Data-To-Text Generation with Macro Planning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lansing Lugnuts Great Lakes Loons
History vs. Great Lakes Great Lakes Loons The Nuts are 3-4 this year and 118-115 all-time vs. Great Lakes, 67-60 in Michigan’s state High-A Affiliate, Los Angeles Dodgers • 18-19, T-4th capital and 51-55 at Dow Diamond. RHP Logan Boyer (3.12 ERA) Meeting Score Meeting Score 1. 5/25 at LAN W, 10-5 13. 7/6 at GL at 2. 5/26 at LAN L, 5-2 14. 7/7 at GL 3. 5/27 at LAN L, 10-1 15. 7/8 at GL 4. 5/28 at LAN L, 4-2 16. 7/9 at GL 5. 5/29 at LAN W, 7-3 17. 7/10 at GL Lansing Lugnuts 6. 5/30 at LAN L, 6-2 18. 7/11 at GL High-A Affiliate, Oakland Athletics • 18-19, T-4th 7. 6/15 at LAN W, 9-7 19. 8/17 at GL 8. 6/16 at LAN 20. 8/18 at GL RHP Seth Shuman (1.42 ERA) 9. 6/17 at LAN 21. 8/19 at GL 10. 6/18 at LAN 22. 8/20 at GL 11. 6/19 at LAN 23. 8/21 at GL JACKSON® FIELD™ LANSING, MI WEDNESDAY, JUNE 16, 2021 7:05 PM GAME 38 12. 6/20 at LAN 24. 8/22 at GL Tonight: Coming off a series-opening victory, the Lugnuts play the second game in a six-game series against the Great Lakes Loons, the eighth meeting of 24 between the two Michigan- based High-A clubs this season. -

Play Ball in Style
Manager: Scott Servais (9) NUMERICAL ROSTER 2 Tom Murphy C 3 J.P. Crawford INF 4 Shed Long Jr. INF 5 Jake Bauers INF 6 Perry Hill COACH 7 Marco Gonzales LHP 9 Scott Servais MANAGER 10 Jarred Kelenic OF 13 Abraham Toro INF 14 Manny Acta COACH 15 Kyle Seager INF 16 Drew Steckenrider RHP 17 Mitch Haniger OF 18 Yusei Kikuchi LHP 21 Tim Laker COACH 22 Luis Torrens C 23 Ty France INF 25 Dylan Moore INF 27 Matt Andriese RHP 28 Jake Fraley OF 29 Cal Raleigh C 31 Tyler Anderson LHP 32 Pete Woodworth COACH 33 Justus Sheffield LHP 36 Logan Gilbert RHP 37 Paul Sewald RHP 38 Anthony Misiewicz LHP 39 Carson Vitale COACH 40 Wyatt Mills RHP 43 Joe Smith RHP 48 Jared Sandberg COACH 50 Erik Swanson RHP 55 Yohan Ramirez RHP 63 Diego Castillo RHP 66 Fleming Baez COACH 77 Chris Flexen RHP 79 Trent Blank COACH 88 Jarret DeHart COACH 89 Nasusel Cabrera COACH 99 Keynan Middleton RHP SEATTLE MARINERS ROSTER NO. PITCHERS (14) B-T HT. WT. BORN BIRTHPLACE 31 Tyler Anderson L-L 6-2 213 12/30/89 Las Vegas, NV 27 Matt Andriese R-R 6-2 215 08/28/89 Redlands, CA 63 Diego Castillo (IL) R-R 6-3 250 01/18/94 Cabrera, DR 77 Chris Flexen R-R 6-3 230 07/01/94 Newark, CA PLAY BALL IN STYLE. 36 Logan Gilbert R-R 6-6 225 05/05/97 Apopka, FL MARINERS SUITES PROVIDE THE PERFECT 7 Marco Gonzales L-L 6-1 199 02/16/92 Fort Collins, CO 18 Yusei Kikuchi L-L 6-0 200 06/17/91 Morioka, Japan SETTING FOR YOUR NEXT EVENT. -
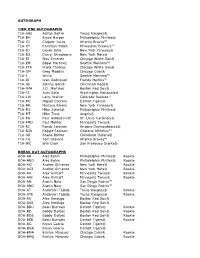
2021 Topps Tier One Checklist .Xls
AUTOGRAPH TIER ONE AUTOGRAPHS T1A-ABE Adrian Beltre Texas Rangers® T1A-BH Bryce Harper Philadelphia Phillies® T1A-CJ Chipper Jones Atlanta Braves™ T1A-CY Christian Yelich Milwaukee Brewers™ T1A-DJ Derek Jeter New York Yankees® T1A-DS Darryl Strawberry New York Mets® T1A-EJ Eloy Jimenez Chicago White Sox® T1A-EM Edgar Martinez Seattle Mariners™ T1A-FTA Frank Thomas Chicago White Sox® T1A-GM Greg Maddux Chicago Cubs® T1A-I Ichiro Seattle Mariners™ T1A-IR Ivan Rodriguez Florida Marlins™ T1A-JB Johnny Bench Cincinnati Reds® T1A-JMA J.D. Martinez Boston Red Sox® T1A-JS Juan Soto Washington Nationals® T1A-LW Larry Walker Colorado Rockies™ T1A-MC Miguel Cabrera Detroit Tigers® T1A-MR Mariano Rivera New York Yankees® T1A-MS Mike Schmidt Philadelphia Phillies® T1A-MT Mike Trout Angels® T1A-PG Paul Goldschmidt St. Louis Cardinals® T1A-PMO Paul Molitor Minnesota Twins® T1A-RJ Randy Johnson Arizona Diamondbacks® T1A-RJA Reggie Jackson Oakland Athletics™ T1A-SB Shane Bieber Cleveland Indians® T1A-TG Tom Glavine Atlanta Braves™ T1A-WC Will Clark San Francisco Giants® BREAK OUT AUTOGRAPHS BOA-AB Alec Bohm Philadelphia Phillies® Rookie BOA-ABO Alec Bohm Philadelphia Phillies® Rookie BOA-AG Andres Gimenez New York Mets® Rookie BOA-AGI Andres Gimenez New York Mets® Rookie BOA-AK Alex Kirilloff Minnesota Twins® Rookie BOA-AKI Alex Kirilloff Minnesota Twins® Rookie BOA-AN Austin Nola San Diego Padres™ BOA-ANO Austin Nola San Diego Padres™ BOA-AT Anderson Tejeda Texas Rangers® Rookie BOA-ATE Anderson Tejeda Texas Rangers® Rookie BOA-AV Alex Verdugo Boston -

2020 Topps Chrome Sapphire Edition .Xls
SERIES 1 1 Mike Trout Angels® 2 Gerrit Cole Houston Astros® 3 Nicky Lopez Kansas City Royals® 4 Robinson Cano New York Mets® 5 JaCoby Jones Detroit Tigers® 6 Juan Soto Washington Nationals® 7 Aaron Judge New York Yankees® 8 Jonathan Villar Baltimore Orioles® 9 Trent Grisham San Diego Padres™ Rookie 10 Austin Meadows Tampa Bay Rays™ 11 Anthony Rendon Washington Nationals® 12 Sam Hilliard Colorado Rockies™ Rookie 13 Miles Mikolas St. Louis Cardinals® 14 Anthony Rendon Angels® 15 San Diego Padres™ 16 Gleyber Torres New York Yankees® 17 Franmil Reyes Cleveland Indians® 18 Minnesota Twins® 19 Angels® Angels® 20 Aristides Aquino Cincinnati Reds® Rookie 21 Shane Greene Atlanta Braves™ 22 Emilio Pagan Tampa Bay Rays™ 23 Christin Stewart Detroit Tigers® 24 Kenley Jansen Los Angeles Dodgers® 25 Kirby Yates San Diego Padres™ 26 Kyle Hendricks Chicago Cubs® 27 Milwaukee Brewers™ Milwaukee Brewers™ 28 Tim Anderson Chicago White Sox® 29 Starlin Castro Washington Nationals® 30 Josh VanMeter Cincinnati Reds® 31 American League™ 32 Brandon Woodruff Milwaukee Brewers™ 33 Houston Astros® Houston Astros® 34 Ian Kinsler San Diego Padres™ 35 Adalberto Mondesi Kansas City Royals® 36 Sean Doolittle Washington Nationals® 37 Albert Almora Chicago Cubs® 38 Austin Nola Seattle Mariners™ Rookie 39 Tyler O'neill St. Louis Cardinals® 40 Bobby Bradley Cleveland Indians® Rookie 41 Brian Anderson Miami Marlins® 42 Lewis Brinson Miami Marlins® 43 Leury Garcia Chicago White Sox® 44 Tommy Edman St. Louis Cardinals® 45 Mitch Haniger Seattle Mariners™ 46 Gary Sanchez New York Yankees® 47 Dansby Swanson Atlanta Braves™ 48 Jeff McNeil New York Mets® 49 Eloy Jimenez Chicago White Sox® Rookie 50 Cody Bellinger Los Angeles Dodgers® 51 Anthony Rizzo Chicago Cubs® 52 Yasmani Grandal Chicago White Sox® 53 Pete Alonso New York Mets® 54 Hunter Dozier Kansas City Royals® 55 Jose Martinez St. -

MLB Curt Schilling Red Sox Jersey MLB Pete Rose Reds Jersey MLB
MLB Curt Schilling Red Sox jersey MLB Pete Rose Reds jersey MLB Wade Boggs Red Sox jersey MLB Johnny Damon Red Sox jersey MLB Goose Gossage Yankees jersey MLB Dwight Goodin Mets jersey MLB Adam LaRoche Pirates jersey MLB Jose Conseco jersey MLB Jeff Montgomery Royals jersey MLB Ned Yost Royals jersey MLB Don Larson Yankees jersey MLB Bruce Sutter Cardinals jersey MLB Salvador Perez All Star Royals jersey MLB Bubba Starling Royals baseball bat MLB Salvador Perez Royals 8x10 framed photo MLB Rolly Fingers 8x10 framed photo MLB Joe Garagiola Cardinals 8x10 framed photo MLB George Kell framed plaque MLB Salvador Perez bobblehead MLB Bob Horner helmet MLB Salvador Perez Royals sports drink bucket MLB Salvador Perez Royals sports drink bucket MLB Frank White and Willie Wilson framed photo MLB Salvador Perez 2015 Royals World Series poster MLB Bobby Richardson baseball MLB Amos Otis baseball MLB Mel Stottlemyre baseball MLB Rod Gardenhire baseball MLB Steve Garvey baseball MLB Mike Moustakas baseball MLB Heath Bell baseball MLB Danny Duffy baseball MLB Frank White baseball MLB Jack Morris baseball MLB Pete Rose baseball MLB Steve Busby baseball MLB Billy Shantz baseball MLB Carl Erskine baseball MLB Johnny Bench baseball MLB Ned Yost baseball MLB Adam LaRoche baseball MLB Jeff Montgomery baseball MLB Tony Kubek baseball MLB Ralph Terry baseball MLB Cookie Rojas baseball MLB Whitey Ford baseball MLB Andy Pettitte baseball MLB Jorge Posada baseball MLB Garrett Cole baseball MLB Kyle McRae baseball MLB Carlton Fisk baseball MLB Bret Saberhagen baseball -

Padres Press Clips Thursday, May 22, 2014
Padres Press Clips Thursday, May 22, 2014 Article Source Author Page Padres are shut out for eighth time this season MLB.com Miller 2 Play stands after Twins challenge call vs. Padres MLB.com Miller 5 Roach to get second start, filling in for Cashner MLB.com Miller 6 Cubs open set in Renteria's old stomping grounds MLB.com Muskat 7 Jones, Nelson to represent Padres at Draft MLB.com Miller 10 Padres lead the Majors in close games MLB.com Miller 11 Black tries Alonso in cleanup spot MLB.com Miller 12 Grandal takes responsibility for wild pitches MLB.com Miller 13 Kennedy’s Home vs. Away Anomaly FriarWire Center 14 NLCS Victory over Cubs Capped Historic 1984 Season FriarWire Center 16 From the Farm, 5/20/14: Peterson off Fast in El Paso FriarWire Center 18 Again, Padres' bats can't support Ross UT San Diego Sanders 19 Padres' Roach preparing for second start UT San Diego Sanders 21 Mound visits: More than a walk in the park UT San Diego Lin 23 Minors: Another rocky start for Wisler UT San Diego Lin 26 Morning links: 'Filthy' Ross loves Petco UT San Diego Sanders 27 Pregame: Rivera has pop to go with glove UT San Diego Sanders 28 Padres waste Ross' outing in 2-0 loss to Twins Associated Press AP 29 Geer 's Passion Still Motivates Him SAMissions.com Turner 32 1 Padres are shut out for eighth time this season Ross strikes out eight in strong outing, but takes loss By Scott Miller / Special to MLB.com | 5/22/2014 12:58 AM ET SAN DIEGO -- If things keep going the way they're going, the Padres offensive numbers are going to go from bad to invisible. -

Baltimore Orioles Game Notes
BALTIMORE ORIOLES GAME NOTES ORIOLE PARK AT CAMDEN YARDS • 333 WEST CAMDEN STREET • BALTIMORE, MD 21201 MONDAY, AUGUST 20, 2018 • GAME #125 • ROAD GAME #64 BALTIMORE ORIOLES (37-87) at TORONTO BLUE JAYS (55-69) RHP Andrew Cashner (4-10, 4.71) vs. RHP Marco Estrada (6-9, 4.87) CEDRIC THE ENTERTAINER: OF Cedric Mullins went 2-for-3 on Sunday at Cleveland and hit his first career home run Saturday...Since I’VE GOT YOUR BACK making his Major League debut on August 10, he is batting .387 (12-for-31) and six of his 12 hits are extra-base hits...Mullins has five Lowest inherited runners scored percentage in doubles through nine career games...He is the first Orioles batter with at least five doubles through nine career games since current Orioles the American League (by team): assistant hitting coach Howie Clark notched five doubles in 2002...Since making his debut on August 10, Mullins’ .387 batting average 1. Los Angeles-AL 20.6% (43-of-209) leads AL rookies and ranks second in the majors among rookies behind Atlanta’s Ronald Acuña, Jr. (.450)...His five doubles since August 2. Houston 24.6% (32-of-130) 10 are tied for second-most in the majors among rookies. 3. Cleveland 27.0% (48-for-178) 4. Boston 28.2% (37-of-131) BREAKING NEWS: The Orioles rank among league leaders in several major offensive categories since the All-Star break, including 5. BALTIMORE 29.1% (67-of-230) ranking third in the majors in batting average at .276 (257-for-931)...They have recorded 257 hits in 26 games since the All-Star break, 6. -

List of Players in Apba's 2018 Base Baseball Card
Sheet1 LIST OF PLAYERS IN APBA'S 2018 BASE BASEBALL CARD SET ARIZONA ATLANTA CHICAGO CUBS CINCINNATI David Peralta Ronald Acuna Ben Zobrist Scott Schebler Eduardo Escobar Ozzie Albies Javier Baez Jose Peraza Jarrod Dyson Freddie Freeman Kris Bryant Joey Votto Paul Goldschmidt Nick Markakis Anthony Rizzo Scooter Gennett A.J. Pollock Kurt Suzuki Willson Contreras Eugenio Suarez Jake Lamb Tyler Flowers Kyle Schwarber Jesse Winker Steven Souza Ender Inciarte Ian Happ Phillip Ervin Jon Jay Johan Camargo Addison Russell Tucker Barnhart Chris Owings Charlie Culberson Daniel Murphy Billy Hamilton Ketel Marte Dansby Swanson Albert Almora Curt Casali Nick Ahmed Rene Rivera Jason Heyward Alex Blandino Alex Avila Lucas Duda Victor Caratini Brandon Dixon John Ryan Murphy Ryan Flaherty David Bote Dilson Herrera Jeff Mathis Adam Duvall Tommy La Stella Mason Williams Daniel Descalso Preston Tucker Kyle Hendricks Luis Castillo Zack Greinke Michael Foltynewicz Cole Hamels Matt Harvey Patrick Corbin Kevin Gausman Jon Lester Sal Romano Zack Godley Julio Teheran Jose Quintana Tyler Mahle Robbie Ray Sean Newcomb Tyler Chatwood Anthony DeSclafani Clay Buchholz Anibal Sanchez Mike Montgomery Homer Bailey Matt Koch Brandon McCarthy Jaime Garcia Jared Hughes Brad Ziegler Daniel Winkler Steve Cishek Raisel Iglesias Andrew Chafin Brad Brach Justin Wilson Amir Garrett Archie Bradley A.J. Minter Brandon Kintzler Wandy Peralta Yoshihisa Hirano Sam Freeman Jesse Chavez David Hernandez Jake Diekman Jesse Biddle Pedro Strop Michael Lorenzen Brad Boxberger Shane Carle Jorge de la Rosa Austin Brice T.J. McFarland Jonny Venters Carl Edwards Jackson Stephens Fernando Salas Arodys Vizcaino Brian Duensing Matt Wisler Matt Andriese Peter Moylan Brandon Morrow Cody Reed Page 1 Sheet1 COLORADO LOS ANGELES MIAMI MILWAUKEE Charlie Blackmon Chris Taylor Derek Dietrich Lorenzo Cain D.J. -

2018 Topps Series 1 Checklist Finala
2018 TOPPS BASEBALL SERIES 1 BASE CARDS A.J. Pollock Arizona Diamondbacks® A.J. Ramos New York Mets® Aaron Judge New York Yankees® Aaron Judge New York Yankees® League Leaders Aaron Judge New York Yankees® League Leaders Aaron Nola Philadelphia Phillies® Aaron Sanchez Toronto Blue Jays® Aaron Slegers Minnesota Twins® Rookie Adam Jones Baltimore Orioles® Adam Wainwright St. Louis Cardinals® Adeiny Hechavarria Tampa Bay Rays™ Adrian Beltre Texas Rangers® Aledmys Diaz St. Louis Cardinals® Alex Avila Chicago Cubs® Alex Bregman Houston Astros® Alex Bregman Houston Astros® World Series Highlights Alex Colome Tampa Bay Rays™ Alex Verdugo Los Angeles Dodgers® Rookie Alex Wood Los Angeles Dodgers® Amed Rosario New York Mets® Rookie American League™ American League™ Combo Cards Amir Garrett Cincinnati Reds® Andrelton Simmons Angels® Andrew Cashner Texas Rangers® Andrew McCutchen Pittsburgh Pirates® Andrew Miller Cleveland Indians® Andrew Stevenson Washington Nationals® Rookie Anthony Banda Arizona Diamondbacks® Rookie Anthony Rendon Washington Nationals® Anthony Rizzo Chicago Cubs® Antonio Senzatela Colorado Rockies™ Ariel Miranda Seattle Mariners™ Austin Hays Baltimore Orioles® Rookie Avisail Garcia Chicago White Sox® Avisail Garcia Chicago White Sox® League Leaders Billy Hamilton Cincinnati Reds® Boston Red Sox® Boston Red Sox® Combo Cards Brad Hand San Diego Padres™ Brandon Belt San Francisco Giants® Brandon Drury Arizona Diamondbacks® Brandon Finnegan Cincinnati Reds® Brandon McCarthy Los Angeles Dodgers® Brandon Phillips Angels® Brandon Woodruff -

Weekly Notes 072817
MAJOR LEAGUE BASEBALL WEEKLY NOTES FRIDAY, JULY 28, 2017 BLACKMON WORKING TOWARD HISTORIC SEASON On Sunday afternoon against the Pittsburgh Pirates at Coors Field, Colorado Rockies All-Star outfi elder Charlie Blackmon went 3-for-5 with a pair of runs scored and his 24th home run of the season. With the round-tripper, Blackmon recorded his 57th extra-base hit on the season, which include 20 doubles, 13 triples and his aforementioned 24 home runs. Pacing the Majors in triples, Blackmon trails only his teammate, All-Star Nolan Arenado for the most extra-base hits (60) in the Majors. Blackmon is looking to become the fi rst Major League player to log at least 20 doubles, 20 triples and 20 home runs in a single season since Curtis Granderson (38-23-23) and Jimmy Rollins (38-20-30) both accomplished the feat during the 2007 season. Since 1901, there have only been seven 20-20-20 players, including Granderson, Rollins, Hall of Famers George Brett (1979) and Willie Mays (1957), Jeff Heath (1941), Hall of Famer Jim Bottomley (1928) and Frank Schulte, who did so during his MVP-winning 1911 season. Charlie would become the fi rst Rockies player in franchise history to post such a season. If the season were to end today, Blackmon’s extra-base hit line (20-13-24) has only been replicated by 34 diff erent players in MLB history with Rollins’ 2007 season being the most recent. It is the fi rst stat line of its kind in Rockies franchise history. Hall of Famer Lou Gehrig is the only player in history to post such a line in four seasons (1927-28, 30-31). -

2009 Draysbay Season Preview
DRaysBay Season Preview 2009 1 DRaysBay Season Preview 2009 DRAYSBAY 09 Season Preview ________________________________________________________________________ CHANGE GONNA COME BY MARC NORMANDIN ................................................................ 6 INTRODUCTION BY R.J. ANDERSON ....................................................................................... 8 DUMPING THE CLICHÉS BY R.J. ANDERSON....................................................................... 9 THE MAGNIFICENT 10 BY TOMMY RANCEL ....................................................................... 14 COMMUNITY PROJECTIONS..................................................................................................... 19 MAJOR LEAGUE TYPES............................................................................................................... 21 WILLY AYBAR UTL .......................................................................................................................... 21 GRANT BALFOUR RHP...................................................................................................................... 21 JASON BARTLETT SS......................................................................................................................... 21 CHAD BRADFORD RHP ..................................................................................................................... 22 PAT BURRELL DH/OF...................................................................................................................... -

Slsl Strat-O-Matic League Rosters As of September 18, 2010
SLSL STRAT-O-MATIC LEAGUE ROSTERS AS OF SEPTEMBER 18, 2010 ARIZONA HEAT CALIFORNIA DRAGONS CEN VALLEY CONDORS CHESAPEAKE CRABS 1 BRETT ANDERSON OAK 1 BILLY BUTLER KCR 1 DANIEL BARD BOS 1 BOBBY ABREU LAA 2 ANDREW BAILEY OAK 2 J.D. DREW BOS 2 RYAN BRAUN MIL 2 ERICK AYBAR LAA 3 JOSH BECKETT BOS 3 PRINCE FIELDER MIL 3 PAT BURRELL SFG 3 MIGUEL CABRERA DET 4 LANCE BERKMAN HOU 4 GAVIN FLOYD CWS 4 ROBINSON CANO NYY 4 CRAIG COUNSELL MIL 5 JAY BRUCE CIN 5 FRANKLIN GUTIERREZ SEA 5 KOSUKE FUKUDOME CHC 5 CARL CRAWFORD TBR 6 JOHN BUCK KCR 6 JASON HAMMEL COL 6 JON GARLAND AZH 6 R.A. DICKEY NYM 7 SHIN-SOO CHOO CLE 7 PAUL JANISH CIN 7 LUKE GREGORSON SDP 7 ANGEL GUZMAN CHC 8 CHRIS COGHLAN FLA 8 MATTHEW JOYCE TBR 8 TOMMY HANSON ATL 8 DAN HAREN ARI 9 JOHNNY CUETO CIN 9 MAT LATOS SDP 9 J.A. HAPP PHI 9 JOSH JOHNSON FLA 10 STEPHEN DREW ARI 10 CARLOS LEE HOU 10 COREY HART MIL 10 CLAYTON KERSHAW LAD 11 DEXTER FOWLER COL 11 DAISUKE MATSUZAKA BOS 11 RYAN HOWARD PHI 11 FRANCiSCO LIRIANO MIN 12 TOM GORZELANNY CHC 12 JOE MAUER MIN 12 EDWIN JACKSON DET 12 VICTOR MARTINEZ BOS 13 TOMMY HUNTER TEX 13 DUSTIN PEDROIA BOS 13 JOHN LACKEY LAA 13 YADIER MOLINA STL 14 JAIR JURRJENS ATL 14 HUNTER PENCE HOU 14 RUSSELL MARTIN LAD 14 JUSTIN MORNEAU MIN 15 HOWIE KENDRICK LAA 15 RICK PORCELLO DET 15 KYLE MCLELLAN STL 15 NYJER MORGAN WAS 16 TED LILLY CHC 16 HANLEY RAMIREZ FLA 16 KENDRY MORALES LAA 16 DARREN O'DAY TEX 17 JAMES LONEY LAD 17 FRANCISCO RODRIGUEZ NYM 17 SCOTT PODSEDNIK CWS 17 JAKE PEAVY CWS 18 KRIS MEDLEN ATL 18 WANDY RODRIGUEZ HOU 18 SCOTT ROLEN TOR 18 RYAN RABURN DET