Wasmtree: Web Assembly for the Semantic Web
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Desenvolvimento De Uma Ferramenta De Gestão Para Construção Civil Utilizando O Framework Laravel MVC
Universidade Federal de Goiás Regional Catalão Unidade Acadêmica Especial de Biotecnologia Curso de Bacharelado em Ciências da Computação Desenvolvimento de uma ferramenta de gestão para construção civil utilizando o Framework Laravel MVC. Erikson Dutra de Miranda Silva Catalão – GO 2019 Erikson Dutra de Miranda Silva Desenvolvimento de uma ferramenta de gestão para construção civil utilizando o Framework Laravel MVC. Monografia apresentada ao Curso de Bacharelado em Ciências da Computação da Universidade Federal de Goiás – Regional Catalão, como parte dos requisitos para obtenção do grau de Bacharel em Ciências da Computação. VERSÃO REVISADA Orientadora: Prof.a Dr.a Luanna Lopes Lobato Coorientador: Prof. Dr. Thiago Jabur Bittar Coorientador: Prof. Me. Wanderlei Malaquias Pereira Junior Catalão – GO 2019 Ficha de identificação da obra elaborada pelo autor, através do Programa de Geração Automática do Sistema de Bibliotecas da UFG. Silva, Erikson Dutra de Miranda Desenvolvimento de uma ferramenta de gestão para construção civil utilizando o Framework Laravel MVC. [manuscrito] / Erikson Dutra de Miranda Silva. – 2019. 91 p.: il. Orientadora: Prof.a Dr.a Luanna Lopes Lobato Coorientador: Wanderlei Malaquias Pereira Junior Monografia (Graduação) – Universidade Federal de Goiás, Uni- dade Acadêmica Especial de Biotecnologia, Ciências da Computa- ção, 2019. Bibliografia. 1. Engenharia de Software. 2. Desenvolvimento Web. 3. Engenharia Civil. 4. Gestão de Orçamento. 5. Laravel. 6. MVC. I. Lobato, Luanna Lopes, orient. II. Bittar, Thiago Jabur, coorient. Junior, Wanderlei Malaquias Pereira, coorient. III. Título. CDU 004 Erikson Dutra de Miranda Silva Desenvolvimento de uma ferramenta de gestão para construção civil utilizando o Framework Laravel MVC. Monografia apresentada ao curso de Bacharelado em Ciências da Computação da Universidade Federal de Goiás – Regional Catalão. -

Mobilize to Stop Racist Immigration Bill UC Workers to Vote On
Volume 8, Number 16 UCSD Since 1966 May 17-30, 1983 Mobilizeto Stop Racist ImmigrationBill As the Simpson-Ma,,/oliImmigration require all Americans to carry a Bill continuesto wind its way through nationally-controlledidentification Congress,community activists ha~,e work permit: would increase been organi/inga seriesof meetings discriminationagainst all Mexican, aimed at inlormingthe communit~of l.atino,Black, Asian and non-white the repressiveimplications of this persons on the job, and at service legislation. agencies:would reduce or eliminate The Simpson-Ma,,/olibill has already many of the pro’,isionsunder which politicalrelugees can seek asylum ,n the [!.S.; would authori/cand in some INSIDE THIS ISSUE instancesrequire employers, foremen. Historyof Socialism,Film laborcontractors, etc.. to fire,suspend. Reviews, Tenant Organizing, refuseto hire, and refer to the INS persons belie~ ed to ha~,c no Police Terror, Central America documentation:se~erel.~ limit court appealsand constitutionalrights of And the next lucky winnerof reachedthe l]oorof the Senate,and is about to come before the House personsdetained by immigrationagents: an unemploymentcheck is... anddestabilize labor unions. JudiciaryCommittee. Efforts are being madeto pas:,the legislation by August. Perhapsmost controversialhave been 28% of 1982 UCSD graduates entering the work force are now Thebill has come under attack from civil thesanctions against employers who hire unemployed or underemployed, according to a report compiled by libertarians,religious, labor, and undocumented workers, and the UCSD’s Career Planning and Placement Office. 18% of those who are chicanogroups, and othersbecause of nationalidentification card provisions. employedare working as laborers.Few, if any, of these former students The originallegislation required a themassive threat to civilliberties it are eligible for unemployment checks. -
Javascript Var, Let, Const
Angular Frontend Frameworks Browser JavaScript var, let, const Vue for, while, if, switch, operators for ... in vs. for ... of NodeJS TypeScript React Strings, Numbers, Booleans Type Coercion Svelte Templated Strings Functions Closures Higher Order Functions bind, call, apply setTimeout, setInterval Objects (Dictionaries) Prototypes Classes Arrays Slice, Sort, Splice Spread/Rest Operator Map, Filter, Reduce Find, Some, Every Promises Promise.all Promise.race Async/Await RegExp groups, capture, flags test, exec, match Advanced/Uncommon Symbols @@Iterator Generators coroutines Proxies ArrayBuffers UInt8Array, UInt16Array, etc. NodeJS Browser Universal (SSR) Angular CLI Modules Services Dependency Injection Components templates inputs, outputs change detection Router route guards resolvers rxjs Observables Operators Subjects ngrx reducers selectors actions effects NodeJS Browser Next.js (SSR) React JSX Functional Components Props React Native Hooks Class Components State Lifecycle Context, Portal, Fragment Higher Order Components Redux fetch or Axios JavaScript Deno NodeJS npm package.json, scripts, lock Require vs. Import Browser Electron process argv, env, exit fs (File System) promises, write, read, watch child_process spawn, fork, exec os, path, util common libraries Request ExpressJS Hapi JavaScript NodeJS Browser HTML semantic elements Accessibility Attributes dom.js SVG CSS selectors Angular Frontend Frameworks Flex, Grid, calc, scss Vue CSS in JS React DOM attributes, innerHTML Svelte events Shadow DOM Web Components Canvas Webgl, -

Design Mistakes in Node Ryan Dahl JS Conf Berlin June 2018 Background
Design Mistakes in Node Ryan Dahl JS Conf Berlin June 2018 Background ● I created and managed Node through its initial development. ● My goal was heavily focused on programming event driven HTTP servers. ● That focus turned out to be crucial for Server-Side JavaScript at the time. It wasn't obvious then but server-side JS required an event loop to succeed. Background When I left in 2012, I felt Node had (more or less) achieved my goals for a user friendly non-blocking framework: ○ Core supported many protocols: HTTP, SSL, ... ○ Worked on Windows (using IOCP) Linux (epoll) and Mac (kqueue). ○ A relatively small core with a somewhat stable API. ○ A growing ecosystem of external modules via NPM. But I was quite wrong - there was so much left to do... Critical work has kept Node growing since. ● npm (AKA "Isaac") decoupled the core Node library and allowed the ecosystem to be distributed. ● N-API is beautifully designed binding API ● Ben Noordhuis and Bert Belder built the libuv. ● Mikeal Rogers organized the governance and community. ● Fedor Indutny has had a massive influence across the code base, particularly in crypto. ● And many others: TJ Fontaine, Rod Vagg, Myles Borins, Nathan Rajlich, Dave Pacheco, Robert Mustacchi, Bryan Cantrill, Igor Zinkovsky, Aria Stewart, Paul Querna, Felix Geisendörfer, Tim Caswell, Guillermo Rauch, Charlie Robbins, Matt Ranney, Rich Trott, Michael Dawson, James Snell I have only started using Node again in the last 6 months. These days my goals are different. Dynamic languages are the right tool for scientific computing, where often you do quick one-off calculations. -
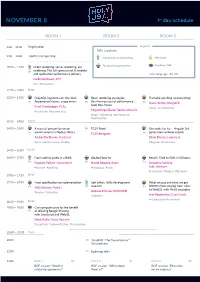
NOVEMBER 8 1St Day Schedule
NOVEMBER 8 1st day schedule ROOM 1 ROOM 2 ROOM 3 9:00 — 19:00 Registration Legend Talk's complexity 9:50 — 10:30 Conference opening Introduction to technology Hardcore For practicing engineers Academic talk 10:30 — 11:30 Client rendering, server rendering, pre EN rendering. The full spectrum of JS website and application performance delivery Talk's language: RU EN Guillermo Rauch, ZEIT #ssr #framework 11:30 — 12:00 Break 12:00 — 13:00 GraphQL fragments on the client: React rendering strategies: Transpile anything to everything! Appearance history, usage errors Get the most out of performance, RU EN EN Anna Herlihy, MongoDB keep bots happy Pavel Chertorogov, PS.kz #tools #fundamental #casestudy #bestpractices Miguel Angel Duran Garcia, Adevinta #react #rendering #performance #optimisation 12:30 — 14:00 Lunch 14:00 — 15:00 A story of one performance EN TC39 Panel Get ready for Ivy — Angular 3rd optimization in a Node.js library generation renderer engine RU TC39 delegates EN Andrey Pechkurov, Hazelcast Eliran Eliassy, e-square.io #perf #optimizations #nodejs #Angular #framework 14:30 — 16:00 Lunch 16:00 — 17:00 From code to pixels in a Blink @babel/how-to NestJS. Tried to Shift in 80 hours EN Prashant Palikhe, Independent EN Nicolò Ribaudo, Babel RU Alexandra Kalinina, #browser #profiling #languages #tools Valor Software #casestudy #Node.js #Backend 17:00 — 17:30 Break 17:30 — 18:30 From specification to implementation Soft Effect: Skills development What we pay and what we get research (PROFIT!) for moving from <div> EN Yulia Startsev, Mozilla -

Volume 5 Full Contents
Butler Journal of Undergraduate Research Volume 5 2019 Volume 5 Full Contents BJUR Staff Follow this and additional works at: https://digitalcommons.butler.edu/bjur Recommended Citation Staff, BJUR (2019) "Volume 5 Full Contents," Butler Journal of Undergraduate Research: Vol. 5 , Article 12. Retrieved from: https://digitalcommons.butler.edu/bjur/vol5/iss1/12 This Article is brought to you for free and open access by the Undergraduate Scholarship at Digital Commons @ Butler University. It has been accepted for inclusion in Butler Journal of Undergraduate Research by an authorized editor of Digital Commons @ Butler University. For more information, please contact [email protected]. BUTLER JOURNAL OF UNDERGRADUATE RESEARCH VOLUME 5 APRIL 2019 Silence and Scream: Women’s Options and Oppressions in Maghrebi Cinema 1 Genevieve Berendt, University of Minnesota Morris Mentor: Sarah Buchanan Exploring a Mechanism Underlying Stereotype Threat in ADHD 27 Alexandra Gabor, Matt Klem, Butler University Mentor: Tara Lineweaver Fight for America's Kids: A Discussion on K-12 Teacher Tenure 46 Nicholas Huang, Butler University Mentor: Jason Lantzer Essay 1 on Ali Smith’s Autumn: The Effects of Art and Insight 70 Brooke Koritala, Southern Methodist University Mentor: LeeAnn Derdeyn Beyond the Looking Glass: Heaven and Earth Mirrored in Early South Asian Literature 77 Dana Maller, Georgia College & State University Mentor: Matthew Milligan Essay 2 on Ali Smith’s Autumn: Establishing Ethical Dialogues 95 Jackson Miller, Southern Methodist University -

Analiza Uporabe GWT Za Razvoj Spletnih Aplikacij
Univerza v Ljubljani Fakulteta za računalništvo in informatiko Saša Makorič Analiza uporabe GWT za razvoj spletnih aplikacij DIPLOMSKO DELO UNIVERZITETNI ŠTUDIJSKI PROGRAM PRVE STOPNJE RAČUNALNIŠTVO IN INFORMATIKA Mentor: prof. dr. Matjaž Branko Jurič Ljubljana 2013 Rezultati diplomskega dela so intelektualna lastnina avtorja in Fakultete za ra- čunalništvo in informatiko Univerze v Ljubljani. Za objavljanje ali izkoriščanje rezultatov diplomskega dela je potrebno pisno soglasje avtorja, Fakultete za raču- nalništvo in informatiko ter mentorja. 1 Besedilo je oblikovano z urejevalnikom besedil LATEX. 1V dogovorju z mentorjem lahko kandidat diplomsko delo s pripadajočo izvorno kodo izda tudi pod katero izmed alternativnih licenc, ki ponuja določen del pravic vsem: npr. Creative Commons, GNU GPL. V tem primeru na to mesto vstavite opis licence, na primer tekst [?] Izjava o avtorstvu diplomskega dela Spodaj podpisani Saša Makorič, z vpisno številko 63080128, sem avtor di- plomskega dela z naslovom: Analiza uporabe GWT za razvoj spletnih aplikacij S svojim podpisom zagotavljam, da: • sem diplomsko delo izdelal samostojno pod mentorstvom prof. dr. Ma- tjaža Branka Juriča • so elektronska oblika diplomskega dela, naslov (slov., angl.), povzetek (slov., angl.) ter ključne besede (slov., angl.) identični s tiskano obliko diplomskega dela • soglašam z javno objavo elektronske oblike diplomskega dela v zbirki ”Dela FRI”. V Ljubljani, dne 11. januarja 2011 Podpis avtorja: Kazalo 1 Uvod 1 2 Google Web Toolkit 3 2.1 Kako deluje GWT? . 3 2.2 Osnove kodiranja v GWT . 4 2.2.1 Modul GWT . 4 2.2.2 JSNI: Uporaba programskega jezika JavaScript . 5 2.3 Razlike med programskim jezikom Java ter GWT . 5 2.4 GWT prevajalnik . -

Pdf/Acyclic.1.Pdf
tldr pages Simplified and community-driven man pages Generated on Sun Sep 26 15:57:34 2021 Android am Android activity manager. More information: https://developer.android.com/studio/command-line/adb#am. • Start a specific activity: am start -n {{com.android.settings/.Settings}} • Start an activity and pass data to it: am start -a {{android.intent.action.VIEW}} -d {{tel:123}} • Start an activity matching a specific action and category: am start -a {{android.intent.action.MAIN}} -c {{android.intent.category.HOME}} • Convert an intent to a URI: am to-uri -a {{android.intent.action.VIEW}} -d {{tel:123}} bugreport Show an Android bug report. This command can only be used through adb shell. More information: https://android.googlesource.com/platform/frameworks/native/+/ master/cmds/bugreport/. • Show a complete bug report of an Android device: bugreport bugreportz Generate a zipped Android bug report. This command can only be used through adb shell. More information: https://android.googlesource.com/platform/frameworks/native/+/ master/cmds/bugreportz/. • Generate a complete zipped bug report of an Android device: bugreportz • Show the progress of a running bugreportz operation: bugreportz -p • Show the version of bugreportz: bugreportz -v • Display help: bugreportz -h cmd Android service manager. More information: https://cs.android.com/android/platform/superproject/+/ master:frameworks/native/cmds/cmd/. • List every running service: cmd -l • Call a specific service: cmd {{alarm}} • Call a service with arguments: cmd {{vibrator}} {{vibrate 300}} dalvikvm Android Java virtual machine. More information: https://source.android.com/devices/tech/dalvik. • Start a Java program: dalvikvm -classpath {{path/to/file.jar}} {{classname}} dumpsys Provide information about Android system services. -
Future Web App Technologies Mendel Rosenblum
Future Web App Technologies Mendel Rosenblum CS142 Lecture Notes - FutureWebAppTech MERN software stack ● React.js ○ Browser-side JavaScript framework - Only View/controller parts ○ Javascript/CSS with HTML templates embedded (JSX) ○ Unopinionated: leaves much SPA support to 3rd parties - routing, model fetching, etc. ● Node.js / Express.js web server code ○ Server side JavaScript ○ High "concurrency" with single-thread event-based programming ● MongoDB "document" storage ○ Store frontend model data ○ Storage system support scale out (sharing and replication), queries, indexes ● Commonly listed alternatives: Angular(2) and Vue.js CS142 Lecture Notes - FutureWebAppTech Angular (AngularJS Version 2) ● Very different from AngularJS (First version of Angular) ○ Doubled down on the AngularJS Directive abstraction - focus reusable components ● Components written in extended Typescript (ES6 + Typescript + annotations) ○ Got rid of AngularJS scopes, controllers, two-way binding ○ Directives are components with a HTML template and corresponding controller code ● Similar architecture to ReactJS ○ Faster rendering and can support server-side rendering ● Vue.js - Done by former AngularJS developer, community supported ○ Similar component architecture ○ Mostly big companies in China CS142 Lecture Notes - FutureWebAppTech Current generation: React.js, Angular, Vue.js ● Common approach: Run in browser, component building blocks, etc. ○ A sign the area is maturing? ● Specification using traditional web programming languages ○ Advanced JavaScript - Babel -
The Utah Online Dispute Resolution Platform: a Usability Evaluation and Report
The Utah Online Dispute Resolution Platform: A Usability Evaluation and Report September 8, 2020 Stacy Butler Sarah Mauet Christopher L. Griffin, Jr. Mackenzie S. Pish Innovation for Justice Program www.law.arizona.edu/i4j [This page intentionally left blank.] The Utah Online Dispute Resolution Platform: i A Usability Evaluation and Report I. EXECUTIVE SUMMARY This report contains findings and recommendations from usability testing of the State of Utah’s online dispute resolution (ODR) platform, which was conducted by the Innovation for Justice (i4J) Program at the University of Arizona James E. Rogers College of Law. Utah’s ODR platform is a web-based alternative dispute resolution tool that provides parties in small claims debt collection actions with an opportunity to resolve their cases online. The i4J Program partnered with the Utah Administrative Office of the Courts and the Pew Charitable Trusts to conduct observation-based usability testing and to identify how the Utah ODR platform could be improved or enhanced, with a focus on functionality, usability, accessibility, and comprehension issues. The research team executed a multi-phase testing process designed to engage the low-income community in the review and redesign of Utah’s ODR platform. The evaluations were conducted in Pima County, Arizona, where the research team is located. All testing involved participants who were screened for demographic characteristics that aligned with national data on non-bank personal loan debtors. Two rounds of observation- based usability testing—the first with the existing, baseline platform and the second with a redesigned prototype—yielded data from a total of sixteen participants. -
![Arxiv:2010.02976V2 [Cs.CL] 25 Oct 2020 Language Carries Information Through Both Deno- Tions in Applications Such As Information Retrieval Tation and Connotation](https://docslib.b-cdn.net/cover/6434/arxiv-2010-02976v2-cs-cl-25-oct-2020-language-carries-information-through-both-deno-tions-in-applications-such-as-information-retrieval-tation-and-connotation-6436434.webp)
Arxiv:2010.02976V2 [Cs.CL] 25 Oct 2020 Language Carries Information Through Both Deno- Tions in Applications Such As Information Retrieval Tation and Connotation
Are “Undocumented Workers” the Same as “Illegal Aliens”? Disentangling Denotation and Connotation in Vector Spaces Albert Webson1,2, Zhizhong Chen3, Carsten Eickhoff1, and Ellie Pavlick1 falbert webson, zhizhong chen, carsten, ellie [email protected] 1Department of Computer Science, Brown University 2Department of Philosophy, Brown University 3Department of Physics, Brown University Abstract government run affordable taxpayer health funded In politics, neologisms are frequently invented horror stories for partisan objectives. For example, “undoc- insurance program umented workers” and “illegal aliens” refer to totalitarian single the same group of people (i.e., they have the payer same denotation), but they carry clearly differ- obama wealthiest ent connotations. Examples like these have policies americans traditionally posed a challenge to reference- trillion ryan based semantic theories and led to increasing dollar budget stimulus spending acceptance of alternative theories (e.g., Two- freedomworks bill cuts Factor Semantics) among philosophers and cognitive scientists. In NLP, however, pop- Figure 1: Nearest neighbors of government-run health- ular pretrained models encode both denota- care (triangles) and economic stimulus (circles). Note tion and connotation as one entangled repre- that words cluster as strongly by policy denotation sentation. In this study, we propose an ad- (shapes) as by partisan connotation (colors); namely, versarial neural network that decomposes a pretrained representations conflate denotation with con- pretrained representation as independent deno- notation. Plotted by t-SNE with perplexity = 10. tation and connotation representations. For intrinsic interpretability, we show that words with the same denotation but different conno- word contexts. Such assumption risks confusing tations (e.g., “immigrants” vs. “aliens”, “estate differences in connotation for differences in deno- tax” vs. -

Corpse Reviver: Sound and Efficient Gradual Typing Via Contract Verification
Corpse Reviver: Sound and Efficient Gradual Typing via Contract Verification CAMERON MOY, Northeastern University, USA PHÚC C. NGUYỄN, University of Maryland, USA SAM TOBIN-HOCHSTADT, Indiana University, USA DAVID VAN HORN, University of Maryland, USA Gradually-typed programming languages permit the incremental addition of static types to untyped pro- grams. To remain sound, languages insert run-time checks at the boundaries between typed and untyped code. Unfortunately, performance studies have shown that the overhead of these checks can be disastrously high, calling into question the viability of sound gradual typing. In this paper, we show that by building on existing work on soft contract verification, we can reduce or eliminate this overhead. Our key insight is that while untyped code cannot be trusted by a gradual type system, there is no need to consider only the worst case when optimizing a gradually-typed program. Instead, we statically analyze the untyped portions of a gradually-typed program to prove that almost all of the dynamic checks implied by gradual type boundaries cannot fail, and can be eliminated at compile time. Our analysis is modular, and can be applied to any portion of a program. We evaluate this approach on a dozen existing gradually-typed programs previously shown to have pro- hibitive performance overhead—with a median overhead of 3.5× and up to 73.6× in the worst case—and eliminate all overhead in most cases, suffering only 1.6× overhead in the worst case. 1 STATIC VERIFICATION TO AVOID DYNAMIC COSTS Gradual typing [30, 36] has become a popular approach to integrate static types into existing dynamically-typed programming languages [7, 21, 32, 37].