Toward Virtual Actors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The University of Chicago Looking at Cartoons
THE UNIVERSITY OF CHICAGO LOOKING AT CARTOONS: THE ART, LABOR, AND TECHNOLOGY OF AMERICAN CEL ANIMATION A DISSERTATION SUBMITTED TO THE FACULTY OF THE DIVISION OF THE HUMANITIES IN CANDIDACY FOR THE DEGREE OF DOCTOR OF PHILOSOPHY DEPARTMENT OF CINEMA AND MEDIA STUDIES BY HANNAH MAITLAND FRANK CHICAGO, ILLINOIS AUGUST 2016 FOR MY FAMILY IN MEMORY OF MY FATHER Apparently he had examined them patiently picture by picture and imagined that they would be screened in the same way, failing at that time to grasp the principle of the cinematograph. —Flann O’Brien CONTENTS LIST OF FIGURES...............................................................................................................................v ABSTRACT.......................................................................................................................................vii ACKNOWLEDGMENTS....................................................................................................................viii INTRODUCTION LOOKING AT LABOR......................................................................................1 CHAPTER 1 ANIMATION AND MONTAGE; or, Photographic Records of Documents...................................................22 CHAPTER 2 A VIEW OF THE WORLD Toward a Photographic Theory of Cel Animation ...................................72 CHAPTER 3 PARS PRO TOTO Character Animation and the Work of the Anonymous Artist................121 CHAPTER 4 THE MULTIPLICATION OF TRACES Xerographic Reproduction and One Hundred and One Dalmatians.......174 -

Animation:Then,Now,Next
Fall 2020 FYI, section 093 is a 2nd half of the semester course. If you wish to enroll in the full-semester version please email instructor FILM1600 : Then|Now|Next [email protected] for permission code. (August 17,2020) What you need to know! Designed to be online (asynchronous – anytime during the week) since 2016. It is not a zoom/IVC adaptation because of COVID. The course incorporates extensive visual media that make up the majority of the course content (no required book to purchase). It is now 99% Closed Captioned (spring 2020). Updated each semester with newest advances in the field. This course is 8 weeks long, which means things move a bit faster to fit everything in but is very manageable with good organization. What is different about this course… this is not a history course but reveals the people, processes and future changes in how animation is used in digital media. The content of the course draws directly from the professor’s experience and insights working at Disney Feature Animation and Electronic Arts (games). Weekly Modules are structured to emulate regular in-person classes. The modules contain each week's opening animations, lectures, readings, and quizzes. You can access the material several weeks before due dates. Course Content Animation techniques have evolved from simple cartoon drawings to 3D VFX. Today this evolution continues as it is Link to Sample Lecture Class rapidly being integrated into XR. From Animation's beginnings, (2 lectures per week) each new technological innovation extended the creative possibilities for storytelling (e.g. -

Animating Race the Production and Ascription of Asian-Ness in the Animation of Avatar: the Last Airbender and the Legend of Korra
Animating Race The Production and Ascription of Asian-ness in the Animation of Avatar: The Last Airbender and The Legend of Korra Francis M. Agnoli Submitted for the degree of Doctor of Philosophy (PhD) University of East Anglia School of Art, Media and American Studies April 2020 This copy of the thesis has been supplied on condition that anyone who consults it is understood to recognise that its copyright rests with the author and that use of any information derived there from must be in accordance with current UK Copyright Law. In addition, any quotation or extract must include full attribution. 2 Abstract How and by what means is race ascribed to an animated body? My thesis addresses this question by reconstructing the production narratives around the Nickelodeon television series Avatar: The Last Airbender (2005-08) and its sequel The Legend of Korra (2012-14). Through original and preexisting interviews, I determine how the ascription of race occurs at every stage of production. To do so, I triangulate theories related to race as a social construct, using a definition composed by sociologists Matthew Desmond and Mustafa Emirbayer; re-presentations of the body in animation, drawing upon art historian Nicholas Mirzoeff’s concept of the bodyscape; and the cinematic voice as described by film scholars Rick Altman, Mary Ann Doane, Michel Chion, and Gianluca Sergi. Even production processes not directly related to character design, animation, or performance contribute to the ascription of race. Therefore, this thesis also references writings on culture, such as those on cultural appropriation, cultural flow/traffic, and transculturation; fantasy, an impulse to break away from mimesis; and realist animation conventions, which relates to Paul Wells’ concept of hyper-realism. -

Perceptual Evaluation of Cartoon Physics: Accuracy, Attention, Appeal
Perceptual Evaluation of Cartoon Physics: Accuracy, Attention, Appeal Marcos Garcia∗ John Dingliana† Carol O’Sullivan‡ Graphics Vision and Visualisation Group, Trinity College Dublin Abstract deformations to real-time interactive physics simulations e.g. Cel Damage by Pseudo Interactive R and Electronic Arts R . A num- People have been using stylistic methods in classical animation for ber of papers have been published on simulating cartoon physics many years and such methods have also been recently applied in 3D using a range of different approaches from simple geometrical de- Computer Graphics. We have developed a method to apply squash formations to complex physically based models of elasticity. In this and stretch cartoon stylisations to physically based simulations in paper we present the results of a number of experiments that were real-time. In this paper, we present a perceptual evaluation of this performed to address the question of whether and to what degree approach in a series of experiments. Our hypotheses were: that styl- stylisation contributes to the quality of a real-time interactive simu- ised motion would improve user Accuracy (trajectory prediction); lation. that user Attention would be drawn more to objects with cartoon physics; and that animations with cartoon physics would have more 1.1 Contributions Appeal. In a task that required users to accurately predict the tra- jectories of bouncing objects with a range of elasticities and vary- Our main contribution in this paper is to validate some well known ing degrees of information, we found that stylisation significantly assumptions that stylised behaviour has the potential to signifi- improved user accuracy, especially for high elasticities and low in- cantly affect a user’s perception and response to a scene. -

Incongruous Surrealism Within Narrative Animated Film
University of Central Florida STARS Electronic Theses and Dissertations, 2020- 2021 Incongruous Surrealism within Narrative Animated Film Daniel McCabe University of Central Florida Part of the Film and Media Studies Commons Find similar works at: https://stars.library.ucf.edu/etd2020 University of Central Florida Libraries http://library.ucf.edu This Masters Thesis (Open Access) is brought to you for free and open access by STARS. It has been accepted for inclusion in Electronic Theses and Dissertations, 2020- by an authorized administrator of STARS. For more information, please contact [email protected]. STARS Citation McCabe, Daniel, "Incongruous Surrealism within Narrative Animated Film" (2021). Electronic Theses and Dissertations, 2020-. 529. https://stars.library.ucf.edu/etd2020/529 INCONGRUOUS SURREALISM WITHIN NARRATIVE ANIMATED FILM by DANIEL MCCABE B.A. University of Central Florida, 2018 B.S.B.A. University of Central Florida, 2018 A thesis submitted in partial fulfillment of the requirements for the degree of Masters of Fine Arts in the School of Visual Arts and Design in the College of Arts and Humanities at the University of Central Florida Orlando, Florida Spring Term 2021 © Daniel Francis McCabe 2021 ii ABSTRACT A pop music video is a form of media containing incongruous surrealistic imagery with a narrative structure supplied by song lyrics. The lyrics’ presence allows filmmakers to digress from sequential imagery through introduction of nonlinear visual elements. I will analyze these surrealist film elements through several post-modern philosophies to better understand how this animated audio-visual synthesis resides in the larger world of art theory and its relationship to the popular music video. -

Animating Film Theory Animating Film Theory
animating film animating animating film theorytheory film theory karen beckman, editor Animating Film Theory Animating Film Theory Karen Beckman, editor Duke university Press Durham anD LonDon 2014 © 2014 Duke University Press All rights reserved Printed in the United States of America on acid- free paper ♾ Typeset in Chaparral Pro by Tseng Information Systems, Inc. Library of Congress Cataloging- in- Publication Data Animating film theory / Karen Beckman, editor. pages cm Includes bibliographical references and index. isbn 978- 0- 8223- 5640- 0 (cloth : alk. paper) isbn 978- 0- 8223- 5652- 3 (pbk. : alk. paper) 1. Animated films—History and criticism. 2. Animated films—Social aspects. 3. Animation (Cinematography) I. Beckman, Karen Redrobe nc1765.a535 2014 791.43′34—dc23 2013026435 “Film as Experiment of Animation—Are Films Experiments on Human Beings?” © Gertrud Koch. In memory of Ruth Wright (1917–2012) Contents Acknowledgments · ix Animating Film Theory: An Introduction · karen beckman · 1 Part I: Time and Space 1 : : Animation and History · esther LesLie · 25 2 : : Animating the Instant: The Secret Symmetry between Animation and Photography · tom GunninG · 37 3 : : Polygraphic Photography and the Origins of 3- D Animation · aLexanDer r. GaLLoway · 54 4 : : “A Living, Developing Egg Is Present before You”: Animation, Scientific Visualization, Modeling · Oliver Gaycken · 68 Part II: Cinema and Animation 5 : : André Martin, Inventor of Animation Cinema: Prolegomena for a History of Terms · hervé Joubert- Laurencin; transLateD by Lucy swanson · 85 6 : : “First Principles” of Animation · aLan choLoDenko · 98 7 : : Animation, in Theory · suzanne buchan · 111 Part III: The Experiment 8 : : Film as Experiment in Animation: Are Films Experiments on Human Beings? · GertruD koch; transLateD by DanieL henDrickson · 131 9 : : Frame Shot: Vertov’s Ideologies of Animation · mihaeLa mihaiLova anD John mackay · 145 10 : : Signatures of Motion: Len Lye’s Scratch Films and the Energy of the Line · anDrew r. -
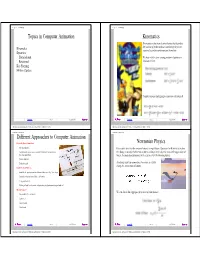
Topics in Computer Animation Different Approaches to Computer
Lecture 22 --- 6.837 Fall '00 Lecture 22 --- 6.837 Fall '00 Topics in Computer Animation Kinematics Kinematics is that branch of mechanics that describes Kinematics the motions of bodies without considering the forces required to produce and maintain the motion. Dynamics Translational We start with the time varying motions of points as a Rotational function of time: Key Framing Motion Capture Consider a point undergoing a constant acceleration k Lecture 22 Slide 1 6.837 Fall '00 Lecture 22 Slide 3 6.837 Fall '00 http://graphics.lcs.mit.edu/classes/6.837/F00/Lecture22/Slide01.html [12/7/2000 12:47:45 PM] http://graphics.lcs.mit.edu/classes/6.837/F00/Lecture22/Slide03.html [12/7/2000 12:47:51 PM] Lecture 22 --- 6.837 Fall '00 Lecture 22 --- 6.837 Fall '00 Different Approaches to Computer Animation Physically Based Animations - Newtonian Physics All about physics. Kinematics describes the motion of objects in equilibrium. Dynamics (or Kinetics) describes Assign masses to our objects, establish initial and reaction forces, the change in an object's kinematics due to a change in the object's mass or the application of then run simulations. forces. To understand dynamics we'll need to review Newtonian physics. Results look real Lack of control A moving mass has momentum. Forces are needed to change the momentum of a mass. Hand Tweaked Motions - Establish the positions and orientations of objects at "key" time steps Interpolate the positions of objects in-between Very good control Making it "look" real is an art, and sometimes we don't want things to look real Motion Capture - We can also define aggregate properties of point masses. -

Post-Print Version
1 This is a pre-copyedited version of an article accepted for publication in The Velvet Light Trap following peer review. The definitive publisher-authenticated version is available through the University of Texas Press. This article was published in The Velvet Light Trap No. 77 (Spring 2016). If you have institutional access to The Velvet Light Trap via Project Muse, the published version is available here: https://muse.jhu.edu/article/609056 Do the Locomotion: Obstinate Avatars, Dehiscent Performances, and the Rise of the Comedic Videogame Ian Bryce Jones In recent years, independent gaming has witnessed an explosion of bodies: gangling and ungainly bodies, hapless and haphazard bodies, bodies stretched, strewn out, their limbs and gestures de-articulated into component parts. Spurred on by a combination of technical advances in physics simulation, new digital distribution options for games with niche appeal, and the emergence of YouTube fan videos as an amplifier of cult games’ viral potential, a cluster of games with similar themes and mechanics have begun to radically re-assess the role of the avatar as embodied entity. Affixed by critics with the colloquial designation “fumblecore,” the games within this burgeoning micro-genre have gained notoriety not only for their frequent lapses into tremendous difficulty, but also for the unusual source of this difficulty: the control of bodily movement itself.1 This article has benefited enormously from the criticism and suggestions of a diverse array of scholars and players. I would especially like to thank Manuel Garin for the opportunity to present early material on the panel “Video Games and Comedy: Between Laughter and Performance” at SCMS 2014, as well as my co-panelists, Jaroslav Švelch and Constantino Oliva, for their welcome feedback. -

Subject Index
863 Subject Index ‘Note: Page numbers followed by “f” indicate figures, “t” indicate tables and “b” indicate boxes.’ A Affordances, 112–114 A/D conversion. See Analog to Digital conversion in virtual reality, 114–117 (A/D conversion) false affordances, 116 AAAD. See Action at a distance (AAAD) reinforcing perceived affordances, 116–117 AAR. See After-action review (AAR) After-action review (AAR), 545f, 630, 630f, 634–635, 645, Absolute input, 198–200 761 Abstract haptic representations, 439 Affordances of VR, 114–117 Abstract synthesis, 495 Agency, 162, 164, 181 Abstraction triangle, 448 Agents, 552–553, 592–593, 614, 684–685 Accelerometers, 198–199, 218 AIFF. See Audio interchange file format (AIFF) Accommodation, 140–141, 273–275, 320, 570, 804 Airfoils, 13 Action at a distance (AAAD), 557–558 AIs. See Artificial intelligences (AIs) Activation mechanism, 554–556, 583 Aladdin’s Magic Carpet Ride VR experience, 185–186, 347, Active haptic displays, 516 347f, 470, 505, 625, 735, 770–771 Active input, 193–196 Alberti, Leon Battista, 28 Active surfaces, 808 Alice system for programming education, Adaptability, 122–123 758–759 Adaptive rectangular decomposition (ARD), 502 AlloSphere, 51–52, 51f, 280 Additive sound creation techniques, 499 Allstate Impaired Driver Simulator, 625, 629f Advanced Realtime Tracking (ART), 53–54, 213f Alpha delta fiber (Aδ fiber), 149 Advanced Robotics Research Lab (ARRL), 369 Alphanumeric value selection, 591–593 Advanced systems, 11–12 Ambient sounds, 436–437, 505 Advanced texture mapping techniques, 469–473 Ambiotherm device, 372, 373f Adventure (games), 12 Ambisonics, 354 Adverse effect, 351 Ambulatory platforms, 242–243 Aestheticism, 414 American Sign Language (ASL), 552–553 Affine transformations, 486–487 Amount/type of information, 196–198 864 | SUBJECT INDEX Amplification, 349–350 ARToolKit (ARTK), 48–49, 715–716 Amplifier, 349–350, 349f Ascension Technologies, 41–44, 44f, 46–47, 86–87 Anaglyphic 3D, 270f, 7f, 30, 49, 269–270, 271f ASL. -

Motion Capture Technology for Entertainment
[in the SPOTLIGHT] Chris Bregler Motion Capture Technology for Entertainment he year 2007 started with this momentous goal. One of the considered “cheating” in the anima- two big bangs for Lucas- secret ingredients that will get us tion world, where it was thought that Film’s Industrial Light and there may be motion capture (MoCap), everything should be conjured up by Magic (ILM), the motion defined as a technology that allows us the imagination. “Good animation” picture visual effects compa- to record human motion with sensors was considered to be a rare and hard- Tny started by George Lucas in 1975, in and to digitally map the motion to to-acquire art form that followed the two eagerly awaited Hollywood events. In computer-generated creatures. MoCap famous drawing and animation princi- January, ILM won the “Scientific and has been both hyped and criticized ples of cartoon physics invented by Engineering Award” of the Academy of since people started experimenting Disney. Rotoscoping was thought to be Motion Picture Arts and Sciences for with computerized motion-recording “cheap animation” that lacked expres- their image-based modeling work applied devices in the 1970s. Whether reviled siveness. If one of animation’s main to visual effects in the film industry. In by animation purists as a shortcut or principles is exaggeration—everything February, ILM took home the Oscar needs to be bigger than life, not for “Best Visual Effects” for Pirates just a copy of life—rotoscoping, as of the Caribbean: Dead Man’s Chest, THE ILM AWARDS ARE precursor of MoCap, was consid- a milestone achievement for ILM IN LINE WITH ONE SPECIFIC ered even less than life because after their last Oscar for Forrest GOAL—THE CREATION OF many important subtleties got lost Gump in 1994 and many previous ARTIFICIAL HUMANS in the process. -

Ontology, Aesthetics, and Cartoon Alienation
Georgia State University ScholarWorks @ Georgia State University Film, Media & Theatre Theses School of Film, Media & Theatre Summer 7-31-2018 Animating Social Pathology: Ontology, Aesthetics, and Cartoon Alienation Wolfgang Boehm Georgia State University Follow this and additional works at: https://scholarworks.gsu.edu/fmt_theses Recommended Citation Boehm, Wolfgang, "Animating Social Pathology: Ontology, Aesthetics, and Cartoon Alienation." Thesis, Georgia State University, 2018. https://scholarworks.gsu.edu/fmt_theses/2 This Thesis is brought to you for free and open access by the School of Film, Media & Theatre at ScholarWorks @ Georgia State University. It has been accepted for inclusion in Film, Media & Theatre Theses by an authorized administrator of ScholarWorks @ Georgia State University. For more information, please contact [email protected]. Animating Social Pathology: Ontology, Aesthetics, and Cartoon Alienation by Wolfgang Boehm Under the Direction of Professor Greg Smith ABSTRACT This thesis grounds an unstable ontology in animation’s industrial history and its plas- matic aesthetics, in-so-doing I find animation to be a site of rendering visible a particular con- frontation with an inability to properly rationalize, ossify, or otherwise delimit traditionally held boundaries of motility. Because of this inability, animation is privileged as a form to rethink our interactions with media technology, leading to utopian thought and bizarre, pathological behav- ior. I follow the ontological trend through animation studies, using Pixar’s WALL-E as a guide. I explore animation as an afterimage of social pathology, which stands in contrast to the more lu- dic thought of a figure such as Sergei Eisenstein, using Black Mirror’s “The Waldo Moment.” I look to two Cartoon Network shows as examples of potential alternatives to both the utopian and pathological of the preceding chapters. -

History of Animation- Syllabus
A History of Animation Instructor: Kirk Pearson ([email protected]) Meeting Times: TBD (1 hour/week for class, up to 2 hours/week for screenings, plus under 20 !minutes for weekly reading) “A History of Animation" is a course about the technical and narrative developments of the animated film, all the way from the zoetrope through vaporwave. As we walk through 20th century history, we will pay close attention to the mechanized history and cultural theory behind some of the world’s most critically important animations. Students will complete this course with both a considerable knowledge of technical film and a more nuanced understanding of the sheer magic and profundity of the animated form. Animation depicts the compromised dream sequences in Satochi Kon’s “Paprika.” Attendance Policy: Students are expected to attend every class and screening. Students are !allowed two unexcused absences. Any more will result in a grade of “NP.” Homework (40%): One or two short readings will be assigned each week. You will be expected to reserve 10 to 40 minutes to read and understand them well. Furthermore, you will also be asked to send a related comment or discussion question to the instructor before class every week, !which will help determine your class grade. Timeline Project (10%): At the start of the first class, students will be given a large sheet of paper and begin a timeline that will evolve through the course. This will not be collected and !graded, but will simply serve as a helpful tool for contextualizing large-scale cultural trends. Lead Class Discussion (20%): Classes 6-12 will not be a traditional lecture, but a conversation about the week’s topic led by students.