Applying an Information Gathering Architecture to Netfind: a White Pages Tool for a Changing and Growing Internet
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

List of TCP and UDP Port Numbers from Wikipedia, the Free Encyclopedia
List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the Transport Layer of the Internet Protocol Suite for the establishment of host-to-host communications. Originally, these ports number were used by the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP), but are also used for the Stream Control Transmission Protocol (SCTP), and the Datagram Congestion Control Protocol (DCCP). SCTP and DCCP services usually use a port number that matches the service of the corresponding TCP or UDP implementation if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[1] However, many unofficial uses of both well-known and registered port numbers occur in practice. Contents 1 Table legend 2 Well-known ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Use Description Color Official Port is registered with IANA for the application white Unofficial Port is not registered with IANA for the application blue Multiple use Multiple applications are known to use this port. yellow Well-known ports The port numbers in the range from 0 to 1023 are the well-known ports. They are used by system processes that provide widely used types of network services. On Unix-like operating systems, a process must execute with superuser privileges to be able to bind a network socket to an IP address using one of the well-known ports. -

List of TCP and UDP Port Numbers from Wikipedia, the Free Encyclopedia
List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the transport layer of the Internet Protocol Suite for the establishment of host-to-host connectivity. Originally, port numbers were used by the Network Control Program (NCP) in the ARPANET for which two ports were required for half- duplex transmission. Later, the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) needed only one port for full- duplex, bidirectional traffic. The even-numbered ports were not used, and this resulted in some even numbers in the well-known port number /etc/services, a service name range being unassigned. The Stream Control Transmission Protocol database file on Unix-like operating (SCTP) and the Datagram Congestion Control Protocol (DCCP) also systems.[1][2][3][4] use port numbers. They usually use port numbers that match the services of the corresponding TCP or UDP implementation, if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[5] However, many unofficial uses of both well-known and registered port numbers occur in practice. Contents 1 Table legend 2 Well-known ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Official: Port is registered with IANA for the application.[5] Unofficial: Port is not registered with IANA for the application. Multiple use: Multiple applications are known to use this port. Well-known ports The port numbers in the range from 0 to 1023 are the well-known ports or system ports.[6] They are used by system processes that provide widely used types of network services. -

Uiucnet69293univ.Pdf
Digitized by the Internet Archive in 2012 with funding from University of Illinois Urbana-Champaign http://archive.org/details/uiucnet69293univ UMTVERStTY OF ILLINOIS LIBRARY M URBANA-CHAMPA1GN A Publication of the Computing and Communications Services Office UNIV OF ILL, JAN 2 5 1993 The University of Illinois Campus Network Vol. 6 No. 1 Dec. 1992 -Jan. 1993 Icon Key Exploring the Power of Novices the Internet Gopher INTERNET TREASURES of the Golden Gophers) in an effort to Experienced users provide the UM students and staff with a flexible Campus-Wide Information Sys- tem (CWIS) for disseminating news, an- nouncements, and other kinds of informa- Network Administrators now, most UlUCnet users have at tion to the university community. In order MSS\ least heard about gopher. The furry to make it easy for departmental informa- Bylittle rodent who burrows through tion providers to maintain control over AISS clients gopherspace on the Internet has been fea- their own data, the gopher team sought to tured twice in CCSO's Updates newsletter develop a "distributed document delivery (vol. 3 no. 4 and vol. 3 no. 8) and once in system"—that is, a system in which the Everyone the semi-monthly UIUC faculty/staff data could physically reside on multiple newspaper Inside Illinois (vol. 12 no. 11). computers in multiple locations. Their National publications for computing and solution was a TCP/ IP-based client-server Platform/Operating System networking professionals and hobbyists protocol and a set of applications that pro- (e.g., MacWeek, Network World, Computer vided for the coordination and linking of Shopper) have also been tracking the devel- {continued on page 2) HH opment of this increasingly popular and PC compatibles (DOS™) ubiquitous Internet tool. -

List of TCP and UDP Port Numbers - Wikipedia, Th
List of TCP and UDP port numbers - Wikipedia, th... https://en.wikipedia.org/wiki/List_of_TCP_and_U... List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the transport layer of the Internet Protocol Suite for the establishment of host-to-host connectivity. Originally, port numbers were used by the Network Control Program (NCP) in the ARPANET for which two ports were required for half-duplex transmission. Later, the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) needed only one port for full-duplex, bidirectional traffic. The even-numbered ports were not used, and this resulted in some even numbers in the well-known port number range being unassigned. The Stream Control Transmission Protocol (SCTP) and the Datagram Congestion Control Protocol (DCCP) also use port numbers. They usually use port numbers that match the services of the corresponding TCP or UDP implementation, if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[1] However, many unofficial uses of both well-known and registered port numbers occur in practice. Contents 1 Table legend 2 Well-known ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Official: Port is registered with IANA for the application.[1] Unofficial: Port is not registered with IANA for the application. Multiple use: Multiple applications are known to use this port. Well-known ports The port numbers in the range from 0 to 1023 are the well-known ports or system ports.[2] They are used by system processes that provide widely used types of network services. -

® Common Abbreviations
® Common Abbreviations AA auto-answer AAL A TM adaptation layer AAN autonomously attached network ABM asynchronous balanced mode AbMAN Aberdeen MAN ABNF augmented BNF AC access control ACAP application configuration access protocol ACK acknowledge ACL access control list ADC analogue-to-digital converter ADPCM adaptive delta pulse code modulation AES audio engineering society AFI authority and format identifier AGENTX agent extensibility protocol AGP accelerated graphics port AM amplitude modulation AMI alternative mark inversion ANSI American National Standard Institute APCM adaptive pulse code modulation API application program interface ARM asynchronous response mode ARP address resolution protocol ASCII American standard code for information exchange ASK amplitude-shift keying AT attention ATM asynchronous transfer mode AUI attachment unit interface BCC blind carbon copy BCD binary coded decimal BGP border gateway protocol BIOS basic input/output system B-ISDN broadband ISDN BMP bitmapped BNC British Naval Connector BaM beginning of message BOOTP bootstrap protocol BPDU bridge protocol data units bps bits per second BVCP Banyan Vines control protocol CAD computer-aided design 403 CAN concentrated area network CASE common applications service elements CATNIP common architecture for the Internet CC carbon copy CCITT International Telegraph and Telephone Consultative CD carrier detect CD compact disk CDE common desktop environment CDFS CD file system CD-R CD-recordable CD-ROM compact disk - read-only memory CF control field CGI common -
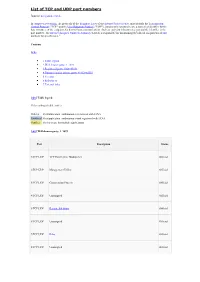
List of TCP and UDP Port Numbers
List of TCP and UDP port numbers Jump to: navigation, search In computer networking, the protocols of the Transport Layer of the Internet Protocol Suite, most notably the Transmission Control Protocol ("TCP") and the User Datagram Protocol ("UDP"), but also other protocols, use a numerical identifier for the data structures of the endpoints for host-to-host communications. Such an endpoint is known as a port and the identifier is the port number. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[1] Contents [hide] • 1 Table legend • 2 Well-known ports: 1–1023 • 3 Registered ports: 1024–49151 • 4 Dynamic and/or private ports: 49152–65535 • 5 See also • 6 References • 7 External links [edit] Table legend Color coding of table entries Official Port/application combination is registered with IANA Unofficial Port/application combination is not registered with IANA Conflict Port is in use for multiple applications [edit] Well-known ports: 1–1023 Port Description Status 1/TCP,UDP TCP Port Service Multiplexer Official 2/TCP,UDP Management Utility Official 3/TCP,UDP Compression Process Official 4/TCP,UDP Unassigned Official 5/TCP,UDP Remote Job Entry Official 6/TCP,UDP Unassigned Official 7/TCP,UDP Echo Official 8/TCP,UDP Unassigned Official 9/TCP,UDP Discard Official 11/TCP,UDP Active Users Official 13/TCP,UDP DAYTIME – (RFC 867) Official 17/TCP,UDP Quote of the Day Official 18/TCP,UDP Message Send Protocol Official 19/TCP,UDP Character Generator Official -
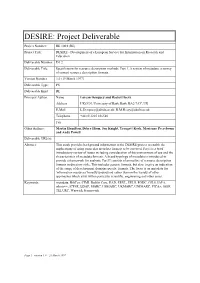
DESIRE: Project Deliverable
DESIRE: Project Deliverable Project Number: RE 1004 (RE) Project Title: DESIRE - Development of a European Service for Information on Research and Education Deliverable Number: D3.2 Deliverable Title: Specification for resource description methods. Part 1. A review of metadata: a survey of current resource description formats. Version Number 1.0 (19 March 1997) Deliverable Type: PU Deliverable Kind: RE Principal Author: Name Lorcan Dempsey and Rachel Heery Address UKOLN, University of Bath, Bath, BA2 7AY, UK E-Mail [email protected], [email protected] Telephone +44 (0)1225 826580 Fax Other Authors: Martin Hamilton, Debra Hiom, Jon Knight, Traugott Koch, Marianne Peereboom and Andy Powell Deliverable URL(s): Abstract: This study provides background information to the DESIRE project to enable the implications of using particular metadata formats to be assessed. Part I is a brief introductory review of issues including consideration of the environment of use and the characteristics of metadata formats. A braod typology of metadata is introduced to provide a framework for analysis. Part II consists of an outline of resource description formats in directory style. This includes generic formats, but also, to give an indication of the range of development, domain-specific formats. The focus is on metadata for 'information resources' broadly understood rather than on the variety of other approaches which exist within particular scientific, engineering and other areas. Keywords: metadata, BibTex, CIMI, Dublin Core, EAD, EEVL, EELS, FGDC, GILS, IAFA, whois++, ICPSR, LDAP, MARC, USMARC, UKMARC, UNIMARC, PICA+, SOIF, TEI,URC, Warwick Framework Page 1 version 1.0 21 March 1997 PART II: Executive Summary This document has been prepared as a working paper in the Indexing and Cataloguing work package of the DESIRE project (WP3), funded by the European Union as part of the Telematics for Research area of the Fourth Framework Programme. -

Eth, Ip and TCP Packet Structure
ETHERNET Structure - 6 bytes Destination Ethernet Address (All 1 if broadcast, …) - 6 bytes Source Ethernet Address - 2 bytes Length or Type Field - if IEEE 802.3 number of bytes <= 1500(05DC) - if ethernet I or II is the packet type > 1500(05DC) - 46 bytes until 1500 are data! Short packets filled until 46 bytes - 4 bytes (Frame Check sequence: directly evaluated and managed by the hardware. Not accessible via software.) 1 SAP CODES Null LSAP 0x00 Individual LLC Sublayer Management Function 0x02 Group LLC Sublayer Management Function 0x03 IBM SNA Path Control (individual) 0x04 IBM SNA Path Control (group) 0x05 ARPANET Internet Protocol (IP) 0x06 SNA 0x08 SNA 0x0C PROWAY (IEC955) Network Management & Initialization 0x0E Texas Instruments 0x18 IEEE 802.1 Bridge Spanning Tree Protocol 0x42 EIA RS-511 Manufacturing Message Service 0x4E ISO 8208 (X.25 over IEEE 802.2 Type 2 LLC) 0x7E Xerox Network Systems (XNS) 0x80 Nestar 0x86 PROWAY (IEC 955) Active Station List Maintenance 0x8E ARPANET Address Resolution Protocol (ARP) 0x98 Banyan VINES 0xBC SubNetwork Access Protocol (SNAP) 0xAA Novell NetWare 0xE0 IBM NetBIOS 0xF0 IBM LAN Management (individual) 0xF4 IBM LAN Management (group) 0xF5 IBM Remote Program Load (RPL) 0xF8 Ungermann-Bass 0xFA ISO Network Layer Protocol 0xFE Global LSAP 0xFF Ethernet types 0x0000 0x05DC IEEE 802.3 Length Fields 0x0600 0x0600 Xerox XNS IDP 0x0800 0x0800 DOD IP 0x0801 0x0801 X.75 Internet 0x0802 0x0802 NBS Internet 0x0803 0x0803 ECMA Internet 0x0804 0x0804 CHAOSnet 0x0805 0x0805 X.25 Level 3 0x0806 0x0806 ARP (for IP and CHAOS) 0x0807 0x0807 Xerox XNS Compatibility 0x081C 0x081C Symbolics Private 0x0888 0x088A Xyplex 0x0900 0x0900 Ungermann-Bass network debugger 0x0A00 0x0A00 Xerox 802.3 PUP 0x0A01 0x0A01 Xerox 802.3 PUP Address Translation 0x0A02 0x0A02 Xerox PUP CAL Protocol (unused) 0x0BAD 0x0BAD Banyan Systems, Inc. -

List of TCP and UDP Port Numbers - Wikipedia, the Free Encyclopedia
List of TCP and UDP port numbers - Wikipedia, the free encyclopedia http://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the Transport Layer of the Internet Protocol Suite for the establishment of host-to-host connectivity. Originally, these port numbers were used by the Network Control Program (NCP) and two ports were needed as transmission was done at half duplex. As Transmission Control Protocol (TCP) and User Datagram Protocol (UDP) were adopted, only one port was needed. The even numbered ports were dropped. This is why some even numbers in the well-known port number range are unassigned. TCP and UDP port numbers are also used for the Stream Control Transmission Protocol (SCTP), and the Datagram Congestion Control Protocol (DCCP). SCTP and DCCP services usually use a port number that matches the service of the corresponding TCP or UDP implementation if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses. [1] However, many unofficial uses of both well-known and registered port numbers occur in practice. Contents 1 Table legend 2 Well-known ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Use Description Color Official Port is registered with IANA for the application [1] White Unofficial Port is not registered with IANA for the application Blue Multiple use Multiple applications are known to use this port. -

Port TCP UDP Description Status 0 TCP Shirt Pocket Software
Port TCP UDP Description Status 0 TCP Shirt Pocket software (netTunes and launchTunes) Official 0 UDP Reserved Official 1 TCP UDP TCP Port Service Multiplexer Official 2 TCP UDP Management Utility Official 3 TCP UDP Compression Process Official 4 TCP UDP Unassigned Official 5 TCP UDP Remote Job Entry Official 6 TCP UDP Unassigned Official 7 TCP UDP Echo Official 8 TCP UDP Unassigned Official 9 TCP UDP Discard Official 10 TCP UDP Unassigned Official 11 TCP UDP Active Users Official 12 TCP UDP Unassigned Official 13 TCP UDP DAYTIME – (RFC 867) Official 14 TCP UDP Unassigned Official 16 TCP UDP Unassigned Official 17 TCP UDP Quote of the Day Official 18 TCP UDP Message Send Protocol Official 19 TCP UDP Character Generator Official 20 TCP FTP – data transfer Official 21 TCP FTP – control (command) Official Secure Shell (SSH)—used for secure logins, file transfers (scp, sftp) 22 TCP UDP Official and port forwarding Official 23 TCP Telnet protocol—unencrypted text communications USA only 24 TCP UDP Priv-mail : any private mail system. Official Simple Mail Transfer Protocol (SMTP)—used for e-mail routing 25 TCP Official between mail servers 34 TCP UDP Remote File (RF)—used to transfer files between machines Unofficial 35 TCP UDP Any private printer server protocol Official 37 TCP UDP TIME protocol Official Resource Location Protocol[2] (RLP)—used for determining the 39 TCP UDP Official location of higher level services from hosts on a network 41 TCP UDP Graphics Official 42 TCP UDP nameserver, ARPA Host Name Server Protocol Official 42 TCP UDP -

List of TCP and UDP Port Numbers from Wikipedia, the Free Encyclopedia
List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the Transport Layer of the Internet Protocol Suite for the establishment of hosttohost connectivity. Originally, port numbers were used by the Network Control Program (NCP) in the ARPANET for which two ports were required for half duplex transmission. Later, the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) needed only one port for full duplex, bidirectional traffic. The even numbered ports were not used, and this resulted in some even numbers in the wellknown port number range being unassigned. The Stream Control Transmission Protocol (SCTP) and the Datagram Congestion Control Protocol (DCCP) also use port numbers. They usually use port numbers that match the services of the corresponding TCP or UDP implementation, if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[1] However, many unofficial uses of both wellknown and registered port numbers occur in practice. Contents 1 Table legend 2 Wellknown ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Use Description Color Official Port is registered with IANA for the application[1] White Unofficial Port is not registered with IANA for the application Blue Multiple use Multiple applications are known to use this port. Yellow Wellknown ports The port numbers in the range from 0 to 1023 are the wellknown ports or system ports.[2] They are used by system processes that provide widely used types of network services.