Darwin-Lamarck-Evolutionary-Algorithms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Segmentation in Vertebrates: Clock and Gradient Finally Joined
Downloaded from genesdev.cshlp.org on September 24, 2021 - Published by Cold Spring Harbor Laboratory Press REVIEW Segmentation in vertebrates: clock and gradient finally joined Alexander Aulehla1 and Bernhard G. Herrmann2 Max-Planck-Institute for Molecular Genetics, Department of Developmental Genetics, 14195 Berlin, Germany The vertebral column is derived from somites formed by terior (A–P) axis. Somite formation takes place periodi- segmentation of presomitic mesoderm, a fundamental cally in a fixed anterior-to-posterior sequence. process of vertebrate embryogenesis. Models on the In the chick embryo, a new somite is formed approxi- mechanism controlling this process date back some mately every 90 min, whereas in the mouse embryo, the three to four decades. Access to understanding the mo- periodicity varies, dependent on the axial position (Tam lecular control of somitogenesis has been gained only 1981). Classical embryology experiments revealed that recently by the discovery of molecular oscillators (seg- periodicity and directionality of somite formation are mentation clock) and gradients of signaling molecules, controlled by an intrinsic program set off in the cells as as predicted by early models. The Notch signaling path- they are recruited into the psm. For instance, when the way is linked to the oscillator and plays a decisive role in psm is inverted rostro–caudally, somite formation in the inter- and intrasomitic boundary formation. An Fgf8 sig- inverted region proceeds from caudal to rostral, main- naling gradient is involved in somite size control. And taining the original direction (Christ et al. 1974). More- the (canonical) Wnt signaling pathway, driven by Wnt3a, over, neither the transversal bisection nor the isolation appears to integrate clock and gradient in a global of the psm from all surrounding tissues stops the seg- mechanism controlling the segmentation process. -

Perspectives
Copyright 0 1994 by the Genetics Society of America Perspectives Anecdotal, Historical and Critical Commentaries on Genetics Edited by James F. Crow and William F. Dove A Century of Homeosis, A Decade of Homeoboxes William McGinnis Department of Molecular Biophysics and Biochemistry, Yale University, New Haven, Connecticut 06520-8114 NE hundred years ago, while the science of genet- ing mammals, and were proposed to encode DNA- 0 ics still existed only in the yellowing reprints of a binding homeodomainsbecause of a faint resemblance recently deceased Moravian abbot, WILLIAMBATESON to mating-type transcriptional regulatory proteins of (1894) coined the term homeosis to define a class of budding yeast and an even fainter resemblance to bac- biological variations in whichone elementof a segmen- terial helix-turn-helix transcriptional regulators. tally repeated array of organismal structures is trans- The initial stream of papers was a prelude to a flood formed toward the identity of another. After the redis- concerning homeobox genes and homeodomain pro- coveryof MENDEL’Sgenetic principles, BATESONand teins, a flood that has channeled into a steady river of others (reviewed in BATESON1909) realized that some homeo-publications, fed by many tributaries. A major examples of homeosis in floral organs and animal skel- reason for the continuing flow of studies is that many etons could be attributed to variation in genes. Soon groups, working on disparate lines of research, have thereafter, as the discipline of Drosophila genetics was found themselves swept up in the currents when they born and was evolving into a formidable intellectual found that their favorite protein contained one of the force enriching many biologicalsubjects, it gradually be- many subtypes of homeodomain. -

PAPC Couples the Segmentation Clock to Somite Morphogenesis by Regulating N-Cadherin-Dependent Adhesion
© 2017. Published by The Company of Biologists Ltd | Development (2017) 144, 664-676 doi:10.1242/dev.143974 RESEARCH ARTICLE PAPC couples the segmentation clock to somite morphogenesis by regulating N-cadherin-dependent adhesion Jérome Chal1,2,3,4,5,*, Charlenè Guillot3,4,* and Olivier Pourquié1,2,3,4,5,6,7,‡ ABSTRACT specific level of the PSM called the determination front. The Vertebrate segmentation is characterized by the periodic formation of determination front is defined as a signaling threshold epithelial somites from the mesenchymal presomitic mesoderm implemented by posterior gradients of Wnt and FGF (Aulehla (PSM). How the rhythmic signaling pulse delivered by the et al., 2003; Diez del Corral and Storey, 2004; Dubrulle et al., segmentation clock is translated into the periodic morphogenesis of 2001; Hubaud and Pourquie, 2014; Sawada et al., 2001). Cells of somites remains poorly understood. Here, we focused on the role of the posterior PSM exhibit mesenchymal characteristics and paraxial protocadherin (PAPC/Pcdh8) in this process. We showed express Snail-related transcription factors (Dale et al., 2006; that in chicken and mouse embryos, PAPC expression is tightly Nieto, 2002). In the anterior PSM, cells downregulate snail/slug regulated by the clock and wavefront system in the posterior PSM. We expression and upregulate epithelialization-promoting factors such observed that PAPC exhibits a striking complementary pattern to N- as paraxis (Barnes et al., 1997; Sosic et al., 1997). This molecular cadherin (CDH2), marking the interface of the future somite boundary transition correlates with the anterior PSM cells progressively in the anterior PSM. Gain and loss of function of PAPC in chicken acquiring epithelial characteristics (Duband et al., 1987; Martins embryos disrupted somite segmentation by altering the CDH2- et al., 2009). -

Transformations of Lamarckism Vienna Series in Theoretical Biology Gerd B
Transformations of Lamarckism Vienna Series in Theoretical Biology Gerd B. M ü ller, G ü nter P. Wagner, and Werner Callebaut, editors The Evolution of Cognition , edited by Cecilia Heyes and Ludwig Huber, 2000 Origination of Organismal Form: Beyond the Gene in Development and Evolutionary Biology , edited by Gerd B. M ü ller and Stuart A. Newman, 2003 Environment, Development, and Evolution: Toward a Synthesis , edited by Brian K. Hall, Roy D. Pearson, and Gerd B. M ü ller, 2004 Evolution of Communication Systems: A Comparative Approach , edited by D. Kimbrough Oller and Ulrike Griebel, 2004 Modularity: Understanding the Development and Evolution of Natural Complex Systems , edited by Werner Callebaut and Diego Rasskin-Gutman, 2005 Compositional Evolution: The Impact of Sex, Symbiosis, and Modularity on the Gradualist Framework of Evolution , by Richard A. Watson, 2006 Biological Emergences: Evolution by Natural Experiment , by Robert G. B. Reid, 2007 Modeling Biology: Structure, Behaviors, Evolution , edited by Manfred D. Laubichler and Gerd B. M ü ller, 2007 Evolution of Communicative Flexibility: Complexity, Creativity, and Adaptability in Human and Animal Communication , edited by Kimbrough D. Oller and Ulrike Griebel, 2008 Functions in Biological and Artifi cial Worlds: Comparative Philosophical Perspectives , edited by Ulrich Krohs and Peter Kroes, 2009 Cognitive Biology: Evolutionary and Developmental Perspectives on Mind, Brain, and Behavior , edited by Luca Tommasi, Mary A. Peterson, and Lynn Nadel, 2009 Innovation in Cultural Systems: Contributions from Evolutionary Anthropology , edited by Michael J. O ’ Brien and Stephen J. Shennan, 2010 The Major Transitions in Evolution Revisited , edited by Brett Calcott and Kim Sterelny, 2011 Transformations of Lamarckism: From Subtle Fluids to Molecular Biology , edited by Snait B. -

Rapid Changes in Morphogen Concentration Control Self-Organized
RESEARCH COMMUNICATION Rapid changes in morphogen concentration control self-organized patterning in human embryonic stem cells Idse Heemskerk1†, Kari Burt1, Matthew Miller1, Sapna Chhabra2, M Cecilia Guerra1, Lizhong Liu1, Aryeh Warmflash1,3* 1Department of Biosciences, Rice University, Houston, United States; 2Systems, Synthetic and Physical Biology Program, Rice University, Houston, United States; 3Department of Bioengineering, Rice University, Houston, United States Abstract During embryonic development, diffusible signaling molecules called morphogens are thought to determine cell fates in a concentration-dependent way. Yet, in mammalian embryos, concentrations change rapidly compared to the time for making cell fate decisions. Here, we use human embryonic stem cells (hESCs) to address how changing morphogen levels influence differentiation, focusing on how BMP4 and Nodal signaling govern the cell-fate decisions associated with gastrulation. We show that BMP4 response is concentration dependent, but that expression of many Nodal targets depends on rate of concentration change. Moreover, in a self- organized stem cell model for human gastrulation, expression of these genes follows rapid changes in endogenous Nodal signaling. Our study shows a striking contrast between the specific ways ligand dynamics are interpreted by two closely related signaling pathways, highlighting both the *For correspondence: subtlety and importance of morphogen dynamics for understanding mammalian embryogenesis [email protected] and designing optimized protocols for directed stem cell differentiation. Editorial note: This article has been through an editorial process in which the authors decide how † Present address: Department to respond to the issues raised during peer review. The Reviewing Editor’s assessment is that all of Cell and Developmental the issues have been addressed (see decision letter). -
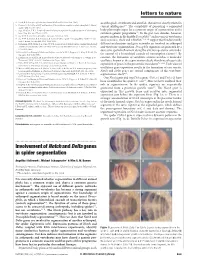
Involvement Ofnotchanddeltagenes in Spider Segmentation
letters to nature 4. Urick, R. J. Principles of Underwater Sound (McGraw Hill, New York, 1983). as arthropods, vertebrates and annelids, that are not closely related in 5. Henson, O. W. Jr The activity and function of the middle ear muscles in echolocating bats. J. Physiol. current phylogenies10. The complexity of generating a segmented (Lond.) 180, 871–887 (1965). 6. Suga, N. & Jen, P. H. S. Peripheral control of acoustic signals in the auditory system of echolocating body plan might argue for a common origin of segmentation and a bats. J. Exp. Biol. 62, 277–331 (1975). common genetic programme1,2. In the past two decades, however, 7. Au, W. W. L. The Sonar of Dolphins (Springer, New York, 1993). genetic analyses in the fruitfly Drosophila3,4 and in various vertebrates 8. Au, W. W. L., Ford, J. K. B. & Allman, K. A. Echolocation signals of foraging killer whales (Orcinus 7–9,11–14 orca). J. Acoust. Soc. Am. 111, 2343–2344 (2002). such as mouse, chick and zebrafish suggest that fundamentally 9. Rasmussen, M. H., Miller, L. A. & Au, W. W. L. Source levels of clicks from free-ranging white beaked different mechanisms and gene networks are involved in arthropod dolphins (Lagenorhynchus albirostris Gray 1846) recorded in Icelandic waters. J. Acoust. Soc. Am. 111, and vertebrate segmentation. Drosophila segments are generated by a 1122–1125 (2002). successive spatial refinement along the anterior–posterior axis under 10. Ketten, D. R. in Hearing by Whales and Dolphins (eds Au, W. W. L., Popper, A. N. & Fay, R. R.) 43–108 3,4 (Springer, New York, 2000). -

Stages of Embryonic Development of the Zebrafish
DEVELOPMENTAL DYNAMICS 2032553’10 (1995) Stages of Embryonic Development of the Zebrafish CHARLES B. KIMMEL, WILLIAM W. BALLARD, SETH R. KIMMEL, BONNIE ULLMANN, AND THOMAS F. SCHILLING Institute of Neuroscience, University of Oregon, Eugene, Oregon 97403-1254 (C.B.K., S.R.K., B.U., T.F.S.); Department of Biology, Dartmouth College, Hanover, NH 03755 (W.W.B.) ABSTRACT We describe a series of stages for Segmentation Period (10-24 h) 274 development of the embryo of the zebrafish, Danio (Brachydanio) rerio. We define seven broad peri- Pharyngula Period (24-48 h) 285 ods of embryogenesis-the zygote, cleavage, blas- Hatching Period (48-72 h) 298 tula, gastrula, segmentation, pharyngula, and hatching periods. These divisions highlight the Early Larval Period 303 changing spectrum of major developmental pro- Acknowledgments 303 cesses that occur during the first 3 days after fer- tilization, and we review some of what is known Glossary 303 about morphogenesis and other significant events that occur during each of the periods. Stages sub- References 309 divide the periods. Stages are named, not num- INTRODUCTION bered as in most other series, providing for flexi- A staging series is a tool that provides accuracy in bility and continued evolution of the staging series developmental studies. This is because different em- as we learn more about development in this spe- bryos, even together within a single clutch, develop at cies. The stages, and their names, are based on slightly different rates. We have seen asynchrony ap- morphological features, generally readily identi- pearing in the development of zebrafish, Danio fied by examination of the live embryo with the (Brachydanio) rerio, embryos fertilized simultaneously dissecting stereomicroscope. -

Direct Integration of Hox and Segmentation Gene Inputs During Drosophila Development
articles Direct integration of Hox and segmentation gene inputs during Drosophila development Brian Gebelein1, Daniel J. McKay2 & Richard S. Mann1 1Department of Biochemistry and Molecular Biophysics and Center for Neurobiology and Behavior, 2Integrated Program in Cellular, Molecular, and Biophysical Studies, Columbia University, 701 West 168th Street, HHSC 1104, New York, New York 10032, USA ........................................................................................................................................................................................................................... During Drosophila embryogenesis, segments, each with an anterior and posterior compartment, are generated by the segmentation genes while the Hox genes provide each segment with a unique identity. These two processes have been thought to occur independently. Here we show that abdominal Hox proteins work directly with two different segmentation proteins, Sloppy paired and Engrailed, to repress the Hox target gene Distalless in anterior and posterior compartments, respectively. These results suggest that segmentation proteins can function as Hox cofactors and reveal a previously unanticipated use of compartments for gene regulation by Hox proteins. Our results suggest that these two classes of proteins may collaborate to directly control gene expression at many downstream target genes. The segregation of groups of cells into compartments is funda- and DMX-lacZ in both compartments, thereby blocking leg mental to animal development1–4. -

Drosophila: the Genetics of Segmentation (WR Lecture 2)
Drosophila: the genetics of segmentation (WR lecture 2) In the previous lecture we covered the Drosophila life cycle from developing oocyte to the newly-cellularized blastoderm. At this stage (left), the embryo is shaped like a slightly bent rugby ball with about 6000 cells distributed around the surface. There are very few recognizable surface or internal features, but the future body plan is already mapped out through the expression of a set of genes known as the segmentation genes. This expression pattern - which defines a series of 15 stripes around the embryo - is a "molecular blueprint" that specifies the larval and adult segments. In this lecture we learn about the molecular events that subdivide the embryo into stripes (known as parasegments in the embryo). The key players in this process were identified during a genetic screen that was carried out by Christiane Nusslein-Volhart, Eric Wieschaus and their collaborators. Their groundbreaking effort was rewarded in 1995 by the award of the Nobel prize in Physiology and Medicine, which they shared with Ed Lewis for his work on homeotic mutants (next lecture). All animals, whether flies or humans, are constructed according to a fundamental repeated pattern so this work in Drosophila lays the foundation for understanding development of all animals. 1. Three sets of maternal effect genes define the anterior-posterior axis. These are the anterior group, the posterior group and the terminal group genes (the latter determine structures at the extreme front and back ends of the fly - the telson at the back and the acron at the front). The main player in the anterior group is bicoid, mRNA for which is localized at the anterior end of the oocyte and is translated into protein (a homeodomain transcription factor) that diffuses posteriorly to set up an anterior-posterior (high-low) concentration gradient. -

Metazoan Segmentation
Molecular Systems Biology 3; Article number 154; doi:10.1038/msb4100192 Citation: Molecular Systems Biology 3:154 & 2007 EMBO and Nature Publishing Group All rights reserved 1744-4292/07 www.molecularsystemsbiology.com Deriving structure from evolution: metazoan segmentation Paul Franc¸ois1,3,*, Vincent Hakim2,3 and Eric D Siggia1,3 1 Center for Studies in Physics and Biology, The Rockefeller University, New York, NY, USA and 2 Laboratoire de Physique Statistique, CNRS UMR 8550, Ecole Normale Supe´rieure, Paris Cedex, France 3 Order of authors is alphabetical. * Corresponding author. Center for Studies in Physics and Biology, The Rockefeller University, 1230 York Avenue, New York, NY 10065, USA. Tel.: 1 212 327 8835; Fax: 1 212 327 8544; E-mail: [email protected] þ þ Received 25.4.07; accepted 17.10.07 Segmentation is a common feature of disparate clades of metazoans, and its evolution is a central problem of evolutionary developmental biology. We evolved in silico regulatory networks by a mutation/selection process that just rewards the number of segment boundaries. For segmentation controlled by a static gradient, as in long-germ band insects, a cascade of adjacent repressors reminiscent of gap genes evolves. For sequential segmentation controlled by a moving gradient, similar to vertebrate somitogenesis, we invariably observe a very constrained evolutionary path or funnel. The evolved state is a cell autonomous ‘clock and wavefront’ model, with the new attribute of a separate bistable system driven by an autonomous clock. Early stages in the evolution of both modes of segmentation are functionally similar, and simulations suggest a possible path for their interconversion. -
![[ 130 ] Studies on the Morphogenesis of The](https://docslib.b-cdn.net/cover/2242/130-studies-on-the-morphogenesis-of-the-1482242.webp)
[ 130 ] Studies on the Morphogenesis of The
[ 130 ] STUDIES ON THE MORPHOGENESIS OF THE MOUSE STERNUM III. EXPERIMENTS ON THE CLOSURE AND SEGMENTATION OF THE STERNAL BANDS BY JUI MING CHEN Strangeways Research Laboratory, Cambridge INTRODUCTION The study of the normal embryonic development of the mouse sternum and the experiments on its differentiation in vitro reported in Parts I and II of the present series of studies (Chen, 1952a, b) indicated two points of special interest in relation to the developmental mechanics of this bone, namely the closure of the two sternal bands and the segmentation of the sternum. The bilateral, dual origin of the sternum is perhaps an unusual feature in morpho- genesis, for very few organs in the vertebrate have a similar ontogenetic course, but in all classes the true sternum originates in the same way (Gladstone & Wakeley, 1932). So far, the mechanism by which the two widely separated mesodermal bands are brought together has only been investigated experimentally in birds (Fell, 1939). Fell has shown that, of the factors possibly involved, i.e. (i) the expansion of the sternal bands themselves, (ii) the elongation of the ribs, (iii) the shrinkage of the mid-ventral body-wall and (iv) the movement of the dorso-lateral tissue of the thoracic wall, the last one is primarily responsible, while the shrinkage of the ventral body-wall may have a secondary effect. The study of the normal development of the mouse sternum has shown that all these factors except the first may operate in the mouse also. By analogy, it seemed possible that the same mechanism was involved in both species, but it was advisable to investigate the matter by experimental means. -

Reconstructing Stages in the Evolution of Animal Segmentation Renske M
Vroomans et al. EvoDevo (2016) 7:14 DOI 10.1186/s13227-016-0052-8 EvoDevo RESEARCH Open Access In silico evo‑devo: reconstructing stages in the evolution of animal segmentation Renske M. A. Vroomans* , Paulien Hogeweg and Kirsten H. W. J. ten Tusscher Abstract Background: The evolution of animal segmentation is a major research focus within the field of evolutionary–devel- opmental biology. Most studied segmented animals generate their segments in a repetitive, anterior-to-posterior fashion coordinated with the extension of the body axis from a posterior growth zone. In the current study we ask which selection pressures and ordering of evolutionary events may have contributed to the evolution of this specific segmentation mode. Results: To answer this question we extend a previous in silico simulation model of the evolution of segmenta- tion by allowing the tissue growth pattern to freely evolve. We then determine the likelihood of evolving oscillatory sequential segmentation combined with posterior growth under various conditions, such as the presence or absence of a posterior morphogen gradient or selection for determinate growth. We find that posterior growth with sequential segmentation is the predominant outcome of our simulations only if a posterior morphogen gradient is assumed to have already evolved and selection for determinate growth occurs secondarily. Otherwise, an alternative segmenta- tion mechanism dominates, in which divisions occur in large bursts through the entire tissue and all segments are created simultaneously. Conclusions: Our study suggests that the ancestry of a posterior signalling centre has played an important role in the evolution of sequential segmentation. In addition, it suggests that determinate growth evolved secondarily, after the evolution of posterior growth.