Efficient Javavm Just-In-Time Compilation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

David T. C~Ai9 736 Edgewater [M J Wichita, Kansas 67230 (USA)
_.., ,.i.'~...< ~~ ':' ..". PASCAL US~RS GROUP Pa.scal.N ews I.. NUMlsER ,< Iq COMMUNICATIONS ABOUT THE PROGRAMMING LANGUAGE PASCAL BVPASCALERS SE PT EMbER .,1980 ~,_v., j : ;,. ~ - EX LIBRIS: David T. C~ai9 736 Edgewater [M J Wichita, Kansas 67230 (USA) ' ... '-" .- . .. .,.- ... ., '-" -'. ..,. ...- .--'- -"--"'.". '. POLICY: PASCAL NEWS (15...Sep...80) * Pascal~ is the official but informal publication of the User's Group. * Pascal Newa contains all we (the editors) kriowabout Pascal; we use it as the vetlICIe to answer all inquiries because our physical energy and resources for answering individual requests are finite. As PUG grows, we unfortunately succumb to the reality of: 1. Having to insist that people ~o need to know "about Pascal" join PUG and read Pascal News - that is why we spend lime to produce, it! 2. Refusing to return phone calls or answer letters full of questions - we will pass the questions on to the readership of Pascal News. Please understand what the collective effect of individual inquirie8lias at the "concentrators" (our phones and mailboxes). We are trying honestly to say: "We cannot promise more that we can do." ' * Pascal News is produced 3 or4 times during a year; usually in March, June, September, and December. * ALL THE NEWS THAT'S FIT, WE PRINT .Please send material (brevity is a virtue) for Pascal News single-spaced and camera-ready (use dark ribbon and 18.5 em lines!) '. - ~ * Remember : ALL LETTERS TO US WILL BE PRINTED UNLESS THEY CONTAIN A REQUEST u TO THE CONTRARY. -.- * Pascal News is divided into flexible sections: o POLICY - explains the way we do things (ALL-PURPOSE COUPON, etc.) EDITOR'S CONTRIBUTION - passes along the opinion and point of view of the D. -

Ucsd-Psystem-Fs UCSD P-System Filesystem Reference Manual
ucsd-psystem-fs UCSD p-System Filesystem Reference Manual Peter Miller [email protected] . This document describes ucsd-psystem-fs version 1.22 and was prepared 21 July 2013. This document describing the ucsd-psystem-fs package, and the ucsd-psystem-fs utility pro- grams, are Copyright © 2006, 2007, 2008, 2010, 2011, 2012, 2013 Peter Miller This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3 of the License, or (at your option) anylater version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without eventhe implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICU- LAR PURPOSE. See the GNU General Public License for more details. Youshould have receivedacopyofthe GNU General Public License along with this program. If not, see <http://www.gnu.org/licenses/>. 0 Table of Contents(ucsd-psystem-fs) Table of Contents(ucsd-psystem-fs) The README file . ................. 1 Release Notes ................... 2 Howtobuild ucsd-psystem-fs .............. 6 ucsdpsys_disk(1) manipulate files on a UCSD p-System filesystem image ...... 10 ucsdpsys_fsck(1) verify and repair UCSD p-System filesystem images ....... 13 ucsdpsys_fs_license(1) GNU General Public License ............... 14 ucsdpsys_interleave(1) decode interleavedUCSD p-System filesystem image ....... 23 ucsdpsys_mkfs(1) create newUCSD p-System filesystem disk images ........ 25 ucsdpsys_mount(1) mount aUCSD p-System filesystem . ........... 27 ucsdpsys_rt11(1) extract files from RT-11 disk images ............ 29 ucsdpsys_text(1) translate UCSD p-System text files . ............ 30 ucsdpsys_umount(1) unmount UCSD p-System filesystems . -

Implementing the UCSD PASCAL System on the MODCOMP Computer
TDA Progress Report 42-60 September and October 1960 Implementing the UCSD PASCAL System on the MODCOMP Computer T. Wolfe DSN Data Systems Section This article describes the UCSD PASCAL system developed by the University of California, San Diego, now available on the MODCOMP computer. The system includes a Pascal compiler and many useful utility programs. A BASIC compiler and a FORTRAN 77 compiler are also avatkble. There is currently a large amount of software availabie written in UCSD PASCAL, including a data base system, word processing systems and a MODULA compiler. I. Introduction Assembly language subroutines thus produced may also be called from either Pascal or FORTRAN. Currently the assem- The UCSD PASCAL* System is a complete interactive bler has not been modified to produce MODCOMP machine software development system consisting of an operating sys- code. A system library program may be used to build libraries tem, compilers (Pascal, BASIC, FORTRAN 77) two text of useful subroutines and the system linker used to link them editors (screen editor and line-oriented editor), a linker and to user programs. many useful utility programs. The system is written and main- tained in Pascal. The compiler generates code for an idealized processor known as the “pseudo-machine.” The “pseudo- Interpreters currently exist for Z80/8080, PDP 11 /LSI-1 1, code” (p-code) generated by the compiler is interpreted at 6800, 9900 and 6502 computers and are being developed for runtime by a program (known as the interpreter) which emu- other computers. Thus, software could be developed on an lates the pseudo-machine. -

Oral History Interview with John Brackett and Doug Ross
An Interview with JOHN BRACKETT AND DOUG ROSS OH 392 Conducted by Mike Mahoney on 7 May 2004 Needham, Massachusetts Charles Babbage Institute Center for the History of Information Processing University of Minnesota, Minneapolis Copyright, Charles Babbage Institute John Brackett and Doug Ross Interview 7 May 2004 Oral History 392 Abstract Doug Ross and John Brackett focus on the background of SofTech and then its entry into the microcomputer software marketplace. They describe their original contact with the University of California at San Diego (UCSD) and licensing the p-System which had been developed there. They discuss the effort required to bring the program to production status and the difficulties in marketing it to the sets of customers. They talk about the transition from 8 bit to 16 bit machines and how that affected their market opportunities. They conclude with a review of the negotiations with IBM and their failure to get p-System to become a primary operating environment. That, and the high performance of Lotus 1-2-3, brought about the demise of the p- System. [John Brackett requested that the following information from Wikipedia, the free encyclopedia, be provided as an introduction to this oral history interview: “UCSD p-System or UCSD Pascal System was a portable, highly machine independent operating system based upon UCSD Pascal. The University of California, San Diego Institute for Information Systems developed it in 1978 to provide students with a common operating system that could run on any of the then available microcomputers as well as campus DEC PDP-11 minicomputers. UCSD p- System was one of three operating systems (along with PC-DOS and CP/M-86) that IBM offered for its original IBM PC. -

BULLETIN I of AVAILABLE TERAK SOFTWARE (Tugboats) the Terak User's Group Library Is a Clearing House Only; It Does Not Sell, Generate Or Test Prograns
Vol. 2, Issue 1 01·Jan.·82 BULLETIN i OF AVAILABLE TERAK SOFTWARE (Tugboats) The Terak User's Group Library Is a clearing house only; It does not sell, generate or test prograns. All prograns and information are provided "AS IS". Terak User's Group and contributors of software disclaim all warranties on the prograns, Including without I Imitation, all Impl led warranties of merchantabtl ity and fitness. The description, service charges, and ayallabll tty of software available for the Terak User's Group Library are subject to change without notice. Copyright (C) 1982, Terak User's Group; Scottsdale, Arizona DEC, DECUS, RT-l1, PDP-l1 are all trademarks of DIgItal EquIpment CorporatIon. UCSD Pascal Is a trademark of the UnIversIty of CalIfornIa Board of Regents. Terak Is a trademark of the Terak CorporatIon. TABLE OF CONTENTS PAGE TOflCS Introduction •••••••••••••••••••••••••••••••••••••••••••••••••••••••••• 1-1 TUGBOATS Updates •••••••••••••••••••••••••••••••••••••••••••••••••••••• 1-1 Ordering User Group Library Software •••••••••••••••••••••••••••••••••• 1-2 1. RT-ll Operating System •••••••••••••••••••••••••••••••••••••••••••••• 1-1 1.1 Languages •••••••••••••••••••••••••••••••••••••••••••••••••••••••• 1-1 1.2 Editors •••••••••••••••••••••••••••••••••••••••••••••••••••••••••• 1-2 1.3 Device Handlers •••••••••••••••••••••••••••••••••••••••••••••••••• 1-3 1.4 Statistical Routines ••••••••••••••••••••••••••••••••••••••••••••• 1-4 1.5 Disk FormattIng •••••••••••••••••••••••••••••••••••••••••••••••••• 1-5 1.6 Utll Itfes •••••••••••••••••••••••••••••••••••••••••••••••••••••••• -

The UCSD P-System STATUT ORIL Y EX E:M PT
DOCfi!D(ov~ by NSA on 12-01-2011, Transparency Case# 5335]UNCLASSIFIED The UCSD p-System STATUT ORIL Y EX E:M PT This paper discusses the UCSD p-System, an operating system for small computers developed at the University of California at San Diego. The discussion includes the overall system, file managing, editing, and programming in Pascal on the system. INTRODUCTION The UCSD p-System was developed at the University of California at San Diego to support Pascal programming on microcomputers. Similar to MS-DOS, the p-System is an operating system for small computers but is, in many ways, very different. The p-System is written in Pascal and now supports not only Pascal, but also FORTRAN, COBOL, BASIC, and Modula-2. The concept was to have an operating system that, once it was implemented on a machine, allowed any program written under that operating system to be truly transportable from computer to computer. That is to say, the p-System compiler would not actually translate the program into a language that was specific for, say, an 8088 chip on the IBM-PC, but rather would translate it into a "pseudo" language that, when used with an operating system designed for the PC, would run correctly. Similarly, if the operating system were implemented on a Digital Equipment Corporation (DEC) computer, this same pseudo code would still work properly with no modifications. The particular version of UCSD p-System tested was written for the IBM-PC and requires two single-sided double-density disk drives and at least 128K of memory. -

P-System Editors Pascal Assembler
COMPUTER TECHNOLOGY p-System Editors Pascal Assembler 35 NORTH EDISON WAY, SUITE 4· RENO, NEVADA 89502· (702) 322-6868 Contributors at SofTech Microsystems: Software Development: Mark Allen, Gail Anderson, David Berger, Barry Demchak, William Franks, Rich Gleaves, Dean Jacobs, Richard Kaufmann, Stephen Koehler, Mark Overgaard, Stan Stringfellow. Documentation: Randy Clark, Barry Demchak, Rich Gleaves, C.A. Irvine, Bruce Sherman, Stan Stringfellow. End-user Support: H. Blake Berry, Jr., David Barto, Carolyn Chase, Randy Clark, Karen Fraser, Nancy Lanning, Bruce Sherman, George Symons, John Tennant. And thanks too to all the people not named here, at SofTech Microsystems or elsewhere, including the people at Courseware who prepared the illustrations. · DISCLAIMER: These documents and the software they describe are subject to change without notice. No warranty express or implied covers their use. Neither the manufacturer nor the seller is responsible or liable for any consequences of their use. SofTech Microsystems provides telephone and mail support for those users who have purchased their system from either SofTech Microsystems or UCSD (version 1.5 or later). This includes users who purchased their system from retail outlets of SofTech Microsystems. All other users of UCSD Pascal or the UCSD p-System should <;ontact their supplier for support. SofTech Microsystems does not have the resources to support users who purchased their software from other vendors. ACKNOWLEDGEMENTS: The UCSD Pascal project was initiated and guided by the director of the Institute for Information Systems, Professor Kenneth L. Bowles. While at UCSD, the project was supported by a variety of generous contributions, both of money and personal time. -

The Pascal Programming Language
The Pascal Programming Language http://pascal-central.com/ppl/index.html The Pascal Programming Language Bill Catambay, Pascal Developer Updated: 9-5-01 The Pascal Programming Language by Bill Catambay Table of Contents I. Introduction About the Author Origins of Pascal II. The Pascal Architecture Block Structure Style Manageability III. Pascal Standards Unextended Pascal Extended Pascal Object Pascal IV. Myths Uncovered Myth 1: C and Pascal Are Basically the Same Language Myth 2: Pascal is Limited in Power Myth 3: Pascal Has Weak String Handling Capabilities Myth 4: Pascal Does Not Support Object Oriented Programming Myth 5: Pascal is Only an Instructional Language Myth 6: Pascal is Not For Serious Programmers V. Pascal Today Platforms Compilers Internet VI. Summary VII. Bibliography I. Introduction This paper is a review of the Pascal programming language. I will address the origin of the language, discuss the architecture, and talk about the language standards for unextended Pascal and Extended Pascal. I will confront the major criticisms of the language, explaining the origin and inaccuracy of the many myths about Pascal. Finally, I will address the Pascal implementations available today, comparing the 1 of 5 11/9/07 11:42 AM The Pascal Programming Language http://pascal-central.com/ppl/index.html different compilers and the different platforms on which Pascal is currently available. My experience with Pascal dates back to the PDP-11, the system used at Santa Clara University where I received my Bachelor of Science in Computer Science in 1984. During my college years, I learned and worked with several languages on campus, ranging from FORTRAN to Pascal, COBOL to Assembly. -
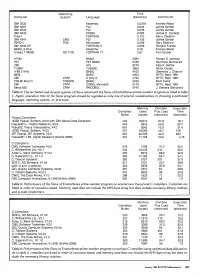
Table 2: the Ten Fastest and Slowest Systems of Those Tested with the Sieve of Eratosthenes Prime -Number Program As Listed in Table 1
Operating Time Computer System Language (Seconds) Contributor IBM 3033 Assembly 0.0078 Andrew Wood IBM 3081 PUI 0.034 James Gerber IBM 3033 PL/I 0.036 James Gerber IBM 3033 COBOL 0.082 James C. Fairfield Cray -1 FORTRAN 0.110 Kerry Chesbro IBM 4341 CMS PUI 0.135 James Gerber PERQ -1 POS Microcode 0.239 Gary Bickford IBM 3033 AP FORTRAN H 0.258 Richard Franke 68000, 8 MHz Assembly 0.49 Andrew Wood Univac 1100/82 OS 1100 FORTRAN 77 0.67 Tom Gruber HP-85 BASIC 3084 Ronald B. Johnson PET PET BASIC 3180 Raymond Mannarelli Z80 APL 3276 Alpa K. Mehta TI 99/4 TI -BASIC 3960 Victor Dodier H -89 2 MHz BASIC 4100 Desmond J. Charron 6809 BASIC 4303 BYTE, Sept. 1981 Z80 CP /M C (tiny -c) 4720 BYTE, Sept. 1981 TRS -80 Mod III TRSDOS BASIC 4780 Matt Ewing Z80 CP /M COBOL Microsoft 5115 BYTE, Sept. 1981 Xerox 820 CP /M RMCOBOL 5740 J. Stevens Blanchard Table 2: The ten fastest and slowest systems of those tested with the Sieve of Eratosthenes prime -number program as listed in table 1. Again, execution time of the Sieve program should be regarded as only one of several considerations in choosing a particular language, operating system, or processor. Memory Compile Execution Compiled Used Plus Load Time Bytes (bytes) (seconds) (seconds) Pascal Compilers UCSD Pascal, Softech, IV.03 with Z80 Native -Code Generator 442 18,874 87.9 19.7 Pascal/MT+ , Digital Research, V5.5 344 3816 50.8 22.7 Pascal /Z, Ithaca Intersystems, V4.0 687 3645 75.0 31.4 UCSD Pascal, Softech, IV.03 237 18,669 46.7 156 JRT Pascal, JRT Systems, V2.0 224 22,008 34.5 383 Pascal /MT+ 86, -

UCSD Pascal'· One Pascal for All Microcomputers
sOFTecH IT1ICROSYS~ UCSD Pascal'· One Pascal For All Microcomputers Installation Guide -Z ft • MILWAUKEE COMPUTERS INC. 16235 W. RYERSON ROAD * NEW BERLIN. WI 53151 UCSD Pascal is a trademark of the Regents of the University of California. I) SERIES COMPUTERS ALL STANDARD Our new MC·IOOO Computer Sys' tern is proof that the age of afforda· • 64K Memory • 2.51/," DI_ DrIves (225K Total Storage) bility in computers has arrived. • Real Time Clock Thanks to single board design we can • 2·RS·232 Interfaces offer not only the lowest priced com· • Parallel PrInter Port (Centronlc:a Type) puter in its class but also the most • extensive Self Diagnostics (In Rom) reliable. For In/ormation and or • 2 Year Umlted Warranty dering call: OPTIONS (414) 184-2312 • Disk Capacity to 1.8 MBYTE • UCSD' Pa..:al. BasiC. Fortran . ~U.Of~ MILWAUKEE COMPUTERS INC. 16235 W. RYERSON ROAD * NEW BERLIN. WI 53151 * (414) 784·2312 CIrcle 313 on Inqulry._ Milwaukee Computers Inc. 16235 W. Ryerson Road, New Berlin, WI 53151 • (414) 784-2312 TWO YEAR LIMITED WARRANTY FOR MC-lOOO SERIES COMPUTERS WARRANTY - Milwaukee Computers Inc. warranties that all MC-lOOO Series Computers shall be free from defects in materials and workmanship. Milwaukee Computers Inc. will repair any and all such defects provided the buyer or ultimate user ("Customer") notifies Milwaukee Computers Inc. of the defect within two (2) years from the date of delivery. (90 days on disk drives) PROCEDURE - To have your MC-lOOO Series Computer repaired under the terms of this warranty follow the following procedure. 1. Contact Milwaukee Computers Inc. -

Computer Science & Engineering
UNIVERSITY OF CALIFORNIA, SAN DIEGO UCSD COMPUTER SCIENCE & ENGINEERING Jacobs School of Engineering University of California, San Diego 9500 Gilman Drive, Dept 0404 La Jolla, CA 92093-0404 858.822.5198 www.cs.ucsd.edu 2 CONTENTS COMPUTER SCIENCE + ENGINEERING LETTER FROM THE CHAIR In recent years the National Academy of Engineering (NAE) conducted an in- CONTENTS tense study of grand challenges and opportunities in engineering facing those born at the dawn of this new century. With input from leading thinkers, practi- Letter from the Chair 2 tioners and even online public commentary, the NAE converged on four themes – sustainability, health, security and living – and 14 grand challenges. Six of At a Glance and CSE Timeline 3 these challenges are related to topics directly addressed by computer science and engineering as a discipline: health informatics, secure cyberspace, enhance Awards + Honors 4 virtual reality, reverse-engineer the brain, personalized learning, and tools of scientific discovery. So it should come as no surprise that the problems we tack- Interdisciplinary Research: ENERGY 6 le as computer scientists and engineers are increasingly inspired by big issues facing society: better education, better health care, better democracy, and bet- Research Groups ter infrastructure for society’s lifelines in energy, water and transportation. Algorithms, Complexity + Cryptography 8 It is truly an exciting time to be a (computer) engineer or a (computer) scientist! Enabled by data, our research is at the center of new sensing, learning and other Graphics and Vision / Bioinformatics 10 paradigms as we enable new tools of scientific discovery through the lens of computing. The growing importance of our endeavor – from maintaining criti- Architecture, Embedded Systems + VLSI/CAD 12 cal infrastructure to the secrets of the human genome – makes us humble. -

Pascal MT Plus Language Reference Manual by Digital Research 1983
Pascal/MT+TM Language Reference Manual Copyright © 1983 Digital Research P.O. Box 579 801 Lighthouse Avenue Pacific Grove, CA 93950 (408) 649-3896 TWX 910 360 5001 All Rights Reserved COPYRIGHT Copyright © 1983 by Digital Research. All rights reserved. No part of this publication may be reproduced, transmitted, transcribed, stored in a retrieval system, or translated into any language or computer language, in any form or by any means, electronic, mechanical, magnetic, optical, chemical, manual or otherwise, without the prior written permission of Digital Research, Post Office Box 579, Pacific Grove, California, 93950. This manual is, however, tutorial in nature. Thus, the reader is granted permission to include the example programs, either in whole or in part, in his or her own programs. DISCLAIMER Digital Research makes no representations or warranties with respect to the contents hereof and specifically disclaims any implied warranties of merchantability or fitness for any particular purpose. Further, Digital Research reserves the right to revise this publication and to make changes from time to time in the content hereof without obligation of Digital Research to notify any person of such revision or changes. TRADEMARKS CP/M and CP/M-86 are registered trademarks of Digital Research. Pascal/MT+ is a trademark of Digital Research. The Pascal/MT+ Language Reference Manual was prepared using the Digital Research TEX Text Formatter, and printed in the United States of America. *********************************** * First Edition: February 1983 * *********************************** Foreword The Pascal/MT+TM language is a full implementation of standard Pascal as set forth in the International Standards Organization (ISO) standard DPS/7185.