The Politics of Random Assignment: Implementing Studies and Impacting Policy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Survey Experiments
IU Workshop in Methods – 2019 Survey Experiments Testing Causality in Diverse Samples Trenton D. Mize Department of Sociology & Advanced Methodologies (AMAP) Purdue University Survey Experiments Page 1 Survey Experiments Page 2 Contents INTRODUCTION ............................................................................................................................................................................ 8 Overview .............................................................................................................................................................................. 8 What is a survey experiment? .................................................................................................................................... 9 What is an experiment?.............................................................................................................................................. 10 Independent and dependent variables ................................................................................................................. 11 Experimental Conditions ............................................................................................................................................. 12 WHY CONDUCT A SURVEY EXPERIMENT? ........................................................................................................................... 13 Internal, external, and construct validity .......................................................................................................... -

Analysis of Variance and Analysis of Variance and Design of Experiments of Experiments-I
Analysis of Variance and Design of Experimentseriments--II MODULE ––IVIV LECTURE - 19 EXPERIMENTAL DESIGNS AND THEIR ANALYSIS Dr. Shalabh Department of Mathematics and Statistics Indian Institute of Technology Kanpur 2 Design of experiment means how to design an experiment in the sense that how the observations or measurements should be obtained to answer a qqyuery inavalid, efficient and economical way. The desigggning of experiment and the analysis of obtained data are inseparable. If the experiment is designed properly keeping in mind the question, then the data generated is valid and proper analysis of data provides the valid statistical inferences. If the experiment is not well designed, the validity of the statistical inferences is questionable and may be invalid. It is important to understand first the basic terminologies used in the experimental design. Experimental unit For conducting an experiment, the experimental material is divided into smaller parts and each part is referred to as experimental unit. The experimental unit is randomly assigned to a treatment. The phrase “randomly assigned” is very important in this definition. Experiment A way of getting an answer to a question which the experimenter wants to know. Treatment Different objects or procedures which are to be compared in an experiment are called treatments. Sampling unit The object that is measured in an experiment is called the sampling unit. This may be different from the experimental unit. 3 Factor A factor is a variable defining a categorization. A factor can be fixed or random in nature. • A factor is termed as fixed factor if all the levels of interest are included in the experiment. -

Key Items to Get Right When Conducting Randomized Controlled Trials of Social Programs
Key Items to Get Right When Conducting Randomized Controlled Trials of Social Programs February 2016 This publication was produced by the Evidence-Based Policy team of the Laura and John Arnold Foundation (now Arnold Ventures). This publication is in the public domain. Authorization to reproduce it in whole or in part for educational purposes is granted. We welcome comments and suggestions on this document ([email protected]). 1 Purpose This is a checklist of key items to get right when conducting a randomized controlled trial (RCT) to evaluate a social program or practice. The checklist is designed to be a practical resource for researchers and sponsors of research. It describes items that are critical to the success of an RCT in producing valid findings about a social program’s effectiveness. This document is limited to key items, and does not address all contingencies that may affect a study’s success.1 Items in this checklist are categorized according to the following phases of an RCT: 1. Planning the study; 2. Carrying out random assignment; 3. Measuring outcomes for the study sample; and 4. Analyzing the study results. 1. Key items to get right in planning the study Choose (i) the program to be evaluated, (ii) target population for the study, and (iii) key outcomes to be measured. These should include, wherever possible, ultimate outcomes of policy importance. As illustrative examples: . An RCT of a pregnancy prevention program preferably should measure outcomes such as pregnancies or births, and not just intermediate outcomes such as condom use. An RCT of a remedial reading program preferably should measure outcomes such as reading comprehension, and not just participants’ ability to sound out words. -

Chapter 5 Experiments, Good And
Chapter 5 Experiments, Good and Bad Point of both observational studies and designed experiments is to identify variable or set of variables, called explanatory variables, which are thought to predict outcome or response variable. Confounding between explanatory variables occurs when two or more explanatory variables are not separated and so it is not clear how much each explanatory variable contributes in prediction of response variable. Lurking variable is explanatory variable not considered in study but confounded with one or more explanatory variables in study. Confounding with lurking variables effectively reduced in randomized comparative experiments where subjects are assigned to treatments at random. Confounding with a (only one at a time) lurking variable reduced in observational studies by controlling for it by comparing matched groups. Consequently, experiments much more effec- tive than observed studies at detecting which explanatory variables cause differences in response. In both cases, statistically significant observed differences in average responses implies differences are \real", did not occur by chance alone. Exercise 5.1 (Experiments, Good and Bad) 1. Randomized comparative experiment: effect of temperature on mice rate of oxy- gen consumption. For example, mice rate of oxygen consumption 10.3 mL/sec when subjected to 10o F. temperature (Fo) 0 10 20 30 ROC (mL/sec) 9.7 10.3 11.2 14.0 (a) Explanatory variable considered in study is (choose one) i. temperature ii. rate of oxygen consumption iii. mice iv. mouse weight 25 26 Chapter 5. Experiments, Good and Bad (ATTENDANCE 3) (b) Response is (choose one) i. temperature ii. rate of oxygen consumption iii. -

How to Do Random Allocation (Randomization) Jeehyoung Kim, MD, Wonshik Shin, MD
Special Report Clinics in Orthopedic Surgery 2014;6:103-109 • http://dx.doi.org/10.4055/cios.2014.6.1.103 How to Do Random Allocation (Randomization) Jeehyoung Kim, MD, Wonshik Shin, MD Department of Orthopedic Surgery, Seoul Sacred Heart General Hospital, Seoul, Korea Purpose: To explain the concept and procedure of random allocation as used in a randomized controlled study. Methods: We explain the general concept of random allocation and demonstrate how to perform the procedure easily and how to report it in a paper. Keywords: Random allocation, Simple randomization, Block randomization, Stratified randomization Randomized controlled trials (RCT) are known as the best On the other hand, many researchers are still un- method to prove causality in spite of various limitations. familiar with how to do randomization, and it has been Random allocation is a technique that chooses individuals shown that there are problems in many studies with the for treatment groups and control groups entirely by chance accurate performance of the randomization and that some with no regard to the will of researchers or patients’ con- studies are reporting incorrect results. So, we will intro- dition and preference. This allows researchers to control duce the recommended way of using statistical methods all known and unknown factors that may affect results in for a randomized controlled study and show how to report treatment groups and control groups. the results properly. Allocation concealment is a technique used to pre- vent selection bias by concealing the allocation sequence CATEGORIES OF RANDOMIZATION from those assigning participants to intervention groups, until the moment of assignment. -

Random Assignment
7 RANDOM ASSIGNMENT Just as representativeness can be secured by the method of chance . so equivalence may be secured by chance.1distribute —W. A. McCall or LEARNING OBJECTIVES • Understand what random assignment does and how it works. • Produce a valid randomization processpost, for an experiment and describe it. • Critique simple random assignment, blocking, matched pairs, and stratified random assignment. • Explain the importance of counterbalancing. • Describe a Latincopy, square design. ust as the mantra in real estate is “location, location, location,” the motto in experi- Jmental design is “random assignment, random assignment, random assignment.” This notbook has discussed random assignment all throughout. It bears repeating that ran- dom assignment is the single most important thing a researcher can do in an experiment. Everything else pales in comparison to having done this correctly.2 Random assignment is what distinguishes a true experiment from a quasi, natural, or pre-experimental design. In Dochapter 1, experiments were referred to as the gold standard. Without successful random 173 Copyright ©2019 by SAGE Publications, Inc. This work may not be reproduced or distributed in any form or by any means without express written permission of the publisher. 174 Designing Experiments for the Social Sciences assignment, however, they can quickly become “the bronze standard.”3 This chapter will review some of the advantages of random assignment, discuss the details of how to do it, and explore related issues of counterbalancing. THE PURPOSE OF RANDOM ASSIGNMENT People vary. That is, they are different. Were this not so, there would be no reason to study them. Everyone would be the same, reacting the same way to different teaching techniques, advertisements, health interventions, and political messages. -

Introduction to Impact Evaluation in Social Epidemiology and Public Health
Introduction to Impact Evaluation in Social Epidemiology and Public Health Sam Harper Arijit Nandi McGill University Epi Tools Workshop Series, UCSF, 13 April 2017 1 / 194 Outline 1 What is Impact Evaluation? 2 Evaluating: Randomized studies Pre-randomization phase Randomization phase 3 Evaluating: Non-randomized studies Problems with non-randomized studies Instrumental Variables Regression discontinuity ITS and Difference-in-Differences 4 Concluding thoughts 5 References 2 / 194 This is an “Epi Tools” workshop What’s in your toolbox? 4 / 194 Causation, Association, and Confounding Causal effect: Do individuals randomly assigned (i.e., SET) to treatment have better outcomes? E (Y jSET [Treated]) − E (Y jSET [Untreated]) Association: Do individuals who happen to be treated have better outcomes? E (Y jTreated) − E(Y jUntreated) Confounding [Omitted Variable Bias] : E (Y jSET [Treated]) − E (Y jSET [Untreated]) 6= E (Y jTreated) − E (Y jUntreated) 5 / 194 Effect of what? Questions about effects are expressed as counterfactual contrasts. We can write the average causal effect (ACE) or average treatment effect (ATE) in terms of potential outcomes: E Y a=1 − E Y a=0 indicating potential outcomes for an individual under two possible treatments. Consistency assumption: Y a = a for every individual with A = a. Problematic when there are multiple versions of the treatment, or when we do not have control over treatment assignment. We need well-defined treatments. Hernan 2016[1], among others. 6 / 194 Here’s a question: Does obesity shorten life? The increased emphasis on causal inference in epidemiology has generated some acrimonious debate:* Vandenbroucke, Pearce, Broadbent, Krieger, Davey Smith, Ebrahim, Schwartz, etc.. -

AP Statistics – 5.2 Designing Experiments – Notes
AP Statistics – 5.2 Designing Experiments – Notes 1. Observational Study – we observe individuals and measure variables of interest but do not attempt to influence the responses. 2. Experiment – we deliberately impose some treatment on (that is, do something to) individuals in order to observe their responses. a. Experimental Units – individuals in which the experiment is done b. Subjects – humans in an experiment c. Treatment – specific experimental condition applied to the units d. Double-Blind Experiment –neither the subjects nor those who measure the response variable know which treatment a subject received. 3. Purpose of Experiments – to reveal the response of one variable to changes in other variables. Experiments can give good evidence for causation. a. Factors – explanatory variables in experiments b. Level – When experiments study joint effects of several factors, each treatment is formed by combining a specific value (level) of each factor. 4. Forms of Control a. Comparison – determine differences/results from two or more groups (only valid when the treatments are given to similar groups of experimental units). Comparison helps ensure that all outside influences affect both groups the same. i. Control Group – the group which receives a placebo (fake treatment) in order to control lurking/confounding variables. ii. Experimental Group – the group that receives the actual treatment b. Replication – use enough subjects to reduce chance variation. c. Randomization – use chance to divide experimental units into groups (without judgment of the experimenter or any characteristic of the experimental units). The two groups are similar before treatments are applied. 5. Random Selection & Random Assignment a. Random Selection is where the subjects are randomly selected from the population. -

Study Designs and Their Outcomes
© Jones & Bartlett Learning, LLC © Jones & Bartlett Learning, LLC NOT FOR SALE OR DISTRIBUTION NOT FOR SALE OR DISTRIBUTION © Jones & Bartlett Learning, LLC © Jones & Bartlett Learning, LLC CHAPTERNOT FOR SALE 3 OR DISTRIBUTION NOT FOR SALE OR DISTRIBUTION © JonesStudy & Bartlett Designs Learning, LLC and Their Outcomes© Jones & Bartlett Learning, LLC NOT FOR SALE OR DISTRIBUTION NOT FOR SALE OR DISTRIBUTION “Natural selection is a mechanism for generating an exceedingly high degree of improbability.” —Sir Ronald Aylmer Fisher Peter Wludyka © Jones & Bartlett Learning, LLC © Jones & Bartlett Learning, LLC NOT FOR SALE OR DISTRIBUTION NOT FOR SALE OR DISTRIBUTION OBJECTIVES ______________________________________________________________________________ • Define research design, research study, and research protocol. • Identify the major features of a research study. • Identify© Jonesthe four types& Bartlett of designs Learning,discussed in this LLC chapter. © Jones & Bartlett Learning, LLC • DescribeNOT nonexperimental FOR SALE designs, OR DISTRIBUTIONincluding cohort, case-control, and cross-sectionalNOT studies. FOR SALE OR DISTRIBUTION • Describe the types of epidemiological parameters that can be estimated with exposed cohort, case-control, and cross-sectional studies along with the role, appropriateness, and interpreta- tion of relative risk and odds ratios in the context of design choice. • Define true experimental design and describe its role in assessing cause-and-effect relation- © Jones &ships Bartlett along with Learning, definitions LLCof and discussion of the role of ©internal Jones and &external Bartlett validity Learning, in LLC NOT FOR evaluatingSALE OR designs. DISTRIBUTION NOT FOR SALE OR DISTRIBUTION • Describe commonly used experimental designs, including randomized controlled trials (RCTs), after-only (post-test only) designs, the Solomon four-group design, crossover designs, and factorial designs. -

An Introduction to Randomization*
An Introduction to Randomization* TAF – CEGA Impact Evaluation Workshop Day 1 * http://ocw.mit.edu (J-PAL Impact Evaluation Workshop materials) Outline Background What is randomized evaluation? Advantages and limitations of experiments Conclusions An example: The “Vote 2002” campaign Arceneaux, Gerber and Green (2006) Intervention: get-out-the-vote phone calls to increase voter turnout in Iowa and Michigan, 2002 midterm elections Treatment group = 60,000 individuals (35,000 actually reached by phone) Control group = >2,000,000 individuals Main outcome: turnout (did the individual vote?) Effect sizes using experimental v. non-experimental methods How to measure impact? What would have happened in the absence of the intervention program? { Since the counterfactual is not observable, key goal of all impact evaluation methods is to construct of “mimic” the counterfactual Constructing the counterfactual Counterfactual is often constructed by selecting a group not affected by the program Randomized: { Use random assignment of the program to create a control group which mimics the counterfactual. Non-randomized: { Argue that a certain excluded group mimics the counterfactual. Validity A tool to assess credibility of a study Internal validity { Relates to ability to draw causal inference, i.e. can we attribute our impact estimates to the program and not to something else External validity { Relates to ability to generalize to other settings of interest, i.e. can we generalize our impact estimates from this program to other populations, -

Chapter 11. Experimental Design: One-Way Independent Samples Design
11 - 1 Chapter 11. Experimental Design: One-Way Independent Samples Design Advantages and Limitations Comparing Two Groups Comparing t Test to ANOVA Independent Samples t Test Independent Samples ANOVA Comparing More Than Two Groups Thinking Critically About Everyday Information Quasi-experiments Case Analysis General Summary Detailed Summary Key Terms Review Questions/Exercises 11 - 2 Advantages and Limitations Now that we have introduced the basic concepts of behavioral research, the next five chapters discuss specific research designs. Chapters 11–14 focus on true experimental designs that involve experimenter manipulation of the independent variable and experimenter control over the assignment of participants to treatment conditions. Chapter 15 focuses on alternative research designs in which the experimenter does not manipulate the independent variable and/or does not have control over the assignment of participants to treatment conditions. Let’s return to a topic and experimental design that we discussed earlier. Suppose we are interested in the possible effect of TV violence on aggressive behavior in children. One fairly simple approach is to randomly sample several day-care centers for participants. On a particular day, half of the children in each day-care center are randomly assigned to watch Mister Rogers for 30 minutes, and the other half watch Beast Wars for 30 minutes. The children are given the same instructions by one of the day-care personnel and watch the TV programs in identical environments. Following the TV program, the children play for 30 minutes, and the number of aggressive behaviors is observed and recorded by three experimenters who are “blind” to which TV program each child saw. -
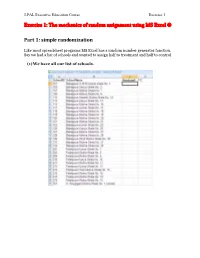
Exercise 1: the Mechanics of Random Assignment Using MS Excel ®
J-PAL Executive Education Course Exercise 1 Exercise 1: The mechanics of random assignment using MS Excel ® Part 1: simple randomization Like most spreadsheet programs MS Excel has a random number generator function. Say we had a list of schools and wanted to assign half to treatment and half to control (1) We have all our list of schools. Incorporating Random Assignment into the Research Design (2) Assign a random number to each school: The function RAND () is Excel’s random number generator. To use it, in Column C, type in the following = RAND() in each cell adjacent to every name. Or you can type this function in the top row (row 2) and simply copy and paste to the entire column, or click and drag. Typing = RAND() puts a 15-digit random number between 0 and 1 in the cell. 2 The Abdul Latif Jameel Poverty Action Lab @MIT, Cambridge, MA 02130, USA | @IFMR, Chennai 600 008, India | @PSE, Paris 75014, France Remedial Education: Evaluating the Balsakhi Program (3) Copy the cells in Colum C, then paste the values over the same cells The function, =RAND() will re-randomize each time you make any changes to any other part of the spreadsheet. Excel does this because it recalculates all values with any change to any cell. (You can also induce recalculation, and hence re-randomization, by pressing the key F9.) This can be confusing, however. Once we’ve generated our column of random numbers, we do not need to re-randomize. We already have a clean column of random values.