Practical Regression and Anova Using R
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

HO Hartley Publications by Year
APPENDIX H.O. Hartley Publications by Year (1935-1980) BOOKS Pearson, ES; Hartley, HO. Biomtrika Tables for Statisticians, Vol. I. Biometrika Publications, Cambridge University Press, Bentley House, London, 1954 Greenwood, JA; Hartley, HO. Guide to Tables in Mathematical Statistics, Princeton University Press, Princeton, New Jersey, 1961 Pearson, ES; Hartley, HO. Biomtrika Tables for Statisticians, Vol. II. Biometrika Publications, Cambridge University Press, Bentley House, London, 1972 PEER- REVIEWED PUBLISHED MANUSCRIPTS 1935 *Hirshchfeld, HO. A Connection between Correlation and Contingency. Proceedings of the Cambridge Philosophical Society (Math. Proc.) 31: 520-524 1936 *Hirschfeld, HO. A Generalization of Picard’s Method of Successive Approximation. Proceedings of the Cambridge Philosophical Society 32: 86-95 *Hirschfeld, HO. Continuation of Differentiable Functions through the Plane. The Quarterly Journal of Mathematics, Oxford Series, 7: 1-15 Wishart, J; *Hirschfeld, HO. A Theorem Concerning the Distribution of Joins between Line Segments. Journal of the London Mathematical Society, 11: 227-235 1937 *Hirschfeld, HO. The Distribution of the Ratio of Covariance Estimates in Two Samples Drawn from Normal Bivariate Populations. Biometrika 29: 65-79 *Manuscripts dated from 1935 to 1937 are listed under born name of Hirschfeld, Hermann Otto. Manuscripts dated from 1938 -1980 are listed under changed name of Hartley, Herman Otto. 1938 Hunter, H; Hartley, HO. Relation of Ear Survival to the Nitrogen Content of Certain Varieties of Barley – With a Statistical Study. Journal of Agricultural Science 28: 472-502 Hartley, HO. Studentization and Large Sample Theory. Supplement to the Journal of the Royal Statistical Society 5: 80-88 1940 Hartley, HO. Testing the Homogeneity of a Set of Variances. -

A Simple but Accurate Excel User-Defined Function to Calculate Studentized Range Quantiles for Tukey Tests
A Simple but Accurate Excel United States Department of User-Defined Function to Agriculture Calculate Studentized Range Agricultural Quantiles for Tukey Tests Research Service K. Thomas Klasson Southern Regional Research Center Technical Report June 2019 Revised February 2020 The Agricultural Research Service (ARS) is the U.S. Department of Agriculture's chief scientific in-house research agency. Our job is finding solutions to agricultural problems that affect Americans every day from field to table. ARS conducts research to develop and transfer solutions to agricultural problems of high national priority and provide information access and dissemination of its research results. The U.S. Department of Agriculture (USDA) prohibits discrimination in all its programs and activities on the basis of race, color, national origin, age, disability, and where applicable, sex, marital status, familial status, parental status, religion, sexual orientation, genetic information, political beliefs, reprisal, or because all or part of an individual's income is derived from any public assistance program. (Not all prohibited bases apply to all programs.) Persons with disabilities who require alternative means for communication of program information (Braille, large print, audiotape, etc.) should contact USDA's TARGET Center at (202) 720-2600 (voice and TDD). To file a complaint of discrimination, write to USDA, Director, Office of Civil Rights, 1400 Independence Avenue, S.W., Washington, D.C. 20250-9410, or call (800) 795-3272 (voice) or (202) 720-6382 (TDD). USDA is an equal opportunity provider and employer. K. Thomas Klasson is a Supervisory Chemical Engineer at USDA-ARS, Southern Regional Research Center, 1100 Robert E. Lee Boulevard, New Orleans, LA 70124; email: [email protected] A Simple but Accurate Excel User-Defined Function to Calculate Studentized Range Quantiles for Tukey Tests K. -

A Simple Censored Median Regression Estimator
Statistica Sinica 16(2006), 1043-1058 A SIMPLE CENSORED MEDIAN REGRESSION ESTIMATOR Lingzhi Zhou The Hong Kong University of Science and Technology Abstract: Ying, Jung and Wei (1995) proposed an estimation procedure for the censored median regression model that regresses the median of the survival time, or its transform, on the covariates. The procedure requires solving complicated nonlinear equations and thus can be very difficult to implement in practice, es- pecially when there are multiple covariates. Moreover, the asymptotic covariance matrix of the estimator involves the density of the errors that cannot be esti- mated reliably. In this paper, we propose a new estimator for the censored median regression model. Our estimation procedure involves solving some convex min- imization problems and can be easily implemented through linear programming (Koenker and D'Orey (1987)). In addition, a resampling method is presented for estimating the covariance matrix of the new estimator. Numerical studies indi- cate the superiority of the finite sample performance of our estimator over that in Ying, Jung and Wei (1995). Key words and phrases: Censoring, convexity, LAD, resampling. 1. Introduction The accelerated failure time (AFT) model, which relates the logarithm of the survival time to covariates, is an attractive alternative to the popular Cox (1972) proportional hazards model due to its ease of interpretation. The model assumes that the failure time T , or some monotonic transformation of it, is linearly related to the covariate vector Z 0 Ti = β0Zi + "i; i = 1; : : : ; n: (1.1) Under censoring, we only observe Yi = min(Ti; Ci), where Ci are censoring times, and Ti and Ci are independent conditional on Zi. -

Cluster Analysis, a Powerful Tool for Data Analysis in Education
International Statistical Institute, 56th Session, 2007: Rita Vasconcelos, Mßrcia Baptista Cluster Analysis, a powerful tool for data analysis in Education Vasconcelos, Rita Universidade da Madeira, Department of Mathematics and Engeneering Caminho da Penteada 9000-390 Funchal, Portugal E-mail: [email protected] Baptista, Márcia Direcção Regional de Saúde Pública Rua das Pretas 9000 Funchal, Portugal E-mail: [email protected] 1. Introduction A database was created after an inquiry to 14-15 - year old students, which was developed with the purpose of identifying the factors that could socially and pedagogically frame the results in Mathematics. The data was collected in eight schools in Funchal (Madeira Island), and we performed a Cluster Analysis as a first multivariate statistical approach to this database. We also developed a logistic regression analysis, as the study was carried out as a contribution to explain the success/failure in Mathematics. As a final step, the responses of both statistical analysis were studied. 2. Cluster Analysis approach The questions that arise when we try to frame socially and pedagogically the results in Mathematics of 14-15 - year old students, are concerned with the types of decisive factors in those results. It is somehow underlying our objectives to classify the students according to the factors understood by us as being decisive in students’ results. This is exactly the aim of Cluster Analysis. The hierarchical solution that can be observed in the dendogram presented in the next page, suggests that we should consider the 3 following clusters, since the distances increase substantially after it: Variables in Cluster1: mother qualifications; father qualifications; student’s results in Mathematics as classified by the school teacher; student’s results in the exam of Mathematics; time spent studying. -

The Detection of Heteroscedasticity in Regression Models for Psychological Data
Psychological Test and Assessment Modeling, Volume 58, 2016 (4), 567-592 The detection of heteroscedasticity in regression models for psychological data Andreas G. Klein1, Carla Gerhard2, Rebecca D. Büchner2, Stefan Diestel3 & Karin Schermelleh-Engel2 Abstract One assumption of multiple regression analysis is homoscedasticity of errors. Heteroscedasticity, as often found in psychological or behavioral data, may result from misspecification due to overlooked nonlinear predictor terms or to unobserved predictors not included in the model. Although methods exist to test for heteroscedasticity, they require a parametric model for specifying the structure of heteroscedasticity. The aim of this article is to propose a simple measure of heteroscedasticity, which does not need a parametric model and is able to detect omitted nonlinear terms. This measure utilizes the dispersion of the squared regression residuals. Simulation studies show that the measure performs satisfactorily with regard to Type I error rates and power when sample size and effect size are large enough. It outperforms the Breusch-Pagan test when a nonlinear term is omitted in the analysis model. We also demonstrate the performance of the measure using a data set from industrial psychology. Keywords: Heteroscedasticity, Monte Carlo study, regression, interaction effect, quadratic effect 1Correspondence concerning this article should be addressed to: Prof. Dr. Andreas G. Klein, Department of Psychology, Goethe University Frankfurt, Theodor-W.-Adorno-Platz 6, 60629 Frankfurt; email: [email protected] 2Goethe University Frankfurt 3International School of Management Dortmund Leipniz-Research Centre for Working Environment and Human Factors 568 A. G. Klein, C. Gerhard, R. D. Büchner, S. Diestel & K. Schermelleh-Engel Introduction One of the standard assumptions underlying a linear model is that the errors are inde- pendently identically distributed (i.i.d.). -

Statistical Analysis 8: Two-Way Analysis of Variance (ANOVA)
Statistical Analysis 8: Two-way analysis of variance (ANOVA) Research question type: Explaining a continuous variable with 2 categorical variables What kind of variables? Continuous (scale/interval/ratio) and 2 independent categorical variables (factors) Common Applications: Comparing means of a single variable at different levels of two conditions (factors) in scientific experiments. Example: The effective life (in hours) of batteries is compared by material type (1, 2 or 3) and operating temperature: Low (-10˚C), Medium (20˚C) or High (45˚C). Twelve batteries are randomly selected from each material type and are then randomly allocated to each temperature level. The resulting life of all 36 batteries is shown below: Table 1: Life (in hours) of batteries by material type and temperature Temperature (˚C) Low (-10˚C) Medium (20˚C) High (45˚C) 1 130, 155, 74, 180 34, 40, 80, 75 20, 70, 82, 58 2 150, 188, 159, 126 136, 122, 106, 115 25, 70, 58, 45 type Material 3 138, 110, 168, 160 174, 120, 150, 139 96, 104, 82, 60 Source: Montgomery (2001) Research question: Is there difference in mean life of the batteries for differing material type and operating temperature levels? In analysis of variance we compare the variability between the groups (how far apart are the means?) to the variability within the groups (how much natural variation is there in our measurements?). This is why it is called analysis of variance, abbreviated to ANOVA. This example has two factors (material type and temperature), each with 3 levels. Hypotheses: The 'null hypothesis' might be: H0: There is no difference in mean battery life for different combinations of material type and temperature level And an 'alternative hypothesis' might be: H1: There is a difference in mean battery life for different combinations of material type and temperature level If the alternative hypothesis is accepted, further analysis is performed to explore where the individual differences are. -

Testing Hypotheses for Differences Between Linear Regression Lines
United States Department of Testing Hypotheses for Differences Agriculture Between Linear Regression Lines Forest Service Stanley J. Zarnoch Southern Research Station e-Research Note SRS–17 May 2009 Abstract The general linear model (GLM) is often used to test for differences between means, as for example when the Five hypotheses are identified for testing differences between simple linear analysis of variance is used in data analysis for designed regression lines. The distinctions between these hypotheses are based on a priori assumptions and illustrated with full and reduced models. The studies. However, the GLM has a much wider application contrast approach is presented as an easy and complete method for testing and can also be used to compare regression lines. The for overall differences between the regressions and for making pairwise GLM allows for the use of both qualitative and quantitative comparisons. Use of the Bonferroni adjustment to ensure a desired predictor variables. Quantitative variables are continuous experimentwise type I error rate is emphasized. SAS software is used to illustrate application of these concepts to an artificial simulated dataset. The values such as diameter at breast height, tree height, SAS code is provided for each of the five hypotheses and for the contrasts age, or temperature. However, many predictor variables for the general test and all possible specific tests. in the natural resources field are qualitative. Examples of qualitative variables include tree class (dominant, Keywords: Contrasts, dummy variables, F-test, intercept, SAS, slope, test of conditional error. codominant); species (loblolly, slash, longleaf); and cover type (clearcut, shelterwood, seed tree). Fraedrich and others (1994) compared linear regressions of slash pine cone specific gravity and moisture content Introduction on collection date between families of slash pine grown in a seed orchard. -
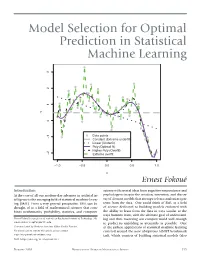
Model Selection for Optimal Prediction in Statistical Machine Learning
Model Selection for Optimal Prediction in Statistical Machine Learning Ernest Fokou´e Introduction science with several ideas from cognitive neuroscience and At the core of all our modern-day advances in artificial in- psychology to inspire the creation, invention, and discov- telligence is the emerging field of statistical machine learn- ery of abstract models that attempt to learn and extract pat- ing (SML). From a very general perspective, SML can be terns from the data. One could think of SML as a field thought of as a field of mathematical sciences that com- of science dedicated to building models endowed with bines mathematics, probability, statistics, and computer the ability to learn from the data in ways similar to the ways humans learn, with the ultimate goal of understand- Ernest Fokou´eis a professor of statistics at Rochester Institute of Technology. His ing and then mastering our complex world well enough email address is [email protected]. to predict its unfolding as accurately as possible. One Communicated by Notices Associate Editor Emilie Purvine. of the earliest applications of statistical machine learning For permission to reprint this article, please contact: centered around the now ubiquitous MNIST benchmark [email protected]. task, which consists of building statistical models (also DOI: https://doi.org/10.1090/noti2014 FEBRUARY 2020 NOTICES OF THE AMERICAN MATHEMATICAL SOCIETY 155 known as learning machines) that automatically learn and Theoretical Foundations accurately recognize handwritten digits from the United It is typical in statistical machine learning that a given States Postal Service (USPS). A typical deployment of an problem will be solved in a wide variety of different ways. -

Residuals, Part II
Biostatistics 650 Mon, November 5 2001 Residuals, Part II Key terms External Studentization Outliers Added Variable Plot — Partial Regression Plot Partial Residual Plot — Component Plus Residual Plot Key ideas/results ¢ 1. An external estimate of ¡ comes from refitting the model without observation . Amazingly, it has an easy formula: £ ¦!¦ ¦ £¥¤§¦©¨ "# 2. Externally Studentized Residuals $ ¦ ¦©¨ ¦!¦)( £¥¤§¦&% ' Ordinary residuals standardized with £*¤§¦ . Also known as R-Student. 3. Residual Taxonomy Names Definition Distribution ¦!¦ ¦+¨-,¥¦ ,0¦ 1 Ordinary ¡ 5 /. &243 ¦768¤§¦©¨ ¦ ¦!¦ 1 ¦!¦ PRESS ¡ &243 9' 5 $ Studentized ¦©¨ ¦ £ ¦!¦ ¤0> % = Internally Studentized : ;<; $ $ Externally Studentized ¦+¨ ¦ £?¤§¦ ¦!¦ ¤0>¤A@ % R-Student = 4. Outliers are unusually large observations, due to an unmodeled shift or an (unmodeled) increase in variance. 5. Outliers are not necessarily bad points; they simply are not consistent with your model. They may posses valuable information about the inadequacies of your model. 1 PRESS Residuals & Studentized Residuals Recall that the PRESS residual has a easy computation form ¦ ¦©¨ PRESS ¦!¦ ( ¦!¦ It’s easy to show that this has variance ¡ , and hence a standardized PRESS residual is 9 ¦ ¦ ¦!¦ ¦ PRESS ¨ ¨ ¨ ¦ : £ ¦!¦ £ ¦!¦ £ ¦ ¦ % % % ' When we standardize a PRESS residual we get the studentized residual! This is very informa- ,¥¦ ¦ tive. We understand the PRESS residual to be the residual at ¦ if we had omitted from the 3 model. However, after adjusting for it’s variance, we get the same thing as a studentized residual. Hence the standardized residual can be interpreted as a standardized PRESS residual. Internal vs External Studentization ,*¦ ¦ The PRESS residuals remove the impact of point ¦ on the fit at . But the studentized 3 ¢ ¦ ¨ ¦ £?% ¦!¦ £ residual : can be corrupted by point by way of ; a large outlier will inflate the residual mean square, and hence £ . -

5. Dummy-Variable Regression and Analysis of Variance
Sociology 740 John Fox Lecture Notes 5. Dummy-Variable Regression and Analysis of Variance Copyright © 2014 by John Fox Dummy-Variable Regression and Analysis of Variance 1 1. Introduction I One of the limitations of multiple-regression analysis is that it accommo- dates only quantitative explanatory variables. I Dummy-variable regressors can be used to incorporate qualitative explanatory variables into a linear model, substantially expanding the range of application of regression analysis. c 2014 by John Fox Sociology 740 ° Dummy-Variable Regression and Analysis of Variance 2 2. Goals: I To show how dummy regessors can be used to represent the categories of a qualitative explanatory variable in a regression model. I To introduce the concept of interaction between explanatory variables, and to show how interactions can be incorporated into a regression model by forming interaction regressors. I To introduce the principle of marginality, which serves as a guide to constructing and testing terms in complex linear models. I To show how incremental I -testsareemployedtotesttermsindummy regression models. I To show how analysis-of-variance models can be handled using dummy variables. c 2014 by John Fox Sociology 740 ° Dummy-Variable Regression and Analysis of Variance 3 3. A Dichotomous Explanatory Variable I The simplest case: one dichotomous and one quantitative explanatory variable. I Assumptions: Relationships are additive — the partial effect of each explanatory • variable is the same regardless of the specific value at which the other explanatory variable is held constant. The other assumptions of the regression model hold. • I The motivation for including a qualitative explanatory variable is the same as for including an additional quantitative explanatory variable: to account more fully for the response variable, by making the errors • smaller; and to avoid a biased assessment of the impact of an explanatory variable, • as a consequence of omitting another explanatory variables that is relatedtoit. -

Testing for Uncorrelated Residuals in Dynamic Count Models with an Application to Corporate Bankruptcy
Munich Personal RePEc Archive Testing for Uncorrelated Residuals in Dynamic Count Models with an Application to Corporate Bankruptcy Sant’Anna, Pedro H. C. Universidad Carlos III de Madrid May 2013 Online at https://mpra.ub.uni-muenchen.de/48429/ MPRA Paper No. 48429, posted 19 Jul 2013 13:15 UTC Testing for Uncorrelated Residuals in Dynamic Count Models with an Application to Corporate Bankruptcy Pedro H. C. Sant’Anna Universidad Carlos III de Madrid, Getafe, 28903, Spain [email protected] Abstract This article proposes a new diagnostic test for dynamic count models, which is well suited for risk management. Our test proposal is of the Portmanteau-type test for lack of residual autocorrelation. Unlike previous proposals, the resulting test statistic is asymptotically pivotal when innovations are uncorrelated, but not necessarily iid nor a martingale difference. Moreover, the proposed test is able to detect local alter- natives converging to the null at the parametric rate T −1/2, with T the sample size. The finite sample performance of the test statistic is examined by means of a Monte Carlo experiment. Finally, using a dataset on U.S. corporate bankruptcies, we apply our test proposal to check if common risk models are correctly specified. Keywords: Time Series of counts; Residual autocorrelation function; Model checking; Credit risk management. 1 1. Introduction Credit risk affects virtually every financial contract. Therefore the measurement, pricing and management of credit risk have received much attention from economists, bank supervisors and regulators, and financial market practitioners. A widely used measure of credit risk is the probability of corporate default (PD). -

Analysis of Variance and Analysis of Variance and Design of Experiments of Experiments-I
Analysis of Variance and Design of Experimentseriments--II MODULE ––IVIV LECTURE - 19 EXPERIMENTAL DESIGNS AND THEIR ANALYSIS Dr. Shalabh Department of Mathematics and Statistics Indian Institute of Technology Kanpur 2 Design of experiment means how to design an experiment in the sense that how the observations or measurements should be obtained to answer a qqyuery inavalid, efficient and economical way. The desigggning of experiment and the analysis of obtained data are inseparable. If the experiment is designed properly keeping in mind the question, then the data generated is valid and proper analysis of data provides the valid statistical inferences. If the experiment is not well designed, the validity of the statistical inferences is questionable and may be invalid. It is important to understand first the basic terminologies used in the experimental design. Experimental unit For conducting an experiment, the experimental material is divided into smaller parts and each part is referred to as experimental unit. The experimental unit is randomly assigned to a treatment. The phrase “randomly assigned” is very important in this definition. Experiment A way of getting an answer to a question which the experimenter wants to know. Treatment Different objects or procedures which are to be compared in an experiment are called treatments. Sampling unit The object that is measured in an experiment is called the sampling unit. This may be different from the experimental unit. 3 Factor A factor is a variable defining a categorization. A factor can be fixed or random in nature. • A factor is termed as fixed factor if all the levels of interest are included in the experiment.