Information Extraction from Tv Series Scripts for Uptake Prediction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Spring 2011 Vancouver Prime Time TV Schedules 7 P.M
Spring 2011 Vancouver Prime Time TV Schedules 7 p.m. - 11 p.m. February 20 - March 12 2011 Monday Tuesday Wednesday Thursday Friday Saturday Sunday 7 Wheel of Fortune Heartland Jeopardy! 8 Little Mosque Rick Mercer Report Marketplace NHL Hockey Dragon's Den The Nature of Things 18 to Life InSecurity The Rick Mercer Report Movie 9 Village on a Diet The Pillars of the Earth Republic of Doyle Documentary the fifth estate HNIC After Hours 10 The National The National CBUT CBC News Make the Politician Work 7 Entertainment Tonight 16:9 The Bigger Picture Simpsons Entertainment Tonight Canada Family Restaurant American Dad 8 Survivor: Redemption Simpsons House Glee Wipeout Kitchen Nightmares Island Bob's Burgers Movie 9 The Office Family Guy The Chicago Code NCIS: Los Angeles NCIS 90210 The Office Cleveland Show 10 The Office Hawaii Five-0 The Good Wife Off the Map Haven The Guard Brothers & Sisters CHAN Outsourced 7 How I Met Your Mother what's cooking America's Funniest Home The Office The Most Amazing Videos 8 Community Who do you think you Glenn Martin, DDS Extreme Makeover: Home Minute to Win It Rules of Engagement are? Out There Edition The Bachelor The Biggest Loser 9 Modern Family How I Met Your Mother Fringe The Cape Cougar Town Parks & Recreation 10 30 Rock Movie Harry's Law Parenthood The Murdoch Mysteries Mantracker The Murdoch Mysteries CKVU Perfect Couples 7 eTalk eTalk eTalk eTalk CSI W-Five Undercover Boss The Big Bang Theory The Big Bang Theory The Big Bang Theory The Big Bang Theory 8 Mr. -

February 26, 2021 Amazon Warehouse Workers In
February 26, 2021 Amazon warehouse workers in Bessemer, Alabama are voting to form a union with the Retail, Wholesale and Department Store Union (RWDSU). We are the writers of feature films and television series. All of our work is done under union contracts whether it appears on Amazon Prime, a different streaming service, or a television network. Unions protect workers with essential rights and benefits. Most importantly, a union gives employees a seat at the table to negotiate fair pay, scheduling and more workplace policies. Deadline Amazon accepts unions for entertainment workers, and we believe warehouse workers deserve the same respect in the workplace. We strongly urge all Amazon warehouse workers in Bessemer to VOTE UNION YES. In solidarity and support, Megan Abbott (DARE ME) Chris Abbott (LITTLE HOUSE ON THE PRAIRIE; CAGNEY AND LACEY; MAGNUM, PI; HIGH SIERRA SEARCH AND RESCUE; DR. QUINN, MEDICINE WOMAN; LEGACY; DIAGNOSIS, MURDER; BOLD AND THE BEAUTIFUL; YOUNG AND THE RESTLESS) Melanie Abdoun (BLACK MOVIE AWARDS; BET ABFF HONORS) John Aboud (HOME ECONOMICS; CLOSE ENOUGH; A FUTILE AND STUPID GESTURE; CHILDRENS HOSPITAL; PENGUINS OF MADAGASCAR; LEVERAGE) Jay Abramowitz (FULL HOUSE; GROWING PAINS; THE HOGAN FAMILY; THE PARKERS) David Abramowitz (HIGHLANDER; MACGYVER; CAGNEY AND LACEY; BUCK JAMES; JAKE AND THE FAT MAN; SPENSER FOR HIRE) Gayle Abrams (FRASIER; GILMORE GIRLS) 1 of 72 Jessica Abrams (WATCH OVER ME; PROFILER; KNOCKING ON DOORS) Kristen Acimovic (THE OPPOSITION WITH JORDAN KLEPPER) Nick Adams (NEW GIRL; BOJACK HORSEMAN; -

Full House Tv Show Episodes Free Online
Full house tv show episodes free online Full House This is a story about a sports broadcaster later turned morning talk show host Danny Tanner and his three little Episode 1: Our Very First Show.Watch Full House Season 1 · Season 7 · Season 1 · Season 2. Full House - Season 1 The series chronicles a widowed father's struggles of raising Episode Pilot Episode 1 - Pilot - Our Very First Show Episode 2 - Our. Full House - Season 1 The series chronicles a widowed father's struggles of raising his three young daughters with the help of his brother-in-law and his. Watch Full House Online: Watch full length episodes, video clips, highlights and more. FILTER BY SEASON. All (); Season 8 (24); Season 7 (24); Season. Full House - Season 8 The final season starts with Comet, the dog, running away. The Rippers no longer want Jesse in their band. D.J. ends a relationship with. EPISODES. Full House. S1 | E1 Our Very First Show. S1 | E1 Full House. Full House. S1 | E2 Our Very First Night. S1 | E2 Full House. Full House. S1 | E3 The. Watch Series Full House Online. This is a story about a sports Latest Episode: Season 8 Episode 24 Michelle Rides Again (2) (). Season 8. Watch full episodes of Full House and get the latest breaking news, exclusive videos and pictures, episode recaps and much more at. Full House - Season 5 Season 5 opens with Jesse and Becky learning that Becky is carrying twins; Michelle and Teddy scheming to couple Danny with their. Full House (). 8 Seasons available with subscription. -

Photograph by Candace Dicarlo
60 MAY | JUNE 2013 THE PENNSYLVANIA GAZETTE PHOTOGRAPH BY CANDACE DICARLO Showtime CEO Matt Blank has used boundary-pushing programming, cutting-edge marketing, and smart management to build his cable network into a national powerhouse. By Susan Karlin SUBVERSIVE PRACTICALLY PRACTICALLY THE PENNSYLVANIA GAZETTE MAY | JUNE 2013 61 seems too … normal. “Matt runs the company in a very col- Showtime, Blank is involved with numer- This slim, understated, affa- legial way—he sets a tone among top man- ous media and non-profit organizations, Heble man speaking in tight, agers of cooperation, congeniality, and serving on the directing boards of the corporate phrases—monetizing the brand, loose boundaries that really works in a National Cable Television Association high-impact environments—this can’t be creative business,” says David Nevins, and The Cable Center, an industry edu- the guy whose whimsical vision has Showtime’s president of entertainment. cational arm. Then there are the frequent turned Weeds’ pot-dealing suburban “It helps create a sense of, ‘That’s a club trips to Los Angeles. mom, Dexter’s vigilante serial killer, and that I want to belong to.’ He stays focused “I’m an active person,” he adds. “I like Homeland’s bipolar CIA agent into TV on the big picture, maintaining the integ- a long day with a lot of different things heroes. Can it? rity of the brand and growing its exposure. going on. I think if I sat in a room and did Yet Matt Blank W’72, the CEO of Showtime, Matt is very savvy at this combination of one thing all day, I’d get frustrated.” has more in common with his network than programming and marketing that keeps his conventional appearance suggests. -

Black Magic & White Supremacy
Portland State University PDXScholar University Honors Theses University Honors College 2-23-2021 Black Magic & White Supremacy: Witchcraft as an Allegory for Race and Power Nicholas Charles Peters Portland State University Follow this and additional works at: https://pdxscholar.library.pdx.edu/honorstheses Part of the Film and Media Studies Commons, Race, Ethnicity and Post-Colonial Studies Commons, and the Television Commons Let us know how access to this document benefits ou.y Recommended Citation Peters, Nicholas Charles, "Black Magic & White Supremacy: Witchcraft as an Allegory for Race and Power" (2021). University Honors Theses. Paper 962. https://doi.org/10.15760/honors.986 This Thesis is brought to you for free and open access. It has been accepted for inclusion in University Honors Theses by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Black Magic & White Supremacy: Witchcraft as an Allegory for Race and Power By Nicholas Charles Peters An undergraduate honors thesis submitted in partial fulfillment of the requirements for the degree of Bachelor of Science in English and University Honors Thesis Adviser Dr. Michael Clark Portland State University 2021 1 “Being burned at the stake was an empowering experience. There are secrets in the flames, and I came back with more than a few” (Head 19’15”). Burning at the stake is one of the first things that comes to mind when thinking of witchcraft. Fire often symbolizes destruction or cleansing, expelling evil or unnatural things from creation. “Fire purges and purifies... scatters our enemies to the wind. -

Vita PDF Download
AMOR SCHUMACHER SYNCHRON (Rollen und Ensemble) Auswahl „The Dinner“ Splendid Nana Spier „Superstore“ BSG Frank Muth „Librarians“ Interopa Elke Weidemann „Billions“ Cinephon Reinhard Knapp „Patriots Day“ RC Bernhard Völger „Collateral Beauty“ FFS Marianne Gross „Christmas Office RC Kathrin Fröhlich Party“ „La La Land“ Cinephon Dr. Harald Wolff „House of Lies“ Cinephon Dr. Harald Wolff Wohnort: Berlin „Flikken Maastricht“ Antares Marc Böttcher Geburtsdatum: 14.08.1979 Sprachen: deutsch (Muttersprache), „Paradise“ Studio Funk Olaf Mierau spanisch (Muttersprache), „Homeland“ Cinephon Stephan Hoffmann englisch (fliessend), italienisch (GK) „Istanbul“ Taunusfilm Beate Klöckner Dialekte: hessisch, American English, „Better Call Saul“ BSG Frank Muth British English „Brigade“ SDI Uschi Hugo Akzente: englisch, spanisch, französisch, italienisch, arabisch „Bull“ Cinephon Stefan Ludwig Stimmlage: Alt „New Girl“ Cinephon Martin Schmitz „Bad Batch“ SDI Bernhard Völger Sprachberatung: Spanisch diverse Dialekte „Die irre Heldentour Interopa Christoph Cierpka des Billy Lynn“ „The Strain“ Cinephon Stefan Ludwig „Brotherhood“ Cinephon Wolfgang Ziffer AUSBILDUNG „Veep“ Cinephon Stefan Ludwig „Captain America: FFS Björn Schalla 2009, 2010, 2012 Larry Moss, Susan Civil War“ Batson Masterclass, „I Zombie“ Arena Synchron Gabrielle Pietermann Meisner Technique Mike Bernardin, Berlin „Relentless Justice“ Lautfabrik U.G. Benjamin Plath 2002 - 2006 Berliner Schule für „Longmire” FFS Marianne Gross Schauspiel „ScoobyDoo” SDI Sven Plate 2000 Method Studio London „Vampire -
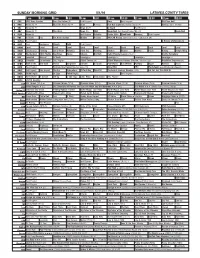
Sunday Morning Grid 5/1/16 Latimes.Com/Tv Times
SUNDAY MORNING GRID 5/1/16 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) Paid Program Boss Paid Program PGA Tour Golf 4 NBC News (N) Å Meet the Press (N) Å News Rescue Red Bull Signature Series (Taped) Å Hockey: Blues at Stars 5 CW News (N) Å News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) NBA Basketball First Round: Teams TBA. (N) Basketball 9 KCAL News (N) Joel Osteen Schuller Pastor Mike Woodlands Amazing Paid Program 11 FOX In Touch Paid Fox News Sunday Midday Prerace NASCAR Racing Sprint Cup Series: GEICO 500. (N) 13 MyNet Paid Program A History of Violence (R) 18 KSCI Paid Hormones Church Faith Paid Program 22 KWHY Local Local Local Local Local Local Local Local Local Local Local Local 24 KVCR Landscapes Painting Joy of Paint Wyland’s Paint This Painting Kitchen Mexico Martha Pépin Baking Simply Ming 28 KCET Wunderkind 1001 Nights Bug Bites Space Edisons Biz Kid$ Celtic Thunder Legacy (TVG) Å Soulful Symphony 30 ION Jeremiah Youssef In Touch Leverage Å Leverage Å Leverage Å Leverage Å 34 KMEX Conexión En contacto Paid Program Fútbol Central (N) Fútbol Mexicano Primera División: Toluca vs Azul República Deportiva (N) 40 KTBN Walk in the Win Walk Prince Carpenter Schuller In Touch PowerPoint It Is Written Pathway Super Kelinda Jesse 46 KFTR Paid Program Formula One Racing Russian Grand Prix. -

Why the Inimitable Sarah Paulson Is the Future Of
he won an Emmy, SAG Award and Golden Globe for her bravura performance as Marcia Clark in last year’s FX miniseries, The People v. O.J. Simpson: American Crime Story, but it took Sarah Paulson almost another year to confirm what the TV industry really thinks about her acting chops. Earlier this year, her longtime collaborator and O.J. executive producer Ryan Murphy offered the actress the lead in Ratched, an origin story he is executive producing that focuses on Nurse Ratched, the Siconic, sadistic nurse from the 1975 film One Flew Over the Cuckoo’s Nest. Murphy shopped the project around to networks, offering a package for the first time that included his frequent muse Paulson attached as star and producer. “That was very exciting and also very scary, because I thought, oh God, what if they take this out, and people are like, ‘No thanks, we’re good. We don’t need a Sarah Paulson show,’” says Paulson. “Thankfully, it all worked out very well.” In the wake of last year’s most acclaimed TV performance, everyone—TV networks and movie studios alike—wants to be in business with Paulson. Ratched sparked a high-stakes bidding war, with Netflix ultimately fending off suitors like Hulu and Apple (which is developing an original TV series strategy) for the project last month, giving the drama a hefty Why the inimitable two-season commitment. And that is only one of three high- profile TV series that Paulson will film over the next year. In Sarah Paulson is the 2018, she’ll begin production on Katrina, the third installment in Murphy’s American Crime Story anthology series for FX, and continue on the other Murphy FX anthology hit that future of TV. -
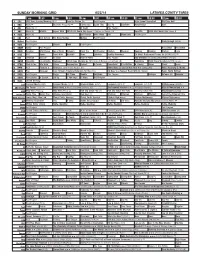
Sunday Morning Grid 6/22/14 Latimes.Com/Tv Times
SUNDAY MORNING GRID 6/22/14 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Morning (N) Å Face the Nation (N) Paid Program High School Basketball PGA Tour Golf 4 NBC News Å Meet the Press (N) Å Conference Justin Time Tree Fu LazyTown Auto Racing Golf 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Wildlife Exped. Wild 2014 FIFA World Cup Group H Belgium vs. Russia. (N) SportCtr 2014 FIFA World Cup: Group H 9 KCAL News (N) Joel Osteen Mike Webb Paid Woodlands Paid Program 11 FOX Paid Joel Osteen Fox News Sunday Midday Paid Program 13 MyNet Paid Program Crazy Enough (2012) 18 KSCI Paid Program Church Faith Paid Program 22 KWHY Como Paid Program RescueBot RescueBot 24 KVCR Painting Wild Places Joy of Paint Wyland’s Paint This Oil Painting Kitchen Mexican Cooking Cooking Kitchen Lidia 28 KCET Hi-5 Space Travel-Kids Biz Kid$ News LinkAsia Healthy Hormones Ed Slott’s Retirement Rescue for 2014! (TVG) Å 30 ION Jeremiah Youssef In Touch Hour of Power Paid Program Into the Blue ›› (2005) Paul Walker. (PG-13) 34 KMEX Conexión En contacto Backyard 2014 Copa Mundial de FIFA Grupo H Bélgica contra Rusia. (N) República 2014 Copa Mundial de FIFA: Grupo H 40 KTBN Walk in the Win Walk Prince Redemption Harvest In Touch PowerPoint It Is Written B. Conley Super Christ Jesse 46 KFTR Paid Fórmula 1 Fórmula 1 Gran Premio Austria. -

Getting to “The Pointe”
Running head: GETTING TO “THE POINTE” GETTING TO “THE POINTE”: ASSESSING THE LIGHT AND DARK DIMENSIONS OF LEADERSHIP ATTRIBUTES IN BALLET CULTURE Ashley Lauren Whitely B.A., Western Kentucky University, 2003 M.A., Western Kentucky University, 2006 Submitted to the Graduate Faculty under the supervision of Gail F. Latta, Ph.D. in partial fulfillment of the requirements for the degree of Doctor of Education in Leadership Studies Xavier University Cincinnati, OH May 2017 Running head: GETTING TO “THE POINTE” Running head: GETTING TO “THE POINTE” GETTING TO “THE POINTE”: ASSESSING THE LIGHT AND DARK DIMENSIONS OF LEADESHIP ATTRIBUTES IN BALLET CULTURE Ashley Lauren Whitely Dissertation Advisor: Gail F. Latta, Ph.D. Abstract The focus of this ethnographic study is to examine the industry-wide culture of the American ballet. Two additional research questions guided the investigation: what attributes, and their light and dark dimensions, are valued among individuals selected for leadership roles within the culture, and how does the ballet industry nurture these attributes? An understanding of the culture was garnered through observations and interviews conducted in three classically-based professional ballet companies in the United States: one located in the Rocky Mountain region, one in the Midwestern region, and one in the Pacific Northwest region. Data analysis brought forth cultural and leadership themes revealing an industry consumed by “the ideal” to the point that members are willing to make sacrifices, both at the individual and organizational levels, for the pursuit of beauty. The ballet culture was found to expect its leaders to manifest the light dimensions of attributes valued by the culture, because these individuals are elevated to the extent that they “become the culture,” but they also allow these individuals to simultaneously exemplify the dark dimensions of these attributes. -

Television Academy Awards
2019 Primetime Emmy® Awards Ballot Outstanding Comedy Series A.P. Bio Abby's After Life American Housewife American Vandal Arrested Development Atypical Ballers Barry Better Things The Big Bang Theory The Bisexual Black Monday black-ish Bless This Mess Boomerang Broad City Brockmire Brooklyn Nine-Nine Camping Casual Catastrophe Champaign ILL Cobra Kai The Conners The Cool Kids Corporate Crashing Crazy Ex-Girlfriend Dead To Me Detroiters Easy Fam Fleabag Forever Fresh Off The Boat Friends From College Future Man Get Shorty GLOW The Goldbergs The Good Place Grace And Frankie grown-ish The Guest Book Happy! High Maintenance Huge In France I’m Sorry Insatiable Insecure It's Always Sunny in Philadelphia Jane The Virgin Kidding The Kids Are Alright The Kominsky Method Last Man Standing The Last O.G. Life In Pieces Loudermilk Lunatics Man With A Plan The Marvelous Mrs. Maisel Modern Family Mom Mr Inbetween Murphy Brown The Neighborhood No Activity Now Apocalypse On My Block One Day At A Time The Other Two PEN15 Queen America Ramy The Ranch Rel Russian Doll Sally4Ever Santa Clarita Diet Schitt's Creek Schooled Shameless She's Gotta Have It Shrill Sideswiped Single Parents SMILF Speechless Splitting Up Together Stan Against Evil Superstore Tacoma FD The Tick Trial & Error Turn Up Charlie Unbreakable Kimmy Schmidt Veep Vida Wayne Weird City What We Do in the Shadows Will & Grace You Me Her You're the Worst Young Sheldon Younger End of Category Outstanding Drama Series The Affair All American American Gods American Horror Story: Apocalypse American Soul Arrow Berlin Station Better Call Saul Billions Black Lightning Black Summer The Blacklist Blindspot Blue Bloods Bodyguard The Bold Type Bosch Bull Chambers Charmed The Chi Chicago Fire Chicago Med Chicago P.D. -

NEEDLESS DEATHS in the GULF WAR Civilian Casualties During The
NEEDLESS DEATHS IN THE GULF WAR Civilian Casualties During the Air Campaign and Violations of the Laws of War A Middle East Watch Report Human Rights Watch New York $$$ Washington $$$ Los Angeles $$$ London Copyright 8 November 1991 by Human Rights Watch. All rights reserved. Printed in the United States of America. Cover design by Patti Lacobee Watch Committee Middle East Watch was established in 1989 to establish and promote observance of internationally recognized human rights in the Middle East. The chair of Middle East Watch is Gary Sick and the vice chairs are Lisa Anderson and Bruce Rabb. Andrew Whitley is the executive director; Eric Goldstein is the research director; Virginia N. Sherry is the associate director; Aziz Abu Hamad is the senior researcher; John V. White is an Orville Schell Fellow; and Christina Derry is the associate. Needless deaths in the Gulf War: civilian casualties during the air campaign and violations of the laws of war. p. cm -- (A Middle East Watch report) Includes bibliographical references. ISBN 1-56432-029-4 1. Persian Gulf War, 1991--United States. 2. Persian Gulf War, 1991-- Atrocities. 3. War victims--Iraq. 4. War--Protection of civilians. I. Human Rights Watch (Organization) II. Series. DS79.72.N44 1991 956.704'3--dc20 91-37902 CIP Human Rights Watch Human Rights Watch is composed of Africa Watch, Americas Watch, Asia Watch, Helsinki Watch, Middle East Watch and the Fund for Free Expression. The executive committee comprises Robert L. Bernstein, chair; Adrian DeWind, vice chair; Roland Algrant, Lisa Anderson, Peter Bell, Alice Brown, William Carmichael, Dorothy Cullman, Irene Diamond, Jonathan Fanton, Jack Greenberg, Alice H.