Lavaan: Latent Variable Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Dialetheists' Lies About the Liar
PRINCIPIA 22(1): 59–85 (2018) doi: 10.5007/1808-1711.2018v22n1p59 Published by NEL — Epistemology and Logic Research Group, Federal University of Santa Catarina (UFSC), Brazil. DIALETHEISTS’LIES ABOUT THE LIAR JONAS R. BECKER ARENHART Departamento de Filosofia, Universidade Federal de Santa Catarina, BRAZIL [email protected] EDERSON SAFRA MELO Departamento de Filosofia, Universidade Federal do Maranhão, BRAZIL [email protected] Abstract. Liar-like paradoxes are typically arguments that, by using very intuitive resources of natural language, end up in contradiction. Consistent solutions to those paradoxes usually have difficulties either because they restrict the expressive power of the language, orelse because they fall prey to extended versions of the paradox. Dialetheists, like Graham Priest, propose that we should take the Liar at face value and accept the contradictory conclusion as true. A logical treatment of such contradictions is also put forward, with the Logic of Para- dox (LP), which should account for the manifestations of the Liar. In this paper we shall argue that such a formal approach, as advanced by Priest, is unsatisfactory. In order to make contradictions acceptable, Priest has to distinguish between two kinds of contradictions, in- ternal and external, corresponding, respectively, to the conclusions of the simple and of the extended Liar. Given that, we argue that while the natural interpretation of LP was intended to account for true and false sentences, dealing with internal contradictions, it lacks the re- sources to tame external contradictions. Also, the negation sign of LP is unable to represent internal contradictions adequately, precisely because of its allowance of sentences that may be true and false. -

Logic, Proofs
CHAPTER 1 Logic, Proofs 1.1. Propositions A proposition is a declarative sentence that is either true or false (but not both). For instance, the following are propositions: “Paris is in France” (true), “London is in Denmark” (false), “2 < 4” (true), “4 = 7 (false)”. However the following are not propositions: “what is your name?” (this is a question), “do your homework” (this is a command), “this sentence is false” (neither true nor false), “x is an even number” (it depends on what x represents), “Socrates” (it is not even a sentence). The truth or falsehood of a proposition is called its truth value. 1.1.1. Connectives, Truth Tables. Connectives are used for making compound propositions. The main ones are the following (p and q represent given propositions): Name Represented Meaning Negation p “not p” Conjunction p¬ q “p and q” Disjunction p ∧ q “p or q (or both)” Exclusive Or p ∨ q “either p or q, but not both” Implication p ⊕ q “if p then q” Biconditional p → q “p if and only if q” ↔ The truth value of a compound proposition depends only on the value of its components. Writing F for “false” and T for “true”, we can summarize the meaning of the connectives in the following way: 6 1.1. PROPOSITIONS 7 p q p p q p q p q p q p q T T ¬F T∧ T∨ ⊕F →T ↔T T F F F T T F F F T T F T T T F F F T F F F T T Note that represents a non-exclusive or, i.e., p q is true when any of p, q is true∨ and also when both are true. -

Logic, Sets, and Proofs David A
Logic, Sets, and Proofs David A. Cox and Catherine C. McGeoch Amherst College 1 Logic Logical Statements. A logical statement is a mathematical statement that is either true or false. Here we denote logical statements with capital letters A; B. Logical statements be combined to form new logical statements as follows: Name Notation Conjunction A and B Disjunction A or B Negation not A :A Implication A implies B if A, then B A ) B Equivalence A if and only if B A , B Here are some examples of conjunction, disjunction and negation: x > 1 and x < 3: This is true when x is in the open interval (1; 3). x > 1 or x < 3: This is true for all real numbers x. :(x > 1): This is the same as x ≤ 1. Here are two logical statements that are true: x > 4 ) x > 2. x2 = 1 , (x = 1 or x = −1). Note that \x = 1 or x = −1" is usually written x = ±1. Converses, Contrapositives, and Tautologies. We begin with converses and contrapositives: • The converse of \A implies B" is \B implies A". • The contrapositive of \A implies B" is \:B implies :A" Thus the statement \x > 4 ) x > 2" has: • Converse: x > 2 ) x > 4. • Contrapositive: x ≤ 2 ) x ≤ 4. 1 Some logical statements are guaranteed to always be true. These are tautologies. Here are two tautologies that involve converses and contrapositives: • (A if and only if B) , ((A implies B) and (B implies A)). In other words, A and B are equivalent exactly when both A ) B and its converse are true. -

Lecture 1: Propositional Logic
Lecture 1: Propositional Logic Syntax Semantics Truth tables Implications and Equivalences Valid and Invalid arguments Normal forms Davis-Putnam Algorithm 1 Atomic propositions and logical connectives An atomic proposition is a statement or assertion that must be true or false. Examples of atomic propositions are: “5 is a prime” and “program terminates”. Propositional formulas are constructed from atomic propositions by using logical connectives. Connectives false true not and or conditional (implies) biconditional (equivalent) A typical propositional formula is The truth value of a propositional formula can be calculated from the truth values of the atomic propositions it contains. 2 Well-formed propositional formulas The well-formed formulas of propositional logic are obtained by using the construction rules below: An atomic proposition is a well-formed formula. If is a well-formed formula, then so is . If and are well-formed formulas, then so are , , , and . If is a well-formed formula, then so is . Alternatively, can use Backus-Naur Form (BNF) : formula ::= Atomic Proposition formula formula formula formula formula formula formula formula formula formula 3 Truth functions The truth of a propositional formula is a function of the truth values of the atomic propositions it contains. A truth assignment is a mapping that associates a truth value with each of the atomic propositions . Let be a truth assignment for . If we identify with false and with true, we can easily determine the truth value of under . The other logical connectives can be handled in a similar manner. Truth functions are sometimes called Boolean functions. 4 Truth tables for basic logical connectives A truth table shows whether a propositional formula is true or false for each possible truth assignment. -

Hardware Abstract the Logic Gates References Results Transistors Through the Years Acknowledgements
The Practical Applications of Logic Gates in Computer Science Courses Presenters: Arash Mahmoudian, Ashley Moser Sponsored by Prof. Heda Samimi ABSTRACT THE LOGIC GATES Logic gates are binary operators used to simulate electronic gates for design of circuits virtually before building them with-real components. These gates are used as an instrumental foundation for digital computers; They help the user control a computer or similar device by controlling the decision making for the hardware. A gate takes in OR GATE AND GATE NOT GATE an input, then it produces an algorithm as to how The OR gate is a logic gate with at least two An AND gate is a consists of at least two A NOT gate, also known as an inverter, has to handle the output. This process prevents the inputs and only one output that performs what inputs and one output that performs what is just a single input with rather simple behavior. user from having to include a microprocessor for is known as logical disjunction, meaning that known as logical conjunction, meaning that A NOT gate performs what is known as logical negation, which means that if its input is true, decision this making. Six of the logic gates used the output of this gate is true when any of its the output of this gate is false if one or more of inputs are true. If all the inputs are false, the an AND gate's inputs are false. Otherwise, if then the output will be false. Likewise, are: the OR gate, AND gate, NOT gate, XOR gate, output of the gate will also be false. -
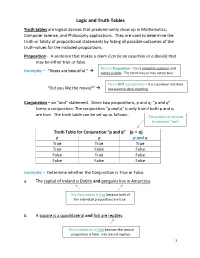
Logic and Truth Tables Truth Tables Are Logical Devices That Predominantly Show up in Mathematics, Computer Science, and Philosophy Applications
Logic and Truth Tables Truth tables are logical devices that predominantly show up in Mathematics, Computer Science, and Philosophy applications. They are used to determine the truth or falsity of propositional statements by listing all possible outcomes of the truth-values for the included propositions. Proposition - A sentence that makes a claim (can be an assertion or a denial) that may be either true or false. This is a Proposition – It is a complete sentence and Examples – “Roses are beautiful.” makes a claim. The claim may or may not be true. This is NOT a proposition – It is a question and does “Did you like the movie?” not assert or deny anything. Conjunction – an “and” statement. Given two propositions, p and q, “p and q” forms a conjunction. The conjunction “p and q” is only true if both p and q are true. The truth table can be set up as follows… This symbol can be used to represent “and”. Truth Table for Conjunction “p and q” (p ˄ q) p q p and q True True True True False False False True False False False False Examples – Determine whether the Conjunction is True or False. a. The capital of Ireland is Dublin and penguins live in Antarctica. This Conjunction is True because both of the individual propositions are true. b. A square is a quadrilateral and fish are reptiles. This Conjunction is False because the second proposition is false. Fish are not reptiles. 1 Disjunction – an “or” statement. Given two propositions, p and q, “p or q” forms a disjunction. -

'Chapter ~ Irltr&I'uctf Yoll'to'the Use of Boblean Cilgebra"And
/ . '. " . .... -: ... '; , " . ! :. " This chapter explores Boolean Algebra and the logic gateS used 3.0 INTRODUCTION to implement Boolean equations. Boolean Algebra is an area of mathematiciinvolVing ' opetations' ontwo-state «true-false) variAbles. "'thls 'type' df 'algebra .' was first formulated by the Eng~h Mathefnafidah 'GeorgeBoolein 1854. ' Boolean" Algebra is based· on the assUII\ptionthat any proposition can be proven with correct answers' to a specific ntlmber Of ·, tnie-false "" qu~t16ns . " Further~ Boolean algebra " provides a means ;whereby true-faIselogic can be 'handled in the form' ofAlgJbralC"eQuationS With the' qUeStioriSas independent variables and the conciu51on Yexpressed as a ' dependent variable (recall that in'" the' equationl" y ' :; A+Bthat A and B are independent vimables and 'Y ' is ' a dependent' variable). This 'chapter ~ irltr&i'uctf YOll 'to'the use of Boblean Cilgebra "and the use of electroruc logic gateS (citcuits) to implement Boolean . ~ ~ equations. ' 21 ., Upon completion of this chapter you should be able to: :' ~~i ' ,- .:. ~. ; ~' : ,;i . >. ~~; . ~~).~( . .'} '.. • Explain the basic operations of Boolean Algebra. , " . : ;:/~ ' .' . ' ,l . •1 . · !• .·i I' f ' ,;,:~ ~ ; •...wr\~~ ~lean~ua.tiol\$~ , " 4' , '. ~ ,' . .~- ',~ : , • .. , .. ~ ' ~ ' . f<-:-; '. ' ~ , ,' ~ 'use logic cirCuits t() implement Boolean equations. _ .;( " '.i;~ ..... ( , -. ~ 'f~>. 3.2DISCtJSSIO.N ',.Boolean algebra is the :. lmn~of mathematics which studies operations ontW~tate variables. For the purposes of this book, an algebra is a system of mathematics where the operations of addition and multiplication can be performed with the results of the operation remaining within the system. In Boolean algebra, addition and multiplication' are the only binary (two-variable) operations which are defined. These two operations also may be performed on more than two independent variables. -

2 Ch 2: LOGIC
2 Ch 2: LOGIC 2.1 Statements A statement is a sentence that is either true or false, but not both. Ex 1: Today is Monday. Ex 2: The integer 3 is even. Not examples: The equation 3x = 12. This is not a statement b/c it depends on the value of x. There is one value that makes it true, but the sentence is not always true. Every statement has a truth value, namely true T or false F. A sentence containing a variable(s) is called an open sentence. Ex: The integer r is even. Possible truth values are often given in a table called a truth table. Examples: P Truth table for a sentence P: T F P Q T T Truth table for two sentences P and Q: T F F T F F Thus two statements will give us 22 combinations (rows below the one with P and Q) in the table. For three statements we would get 23 combinations, since there are two choices for each of the three statement(either T or F). 2.2 The Negation of a statement The negation of a statement P is the statement ∼ P : not P . Ex: P : 3 is even. ∼ P : 3 is not even. OR: ∼ P : 3 is odd. Observe that when the statement is false, its negation is true. P ∼ P Truth table for sentence ∼ P : T F F T 2.3 The Disjunction and Conjunction of a Statement For two statements P and Q, the disjunction of P and Q is P ∨ Q (P or Q). -

Part 2 Module 1 Logic: Statements, Negations, Quantifiers, Truth Tables
PART 2 MODULE 1 LOGIC: STATEMENTS, NEGATIONS, QUANTIFIERS, TRUTH TABLES STATEMENTS A statement is a declarative sentence having truth value. Examples of statements: Today is Saturday. Today I have math class. 1 + 1 = 2 3 < 1 What's your sign? Some cats have fleas. All lawyers are dishonest. Today I have math class and today is Saturday. 1 + 1 = 2 or 3 < 1 For each of the sentences listed above (except the one that is stricken out) you should be able to determine its truth value (that is, you should be able to decide whether the statement is TRUE or FALSE). Questions and commands are not statements. SYMBOLS FOR STATEMENTS It is conventional to use lower case letters such as p, q, r, s to represent logic statements. Referring to the statements listed above, let p: Today is Saturday. q: Today I have math class. r: 1 + 1 = 2 s: 3 < 1 u: Some cats have fleas. v: All lawyers are dishonest. Note: In our discussion of logic, when we encounter a subjective or value-laden term (an opinion) such as "dishonest," we will assume for the sake of the discussion that that term has been precisely defined. QUANTIFIED STATEMENTS The words "all" "some" and "none" are examples of quantifiers. A statement containing one or more of these words is a quantified statement. Note: the word "some" means "at least one." EXAMPLE 2.1.1 According to your everyday experience, decide whether each statement is true or false: 1. All dogs are poodles. 2. Some books have hard covers. 3. -

On the Psychology of Truth-Gaps*
On the Psychology of Truth-Gaps Sam Alxatib1 and Jeff Pelletier2 1 Massachusetts Institute of Technology 2 University of Alberta Abstract. Bonini et al. [2] present psychological data that they take to support an ‘epistemic’ account of how vague predicates are used in natural language. We argue that their data more strongly supports a ‘gap’ theory of vagueness, and that their arguments against gap theories are flawed. Additionally, we present more experimental evidence that supports gap theories, and argue for a semantic/pragmatic alternative that unifies super- and subvaluationary approaches to vagueness. 1 Introduction A fundamental rule in any conservative system of deduction is the rule of ∧- Elimination. The rule, as is known, authorizes a proof of a proposition p from a premise in which p is conjoined with some other proposition q, including the case p ∧¬p,wherep is conjoined with its negation. In this case, i.e. when the conjunction of interest is contradictory, ∧-elimination provides the first of a series of steps that ultimately lead to the inference of q, for any arbitrary proposition q. In the logical literature, this is often referred to as the Principle of Explosion: (1) p ∧¬p (Assumption) (2) p (1, ∧-Elimination) (3) ¬p (1, ∧-Elimination) (4) p ∨ q (2, ∨-Introduction) (5) q (3, 4, Disjunctive Syllogism) Proponents of dialetheism view the ‘explosive’ property of these deductive sys- tems as a deficiency, arguing that logics ought instead to be formulated in a way that preserves contradictory statements without leading to arbitrary con- clusions. One such formulation is Jaśkowski’s DL [8], an axiomatic system that is adopted as a logic for vagueness by Hyde [7]. -

Truth Tables for Negation, Conjunction, and Disjunction
3.2 Truth Tables for Negation, Conjunction, and Disjunction Copyright © 2005 Pearson Education, Inc. Truth Table A truth table is used to determine when a compound statement is true or false. Copyright © 2005 Pearson Education, Inc. Slide 3-2 Conjunction Truth Table Click on speaker for audio The symbol ^ is read as “and” p q pq∧ Case 1 T T T Case 2 T F F Case 3 F T F Case 4 F F F The conjunction is true only when both p and q are true. Copyright © 2005 Pearson Education, Inc. Slide 3-3 Disjunction Click on speaker for audio The symbol V is read as “or” p q p ∨ q Case 1 T T T Case 2 T F T Case 3 F T T Case 4 F F F The disjunction is true when either p is true,qis true, or both p and q are true. Copyright © 2005 Pearson Education, Inc. Slide 3-4 Making a truth table Let’s construct a truth table for p v ~q. This is read as “p or not q”. Step 1: Make a table with different possibilities for p and q .There are 4 different possibilities. p q Case 1 T T Case 2 T F Case 3 F T Case 4 F F Copyright © 2005 Pearson Education, Inc. Slide 3-5 Making a truth table (cont’d) Click on speaker for audio Step 2: Now, make a column for ~q (“not” q) since we want to ultimately find p v ~q p q ~q Case 1 T T F Case 2 T F T Case 3 F T F Case 4 F F T Copyright © 2005 Pearson Education, Inc. -

Some Remarks on the Validity of the Principle of Explosion in Intuitionistic Logic1
Some remarks on the validity of the principle of explosion in intuitionistic logic1 Edgar Campos2 & Abilio Rodrigues3 Abstract The formal system proposed by Heyting (1930, 1936) became the stan- dard formulation of intuitionistic logic. The inference called ex falso quodlibet, or principle of explosion, according to which anything follows from a contradiction, holds in intuitionistic logic. However, it is not clear that explosion is in accordance with Brouwer’s views on the nature of mathematics and its relationship with logic. Indeed, van Atten (2009) argues that a formal system in line with Brouwer’s ideas should be a relevance logic. We agree that explosion should not hold in intuitionistic logic, but a relevance logic requires more than the invalidity of explosion. The principle known as ex quodlibet verum, according to which a valid formula follows from anything, should also be rejected by a relevantist. Given ex quodlibet verum, the inference we call weak explosion, accord- ing to which any negated proposition follows from a contradiction, is proved in a few steps. Although the same argument against explosion can be also applied against weak explosion, rejecting the latter requires the rejection of ex quodlibet verum. The result is the loss of at least one among reflexivity, monotonicity, and the deduction theorem in a Brouwerian intuitionistic logic, which seems to be an undesirable result. 1. Introduction: Brouwer on mathematics and logic The main divergence between Brouwer and the standard approach to mathematics, based on classical logic, is his understanding of the notions of existence and truth as applied to mathematics. According to Brouwer, “to exist in mathematics means: to be constructed by intuition” (Brouwer, 1907, p.