Improved Methods for Mining Software Repositories to Detect Evolutionary Couplings
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Building a Scalable Index and a Web Search Engine for Music on the Internet Using Open Source Software
Department of Information Science and Technology Building a Scalable Index and a Web Search Engine for Music on the Internet using Open Source software André Parreira Ricardo Thesis submitted in partial fulfillment of the requirements for the degree of Master in Computer Science and Business Management Advisor: Professor Carlos Serrão, Assistant Professor, ISCTE-IUL September, 2010 Acknowledgments I should say that I feel grateful for doing a thesis linked to music, an art which I love and esteem so much. Therefore, I would like to take a moment to thank all the persons who made my accomplishment possible and hence this is also part of their deed too. To my family, first for having instigated in me the curiosity to read, to know, to think and go further. And secondly for allowing me to continue my studies, providing the environment and the financial means to make it possible. To my classmate André Guerreiro, I would like to thank the invaluable brainstorming, the patience and the help through our college years. To my friend Isabel Silva, who gave me a precious help in the final revision of this document. Everyone in ADETTI-IUL for the time and the attention they gave me. Especially the people over Caixa Mágica, because I truly value the expertise transmitted, which was useful to my thesis and I am sure will also help me during my professional course. To my teacher and MSc. advisor, Professor Carlos Serrão, for embracing my will to master in this area and for being always available to help me when I needed some advice. -

The 3Ourn L of AUUG Inc. Volume 25 ¯ Number 4 December 2004
The 3ourn l of AUUG Inc. Volume 25 ¯ Number 4 December 2004 Features: A Convert to the Fold 7 Lions Commentary, part 1 16 News: Minutes of AUUG Annual General Meeting, 1 September 2004 54 AUUG 2005 annual conference: CFP 58 First Australian UNIX Developer’s Symposium: CFP 59 First Digital Pest Symposium 60 Regulars: Editorial 1 President’s Column 3 My Home Network 4 This Issue’s CD 29 The Future of AUUG CDs 30 A Hacker’s Diary 31 AUUG Corporate Members 56 Letters to AUUG 56 About AUUGN 61 Chapter Meetings and Contact Details 62 AUUG Membership Application Form 63 ISSN 1035-7521 Print post approved by Australia Post - PP2391500002 AUUGN The journal of AUUG Inc. Volume 25, Number 3 September 2004 Editor ial Frank Crawford <[email protected]> Well, after many, many years of involvement with mittee, preparing each edition. Curr ently, this AUUGN, I’ve finally been roped into writing the consists of Greg Lehey and myself, but we are editorial. In fact, AUUGN has a very long and keen to expand this by a few more, in an effort to distinguished history, providing important infor- spr ead the load. And as with previous changes, mation to generations of Unix users. During that we have a “new” approach to finding contribu- time, therehave been a range of editors all of tions. AUUG has a huge body of work, from whom have guided it through ups and downs. both the Annual Conference and regional meet- Certainly you will know many of the recent ones, ings that should be seen morewidely, especially such as David Purdue (current AUUG President), by those who weren't able to attend these events. -

NYC*BUG in Perspective
Tens Years of NYC*BUG in Perspective versioning ● 10 years is actually December/January ● aimed at a broader audience than just people here ● start an UG? ● “organizational” angle THIS IS A DOT RELEASE my perspective ● I'm not the only one ● many other significant players ● my role exaggerated ● the “philosophical” one ● difficult talk: 10 years I posit that ● We're not the best thing since sliced bread ● We're just a user group But... ● Much significant impact, in NYC and beyond ● The community is better to have us ● Would be better if there were more like us I posit that ● We're not the best thing since sliced bread ● We're just a user group But... ● Much significant impact, in NYC and beyond ● The community is better to have us ● Would be better if there were more like us What Was Clear ● No to “Hobbyism” ● No to “Professionalism” ● No to “Sales” (Apple 2004 meeting) ● Neither a software project nor technical meritocracy ● Free, open, loose ● Needed LOTS of planning (mailing list stats) ● Viewed ourselves as part of a wider community, whether they liked it or not ● People + Technology = success For instance... http://mail-index.netbsd.org/regional-nyc/2004/01/13/0003.html Subject: Re: NYCBUG To: None <[email protected]> From: Michael Shalayeff <[email protected]> List: regional-nyc Date: 01/13/2004 12:51:01 Making, drinking tea and reading an opus magnum from Andrew Brown: > > http://lists.freebsd.org/pipermail/freebsd-advocacy/2004- January/000873.html > > i wonder if beer is involved...there's no mention of it in that posting. -

The GNU General Public License (GPL) Does Govern All Other Use of the Material That Constitutes the Autoconf Macro
Notice About this document The following copyright statements and licenses apply to software components that are distributed with various versions of the StorageGRID PreGRID Environment products. Your product does not necessarily use all the software components referred to below. Where required, source code is published at the following location: ftp://ftp.netapp.com/frm-ntap/opensource/ 215-10078_A0_ur001-Copyright 2015 NetApp, Inc. All rights reserved. 1 Notice Copyrights and licenses The following component is subject to the BSD 1.0 • Free BSD - 44_lite BSD 1.0 Copyright (c) 1982, 1986, 1990, 1991, 1993 The Regents of the University of California. All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. • All advertising materials mentioning features or use of this software must display the following acknowledgement: This product includes software developed by the University of California, Berkeley and its contributors. • Neither the name of the University nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. -

Pipenightdreams Osgcal-Doc Mumudvb Mpg123-Alsa Tbb
pipenightdreams osgcal-doc mumudvb mpg123-alsa tbb-examples libgammu4-dbg gcc-4.1-doc snort-rules-default davical cutmp3 libevolution5.0-cil aspell-am python-gobject-doc openoffice.org-l10n-mn libc6-xen xserver-xorg trophy-data t38modem pioneers-console libnb-platform10-java libgtkglext1-ruby libboost-wave1.39-dev drgenius bfbtester libchromexvmcpro1 isdnutils-xtools ubuntuone-client openoffice.org2-math openoffice.org-l10n-lt lsb-cxx-ia32 kdeartwork-emoticons-kde4 wmpuzzle trafshow python-plplot lx-gdb link-monitor-applet libscm-dev liblog-agent-logger-perl libccrtp-doc libclass-throwable-perl kde-i18n-csb jack-jconv hamradio-menus coinor-libvol-doc msx-emulator bitbake nabi language-pack-gnome-zh libpaperg popularity-contest xracer-tools xfont-nexus opendrim-lmp-baseserver libvorbisfile-ruby liblinebreak-doc libgfcui-2.0-0c2a-dbg libblacs-mpi-dev dict-freedict-spa-eng blender-ogrexml aspell-da x11-apps openoffice.org-l10n-lv openoffice.org-l10n-nl pnmtopng libodbcinstq1 libhsqldb-java-doc libmono-addins-gui0.2-cil sg3-utils linux-backports-modules-alsa-2.6.31-19-generic yorick-yeti-gsl python-pymssql plasma-widget-cpuload mcpp gpsim-lcd cl-csv libhtml-clean-perl asterisk-dbg apt-dater-dbg libgnome-mag1-dev language-pack-gnome-yo python-crypto svn-autoreleasedeb sugar-terminal-activity mii-diag maria-doc libplexus-component-api-java-doc libhugs-hgl-bundled libchipcard-libgwenhywfar47-plugins libghc6-random-dev freefem3d ezmlm cakephp-scripts aspell-ar ara-byte not+sparc openoffice.org-l10n-nn linux-backports-modules-karmic-generic-pae -

Rotterdam Werkt!; Improving Interorganizational Mobility Through Centralizing Vacancies and Resumes
Rotterdam Werkt!; Improving interorganizational mobility through centralizing vacancies and resumes Authors L.E. van Hal H.A.B. Janse D.R. den Ouden R.H. Piepenbrink C.S. Willekens Rotterdam Werkt! Improving interorganizational mobility through centralizing vacancies and resumes To obtain the degree of Bachelor of Science at the Delft University of Technology, to be presented and defended publicly on Friday January 29, 2021 at 14:30 AM. Authors: L.E. van Hal H.A.B. Janse D.R. den Ouden R.H. Piepenbrink C.S. Willekens Project duration: November 9, 2020 – January 29, 2021 Guiding Committee: H. Bolk Rotterdam Werkt!, Client R. Rotmans, Rotterdam Werkt!, Client Dr. C. Hauff, TU Delft, Coach Ir. T.A.R. Overklift Vaupel Klein TU Delft, Bachelor Project Coordinator An electronic version of this thesis is available at http://repository.tudelft.nl/. Preface This report denotes the end of the bachelor in Computer Science and Engineering at the Delft University of Technology. The report demonstrates all the skills we have learned during the bachelor courses in order to be a successful computer scientist or engineer. It will discuss the product we created over the past 10 weeks and will touch upon the skills and knowledge used in order to create it. Our client, Rotterdam Werkt!, is a network of companies located in Rotterdam who are aiming to increase mobility between their organizations. The goal of this report is to inform the reader about the complete work, different phases of this projects and future recommendations for our client. ii Summary Rotterdam Werkt! is a network of fourteen organizations in the Rotterdam area in the Netherlands. -

Meta-Revelation-Ebook-Web.Pdf
©2015 Bil Holton All Rights Reserved The Book of Revelation, New Metaphysical Version text may be quoted and/or reprinted in any form [written, visual, electronic, or audio] up to and inclusive of one hundred twenty five [125] words without the express written permission of the publisher, providing notice of copyright appears on the title or copyright page of the work as follows: The Scriptural quotations contained herein are from The Book of Revelation, New Metaphysical Version. Copyright 2015 by Prosperity Publishing House. Used by permission. All rights reserved. When quotations from the NMV [New Metaphysical Version] are used in non-saleable media, such as church bulletins, transparencies, meditation/prayer readings, etc., a copyright notice is not required, but the initials NMV must appear at the end of each quotation. Quotations and/or reprints in excess of one hundred twenty-five [125] words, as well as other permission requests, including commercial use, must be approved in writing by the publisher: Permissions Office, Prosperity Publishing House, 1405 Autumn Ridge Drive, Durham, NC 27712. ISBN: 978-1-893095-88-5 Library of Congress Control Number: 2009914060 To Truth seekers and spiritual practitioners all over the world who want to consciously, energetically and faithfully align their human self with their Christ Self. Table of Contents Preface How to Read This Book . .3 Chapter One Introduction to Unfolding Our Innate Christ Nature . .5 The Alpha and Omega of Us . .7 The Seven Major Spiritual Energy Centers . .7 Our Christ Nature . .8 A Nascent Reminder . .9 Chapter Two A Quick Overview of Our Base Chakra . -

KDE E.V. Quarterly Report 2008Q1/Q2
KDE e.V. Quarterly Report Q1/2008 & Q2/2008 .init() home for KDE e.V. to call its own but a tremendous asset in Claudia who Dear KDE e.V. member, has rapidly made herself at home in our community providing much needed logistical support and business The first two quarters of 2008 were very busy ones for development effort while diving head-first into the KDE participants. Both the technology project and KDE e.V. community by joining our events and tradeshow teams. We were bustling with activity. are happy to welcome Claudia into our community and our team. The obvious stand-out moment was when KDE 4.0 was released at an immensely successful release event held in In short, the first half of 2008 was busy and full of pleasant Mountain View, California - where Google served as our surprises and achievements. KDE e.V. found ways to be hosts and numerous locations around the world tuned in more efficient and increase our pace to keep up with the to join us live over the Internet. Besides creating new technology project's own escalation. Looking forward to community bonds and bringing together developers from the second half of the year with Akademy 2008 just around various projects and companies in and outside of the KDE the corner, it's safe to say that things aren't about to slow project, it also spawned what will be an annual KDE down, either. Americas event at the beginning of each year. To our membership and partners: thank you for helping Work to ensure Akademy 2008 went off successfully was making the start of 2008 such a positive and productive also in high gear as KDE 4.1 was being readied for release. -

Picongpu Documentation Release 0.6.0-Dev
PIConGPU Documentation Release 0.6.0-dev The PIConGPU Community Sep 24, 2021 INSTALLATION 1 Installation 3 1.1 Introduction.............................................3 1.1.1 Ways to Install.......................................3 1.1.2 References.........................................4 1.2 Instructions..............................................4 1.2.1 Spack............................................4 1.2.2 Docker...........................................5 1.2.3 From Source........................................6 1.3 Dependencies.............................................8 1.3.1 Overview..........................................8 1.3.2 Requirements........................................8 1.4 picongpu.profile........................................... 15 1.4.1 Hemera (HZDR)...................................... 15 1.4.2 Summit (ORNL)...................................... 24 1.4.3 Piz Daint (CSCS)...................................... 25 1.4.4 Taurus (TU Dresden).................................... 27 1.4.5 Lawrencium (LBNL).................................... 34 1.4.6 Cori (NERSC)....................................... 35 1.4.7 Draco (MPCDF)...................................... 39 1.4.8 D.A.V.I.D.E (CINECA)................................... 40 1.4.9 JURECA (JSC)....................................... 42 1.4.10 JUWELS (JSC)....................................... 48 1.4.11 ARIS (GRNET)....................................... 53 1.4.12 Ascent (ORNL)....................................... 55 1.5 Changelog............................................. -
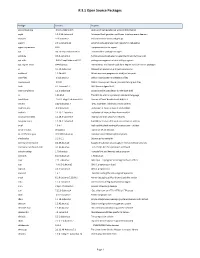
R 3.1 Open Source Packages
R 3.1 Open Source Packages Package Version Purpose accountsservice 0.6.15-2ubuntu9.3 query and manipulate user account information acpid 1:2.0.10-1ubuntu3 Advanced Configuration and Power Interface event daemon adduser 3.113ubuntu2 add and remove users and groups apport 2.0.1-0ubuntu12 automatically generate crash reports for debugging apport-symptoms 0.16 symptom scripts for apport apt 0.8.16~exp12ubuntu10.27 commandline package manager aptitude 0.6.6-1ubuntu1 Terminal-based package manager (terminal interface only) apt-utils 0.8.16~exp12ubuntu10.27 package managment related utility programs apt-xapian-index 0.44ubuntu5 maintenance and search tools for a Xapian index of Debian packages at 3.1.13-1ubuntu1 Delayed job execution and batch processing authbind 1.2.0build3 Allows non-root programs to bind() to low ports base-files 6.5ubuntu6.2 Debian base system miscellaneous files base-passwd 3.5.24 Debian base system master password and group files bash 4.2-2ubuntu2.6 GNU Bourne Again Shell bash-completion 1:1.3-1ubuntu8 programmable completion for the bash shell bc 1.06.95-2 The GNU bc arbitrary precision calculator language bind9-host 1:9.8.1.dfsg.P1-4ubuntu0.16 Version of 'host' bundled with BIND 9.X binutils 2.22-6ubuntu1.4 GNU assembler, linker and binary utilities bsdmainutils 8.2.3ubuntu1 collection of more utilities from FreeBSD bsdutils 1:2.20.1-1ubuntu3 collection of more utilities from FreeBSD busybox-initramfs 1:1.18.5-1ubuntu4 Standalone shell setup for initramfs busybox-static 1:1.18.5-1ubuntu4 Standalone rescue shell with tons of built-in utilities bzip2 1.0.6-1 High-quality block-sorting file compressor - utilities ca-certificates 20111211 Common CA certificates ca-certificates-java 20110912ubuntu6 Common CA certificates (JKS keystore) checkpolicy 2.1.0-1.1 SELinux policy compiler command-not-found 0.2.46ubuntu6 Suggest installation of packages in interactive bash sessions command-not-found-data 0.2.46ubuntu6 Set of data files for command-not-found. -

Glossary.Pdf
2 Contents 1 Glossary 4 3 1 Glossary Technologies Akonadi The data storage access mechanism for all PIM (Personal Information Manager) data in KDE SC 4. One single storage and retrieval system allows efficiency and extensibility not possible under KDE 3, where each PIM component had its own system. Note that use of Akonadi does not change data storage formats (vcard, iCalendar, mbox, maildir etc.) - it just provides a new way of accessing and updating the data.</p><p> The main reasons for design and development of Akonadi are of technical nature, e.g. having a unique way to ac- cess PIM-data (contacts, calendars, emails..) from different applications (e.g. KMail, KWord etc.), thus eliminating the need to write similar code here and there.</p><p> Another goal is to de-couple GUI applications like KMail from the direct access to external resources like mail-servers - which was a major reason for bug-reports/wishes with regard to perfor- mance/responsiveness in the past.</p><p> More info:</p><p> <a href=https://community.kde.org/KDE_PIM/Akonadi target=_top>Akonadi for KDE’s PIM</a></p><p> <a href=https://en.wikipedia.org/wiki/Akonadi target=_top>Wikipedia: Akonadi</a></p><p> <a href=https://techbase.kde.org/KDE_PIM/Akonadi target=_top>Techbase - Akonadi</a> See Also "GUI". See Also "KDE". Applications Applications are based on the core libraries projects by the KDE community, currently KDE Frameworks and previously KDE Platform.</p><p> More info:</p><p> <a href=https://community.kde.org/Promo/Guidance/Branding/Quick_Guide/ target=_top>KDE Branding</a> See Also "Plasma". -
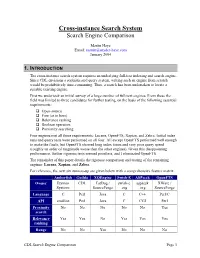
Cross-Instance Search System Search Engine Comparison
Cross-instance Search System Search Engine Comparison Martin Haye Email: [email protected] January 2004 1. INTRODUCTION The cross-instance search system requires an underlying full-text indexing and search engine. Since CDL envisions a sophisticated query system, writing such an engine from scratch would be prohibitively time-consuming. Thus, a search has been undertaken to locate a suitable existing engine. First we undertook an initial survey of a large number of full-text engines. From these the field was limited to three candidates for further testing, on the basis of the following essential requirements: q Open-source q Free (as in beer) q Relevance ranking q Boolean operators q Proximity searching Four engines met all these requirements: Lucene, OpenFTS, Xapian, and Zebra. Initial index runs and query tests were performed on all four. All except OpenFTS performed well enough to make the finals, but OpenFTS showed long index times and very poor query speed (roughly an order of magnitude worse than the other engines). Given this disappointing performance, further rigorous tests seemed pointless, and I eliminated OpenFTS. The remainder of this paper details the rigorous comparison and testing of the remaining engines: Lucene, Xapian, and Zebra. For reference, the next six runners-up are given below with a comprehensive feature matrix. Amberfish Guilda XQEngine Swish-E ASPseek OpenFTS Owner Etymon CDL FatDog / swish-e aspseek XWare / Systems SourceForge .org .org SourceForge Language C Perl Java C C++ Perl/C API cmdline Perl Java C CGI Perl Proximity No No No No No Yes search Relevance Yes Yes No Yes Yes Yes ranking Range No No Yes No No No CDL Search Engine Comparison Page 1 operators UNICODE No Maybe Yes No Yes Partial Wildcards No Yes No Yes Yes No Fuzzy No No No Yes No No search Arbitrary No Yes Yes No Partial Yes fields 2.