premonition was correct. Mia. For those planning to see the new Sam Waterston delivered a good (Gatsby for Tom), at the time of her Farrow, an appreciably better Daisy,' performance as Nick, but the ly released film version of The Great' death. was good, but Mia Farrow is Mia Gatsby, having been taken by' the . Robert Redford portraying the Farrow and a star actress she is not. novel, several words of caution: character appears to be so pathetic desperate Jay Gatsby is as credible Managing to convey Daisy that he is almost repulsive by the end prepare to be disappointed. The as John Wayne attempting the role of fairly well, there is still enough Paramount film, despite a $6.4 million of the movie. Bruce Dern as Tom-is Father Carras (Exorcist). Redford 'lacking in her "money-voiced another major example of poor budget and a reputable cast of himself realized the possibility of elegance" to make one feel that she casting; Tom Buchanan is supposedly character.s, falls short of portrayingi criticism of his part ;unfortunately his ,short-changes the role. a big, athletic, aggressive individual, the of the most widely ~yshque but Dern appears for' the most part ac~lalmed F. Scott Fitzgerald work., SImply e~ough the film's main ."Tartuffe" opens passive and beaten. pr?blem is following too closely to the novel. Much of the dialogue is lifted Without a doubt, the finest act verbatum from the novel, whict next at theater ing should be credited to Karen Black and Scott Wilson. -

Feb 2017 FREE Lamb & Flag the Tything, Worcester, WR1 1JL Fantastic Food, Superior Craft Ales & Exceptional Guinness
Issue 66 Feb 2017 FREE Lamb & Flag The Tything, Worcester, WR1 1JL Fantastic Food, Superior Craft Ales & Exceptional Guinness... Folk Music, Poetry Conkers! Local Cider, Backgammon, Tradition We Have It All!! Italian Inspired Cuisine Open 7 Days - Parties & Functions Catered For [email protected] Tel: 01905 729415 www.twocraftybrewers.co.uk Hello everyone and a belated ‘Happy New Year’ to you all! Welcome to issue 66 as we head into our seventh year of SLAP publication. I would usually at this point write with optimism as we look forward to the year ahead, but these are strange times folks and we’re living a very uncertain world. Global political instability and economic uncertainty are likely to make 2017 a tricky year for most of us. That said, let’s at least look ahead at the positives locally... In Feb2017 this issue we bring you news of Hereford’s bid for City of Culture 2021. This initiative whether successful or not can only be a good thing, breathing new life and ideas into the area. Talking of things Hereford, we say a fond farewell, for the time being at least, and a huge thank you to Naomi and Oli at Circuit SLAP MAGAZINE Sweet who have been for many years good friends of SLAP, writing, distributing and generally supporting. Their duties in these Unit 3a, Lowesmoor Wharf, areas will fall to the lovely people at Hereford’s Underground Worcester WR1 2RS Revolution who are themselves doing great work promoting and Telephone: 01905 26660 supporting the local music scene. [email protected] We at SLAP are proud to support new local promoter Samantha Daly with her UnCover Indie club night. -

Box Office 0121 704 6962
SUMMER •AUTUMN 2016 BOX OFFICE 0121 704 6962 E 27 thecoretheatresolihull.co.uk E PAG R - SE ELLIE TAYLO 2 PANTOMIME Box Office 0121 704 6962 Join Dick and his cat on their adventures as DATE MORNING MATINEE EVENING they run away to London looking for their Friday 9 Dec 7pm fortune but end up at t he docks setting sail Saturday 10 Dec 2.30pm 7pm for... well... goodness knows where! Dick makes some good friends including Sarah the Sunday 11 Dec 11am 3pm Cook, but oh dear!... that pesky King Rat has Monday 12 Dec N O S H O W S stowed away on board too with some of his Tuesday 13 Dec School School sneaky gang! Wednesday 14 Dec School School Action, adventure, secrets, songs, dancing, Thursday 15 Dec School School trickery, romance, swash-buckling sailors and rogue-ish rats aplenty in this sparkling Friday 16 Dec 2.30pm 7pm pantomime show at the newly refurbished and Saturday 17 Dec 11am 3pm renamed Core Theatre Solihull (formerly Solihull Sunday 18 Dec 11am 3pm Arts Complex). Monday 19 Dec N O S H O W S Now in it’s 25th year, this much-loved show is written by and stars Malcolm Stent accompanied Tuesday 20 Dec 11am 3pm by a professional ensemble cast of actors and Wednesday 21 Dec 11am 3pm dancers.With it’s unique local references, Thursday 22 Dec 2.30pm 7pm intimate auditorium - where no-one is more than 15 rows from the front, and amusing audience Friday 23 Dec 2.30pm 7pm interactions the show delights audiences and Saturday 24 Dec 10.30am 2.30pm critics year after year. -

HOUSE of REPRESENTATIVES Pennsylvania? Remarks
1356 CONGRESSIONAL RECORD- HOUSE February 24 demonstrated their interest in such work, elusion of the reading of the joint resolution Mr. Speaker, some people think the and that safeguards be set up preventing de for amendment, the Committee shall rise American farmer has too long been pam pletion of such labor; to the Committee on and report the same· to the House with such pered by the farm policies of the Demo Armed Services. amendments as may have been adopted, and 67. By the SPEAKER:· Petition of Ameri the previous question shall be considered as cratic Party. As individuals, should can Bar Association, Chicago, Ill., relative to ordered on the joint resolution and amend farmers learn not to lean upon Govern the adoption of a resolution upon the recom ments thereto to final passage without ment for. assistance? mendation of its section of international and intervening motion except one motion to The policies of the Republican Secre comparative law, at its meeting held in San recommit. tary of Agriculture are clear to me. He Francisco, September 15, 1952; to the Com has outlined his program with frankness mittee on Foreign Affairs. and sincerity. I am sure that unless 68. Also, petition of National Jewish COMMITTEE ON EDUCATION AND Youth Conference, New York City, N. Y., rel• LABOR selfish farm leaders create confusion, ative to a resolution adopted by the execu the American farmer will understand tive committee of the National Youth Con Mr. McCONNELL. Mr. Speaker, I ask that the end of artificial price-support ference at a meeting in washington, D . -

Omer Avital Ed Palermo René Urtreger Michael Brecker
JANUARY 2015—ISSUE 153 YOUR FREE GUIDE TO THE NYC JAZZ SCENE NYCJAZZRECORD.COM special feature BEST 2014OF ICP ORCHESTRA not clowning around OMER ED RENÉ MICHAEL AVITAL PALERMO URTREGER BRECKER Managing Editor: Laurence Donohue-Greene Editorial Director & Production Manager: Andrey Henkin To Contact: The New York City Jazz Record 116 Pinehurst Avenue, Ste. J41 JANUARY 2015—ISSUE 153 New York, NY 10033 United States New York@Night 4 Laurence Donohue-Greene: [email protected] Interview : Omer Avital by brian charette Andrey Henkin: 6 [email protected] General Inquiries: Artist Feature : Ed Palermo 7 by ken dryden [email protected] Advertising: On The Cover : ICP Orchestra 8 by clifford allen [email protected] Editorial: [email protected] Encore : René Urtreger 10 by ken waxman Calendar: [email protected] Lest We Forget : Michael Brecker 10 by alex henderson VOXNews: [email protected] Letters to the Editor: LAbel Spotlight : Smoke Sessions 11 by marcia hillman [email protected] VOXNEWS 11 by katie bull US Subscription rates: 12 issues, $35 International Subscription rates: 12 issues, $45 For subscription assistance, send check, cash or money order to the address above In Memoriam 12 by andrey henkin or email [email protected] Festival Report Staff Writers 13 David R. Adler, Clifford Allen, Fred Bouchard, Stuart Broomer, CD Reviews 14 Katie Bull, Tom Conrad, Ken Dryden, Donald Elfman, Brad Farberman, Sean Fitzell, Special Feature: Best Of 2014 28 Kurt Gottschalk, Tom Greenland, Alex Henderson, Marcia Hillman, Miscellany Terrell Holmes, Robert Iannapollo, 43 Suzanne Lorge, Marc Medwin, Robert Milburn, Russ Musto, Event Calendar 44 Sean J. O’Connell, Joel Roberts, John Sharpe, Elliott Simon, Andrew Vélez, Ken Waxman As a society, we are obsessed with the notion of “Best”. -
Mark Summers Sunblock Sunburst Sundance
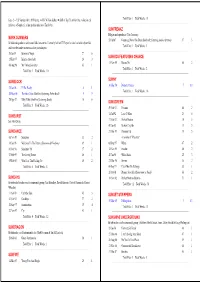
Key - $ = US Number One (1959-date), ✮ UK Million Seller, ➜ Still in Top 75 at this time. A line in red Total Hits : 1 Total Weeks : 11 indicates a Number 1, a line in blue indicate a Top 10 hit. SUNFREAKZ Belgian male producer (Tim Janssens) MARK SUMMERS 28 Jul 07 Counting Down The Days (Sunfreakz featuring Andrea Britton) 37 3 British male producer and record label executive. Formerly half of JT Playaz, he also had a hit a Souvlaki and recorded under numerous other pseudonyms Total Hits : 1 Total Weeks : 3 26 Jan 91 Summers Magic 27 6 SUNKIDS FEATURING CHANCE 15 Feb 97 Inferno (Souvlaki) 24 3 13 Nov 99 Rescue Me 50 2 08 Aug 98 My Time (Souvlaki) 63 1 Total Hits : 1 Total Weeks : 2 Total Hits : 3 Total Weeks : 10 SUNNY SUNBLOCK 30 Mar 74 Doctor's Orders 7 10 21 Jan 06 I'll Be Ready 4 11 Total Hits : 1 Total Weeks : 10 20 May 06 The First Time (Sunblock featuring Robin Beck) 9 9 28 Apr 07 Baby Baby (Sunblock featuring Sandy) 16 6 SUNSCREEM Total Hits : 3 Total Weeks : 26 29 Feb 92 Pressure 60 2 18 Jul 92 Love U More 23 6 SUNBURST See Matt Darey 17 Oct 92 Perfect Motion 18 5 09 Jan 93 Broken English 13 5 SUNDANCE 27 Mar 93 Pressure US 19 5 08 Nov 97 Sundance 33 2 A remake of "Pressure" 10 Jan 98 Welcome To The Future (Shimmon & Woolfson) 69 1 02 Sep 95 When 47 2 03 Oct 98 Sundance '98 37 2 18 Nov 95 Exodus 40 2 27 Feb 99 The Living Dream 56 1 20 Jan 96 White Skies 25 3 05 Feb 00 Won't Let This Feeling Go 40 2 23 Mar 96 Secrets 36 2 Total Hits : 5 Total Weeks : 8 06 Sep 97 Catch Me (I'm Falling) 55 1 20 Oct 01 Pleaase Save Me (Sunscreem -

30Th Birmingham International Jazz & Blues Festival July
Photo by Merlin Daleman WWW.BIRMINGHAMJAZZFESTIVAL.COM [email protected] HOTLINE: 0121 454 7020 WWW.BIRMINGHAMJAZZFESTIVALTV.COM TWITTER: @birmjazzfest #brumjazzfest FacebooK.com/birminghamjazzfestival/ www.birminghamjazzfestival.com COUNCILLOR IAN WARD "It is with great pleasure that Birmingham is welcoming the Birmingham International Jazz and Blues Festival for a landmark 30th consecutive year. To mark this occasion the festival is again hosting big names from across the world with 175 performances at over 80 venues across the City. It is particularly impressive to see the festival increasingly attracting musicians from across Europe with France, Hungary, Czech Republic, Italy, Lithuania, Luxembourg, Slovakia and Spain all represented. The festival is an important event in Birmingham’s event calendar and is an opportunity for everyone to see live music and events at different venues making the festival accessible to all. I always enjoy the event and I am looking forward to it again this year. The breadth of Jazz and Blues on offer make this year’s event a must go festival for residents and visitors alike. Let’s hope the Jazz and Blues Festival brings the summer to Birmingham." Ian Ward Deputy Leader of Birmingham City Council Funded by 2 30TH BIRMINGHAM INTERNATIONAL JAZZ & BLUES FESTIVAL 2014 30TH BIRMINGHAM INTERNATIONAL JAZZ & BLUES FESTIVAL 2014 3 ACKNOWLEDGMENTS www.birminghamjazzfestival.com ACKNOWLEDGMENTS Festival Patron: Digby Fairweather Advisory Board: John Hemming MP, Derek Inman, John James, Danny Longstaff, Cllr. Phillip Parkin, John Patrick, THE JAZZ FESTIVAL BOARD Cllr. Rob Sealey Behind this short, sharp celebration of jazz, blues and related music lies many months Festival Director: Jim Simpson Find us on Commercial and Development Director: Tim Jennings facebook.com/birminghamjazzfestival/ of planning and organisation. -

Volume XII-XIII (2013-2015) ______
South Central Music Bulletin XII-XIII (2013-2015) • A Refereed Journal • ISSN 1545-2271 • http://www.scmb.us _________________________________________________________________________________________ South Central Music Bulletin A Refereed, Open-Access Journal ISSN 1545-2271 Volume XII-XIII (2013-2015) __________________________________________________________________________________________ Editor: Dr. Nico Schüler, Texas State University Music Graphics Editor: Richard D. Hall, Texas State University Editorial Review Board: Dr. Paula Conlon, University of Oklahoma Dr. Stacey Davis, University of Texas – San Antonio Dr. Lynn Job, North Central Texas College Dr. Kevin Mooney, Texas State University Dr. Dimitar Ninov, Texas State University Ms. Sunnie Oh, Independent Scholar & Musician Dr. Robin Stein, Texas State University Dr. Leon Stefanija, University of Ljubljana (Slovenia) Dr. Paolo Susanni, Yaşar University (Turkey) Dr. Lori Wooden, University of Central Oklahoma Subscription: Free This Open Access Journal can be downloaded from http://www.scmb.us. Publisher: South Central Music Bulletin http://www.scmb.us Ó Copyright 2015 by the Authors. All Rights Reserved. 1 South Central Music Bulletin XII-XIII (2013-2015) • A Refereed Journal • ISSN 1545-2271 • http://www.scmb.us _________________________________________________________________________________________ Table of Contents Message from the Editor by Nico Schüler … Page 3 Research Article: Using Electric Light Orchestra as a Model for Popular Music Analysis – Part 2: Theoretical Analysis