Um Recomendador De Aplicativos GNU/Linux Tássia Cam
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Building a Scalable Index and a Web Search Engine for Music on the Internet Using Open Source Software
Department of Information Science and Technology Building a Scalable Index and a Web Search Engine for Music on the Internet using Open Source software André Parreira Ricardo Thesis submitted in partial fulfillment of the requirements for the degree of Master in Computer Science and Business Management Advisor: Professor Carlos Serrão, Assistant Professor, ISCTE-IUL September, 2010 Acknowledgments I should say that I feel grateful for doing a thesis linked to music, an art which I love and esteem so much. Therefore, I would like to take a moment to thank all the persons who made my accomplishment possible and hence this is also part of their deed too. To my family, first for having instigated in me the curiosity to read, to know, to think and go further. And secondly for allowing me to continue my studies, providing the environment and the financial means to make it possible. To my classmate André Guerreiro, I would like to thank the invaluable brainstorming, the patience and the help through our college years. To my friend Isabel Silva, who gave me a precious help in the final revision of this document. Everyone in ADETTI-IUL for the time and the attention they gave me. Especially the people over Caixa Mágica, because I truly value the expertise transmitted, which was useful to my thesis and I am sure will also help me during my professional course. To my teacher and MSc. advisor, Professor Carlos Serrão, for embracing my will to master in this area and for being always available to help me when I needed some advice. -

Improved Methods for Mining Software Repositories to Detect Evolutionary Couplings
IMPROVED METHODS FOR MINING SOFTWARE REPOSITORIES TO DETECT EVOLUTIONARY COUPLINGS A dissertation submitted to Kent State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy by Abdulkareem Alali August, 2014 Dissertation written by Abdulkareem Alali B.S., Yarmouk University, USA, 2002 M.S., Kent State University, USA, 2008 Ph.D., Kent State University, USA, 2014 Approved by Dr. Jonathan I. Maletic Chair, Doctoral Dissertation Committee Dr. Feodor F. Dragan Members, Doctoral Dissertation Committee Dr. Hassan Peyravi Dr. Michael L. Collard Dr. Joseph Ortiz Dr. Declan Keane Accepted by Dr. Javed Khan Chair, Department of Computer Science Dr. James Blank Dean, College of Arts and Sciences ii TABLE OF CONTENTS TABLE OF CONTENTS ............................................................................................... III LIST OF FIGURES ..................................................................................................... VIII LIST OF TABLES ....................................................................................................... XIII ACKNOWLEDGEMENTS ..........................................................................................XX CHAPTER 1 INTRODUCTION ................................................................................... 22 1.1 Motivation and Problem .......................................................................................... 24 1.2 Research Overview ................................................................................................ -

NYC*BUG in Perspective
Tens Years of NYC*BUG in Perspective versioning ● 10 years is actually December/January ● aimed at a broader audience than just people here ● start an UG? ● “organizational” angle THIS IS A DOT RELEASE my perspective ● I'm not the only one ● many other significant players ● my role exaggerated ● the “philosophical” one ● difficult talk: 10 years I posit that ● We're not the best thing since sliced bread ● We're just a user group But... ● Much significant impact, in NYC and beyond ● The community is better to have us ● Would be better if there were more like us I posit that ● We're not the best thing since sliced bread ● We're just a user group But... ● Much significant impact, in NYC and beyond ● The community is better to have us ● Would be better if there were more like us What Was Clear ● No to “Hobbyism” ● No to “Professionalism” ● No to “Sales” (Apple 2004 meeting) ● Neither a software project nor technical meritocracy ● Free, open, loose ● Needed LOTS of planning (mailing list stats) ● Viewed ourselves as part of a wider community, whether they liked it or not ● People + Technology = success For instance... http://mail-index.netbsd.org/regional-nyc/2004/01/13/0003.html Subject: Re: NYCBUG To: None <[email protected]> From: Michael Shalayeff <[email protected]> List: regional-nyc Date: 01/13/2004 12:51:01 Making, drinking tea and reading an opus magnum from Andrew Brown: > > http://lists.freebsd.org/pipermail/freebsd-advocacy/2004- January/000873.html > > i wonder if beer is involved...there's no mention of it in that posting. -

The GNU General Public License (GPL) Does Govern All Other Use of the Material That Constitutes the Autoconf Macro
Notice About this document The following copyright statements and licenses apply to software components that are distributed with various versions of the StorageGRID PreGRID Environment products. Your product does not necessarily use all the software components referred to below. Where required, source code is published at the following location: ftp://ftp.netapp.com/frm-ntap/opensource/ 215-10078_A0_ur001-Copyright 2015 NetApp, Inc. All rights reserved. 1 Notice Copyrights and licenses The following component is subject to the BSD 1.0 • Free BSD - 44_lite BSD 1.0 Copyright (c) 1982, 1986, 1990, 1991, 1993 The Regents of the University of California. All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. • All advertising materials mentioning features or use of this software must display the following acknowledgement: This product includes software developed by the University of California, Berkeley and its contributors. • Neither the name of the University nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. -

Pipenightdreams Osgcal-Doc Mumudvb Mpg123-Alsa Tbb
pipenightdreams osgcal-doc mumudvb mpg123-alsa tbb-examples libgammu4-dbg gcc-4.1-doc snort-rules-default davical cutmp3 libevolution5.0-cil aspell-am python-gobject-doc openoffice.org-l10n-mn libc6-xen xserver-xorg trophy-data t38modem pioneers-console libnb-platform10-java libgtkglext1-ruby libboost-wave1.39-dev drgenius bfbtester libchromexvmcpro1 isdnutils-xtools ubuntuone-client openoffice.org2-math openoffice.org-l10n-lt lsb-cxx-ia32 kdeartwork-emoticons-kde4 wmpuzzle trafshow python-plplot lx-gdb link-monitor-applet libscm-dev liblog-agent-logger-perl libccrtp-doc libclass-throwable-perl kde-i18n-csb jack-jconv hamradio-menus coinor-libvol-doc msx-emulator bitbake nabi language-pack-gnome-zh libpaperg popularity-contest xracer-tools xfont-nexus opendrim-lmp-baseserver libvorbisfile-ruby liblinebreak-doc libgfcui-2.0-0c2a-dbg libblacs-mpi-dev dict-freedict-spa-eng blender-ogrexml aspell-da x11-apps openoffice.org-l10n-lv openoffice.org-l10n-nl pnmtopng libodbcinstq1 libhsqldb-java-doc libmono-addins-gui0.2-cil sg3-utils linux-backports-modules-alsa-2.6.31-19-generic yorick-yeti-gsl python-pymssql plasma-widget-cpuload mcpp gpsim-lcd cl-csv libhtml-clean-perl asterisk-dbg apt-dater-dbg libgnome-mag1-dev language-pack-gnome-yo python-crypto svn-autoreleasedeb sugar-terminal-activity mii-diag maria-doc libplexus-component-api-java-doc libhugs-hgl-bundled libchipcard-libgwenhywfar47-plugins libghc6-random-dev freefem3d ezmlm cakephp-scripts aspell-ar ara-byte not+sparc openoffice.org-l10n-nn linux-backports-modules-karmic-generic-pae -

Rotterdam Werkt!; Improving Interorganizational Mobility Through Centralizing Vacancies and Resumes
Rotterdam Werkt!; Improving interorganizational mobility through centralizing vacancies and resumes Authors L.E. van Hal H.A.B. Janse D.R. den Ouden R.H. Piepenbrink C.S. Willekens Rotterdam Werkt! Improving interorganizational mobility through centralizing vacancies and resumes To obtain the degree of Bachelor of Science at the Delft University of Technology, to be presented and defended publicly on Friday January 29, 2021 at 14:30 AM. Authors: L.E. van Hal H.A.B. Janse D.R. den Ouden R.H. Piepenbrink C.S. Willekens Project duration: November 9, 2020 – January 29, 2021 Guiding Committee: H. Bolk Rotterdam Werkt!, Client R. Rotmans, Rotterdam Werkt!, Client Dr. C. Hauff, TU Delft, Coach Ir. T.A.R. Overklift Vaupel Klein TU Delft, Bachelor Project Coordinator An electronic version of this thesis is available at http://repository.tudelft.nl/. Preface This report denotes the end of the bachelor in Computer Science and Engineering at the Delft University of Technology. The report demonstrates all the skills we have learned during the bachelor courses in order to be a successful computer scientist or engineer. It will discuss the product we created over the past 10 weeks and will touch upon the skills and knowledge used in order to create it. Our client, Rotterdam Werkt!, is a network of companies located in Rotterdam who are aiming to increase mobility between their organizations. The goal of this report is to inform the reader about the complete work, different phases of this projects and future recommendations for our client. ii Summary Rotterdam Werkt! is a network of fourteen organizations in the Rotterdam area in the Netherlands. -
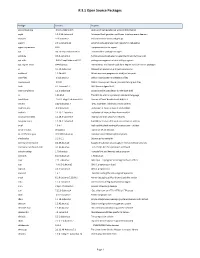
R 3.1 Open Source Packages
R 3.1 Open Source Packages Package Version Purpose accountsservice 0.6.15-2ubuntu9.3 query and manipulate user account information acpid 1:2.0.10-1ubuntu3 Advanced Configuration and Power Interface event daemon adduser 3.113ubuntu2 add and remove users and groups apport 2.0.1-0ubuntu12 automatically generate crash reports for debugging apport-symptoms 0.16 symptom scripts for apport apt 0.8.16~exp12ubuntu10.27 commandline package manager aptitude 0.6.6-1ubuntu1 Terminal-based package manager (terminal interface only) apt-utils 0.8.16~exp12ubuntu10.27 package managment related utility programs apt-xapian-index 0.44ubuntu5 maintenance and search tools for a Xapian index of Debian packages at 3.1.13-1ubuntu1 Delayed job execution and batch processing authbind 1.2.0build3 Allows non-root programs to bind() to low ports base-files 6.5ubuntu6.2 Debian base system miscellaneous files base-passwd 3.5.24 Debian base system master password and group files bash 4.2-2ubuntu2.6 GNU Bourne Again Shell bash-completion 1:1.3-1ubuntu8 programmable completion for the bash shell bc 1.06.95-2 The GNU bc arbitrary precision calculator language bind9-host 1:9.8.1.dfsg.P1-4ubuntu0.16 Version of 'host' bundled with BIND 9.X binutils 2.22-6ubuntu1.4 GNU assembler, linker and binary utilities bsdmainutils 8.2.3ubuntu1 collection of more utilities from FreeBSD bsdutils 1:2.20.1-1ubuntu3 collection of more utilities from FreeBSD busybox-initramfs 1:1.18.5-1ubuntu4 Standalone shell setup for initramfs busybox-static 1:1.18.5-1ubuntu4 Standalone rescue shell with tons of built-in utilities bzip2 1.0.6-1 High-quality block-sorting file compressor - utilities ca-certificates 20111211 Common CA certificates ca-certificates-java 20110912ubuntu6 Common CA certificates (JKS keystore) checkpolicy 2.1.0-1.1 SELinux policy compiler command-not-found 0.2.46ubuntu6 Suggest installation of packages in interactive bash sessions command-not-found-data 0.2.46ubuntu6 Set of data files for command-not-found. -
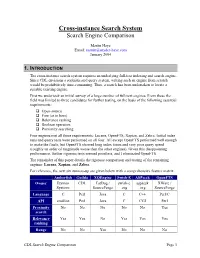
Cross-Instance Search System Search Engine Comparison
Cross-instance Search System Search Engine Comparison Martin Haye Email: [email protected] January 2004 1. INTRODUCTION The cross-instance search system requires an underlying full-text indexing and search engine. Since CDL envisions a sophisticated query system, writing such an engine from scratch would be prohibitively time-consuming. Thus, a search has been undertaken to locate a suitable existing engine. First we undertook an initial survey of a large number of full-text engines. From these the field was limited to three candidates for further testing, on the basis of the following essential requirements: q Open-source q Free (as in beer) q Relevance ranking q Boolean operators q Proximity searching Four engines met all these requirements: Lucene, OpenFTS, Xapian, and Zebra. Initial index runs and query tests were performed on all four. All except OpenFTS performed well enough to make the finals, but OpenFTS showed long index times and very poor query speed (roughly an order of magnitude worse than the other engines). Given this disappointing performance, further rigorous tests seemed pointless, and I eliminated OpenFTS. The remainder of this paper details the rigorous comparison and testing of the remaining engines: Lucene, Xapian, and Zebra. For reference, the next six runners-up are given below with a comprehensive feature matrix. Amberfish Guilda XQEngine Swish-E ASPseek OpenFTS Owner Etymon CDL FatDog / swish-e aspseek XWare / Systems SourceForge .org .org SourceForge Language C Perl Java C C++ Perl/C API cmdline Perl Java C CGI Perl Proximity No No No No No Yes search Relevance Yes Yes No Yes Yes Yes ranking Range No No Yes No No No CDL Search Engine Comparison Page 1 operators UNICODE No Maybe Yes No Yes Partial Wildcards No Yes No Yes Yes No Fuzzy No No No Yes No No search Arbitrary No Yes Yes No Partial Yes fields 2. -

Mod Wsgi Documentation Release 4.9.0
mod_wsgi Documentation Release 4.9.0 Graham Dumpleton Aug 03, 2021 Contents 1 Project Status 3 2 Security Issues 5 3 Getting Started 7 4 Requirements 9 5 Installation 11 6 Troubleshooting 13 7 User Guides 15 8 Configuration 133 9 Finding Help 159 10 Reporting Bugs 161 11 Contributing 163 12 Source Code 167 13 Release Notes 169 i ii mod_wsgi Documentation, Release 4.9.0 The mod_wsgi package implements a simple to use Apache module which can host any Python web application which supports the Python WSGI specification. The package can be installed in two different ways depending on your requirements. The first is as a traditional Apache module installed into an existing Apache installation. Following this path you will need to manually configure Apache to load mod_wsgi and pass through web requests to your WSGI application. The second way of installing mod_wsgi is to install it from PyPI using the Python pip command. This builds and installs mod_wsgi into your Python installation or virtual environment. The program mod_wsgi-express will then be available, allowing you to run up Apache with mod_wsgi from the command line with an automatically generated configuration. This approach does not require you to perform any configuration of Apache yourself. Both installation types are suitable for production deployments. The latter approach using mod_wsgi-express is the best solution if wishing to use Apache and mod_wsgi within a Docker container to host your WSGI application. It is also a better choice when using mod_wsgi during the development of your Python web application as you will be able to run it directly from your terminal. -

Recoll/Xapian - E Ziente Dokumenten- / Desktopsuche
Recoll/Xapian - eziente Dokumenten- / Desktopsuche Michael Schwipps 26. Januar 2016 Michael Schwipps Recoll/Xapian - eziente Dokumenten- / Desktopsuche Übersicht I Recoll ist ein Google für zu hause I Motivation / Warum? I Features I Erweiterungsmöglichkeiten und Grenzen Michael Schwipps Recoll/Xapian - eziente Dokumenten- / Desktopsuche Motivation, Eigenschaften klassischer Unix-Tools I Unix-Tool: Xgrep, ctags, cscope I zuverlässig, stabil, sicher, schnell aber I nur textbasierte Dateiformate, keine Binärformate I RegEx, boolesche Verknüpfung über etwas Shell-Magie I sehr gute Vim-Integration Michael Schwipps Recoll/Xapian - eziente Dokumenten- / Desktopsuche Recoll I Unterstützt direkt die üblichen Dokumenten- und Containerformate I Container multilevel, z.B. tgz in Email I boolesche Ausdrücke in der üblichen Suchmaschinen-Notation, Wildcard* I die Textextraktion erfolgt mit Linux-Standardtools(z.B. pdftotext) I leicht erweiterbar I fuzzy-Suche, mehrsprachiges Stemming während der Suche (z.B. deutsch und englisch), Stammformbildung: iegen, iege, og I Priorisierung/Ranking I aspell-basiertes Meinten Sie-Feature / Anti-Tippfehlervorschlag Michael Schwipps Recoll/Xapian - eziente Dokumenten- / Desktopsuche Recoll 2, Xapian I gibt's fertig als CLI-Tool und X-Programm I Integration in Web-Tools (z.B. MediaWiki, redmine) häug leicht durch fertig Plugins möglich I Datenbank-Indizierung via Sprachintegration python, php I Indizierungstrigger erfolgt über expliziten Aufruf (z.B. cronjob) oder via FAM/inotify I Xapian ist das Speicher-Backend -

ALEXA-Seq Linux Installation Manual (V.1.15)
ALEXA-Seq (www.AlexaPlatform.org) Linux Installation Manual (v.1.15) 14 January 2011 1 Table of Contents Introduction ...............................................................................................................................................3 Preamble.................................................................................................................................................3 Prerequisites .........................................................................................................................................3 Notes .......................................................................................................................................................3 A. Performing the ALEXA-Seq analysis.............................................................................................4 0. Installing Alexa-seq code base....................................................................................................4 1. Installing R.........................................................................................................................................4 2. Installing R packages and BioConductor R libraries.............................................................5 3. Installing BLAST, BWA and mdust .............................................................................................5 BLAST .................................................................................................................................................5 BWA.....................................................................................................................................................5 -

Elementary Setup of a Chamilo Server for Intranet Usage (Version 1.9.X) Table of Contents
Elementary setup of a Chamilo server for intranet usage (version 1.9.x) Table of contents Introduction Chapter 1: installation of Debian Chapter 2: connecting remote Chapter 3: installing basic packages Chapter 4: Chamilo RAPID/PowerPoint converter Chapter 5: Xapian Chapter 6: Prepare the system Chapter 7: Getting Chamilo source Chapter 8: Installing Chamilo via web browser Appendix: document license & version history Introduction This setup guide is neither complete nor does it claim to be the fastest solution available. (indeed, if you really need a fast running server, I would recommend nginx) Also, you will not have video conference, because it is better to run that on a dedicated server. But it shows a good way to create a stable server for running Chamilo :-) What do you need: • server hardware capable of running Debian or something similar like Virtualbox or VMware • Debian installation cd/image (get one free at http://www.debian.org/CD/ ) • elementary knowledge of network design (otherwise you have an admin which will tell you the needed information) • knowledge how to connect to a server via ssh • at least 3 hours of time :-) Let's start with the basics: 1. setup Debian (including network basics) 2. installing additional software 3. do the funny compiling of Xapian (which hopefully will be discontinued in the future) 4. configuring services the Debian way 5. get mail server running (you should definitely change this to your needs!) 6. do some basic server security (at least the basic things) 7. setup an elementary backup solution (depends on if you can afford space) 8.