Ontology for Indian Music-An Approach for Ontology Learning from Online Music Forums Joe.Pptx
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Particulars of Some Temples of Kerala Contents Particulars of Some
Particulars of some temples of Kerala Contents Particulars of some temples of Kerala .............................................. 1 Introduction ............................................................................................... 9 Temples of Kerala ................................................................................. 10 Temples of Kerala- an over view .................................................... 16 1. Achan Koil Dharma Sastha ...................................................... 23 2. Alathiyur Perumthiri(Hanuman) koil ................................. 24 3. Randu Moorthi temple of Alathur......................................... 27 4. Ambalappuzha Krishnan temple ........................................... 28 5. Amedha Saptha Mathruka Temple ....................................... 31 6. Ananteswar temple of Manjeswar ........................................ 35 7. Anchumana temple , Padivattam, Edapalli....................... 36 8. Aranmula Parthasarathy Temple ......................................... 38 9. Arathil Bhagawathi temple ..................................................... 41 10. Arpuda Narayana temple, Thirukodithaanam ................. 45 11. Aryankavu Dharma Sastha ...................................................... 47 12. Athingal Bhairavi temple ......................................................... 48 13. Attukkal BHagawathy Kshethram, Trivandrum ............. 50 14. Ayilur Akhileswaran (Shiva) and Sri Krishna temples ........................................................................................................... -

RAMA RAVI Papanasam Ashok Ramani
SRUTI The India Music and Dance Society 1436 Joel Drive, Ambler, PA 19002 Presents Carnatic vocal concert by RAMA RAVI Nanditha Ravi - vocal support B.V. Raghavendra Rao - violin Prakash Rao - mridangam Saturday Nov 16, 10:30 AM Carnatic vocal concert by Papanasam Ashok Ramani S. Varadarajan - violin Srimushnam Raja Rao - mridangam Saturday Nov 16, 4:30 PM These concerts are presented as part of Composers Day celebrations at the Colonial Middle School, 716 Belvoir Road, Norristown (Plymouth Township), PA 19401. Other activities of the day include presentations of kritis of various composers by local groups of singers. Please see attached flyer for program details and directions to the venue. Sruti concerts are supported in part by The Philadelphia Music Project, Pennsylvania Council on the Arts, and The Philadelphia Foundation. Artist Profiles RAMA RAVI is one of the leading artists in the field of South Indian Classical Music. She received training at Kalakshetra under the guidance of renowned gurus like Mysore Vasudevacharya, Budalur Krishnamurthi Sastrigal, M.D. Ramanathan and T.K. Ramaswami Iyengar, and subsequently learnt from the late D.K. Jayaraman. She is a leading exponent of the Dhanam- mal School, having also learnt from T.Viswanathan the subtleties, nuances and modes of expression characteristic of this school. She has gained considerably from the guidance given by the late T. Brinda, T. Mukta and T. Sankaran. Rama was the Head of the Department of Music at S. R. College, Tiruchirappalli, for two years. She has performed exten- sively in Sangeet Sammelan recitals and on Doordarshan National Programs, and at prestigious organizations like the Chennai Music Academy and Sri Krishna Gana Sabha. -

USER MANUAL Artiste: M.S
248. Anu Dinamunu Artistes: M.S. Subbulakshmi & Radha Vishwanathan Composer: Ramanathapuram Srinivasa Iyengar 249. Naraveshabhushana Artiste: M.S. Subbulakshmi Lyricist: Traditional Music Director: Kadayanallur S. Venkataraman 250. Manju Nihar Artistes: M.S. Subbulakshmi & Radha Vishwanathan Composer: Annamalai Reddiar 251. Muzhudai Unarndavar USER MANUAL Artiste: M.S. Subbulakshmi Composer: Athma visit www.saregama.com/carvaanmini to download the entire songlist 44 239. Sirai Aarum Artistes: M.S. Subbulakshmi & Radha Vishwanathan Composer: Thirugnana Sambandar 240. Sada Saranga Nayane Artiste: M.S. Subbulakshmi Composer: Mysore H. Yoganarasimham 241. Vanajaakshi 1. Overview - Buttons and Ports 3 Artiste: M.S. Subbulakshmi Composer: Traditional 242. Tum Ho Jag Ke 2. Modes 5 Artiste: M.S. Subbulakshmi Lyricist: Ustad Mohd. Dilshad Khan Music Director: Kadayanallur S. Venkataraman 3. Playback Status Light 8 243. Ko Va Rago Vadito Artiste: M.S. Subbulakshmi Lyricist: Mysore H Yoganarasimham 4. Battery 8 Music Director: Gurunanak Shabad, P.S.Srinivasa Rao 244. Mere To Giridhar Artistes: M.S. Subbulakshmi & Gowri Ramanarayanan 5. Safety Handling 8 Composer: Meera 245. Varuga Varugave 6. Warranty Overview 10 Artistes: M.S. Subbulakshmi & Radha Vishwanathan Composer: Ambujam Krishna 246. Sai Charan Ma 7. Song List 18 Artiste: M.S. Subbulakshmi Lyricist: Suresh Dalal Music Director: Ashit Desai 247. Dinudanenu Devuduvu Nivu Artistes: M.S. Subbulakshmi & Radha Vishwanathan Composer: Annamacharya 2 43 231. Oru Thram Saravana Bhava Artiste: M.S. Subbulakshmi Overview - Buttons and Ports Lyricist: Traditional Music Director: Kadayanallur S. Venkataraman 232. Maanilathai Vaazha Vaika Artiste: M.S. Subbulakshmi Lyricist: Kalki R.Krishnamurthy Music Director: Kadayanallur S. Venkataraman 233. Nee Saati Daivamu Artistes: M.S. Subbulakshmi & Radha Vishwanathan Previous Composer: Muthuswami Dikshitar 234. -

News 21112019115636843Ch
2019 \hw-_À 23 cmhnse 9.00 aWn¡v thZn : taev]-¯qÀ HmUn-täm-dnbw {]nb `à-P-\-§-sf, hniz-{]-kn-²-amb Kpcp-hm-bqÀ t£{X-¯nÂ, `à-P-\-§Ä AXy´w {hX-\n-jvT-tbmsS BN-cn-¡p¶ kpZn-\-amWv Kpcp-hm-bqÀ GIm-Z-in. Cs¡m-Ãs¯ Kpcp-hm-bqÀ GIm-Zin atlmÕhw Unkw-_À 8 (1195 hrÝnIw 22) Rmb-dm-gvN-bmWv. `K-hm³ {ioIrjvW³ alm-`m-cX-bp-²`qan-bn sh¨v AÀÖp-\\v `KhZvKoX D]-tZ-in-¨-Xnsâ kvac-W-bn "D°m\ GIm-Zin' F¶pw Adn-b-s¸-Sp¶ Cu kpZn\w KoXm-Zn-\-ambpw BN- cn-¨p-h-cp-¶p. At¶Znhkw t£{X-¯n tZhkzw hI-bmbn DZ-bm-kvX-a\-]q-P, hnti-jm ImgvNiothen F¶nh D m-bn-cn-¡p-¶-Xm-Wv. Zi-an-\m-fn KP-cm-P³ tIi-h³ A\p-kva-c-Whpw tZhkzw \S-¯n-h-cp-¶p. Kpcp-hm-bq-c-¸-t\mSv At`-Zy-amb lrZ-b-_Ôw kq£n-¡p-Ibpw ac-Ww-hsc F´p-Xs¶ {]bm-k-§- fp- m-bmepw Kpcp-hm-bqÀ GIm-Zin Znhkw apS-§msX Kpcp-hm-bq-cn-se¯n `K-hm\v kwKotXm-]mk\ sNbvX A\-izc IÀ®m-SI kwKoXN{IhÀ¯n {io. sNss¼ sshZy-\mY `mK-h-X-cpsS kvac-WmÀ°w Kpcp-hm-bq-À tZhkzw sNss¼ kwKo-tXm-Õhw 44- hÀjambn \S-¯n-h-cp-¶p. 45-þmw sNss¼ kwKo-tXm Õhw 2019 \hw_À 23 i\nbmgvN cmhnse 9.00\v ta¸-¯qÀ HmUn-täm-dn-b-¯nse sNss¼ kwKoXaÞ]- ¯n _lp.tIcf kwØm\ klIcW Sqdnkw tZhkzw hIp¸v a{´n {io. -

Carnatic Music (Melodic Instrumental) (Code No
(B) CARNATIC MUSIC (MELODIC INSTRUMENTAL) (CODE NO. 032) CLASS–XI: (THEORY)(2019-20) One theory paper Total Marks: 100 2 Hours Marks : 30 Theory: A. History and Theory of Indian Music 1. (a) An outline knowledge of the following Lakshana Grandhas Silappadikaram, Natyasastra, Sangita Ratnakara and Chaturdandi Prakasika. (b) Short life sketch and contributions of the following:- Veena Dhanammal, flute Saraba Sastry, Rajamanikkam Pillai, Tirukkodi Kaval Krishna lyer (violin) Rajaratnam Pillai (Nagasvaram), Thyagaraja, Syamasastry, Muthuswamy Deekshitar, Veena Seshanna. (c) Brief study of the musical forms: Geetam and its varieties; Varnam – Padavarnam – Daruvarna Svarajati, Kriti/Kirtana and Padam 2. Definition and explanation of the following terms: Nada, Sruti, Svara, Vadi, Vivadi:, Samvadi, Anuvadi, Amsa & Nyasa, Jaati, Raga, Tala, Jati, Yati, Suladisapta talas, Nadai, Arohana, Avarohana. 3. Candidates should be able to write in notation the Varnam in the prescribed ragas. 4. Lakshanas of the ragas prescribed. 5. Talas Prescribed: Adi, Roopaka, Misra Chapu and Khanda Chapu. A brief study of Suladi Saptatalas. 6. A brief introduction to Manodhama Sangitam CLASS–XI (PRACTICAL) One Practical Paper Marks: 70 B. Practical Activities 1. Ragas Prescribed: Mayamalavagowla, Sankarabharana, Kharaharapriya, Kalyani, Kambhoji, Madhyamavati, Arabhi, Pantuvarali Kedaragaula, Vasanta, Anandabharavi, Kanada, Dhanyasi. 2. Varnams (atleast three) in Aditala in two degree of speed. 3. Kriti/Kirtana in each of the prescribed ragas, covering the main Talas Adi, Rupakam and Chapu. 4. Brief alapana of the ragas prescribed. 5. Technique of playing niraval and kalpana svaras in Adi, and Rupaka talas in two degrees of speed. 6. The candidate should be able to produce all the gamakas pertaining to the chosen instrument. -

Sanjay Subrahmanyan……………………………Revathi Subramony & Sanjana Narayanan
Table of Contents From the Publications & Outreach Committee ..................................... Lakshmi Radhakrishnan ............ 1 From the President’s Desk ...................................................................... Balaji Raghothaman .................. 2 Connect with SRUTI ............................................................................................................................ 4 SRUTI at 30 – Some reflections…………………………………. ........... Mani, Dinakar, Uma & Balaji .. 5 A Mellifluous Ode to Devi by Sikkil Gurucharan & Anil Srinivasan… .. Kamakshi Mallikarjun ............. 11 Concert – Sanjay Subrahmanyan……………………………Revathi Subramony & Sanjana Narayanan ..... 14 A Grand Violin Trio Concert ................................................................... Sneha Ramesh Mani ................ 16 What is in a raga’s identity – label or the notes?? ................................... P. Swaminathan ...................... 18 Saayujya by T.M.Krishna & Priyadarsini Govind ................................... Toni Shapiro-Phim .................. 20 And the Oscar goes to …… Kaapi – Bombay Jayashree Concert .......... P. Sivakumar ......................... 24 Saarangi – Harsh Narayan ...................................................................... Allyn Miner ........................... 26 Lec-Dem on Bharat Ratna MS Subbulakshmi by RK Shriramkumar .... Prabhakar Chitrapu ................ 28 Bala Bhavam – Bharatanatyam by Rumya Venkateshwaran ................. Roopa Nayak ......................... 33 Dr. M. Balamurali -

Palghat Mani Iyer.Pdf
COVER STORY Palghat T.S. Mani Iyer (1912-1981) Sriram.V ometime in the 17th century, a Raja of Palghat is said to have invited many Brahmin families Sbelonging to the Tanjavur region to his principality. They were to inculcate learning and culture in the area. These families settled in 96 villages of Palghat district and greatly enriched the place. Many of their descendants rose to high positions in administration, business and other walks of life. Several shone as musicians. But the man who was to prefix the name of the district to his own name and make it synonymous with percussion was Mani Iyer, the mridanga maestro. Palghat T.S. Mani Iyer was born on 12th June 1912 at Pazhayanur, Tiruvilvamala Taluk, in Palghat District to Sesham Bhagavatar and Anandambal as their second son. The couple had many children of whom some died early with only two sons (Mani Iyer and a younger brother) and two daughters surviving into adulthood. Sesham Bhagavatar was a vocalist in the Harikatha troupe of Mukkai Sivaramakrishna Bhagavatar, a famous exponent of the art form. Mani was christened Ramaswami at birth— after his grandfather who was a school teacher besides being a good singer. Destined as it seemed Mani Iyer was to acquire fame Young Mani in the field of percussion, the forces that control fates could not have selected a better place for his birth. Tiruvilvamala, a village on the southern side of the Born for the Mridanga Bharatapuzha river, was well known for its Panchavadyam performers. ‘Maddalam’ Venkicchan and Konthai were famed practitioners of the percussive arts. -

Senior School Curriculum 2017-18
SENIOR SCHOOL CURRICULUM 2017-18 VOLUME - III Music and Dance for Class XII Central Board of Secondary Education “Shiksha Sadan”, 17, Rouse Avenue, New Delhi – 110 002 / Telephone : +91-11-23237780 /Website : www.cbseacademic.in Downloaded from: www.cbseportal.com Courtesy : CBSE Senior School Curriculum 2017 - 18 Volume - III CBSE, Delhi – 110092 March, 2017 Copies: Price: ` This book or part thereof may not be reproduced by any person or Agency in any manner Published by: The Secretary, CBSE Printed by: Multi Graphics, 8A/101, WEA Karol Bagh, New Delhi – 110 005, Phone: 25783846 Printed by: II Downloaded from: www.cbseportal.com Courtesy : CBSE CONTENTS Page No. Music and Dance Syllabus (i) Carnatic Music 1 (a) Carnatic Music (Vocal) 2 (b) Carnatic Music (Melodic Instrument) 6 (c) Carnatic Music (Percussion Instrumental) 10 (ii) Hindustani Music 15 (a) Hindustani Music (Vocal) 16 (b) Hindustani Music (Melodic Instrument) 19 (c) Hindustani Music (Percussion Instrumental) 22 (iii) (a) Dances 25 (a) Kathak 27 (b) Bharatnatyam 32 (c) Kuchipudi 36 (d) Odissi 38 (e) Manipuri 42 (f) Kathakali 46 (g) Mohiniyattam 49 III Downloaded from: www.cbseportal.com Courtesy : CBSE SENIOR SCHOOL CURRICULUM 2017-18 VOLUME III (i) Carnatic Music Effective from the academic session 2017–2018 for Classes–XI and XII 1 Downloaded from: www.cbseportal.com Courtesy : CBSE (A) CARNATIC MUSIC (VOCAL): (CODE NO. 031) CLASS–XII (2017-18): (THEORY) One Theory Paper Total Marks: 100 3 Hours Marks: 30 72 Periods Theory: A. History and Theory of Indian Music 1. (a) Brief history of Carnatic music with special reference to Sangita Saramrita, Sangita Sampradaya Pradarsini, Svaramelakalanidhi, Raga Vibodham, Brihaddesi. -

June 2018 (Special Edition on Ganakaladhara Madurai Mani Iyer)
Lalitha Kala Tarangini Premier Quarterly Music Magazine from Sri Rama Lalitha Kala Mandira Volume 2018, Issue 2 June 2018 Sangeetha Kalarathna Titte Krishna Iyengar RR Keshavamurthy - The Lion of Karnataka DK Pattammal the Immortal legend Indian Music Experience (IME) Special Edition on Madurai Mani Iyer Raga Laya Prabha award felicitation Sri Rama Lalitha Kala Mandira awarded “Raaga Laya Prabha” on 13th May 2018 to Aditi B Prahalad (Vocal), BK Raghu (Violin) and Akshay Anand (Mridangam) who are the upcoming youngsters from Bangalore. This award is to commemorate the memory of the Founder-Director, Karnataka Kalashree GV Ranganayakamma, Vidushi GV Neela and her Sister, Founder-patron and Veena artiste Dr. GV Vijayalakshmi. The award carries a cash prize of Rs. Twenty Five Thousand and a citation. The award function was followed by a concert of Abhishek Raghuram (Vocal). B Vittal Rangan (Violin), NC Bharadwaj (Mridanga) and Guruprasanna (Kanjra) in presence of a capacity crowd. Left to Right Standing - Sri DR Srikantaiah - President, Akshay Anand, Sri GV Krishna Prasad - Hon. Secretary, Vidushi Neela Ramgopal,Vidwan Abhishek Raghuram, Aditi B Prahalad, BK Raghu June 2018 Titte Krishna Iyengar and RR Keshavamurthy. I am sure they will be an inspiration to the youngsters. Ganakaladhara Madurai Mani Iyer (MMI) shone like a jewel during the golden period of Karnatak music. He, Music world celebrated the centenary year of DK Pattam- along with GN Balasubramaniam (GN Sir) revolutionised mal a doyen in her own right on March 19, 2019. Vice karnatak music so much so that we talk about music in President of India, Shri M Venkaiah Naidu inaugurated the terms of before MMI, GN Sir and after MMI and GN Sir. -
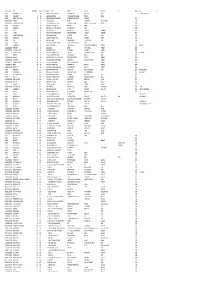
Mgl-Int-1-2013-Unpaid Shareholders List As on 31
DEMAT ID_FOLIO NAME WARRANT NO MICR DIVIDEND AMOUNT ADDRESS 1 ADDRESS 2 ADDRESS 3 ADDRESS 4 CITY PINCODE JH1 JH2 000404 MOHAMMED SHAFEEQ 27 508 30000.00 PUTHIYAVEETIL HOUSE CHENTHRAPPINNI TRICHUR DIST. KERALA DR. ABDUL HAMEED P.A. 002679 NARAYANAN P S 51 532 12000.00 PANAT HOUSE P O KARAYAVATTOM, VALAPAD THRISSUR KERALA 001431 JITENDRA DATTA MISRA 89 570 36000.00 BHRATI AJAY TENAMENTS 5 VASTRAL RAOD WADODHAV PO AHMEDABAD 382415 IN30066910088862 K PHANISRI 116 597 15900.00 Q NO 197A SECTOR I UKKUNAGARAM VISAKHAPATNAM 530032 IN30047640586716 P C MURALEEDHARAN NAIR 120 601 15000.00 DOOR NO 92 U P STAIRS DEVIKALAYA 8TH MAIN RD 9TH CROSS SARASWATHIPURAM MYSORE 570009 001424 BALARAMAN S N 126 607 60000.00 14 ESOOF LUBBAI ST TRIPLICANE MADRAS 600005 002473 GUNASEKARAN V 128 609 30000.00 NO.5/1324,18TH MAIN ROAD ANNA NAGAR WEST CHENNAI 600040 000697 AMALA S. 143 624 12000.00 36 CAR STREET SOWRIPALAYAM COIMBATORE TAMILNADU 641028 000953 SELVAN P. 150 631 18000.00 18, DHANALAKSHMI NAGAR AVARAMPALAYAM ROAD, COIMBATORE TAMILNADU 641044 001209 PANCHIKKAL NARAYANAN 153 634 60000.00 NANU BHAVAN KACHERIPARA KANNUR KERALA 670009 002985 BABY MATHEW 173 654 12000.00 PUTHRUSSERY HOUSE PULIKKAYAM KODANCHERY CALICUT 673580 001680 RAVI P 182 663 30000.00 SUDARSAN CHEMBAKKASSERY TATTAMANGALAM KERALA 678102 001440 RAJI GOPALAN 198 679 60000.00 ANASWARA KUTTIPURAM THIROOR ROAD KUTTYPURAM KERALA 679571 001756 UNNIKRISHNAN P 222 703 30000.00 'SREE SAILAM' PUDUKULAM ROAD PUTHURKKARA, AYYANTHOLE POST THRISSUR 680003 AMBIKA C P 1201090001296071 REBIN SUNNY 227 708 18750.00 21/14 BEETHEL P O AYYANTHOLE THRISSUR 680003 IN30163741039292 NEENAMMA VINCENT 260 741 18000.00 PLOT NO103 NEHRUNAGAR KURIACHIRA THRISSUR 680006 002191 PRESANNA BABU M V 310 791 30000.00 MURIYANKATTIL HOUSE EDAKULAM IRINJALAKUDA, THRISSUR KERALA 680121 SHAILA BABU 001567 ABUBAKER P B 375 856 15000.00 PUITHIYAVEETIL HOUSE P O KURUMPILAVU THRISSUR KERALA 680564 IN30163741303442 REKHA M P 419 900 20250.00 FLAT NO 571 LUCKY HOME PLAZA NEAR TRIPRAYAR TEMPLE NATTIKA P O THRISSUR 680566 1201090004031286 KUMARAN K K . -

Sri Kamalamba Nava Aavarana Kritis
Sri Kamalamba Nava Aavarana Kritis Out of his devotion to Sri Kamalamba, (one of the 64 Sakti Peethams in India), the celebrated deity at the famous Tyagaraja Temple in Tiruvarur and his compassion for all bhaktas, Sri Muthuswamy Dikshitar composed the Kamalamba Navavarana kritis, expounding in each of the nine kritis, the details of the each avarana of the Sri Chakra, including the devatas and the yoginis. Singing these kritis with devotion, sraddha and understanding would be the easy way to Sri Vidya Upasana. Kamala is one of the ten maha vidyas, the principle deities of the Shaktha tradition of Tantra. But, the Sri Kamalamba referred to by Sri Muthuswami Dikshitar in this set of kritis, is the Supreme Divine Mother herself. The immediate inspiration to Dikshitar was, of course, Sri Kamalamba (regarded one of the sixty-four Shakthi centers), the celebrated deity at the famous temple of Sri Tyagaraja and Sri Nilothpalambika in Tiruvavur. Sri Muthuswami Dikshitar follows the Smahara krama, the absorption path, of Sri Chakra puja and proceeds from the outer avarana towards the Bindu in the ninth avarana at the center of the Sri Chakra. At each avarana, he submits his salutation and worships the presiding deity, the yogini (secondary deity) and the attendant siddhis of that avarana; and describes the salient features of the avarana according to the Kadi School of the Dakshinamurthy tradition of Sri Vidya. It is in effect both worship and elucidation. Dikshitar had developed a fascination for composing a series of kritis on a composite theme, perhaps in an attempt to explore the various dimensions of the subject. -
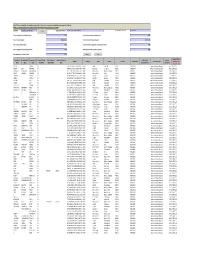
CIN/BCIN Company/Bank Name Date of AGM(DD-MON-YYYY)
Note: This sheet is applicable for uploading the particulars related to the unclaimed and unpaid amount pending with company. Make sure that the details are in accordance with the information already provided in e-form IEPF-2 CIN/BCIN L67120RJ1951PLC045966 Prefill Company/Bank Name JK TYRE & INDUSTRIES LIMITED Date Of AGM(DD-MON-YYYY) 02-SEP-2016 Sum of unpaid and unclaimed dividend 0.00 Sum of interest on matured debentures 0.00 Sum of matured deposit 10986784.00 Sum of interest on matured deposit 2652436.00 Sum of matured debentures 0.00 Sum of interest on application money due for refund 0.00 Sum of application money due for refund 0.00 Redemption amount of preference shares 0.00 Sales proceed for fractional shares 0.00 Validate Clear Proposed Date of Investor First Investor Middle Investor Last Father/Husband Father/Husband Father/Husband Last DP Id-Client Id- Amount Address Country State District Pin Code Folio Number Investment Type transfer to IEPF Name Name Name First Name Middle Name Name Account Number transferred (DD-MON-YYYY) KANTA SINGHAL NA C-175 SURAJ MAL VIHAR DELHI INDIA Delhi East Delhi 110092 P00149014 Interest on matured deposits 285 11-SEP-2016 PADMA DEVI MAKHARIA NA WARD NO.6/38 PO. PILANI PILANI RAJASTHANINDIA Rajasthan Jhunjhunu 333031 P00140944 Amount for matured deposits 460 12-SEP-2016 GUNVANTI JHAMATMAL MIRCHANDANI NA 89 GR FLOOR SINDHUWADI GHATKOPARINDIA EAST MUMBAI MaharashtraMAHARASHTRA Mumbai Suburban 400077 P00142829 Interest on matured deposits 208 14-SEP-2016 DINKER MANGESH MUJMDAR NA SR.156 PLOTNO.15 GANESHNO.2 OPP.SHIVAINDIA MANDIR (VISHWESHWAR Maharashtra )BIJALI NAGAR Pune CHINCHWAD PUNE MAHARASHTRA 411033 P00134078 Interest on matured deposits 189 19-SEP-2016 LOVELEEN KHANNA NA C/O MRS MADHU KOHLI C-2597 SUSHANTINDIA LOK GURGAON Haryana HARYANA Gurgaon 122009 P00132279 Amount for matured deposits 177 19-SEP-2016 AZEEZA SULTANA NA DOOR NO.196 K.E.B.