Sorting Number of Comparisons = Height of Decision Tree
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Improving the Performance of Bubble Sort Using a Modified Diminishing Increment Sorting
Scientific Research and Essay Vol. 4 (8), pp. 740-744, August, 2009 Available online at http://www.academicjournals.org/SRE ISSN 1992-2248 © 2009 Academic Journals Full Length Research Paper Improving the performance of bubble sort using a modified diminishing increment sorting Oyelami Olufemi Moses Department of Computer and Information Sciences, Covenant University, P. M. B. 1023, Ota, Ogun State, Nigeria. E- mail: [email protected] or [email protected]. Tel.: +234-8055344658. Accepted 17 February, 2009 Sorting involves rearranging information into either ascending or descending order. There are many sorting algorithms, among which is Bubble Sort. Bubble Sort is not known to be a very good sorting algorithm because it is beset with redundant comparisons. However, efforts have been made to improve the performance of the algorithm. With Bidirectional Bubble Sort, the average number of comparisons is slightly reduced and Batcher’s Sort similar to Shellsort also performs significantly better than Bidirectional Bubble Sort by carrying out comparisons in a novel way so that no propagation of exchanges is necessary. Bitonic Sort was also presented by Batcher and the strong point of this sorting procedure is that it is very suitable for a hard-wired implementation using a sorting network. This paper presents a meta algorithm called Oyelami’s Sort that combines the technique of Bidirectional Bubble Sort with a modified diminishing increment sorting. The results from the implementation of the algorithm compared with Batcher’s Odd-Even Sort and Batcher’s Bitonic Sort showed that the algorithm performed better than the two in the worst case scenario. The implication is that the algorithm is faster. -

Parallel Sorting Algorithms + Topic Overview
+ Design of Parallel Algorithms Parallel Sorting Algorithms + Topic Overview n Issues in Sorting on Parallel Computers n Sorting Networks n Bubble Sort and its Variants n Quicksort n Bucket and Sample Sort n Other Sorting Algorithms + Sorting: Overview n One of the most commonly used and well-studied kernels. n Sorting can be comparison-based or noncomparison-based. n The fundamental operation of comparison-based sorting is compare-exchange. n The lower bound on any comparison-based sort of n numbers is Θ(nlog n) . n We focus here on comparison-based sorting algorithms. + Sorting: Basics What is a parallel sorted sequence? Where are the input and output lists stored? n We assume that the input and output lists are distributed. n The sorted list is partitioned with the property that each partitioned list is sorted and each element in processor Pi's list is less than that in Pj's list if i < j. + Sorting: Parallel Compare Exchange Operation A parallel compare-exchange operation. Processes Pi and Pj send their elements to each other. Process Pi keeps min{ai,aj}, and Pj keeps max{ai, aj}. + Sorting: Basics What is the parallel counterpart to a sequential comparator? n If each processor has one element, the compare exchange operation stores the smaller element at the processor with smaller id. This can be done in ts + tw time. n If we have more than one element per processor, we call this operation a compare split. Assume each of two processors have n/p elements. n After the compare-split operation, the smaller n/p elements are at processor Pi and the larger n/p elements at Pj, where i < j. -

A Proposed Solution for Sorting Algorithms Problems by Comparison Network Model of Computation
International Journal of Scientific & Engineering Research Volume 3, Issue 4, April-2012 1 ISSN 2229-5518 A Proposed Solution for Sorting Algorithms Problems by Comparison Network Model of Computation. Mr. Rajeev Singh, Mr. Ashish Kumar Tripathi, Mr. Saurabh Upadhyay, Mr.Sachin Kumar Dhar Dwivedi Abstract:-In this paper we have proposed a new solution for sorting algorithms. In the beginning of the sorting algorithm for serial computers (Random access machines, or RAM’S) that allow only one operation to be executed at a time. We have investigated sorting algorithm based on a comparison network model of computation, in which many comparison operation can be performed simultaneously. Index Terms Sorting algorithms, comparison network, sorting network, the zero one principle, bitonic sorting network 1 Introduction 1.2 The output is a permutation, or reordering, of the input. There are many algorithms for solving sorting algorithms For example of bubble sort 8, 25,9,3,6 (networks).A sorting network is an abstract mathematical model of a network of wires and comparator modules that is used to sort 8 8 8 3 3 a sequence of numbers. Each comparator connects two wires and sorts the values by outputting the smaller value to one wire and 25 25 9 9 3 8 6 6 the large to the other. A sorting network consists of two items comparators and wires .each wires carries with its values and each 9 25 3 9 6 8 comparator takes two wires as input and output. This independence of comparison sequences is useful for parallel 3 25 6 9 execution of the algorithms. -
Sorting Networks
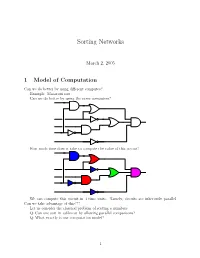
Sorting Networks March 2, 2005 1 Model of Computation Can we do better by using different computes? Example: Macaroni sort. Can we do better by using the same computers? How much time does it take to compute the value of this circuit? We can compute this circuit in 4 time units. Namely, circuits are inherently parallel. Can we take advantage of this??? Let us consider the classical problem of sorting n numbers. Q: Can one sort in sublinear by allowing parallel comparisons? Q: What exactly is our computation model? 1 1.1 Computing with a circuit We are going to design a circuit, where the inputs are the numbers, and we compare two numbers using a comparator gate: ¢¤¦© ¡ ¡ Comparator ¡£¢¥¤§¦©¨ ¡ For our drawings, we will draw such a gate as follows: ¢¡¤£¦¥¨§ © ¡£¦ So, circuits would just be horizontal lines, with vertical segments (i.e., gates) between them. A complete sorting network, looks like: The inputs come on the wires on the left, and are output on the wires on the right. The largest number is output on the bottom line. The surprising thing, is that one can generate circuits from a sorting algorithm. In fact, consider the following circuit: Q: What does this circuit does? A: This is the inner loop of insertion sort. Repeating this inner loop, we get the following sorting network: 2 Alternative way of drawing it: Q: How much time does it take for this circuit to sort the n numbers? Running time = how many time clocks we have to wait till the result stabilizes. In this case: 5 1 2 3 4 6 7 8 9 In general, we get: Lemma 1.1 Insertion sort requires 2n − 1 time units to sort n numbers. -

Foundations of Differentially Oblivious Algorithms
Foundations of Differentially Oblivious Algorithms T-H. Hubert Chan Kai-Min Chung Bruce Maggs Elaine Shi August 5, 2020 Abstract It is well-known that a program's memory access pattern can leak information about its input. To thwart such leakage, most existing works adopt the technique of oblivious RAM (ORAM) simulation. Such an obliviousness notion has stimulated much debate. Although ORAM techniques have significantly improved over the past few years, the concrete overheads are arguably still undesirable for real-world systems | part of this overhead is in fact inherent due to a well-known logarithmic ORAM lower bound by Goldreich and Ostrovsky. To make matters worse, when the program's runtime or output length depend on secret inputs, it may be necessary to perform worst-case padding to achieve full obliviousness and thus incur possibly super-linear overheads. Inspired by the elegant notion of differential privacy, we initiate the study of a new notion of access pattern privacy, which we call \(, δ)-differential obliviousness". We separate the notion of (, δ)-differential obliviousness from classical obliviousness by considering several fundamental algorithmic abstractions including sorting small-length keys, merging two sorted lists, and range query data structures (akin to binary search trees). We show that by adopting differential obliv- iousness with reasonable choices of and δ, not only can one circumvent several impossibilities pertaining to full obliviousness, one can also, in several cases, obtain meaningful privacy with little overhead relative to the non-private baselines (i.e., having privacy \almost for free"). On the other hand, we show that for very demanding choices of and δ, the same lower bounds for oblivious algorithms would be preserved for (, δ)-differential obliviousness. -

Bitonic Sorting Algorithm: a Review
International Journal of Computer Applications (0975 – 8887) Volume 113 – No. 13, March 2015 Bitonic Sorting Algorithm: A Review Megha Jain Sanjay Kumar V.K Patle S.O.S In CS & IT, S.O.S In CS & IT, S.O.S In CS & IT, PT. Ravi Shankar Shukla PT. Ravi Shankar Shukla PT. Ravi Shankar Shukla University, Raipur (C.G), India University, Raipur (C.G), India University, Raipur (C.G), India ABSTRACT 2.1 Bitonic Sequence The Batcher`s bitonic sorting algorithm is a parallel sorting A bitonic sequence of n elements ranges from x0,……,xn-1 algorithm, which is used for sorting the numbers in modern with characteristics (a) Existence of the index i, where 0 ≤ i ≤ parallel machines. There are various parallel sorting n-1, such that there exist monotonically increasing sequence algorithms such as radix sort, bitonic sort, etc. It is one of the from x0 to xi, and monotonically decreasing sequence from xi efficient parallel sorting algorithm because of load balancing to xn-1.(b) Existence of the cyclic shift of indices by which property. It is widely used in various scientific and characterics satisfy [10]. After applying the above engineering applications. However, Various researches have characteristics bitonic sequence occur. The bitonic split worked on a bitonic sorting algorithm in order to improve up operation is applied for producing two bitonic sequences on the performance of original batcher`s bitonic sorting which merge and sort operation is applied as shown in Fig 1. algorithm. In this paper, tried to review the contribution made by these researchers. 3. -

Sorting Algorithm 1 Sorting Algorithm
Sorting algorithm 1 Sorting algorithm In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order. Efficient sorting is important for optimizing the use of other algorithms (such as search and merge algorithms) that require sorted lists to work correctly; it is also often useful for canonicalizing data and for producing human-readable output. More formally, the output must satisfy two conditions: 1. The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order); 2. The output is a permutation, or reordering, of the input. Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement. For example, bubble sort was analyzed as early as 1956.[1] Although many consider it a solved problem, useful new sorting algorithms are still being invented (for example, library sort was first published in 2004). Sorting algorithms are prevalent in introductory computer science classes, where the abundance of algorithms for the problem provides a gentle introduction to a variety of core algorithm concepts, such as big O notation, divide and conquer algorithms, data structures, randomized algorithms, best, worst and average case analysis, time-space tradeoffs, and lower bounds. Classification Sorting algorithms used in computer science are often classified by: • Computational complexity (worst, average and best behaviour) of element comparisons in terms of the size of the list . For typical sorting algorithms good behavior is and bad behavior is . -

Visvesvaraya Technological University a Project Report
` VISVESVARAYA TECHNOLOGICAL UNIVERSITY “Jnana Sangama”, Belagavi – 590 018 A PROJECT REPORT ON “PREDICTIVE SCHEDULING OF SORTING ALGORITHMS” Submitted in partial fulfillment for the award of the degree of BACHELOR OF ENGINEERING IN COMPUTER SCIENCE AND ENGINEERING BY RANJIT KUMAR SHA (1NH13CS092) SANDIP SHAH (1NH13CS101) SAURABH RAI (1NH13CS104) GAURAV KUMAR (1NH13CS718) Under the guidance of Ms. Sridevi (Senior Assistant Professor, Dept. of CSE, NHCE) DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING NEW HORIZON COLLEGE OF ENGINEERING (ISO-9001:2000 certified, Accredited by NAAC ‘A’, Permanently affiliated to VTU) Outer Ring Road, Panathur Post, Near Marathalli, Bangalore – 560103 ` NEW HORIZON COLLEGE OF ENGINEERING (ISO-9001:2000 certified, Accredited by NAAC ‘A’ Permanently affiliated to VTU) Outer Ring Road, Panathur Post, Near Marathalli, Bangalore-560 103 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING CERTIFICATE Certified that the project work entitled “PREDICTIVE SCHEDULING OF SORTING ALGORITHMS” carried out by RANJIT KUMAR SHA (1NH13CS092), SANDIP SHAH (1NH13CS101), SAURABH RAI (1NH13CS104) and GAURAV KUMAR (1NH13CS718) bonafide students of NEW HORIZON COLLEGE OF ENGINEERING in partial fulfillment for the award of Bachelor of Engineering in Computer Science and Engineering of the Visvesvaraya Technological University, Belagavi during the year 2016-2017. It is certified that all corrections/suggestions indicated for Internal Assessment have been incorporated in the report deposited in the department library. The project report has been approved as it satisfies the academic requirements in respect of Project work prescribed for the Degree. Name & Signature of Guide Name Signature of HOD Signature of Principal (Ms. Sridevi) (Dr. Prashanth C.S.R.) (Dr. Manjunatha) External Viva Name of Examiner Signature with date 1. -

I. Sorting Networks Thomas Sauerwald
I. Sorting Networks Thomas Sauerwald Easter 2015 Outline Outline of this Course Introduction to Sorting Networks Batcher’s Sorting Network Counting Networks I. Sorting Networks Outline of this Course 2 Closely follow the book and use the same numberring of theorems/lemmas etc. I. Sorting Networks (Sorting, Counting, Load Balancing) II. Matrix Multiplication (Serial and Parallel) III. Linear Programming (Formulating, Applying and Solving) IV. Approximation Algorithms: Covering Problems V. Approximation Algorithms via Exact Algorithms VI. Approximation Algorithms: Travelling Salesman Problem VII. Approximation Algorithms: Randomisation and Rounding VIII. Approximation Algorithms: MAX-CUT Problem (Tentative) List of Topics Algorithms (I, II) Complexity Theory Advanced Algorithms I. Sorting Networks Outline of this Course 3 Closely follow the book and use the same numberring of theorems/lemmas etc. (Tentative) List of Topics Algorithms (I, II) Complexity Theory Advanced Algorithms I. Sorting Networks (Sorting, Counting, Load Balancing) II. Matrix Multiplication (Serial and Parallel) III. Linear Programming (Formulating, Applying and Solving) IV. Approximation Algorithms: Covering Problems V. Approximation Algorithms via Exact Algorithms VI. Approximation Algorithms: Travelling Salesman Problem VII. Approximation Algorithms: Randomisation and Rounding VIII. Approximation Algorithms: MAX-CUT Problem I. Sorting Networks Outline of this Course 3 (Tentative) List of Topics Algorithms (I, II) Complexity Theory Advanced Algorithms I. Sorting Networks (Sorting, Counting, Load Balancing) II. Matrix Multiplication (Serial and Parallel) III. Linear Programming (Formulating, Applying and Solving) IV. Approximation Algorithms: Covering Problems V. Approximation Algorithms via Exact Algorithms VI. Approximation Algorithms: Travelling Salesman Problem VII. Approximation Algorithms: Randomisation and Rounding VIII. Approximation Algorithms: MAX-CUT Problem Closely follow the book and use the same numberring of theorems/lemmas etc. -

Adaptive Bitonic Sorting
Encyclopedia of Parallel Computing “00101” — 2011/4/16 — 13:39 — Page 1 — #2 A One of the main di7erences between “regular” bitonic Adaptive Bitonic Sorting sorting and adaptive bitonic sorting is that regular bitonic sorting is data-independent, while adaptive G"#$%&' Z"()*"++ bitonic sorting is data-dependent (hence the name). Clausthal University, Clausthal-Zellerfeld, Germany As a consequence, adaptive bitonic sorting cannot be implemented as a sorting network, but only on archi- Definition tectures that o7er some kind of 9ow control. Nonethe- Adaptive bitonic sorting is a sorting algorithm suitable less, it is convenient to derive the method of adaptive for implementation on EREW parallel architectures. bitonic sorting from bitonic sorting. Similar to bitonic sorting, it is based on merging, which Sorting networks have a long history in computer is recursively applied to obtain a sorted sequence. In science research (see the comprehensive survey []). contrast to bitonic sorting, it is data-dependent. Adap- One reason is that sorting networks are a convenient tive bitonic merging can be performed in O n parallel p way to describe parallel sorting algorithms on CREW- time, p being the number of processors, and executes ! " PRAMs or even EREW-PRAMs (which is also called only O n operations in total. Consequently, adaptive n log n PRAC for “parallel random access computer”). bitonic sorting can be performed in O time, ( ) p In the following, let n denote the number of keys which is optimal. So, one of its advantages is that it exe- ! " to be sorted, and p the number of processors. For the cutes a factor of O log n less operations than bitonic sake of clarity, n will always be assumed to be a power sorting. -

An 11-Step Sorting Network for 18 Elements
An 11-Step Sorting Network for 18 Elements Sherenaz W. Al-Haj Baddar, Kenneth E. Batcher Kent State University Department of Computer Science Kent, Ohio 44240 [email protected] [email protected] output set must be a permutation of the input set {I1,I2,…,IN}. Abstract— Sorting Networks are cost-effective multistage Moreover, for every two elements of the output set Oj and Ok, interconnection networks with sorting capabilities. These Oj must be less than or equal to Ok whenever j ≤ k. networks theoretically consume Θ(NlogN) comparisons. However, Sorting networks are constructed using stages (steps) of the fastest implementable sorting networks built so far consume basic cells called Comparator Exchange(CE) modules. A CE is Θ(Nlog2N) comparisons, and generally, use the Merge-sorting a 2-element sorting circuit. It accepts two inputs via two input strategy to sort the input. An 18-element network using the Merge-sorting strategy needs at least 12 steps-here we show a lines, compares them and outputs the larger element on its high network that sorts 18 elements in only 11 steps. output line, whereas the smaller is output on its low output line. It is assumed that two comparators with disjoint inputs can operate in parallel. A typical CE is depicted in Figure 1[2]. Index Terms—Sorting Networks, Partial Ordering, 0/1 cases. I. INTRODUCTION Parallel processors are fast and powerful computing systems Figure 1. A comparator exchange module[2] that have been developed to help undertake computationally challenging problems. Deploying parallelism for solving a An optimal N-element sorting network requires θ(NlogN) given problem implies splitting the problem into subtasks. -

Bitonic Sort and Quick Sort
Assignment of bachelor’s thesis Title: Development of parallel sorting algorithms for GPU Student: Xuan Thang Nguyen Supervisor: Ing. Tomáš Oberhuber, Ph.D. Study program: Informatics Branch / specialization: Computer Science Department: Department of Theoretical Computer Science Validity: until the end of summer semester 2021/2022 Instructions 1. Study the basics of programming GPU using CUDA. 2. Learn the fundamentals of the development of parallel algorithms with TNL library (www.tnl- project.org). 3. Learn and understand parallel sorting algorithms, namely bitonic sort and quick sort. 4. Implement both algorithms into TNL library to run on CPU and GPU. 5. Implement unit tests for testing correctness of the implemented algorithms. 6. Perform measurement of speed-up compared to sorting algorithms in the STL library and GPU implementation [1]. [1] https://github.com/davors/gpu-sorting Electronically approved by doc. Ing. Jan Janoušek, Ph.D. on 30 November 2020 in Prague. Bachelor’s thesis Development of parallel sorting algorithms for GPU Nguyen Xuan Thang Department of Theoretical Computer Science Supervisor: Ing. Tomáš Oberhuber, Ph.D. May 13, 2021 Acknowledgements I would like to thank my supervisor Ing. Tomáš Oberhuber, Ph.D. for his sup- port, guidance and advices throughout the whole time of creating this thesis. My gratitude also goes to my family that helped me during these hard times. Declaration I hereby declare that the presented thesis is my own work and that I have cited all sources of information in accordance with the Guideline for adhering to ethical principles when elaborating an academic final thesis. I acknowledge that my thesis is subject to the rights and obligations stip- ulated by the Act No.