Lossy Coding 2 Perceptual Image Coding JPEG JPEG Discrete
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(A/V Codecs) REDCODE RAW (.R3D) ARRIRAW
What is a Codec? Codec is a portmanteau of either "Compressor-Decompressor" or "Coder-Decoder," which describes a device or program capable of performing transformations on a data stream or signal. Codecs encode a stream or signal for transmission, storage or encryption and decode it for viewing or editing. Codecs are often used in videoconferencing and streaming media solutions. A video codec converts analog video signals from a video camera into digital signals for transmission. It then converts the digital signals back to analog for display. An audio codec converts analog audio signals from a microphone into digital signals for transmission. It then converts the digital signals back to analog for playing. The raw encoded form of audio and video data is often called essence, to distinguish it from the metadata information that together make up the information content of the stream and any "wrapper" data that is then added to aid access to or improve the robustness of the stream. Most codecs are lossy, in order to get a reasonably small file size. There are lossless codecs as well, but for most purposes the almost imperceptible increase in quality is not worth the considerable increase in data size. The main exception is if the data will undergo more processing in the future, in which case the repeated lossy encoding would damage the eventual quality too much. Many multimedia data streams need to contain both audio and video data, and often some form of metadata that permits synchronization of the audio and video. Each of these three streams may be handled by different programs, processes, or hardware; but for the multimedia data stream to be useful in stored or transmitted form, they must be encapsulated together in a container format. -

JPEG and JPEG 2000
JPEG and JPEG 2000 Past, present, and future Richard Clark Elysium Ltd, Crowborough, UK [email protected] Planned presentation Brief introduction JPEG – 25 years of standards… Shortfalls and issues Why JPEG 2000? JPEG 2000 – imaging architecture JPEG 2000 – what it is (should be!) Current activities New and continuing work… +44 1892 667411 - [email protected] Introductions Richard Clark – Working in technical standardisation since early 70’s – Fax, email, character coding (8859-1 is basis of HTML), image coding, multimedia – Elysium, set up in ’91 as SME innovator on the Web – Currently looks after JPEG web site, historical archive, some PR, some standards as editor (extensions to JPEG, JPEG-LS, MIME type RFC and software reference for JPEG 2000), HD Photo in JPEG, and the UK MPEG and JPEG committees – Plus some work that is actually funded……. +44 1892 667411 - [email protected] Elysium in Europe ACTS project – SPEAR – advanced JPEG tools ESPRIT project – Eurostill – consensus building on JPEG 2000 IST – Migrator 2000 – tool migration and feature exploitation of JPEG 2000 – 2KAN – JPEG 2000 advanced networking Plus some other involvement through CEN in cultural heritage and medical imaging, Interreg and others +44 1892 667411 - [email protected] 25 years of standards JPEG – Joint Photographic Experts Group, joint venture between ISO and CCITT (now ITU-T) Evolved from photo-videotex, character coding First meeting March 83 – JPEG proper started in July 86. 42nd meeting in Lausanne, next week… Attendance through national -

University of Florida Acceptable ETD Formats
University of Florida acceptable ETD formats The Acceptable ETD formats below are defined based on those media for which a preservation strategy exists. The aim is to make all ETD’s available into the future as the technology changes and software becomes obsolete. Media formats that are not listed in this table are ones that cannot presently be preserved at an acceptable level. Many of these can easily be converted to one of the acceptable formats. If you create a document using Word or LaTex it should be exported as a PDF. Please consult with the CIRCA ETD unit ([email protected]) for assistance or if you have any questions. The Acceptable ETD Formats are reviewed and updated regularly by the Graduate School, the Library, the ETD training staff in Academic Technology, and the Florida Center for Library Automation. All files should be scanned with up-to-date virus software before submission. Files with viruses will not be accepted. Media Acceptable formats (bold indicates preferred formats) Text - PDF/A-1 (ISO 19005-1) (*.pdf) - Plain text (encoding: USASCII, UTF-8, UTF-16 with BOM) - XML (includes XSD/XSL/XHTML, etc.; with included or accessible schema and character encoding explicitly specified) - Cascading Style Sheets (*.css) - DTD (*.dtd) - Plain text (ISO 8859-1 encoding) - PDF (*.pdf) (embedded fonts) - Rich Text Format 1.x (*.rtf) - HTML (include a DOCTYPE declaration) - SGML (*.sgml) - Open Office (*.sxw/*.odt) - OOXML (ISO/IEC DIS 29500) (*.docx) - Computer program source code (*.c, *.c++, *.java, *.js, *.jsp, *.php, *.pl, etc.) -

Research Paper a Study of Digital Video Compression Techniques
Volume : 5 | Issue : 4 | April 2016 ISSN - 2250-1991 | IF : 5.215 | IC Value : 77.65 Research Paper Engineering A Study of Digital Video Compression Techniques Dr. Saroj Choudhary Department of Applied Science JECRC, Jodhpur, Rajasthan, India Purneshwari Department of ECE JIET, Jodhpur, Rajasthan, India Varshney Earlier, digital video compression technologies have become an integral part of the creation, communication and consumption of visual information. In this, techniques for video compression techniques are reviewed. The paper explains the basic concepts of video codec design and various features which have been integrated into international standards and including the recent standard, H.264/AVC. The ITU-T H.264 video coding standard has been developed to achieve significant improvements over MPEG-2 standard in terms of compression. Although the basic coding framework of the ABSTRACT standard is similar to that of the existing standards, H.264 introduces many new features. KEYWORDS H.264, MPEG-2, PSNR. INTRODUCTION Since minimal information is sent between every four or five The basic communication problem may be posed as conveying frames, a significant reduction in bits required to describe the source data with the highest fidelity possible within an availa- image results. Consequently, compression ratios above 100:1 ble bit rate, or it may be posed as conveying the source data are common. The scheme is asymmetric; the MPEG encoder using the lowest bit rate possible while maintaining specified is very complex and places a very heavy computational load reproduction fidelity [7]. In either case, a fundamental tradeoff for motion estimation. Decoding is much simpler and can be is made between bit rate and fidelity. -

ITC Confplanner DVD Pages Itcconfplanner
Comparative Analysis of H.264 and Motion- JPEG2000 Compression for Video Telemetry Item Type text; Proceedings Authors Hallamasek, Kurt; Hallamasek, Karen; Schwagler, Brad; Oxley, Les Publisher International Foundation for Telemetering Journal International Telemetering Conference Proceedings Rights Copyright © held by the author; distribution rights International Foundation for Telemetering Download date 25/09/2021 09:57:28 Link to Item http://hdl.handle.net/10150/581732 COMPARATIVE ANALYSIS OF H.264 AND MOTION-JPEG2000 COMPRESSION FOR VIDEO TELEMETRY Kurt Hallamasek, Karen Hallamasek, Brad Schwagler, Les Oxley [email protected] Ampex Data Systems Corporation Redwood City, CA USA ABSTRACT The H.264/AVC standard, popular in commercial video recording and distribution, has also been widely adopted for high-definition video compression in Intelligence, Surveillance and Reconnaissance and for Flight Test applications. H.264/AVC is the most modern and bandwidth-efficient compression algorithm specified for video recording in the Digital Recording IRIG Standard 106-11, Chapter 10. This bandwidth efficiency is largely derived from the inter-frame compression component of the standard. Motion JPEG-2000 compression is often considered for cockpit display recording, due to the concern that details in the symbols and graphics suffer excessively from artifacts of inter-frame compression and that critical information might be lost. In this paper, we report on a quantitative comparison of H.264/AVC and Motion JPEG-2000 encoding for HD video telemetry. Actual encoder implementations in video recorder products are used for the comparison. INTRODUCTION The phenomenal advances in video compression over the last two decades have made it possible to compress the bit rate of a video stream of imagery acquired at 24-bits per pixel (8-bits for each of the red, green and blue components) with a rate of a fraction of a bit per pixel. -

Input Formats & Codecs
Input Formats & Codecs Pivotshare offers upload support to over 99.9% of codecs and container formats. Please note that video container formats are independent codec support. Input Video Container Formats (Independent of codec) 3GP/3GP2 ASF (Windows Media) AVI DNxHD (SMPTE VC-3) DV video Flash Video Matroska MOV (Quicktime) MP4 MPEG-2 TS, MPEG-2 PS, MPEG-1 Ogg PCM VOB (Video Object) WebM Many more... Unsupported Video Codecs Apple Intermediate ProRes 4444 (ProRes 422 Supported) HDV 720p60 Go2Meeting3 (G2M3) Go2Meeting4 (G2M4) ER AAC LD (Error Resiliant, Low-Delay variant of AAC) REDCODE Supported Video Codecs 3ivx 4X Movie Alaris VideoGramPiX Alparysoft lossless codec American Laser Games MM Video AMV Video Apple QuickDraw ASUS V1 ASUS V2 ATI VCR-2 ATI VCR1 Auravision AURA Auravision Aura 2 Autodesk Animator Flic video Autodesk RLE Avid Meridien Uncompressed AVImszh AVIzlib AVS (Audio Video Standard) video Beam Software VB Bethesda VID video Bink video Blackmagic 10-bit Broadway MPEG Capture Codec Brooktree 411 codec Brute Force & Ignorance CamStudio Camtasia Screen Codec Canopus HQ Codec Canopus Lossless Codec CD Graphics video Chinese AVS video (AVS1-P2, JiZhun profile) Cinepak Cirrus Logic AccuPak Creative Labs Video Blaster Webcam Creative YUV (CYUV) Delphine Software International CIN video Deluxe Paint Animation DivX ;-) (MPEG-4) DNxHD (VC3) DV (Digital Video) Feeble Files/ScummVM DXA FFmpeg video codec #1 Flash Screen Video Flash Video (FLV) / Sorenson Spark / Sorenson H.263 Forward Uncompressed Video Codec fox motion video FRAPS: -
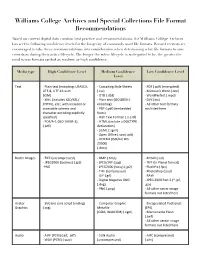
Williams College Archives and Special Collections File Format Recommendations
Williams College Archives and Special Collections File Format Recommendations Based on current digital data curation best practice and recommendations, the Williams College Archives has set the following confidence levels for the longevity of commonly used file formats. Record creators are encouraged to take these recommendations into consideration when determining what file formats to save records as during their active lifecycle. The longer the active lifecycle is anticipated to be, the greater the need to use formats ranked as medium or high confidence. Media type High Confidence Level Medium Confidence Low Confidence Level Level Text - Plain text (encoding: USASCII, - Cascading Style Sheets - PDF (.pdf) (encrypted) UTF-8, UTF-16 with (.css) - Microsoft Word (.doc) BOM) - DTD (.dtd) - WordPerfect (.wpd) - XML (includes XSD/XSL/ - Plain text (ISO 8859-1 - DVI (.dvi) XHTML, etc.; with included or encoding) - All other text forMats accessible schema and - PDF (.pdf) (eMbedded not listed here character encoding explicitly fonts) specified) - Rich Text ForMat 1.x (.rtf) - PDF/A-1 (ISO 19005-1) - HTML (include a DOCTYPE (.pdf) declaration) - SGML (.sgMl) - Open Office (.sxw/.odt) - OOXML (ISO/IEC DIS 29500) (.docx) Raster Images - TIFF (uncoMpressed) - BMP (.bMp) - MrSID (.sid) - JPEG2000 (lossless) (.jp2) - JPEG/JFIF (.jpg) - TIFF (in Planar forMat) -PNG - JPEG2000 (lossy) (.jp2) - FlashPix (.fpx) - TIFF (coMpressed) - PhotoShop (.psd) - GIF (.gif) - RAW - Digital Negative DNG - JPEG 2000 Part 2 (*.jpf, (.dng) .jpx) - PNG (.png) - All other -

Mvix Ultio Pro Media Player Format Support.Pdf
Mvix Ultio Pro Format Support: Video Formats and Codecs File Type File Extension Video Codec Audio Code LPCM, uLaw, aLaw Divx 3 / 4/ / 5/ / 6 MPEG-Audio Motion JPEG HE-AAC, LC-AAC .mp4, .mov, .xvid, .m4v MP4, MOV MPEG-4 SP / ASP (Xvid) Dolby Digital Plus MPEG-4 AVC (H.264) Vorbis MS-ADPCM LPCM, uLaw, aLaw MPEG-1 MPEG-Audio Divx 3 / 4/ / 5/ / 6 HE-AAC, LC-AAC Motion JPEG Dolby Digital Plus .avi, .divx AVI MPEG-4 SP/ASP (Xvid) DTS MPEG-4 AVC (H.264) Vorbis VC-1 MS-ADPCM WMA, WMA Pro MPEG-1 LPCM Minus VR MPEG-2 MPEG-1 Layer 2 LPCM MPEG-1 .iso MPEG-1 Layer 2 DVD Video MPEG-2 DTS Dvix 3 / 5 LPCM MPEG-4 SP/ASP (Xvid) WMA .asf, .wmv, .xvid ASF, WMV VC-1 WMA Pro WMV ADPCM LPCM H.263 .flv MPEG-AUDIO FLV MPEG-4 AVC (H.264) HE-AAC, LC-AAC LPCM MPEG-AUDIO DIVX 3/4/5/6 Dolby Digital Plus MPEG-1 .mkv, .xvid HE-AAC, LC-AAC MKV MPEG-2 DTS, Vorbis MPEG-4 SP/ASP(XviD) MS-ADPCM WMA, WMA Pro COOK RM, RMVB .rm/.rmvb RV8,RV9 HE-AAC, LC-AAC RA-Lossless LPCM MPEG-1 MPEG-AUDIO MPEG-2 .ts/.m2ts/.mts/.tp/.trp Dolby Digital Plus TS MPEG-4 AVC(H.264) HE-AAC, LC-AAC VC-1 DTS, TrueHD LPCM MPEG-1 MPEG-AUDIO .dat, .mpg, .mpeg DAT, MPG, MPEG MPEG-2 HE-AAC, LC-AAC DTS LPCM MPEG-1 .vob MPEG-1 Layer2 VOB MPEG-2 DTS Mvix Ultio Pro Format Support: Audio Formats and Codecs File Type File Extension Version Support MPEG-1 Layer 3 .mp3 WMA .wma, .asf WMA 7~9.1 WMA pro .wma, .asf WMA pro 9.1 N/A MPEG 1/2 MPEG-1/2 Layer 1/2 (included in video only) WAV .wav MKA .mka N/A LPCM (included in video only) N/A Microsoft ADPCM ADPCM (included in video only) G.726 MPEG-2/4 LC/HE profile .aac, .mp4 AAC AAC+ ver. -

JPEG Compression
JPEG Compression Reference: Chapter 6 of Steinmetz and Nahrstedt Motivations: 1. Uncompressed video and audio data are huge. In HDTV, the bit rate easily exceeds 1 Gbps. --> big problems for storage and network communications. 2. The compression ratio of lossless methods (e.g., Huffman, Arithmetic, LZW) is not high enough for image and video compression, especially when distribution of pixel values is relatively flat. 1. What is JPEG? "Joint Photographic Expert Group". Voted as international standard in 1992. Works with color and grayscale images, e.g., satellite, medical, ... 2. JPEG overview Encoding Decoding -- Reverse the order 3. Major Steps DCT (Discrete Cosine Transformation) Quantization Zigzag Scan DPCM on DC component RLE on AC Components Entropy Coding 3a. Discrete Cosine Transform (DCT) Overview: Definition (8 point DCT): DC and AC components. DC Component F(0,0) The average value of all the pixels in the block AC Component Remaining 63 coefficients Represent the amplitudes of progressively higher horizontal and vertical spatial frequencies in the block. Further Exploration Try the Interactive FFT examples and the Interactive DCT examples. Note: You must download the MathCad browser in order to use these examples. 3b. Quantization Why? -- To throw out bits Example: 101101 = 45 (6 bits). Truncate to 4 bits: 1011 = 11. Truncate to 3 bits: 101 = 5. Quantization error is the main source of the Lossy Compression. Uniform quantization Divide by constant N and round result (N = 4 or 8 in examples above). Non powers-of-two gives fine control (e.g., N = 6 loses 2.5 bits) Quantization Tables In JPEG, each F[u,v] is divided by a constant q(u,v). -

Motion JPEG 2000 and Metadata Specific Provisions for Metadata Consideration Using COM Segments SMPTE Timecodes and COM II.3
Methods to Store Metadata within Motion JPEG 2000 Files Glenn Pearson Communications Engineering Branch US National Library of Medicine NIH/HHS Summary The specifications of Motion JPEG 2000 (MJ2) and related documents in the JPEG 2000 family are analyzed, to identify and assess the multiple mechanisms available for storing metadata within a MJ2 file and the types of metadata that can be so accommodated. Adequate mechanisms seem to exist for associating metadata with the production as a whole, individual tracks, and individual frames. In those cases, attention is turned to alternative forms such metadata might take, both those suggested within the JPEG 2000 family specifications and those defined externally. Conversely, existing mechanisms seem inadequate, or at the least underspecified, for embedding and synchronizing scene-based metadata. Various workarounds and possible extensions are discussed, as well as alternative wrapper formats and methods of metadata synchronization from without. Of the externally-defined metadata systems considered, those of MPEG4 (whose file format is a cousin of MJ2) and MXF (which is paired with JPEG 2000 for Digital Cinema) get the most attention herein, but many others, well known to the archival community, are touched upon. This document strives to identify various approaches and, ideally, their pluses and minuses, to provide a basis from which recommended practices or refinement of standards could be developed for video archiving. Contents Section 1. Overview Section II. Provision for “Easy Metadata” – Per Movie, Per Track, Per Frame II.1 Introduction via Still Images and their Metadata The Basic JP2 File Format More About UUID JP2’s Use of UUID and Interpretation as KLV JPX Extensions II.2. -
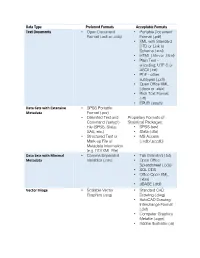
(.Odt Or .Ods) • Portable Document
Data Type Preferred Formats Acceptable Formats Text Documents • Open Document • Portable Document Format (.odt or .ods) Format (.pdf) • XML with Standard DTD or Link to Schema (.xml) • HTML (.htm or .html) • Plain Text - encoding: UTF-8 or ASCII (.txt) • PDF - other subtypes (.pdf) • Open Office XML (.docx or .xlsx) • Rich Text Format (.rtf) • EPUB (.epub) Data Sets with Extensive • SPSS Portable Metadata Format (.por) • Delimited Text and Propietary Formats of Command ('setup') Statistical Packages: File (SPSS, Stata, • SPSS (sav) SAS, etc.) • Stata (.dta) • Structured Text or • MS Access Mark-up File of (.mdb/.accdb) Metadata Information (e.g. DDI XML File) Data Sets with Minimal • Comma Separated • Tab Delimited (.txt) Metadata Variables (.csv) • Open Office Spreadsheet (.ods) • SQL DDS • Office Open XML (.xlsx) • dBASE (.dbf) Vector Image • Scalable Vector • Standard CAD Graphics (.svg) Drawing (.dwg) • AutoCAD Drawing Interchange Format (.dxf) • Computer Graphics Metafile (.cgm) • Adobe Illustrator (.ai) Raster Image • TIFF - Uncompressed • JPEG (.jpeg or .jpg) (.tif or .tiff) • JPEG2000 - Uncompressed or Lossless Compressed (.jp2 or.j2k) • PDF/A or PDF/X - Graphic Exchange Format (.pdf) • PNG (.png) • TIFF - Lossless Compressed (.tif) • GIF (.gif) • RAW Image Format (.raw) • Photoshop Files (.psd) • BMP (.bmp) Audio Files • Broadcast Wave • MP3 (.mp3) (.wav) • Advanced Audio • Audio Interchange Coding (.aac, .m4p, File Format (.aif, .aiff) .m4a) • Free Lossless Audio • MIDI (.mid, .midi) Coding (FLAC) (.flac) • Ogg Vorbis (.ogg) -

Specification Video Playback Motion-JPEG Resolution︰Up To
Specification Motion-JPEG Resolution:up to 720x480@30fps Audio:PCM File format:MOV/AVI MPEG-1 Resolution:up to 720x480@30fps Audio:MPEG1 File format:.MPG/.DAT MPEG-2 Resolution:up to 720x480@30fps Audio:MPEG1/AC3 File format:MPG/VOB/MOD Note: To avoid any Infringement of Copyright, this device is unable to play any DVD files with the encryption technology. Video playback MPEG-4 Resolution:up to 720x480@30fps Audio:AAC/MPEG File format:MP4/MOV/AVI Note: VP8860 can not support H.264 format video XviD Resolution:up to 720x480@30fps Audio:AAC/MPEG1 File format:AVI Note 1. The VP8860 may not read the videos created with codes other than above. If you have these other file types that you would like to view on your VP8860, you must use the video - editing software to re-encode them into the proper video codecs with supported sound stream. MP3 Sample rate:48 KHz Bit-rate:384 kbps File format:MP3 Remark:MPEG1-L1/2/3, MPEG2-L1/2 WAV Sample rate:48 KHz Bit-rate:1536 kbps File format:WAV Remark:linear, aLaw, uLaw, ADPCM, and GSM610 WMA Sample rate:44.1 KHz Audio playback Bit-rate:320 kbps File format:WAV Remark:WMA 7/8/9 AAC Sample rate:48 KHz Bit-rate:320 kbps File format:M4A/AAC Remark:MPEG4 LC-AAC OGG Sample rate:48 KHz Bit-rate:320 kbps File format:OGG/FLC Remark:Ogg Vorbis JPEG: Baseline TIFF: 1 and 8 bits grayscale, 8 bits indexed-color, 8 and 16 bits true color (Unsupport for compression format) BMP: Monochrome, 8 bits indexed-color, RGB, RLE8 GIF RAW: Support following camera models Canon: 1Ds Mark-II, 1D Mark II N, EOS 1D MARK III, EOS 1Ds