Predicting Functional Effects of Missense Variants in Voltage-Gated
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genetic Associations Between Voltage-Gated Calcium Channels (Vgccs) and Autism Spectrum Disorder (ASD)
Liao and Li Molecular Brain (2020) 13:96 https://doi.org/10.1186/s13041-020-00634-0 REVIEW Open Access Genetic associations between voltage- gated calcium channels and autism spectrum disorder: a systematic review Xiaoli Liao1,2 and Yamin Li2* Abstract Objectives: The present review systematically summarized existing publications regarding the genetic associations between voltage-gated calcium channels (VGCCs) and autism spectrum disorder (ASD). Methods: A comprehensive literature search was conducted to gather pertinent studies in three online databases. Two authors independently screened the included records based on the selection criteria. Discrepancies in each step were settled through discussions. Results: From 1163 resulting searched articles, 28 were identified for inclusion. The most prominent among the VGCCs variants found in ASD were those falling within loci encoding the α subunits, CACNA1A, CACNA1B, CACN A1C, CACNA1D, CACNA1E, CACNA1F, CACNA1G, CACNA1H, and CACNA1I as well as those of their accessory subunits CACNB2, CACNA2D3, and CACNA2D4. Two signaling pathways, the IP3-Ca2+ pathway and the MAPK pathway, were identified as scaffolds that united genetic lesions into a consensus etiology of ASD. Conclusions: Evidence generated from this review supports the role of VGCC genetic variants in the pathogenesis of ASD, making it a promising therapeutic target. Future research should focus on the specific mechanism that connects VGCC genetic variants to the complex ASD phenotype. Keywords: Autism spectrum disorder, Voltage-gated calcium -

The Mineralocorticoid Receptor Leads to Increased Expression of EGFR
www.nature.com/scientificreports OPEN The mineralocorticoid receptor leads to increased expression of EGFR and T‑type calcium channels that support HL‑1 cell hypertrophy Katharina Stroedecke1,2, Sandra Meinel1,2, Fritz Markwardt1, Udo Kloeckner1, Nicole Straetz1, Katja Quarch1, Barbara Schreier1, Michael Kopf1, Michael Gekle1 & Claudia Grossmann1* The EGF receptor (EGFR) has been extensively studied in tumor biology and recently a role in cardiovascular pathophysiology was suggested. The mineralocorticoid receptor (MR) is an important efector of the renin–angiotensin–aldosterone‑system and elicits pathophysiological efects in the cardiovascular system; however, the underlying molecular mechanisms are unclear. Our aim was to investigate the importance of EGFR for MR‑mediated cardiovascular pathophysiology because MR is known to induce EGFR expression. We identifed a SNP within the EGFR promoter that modulates MR‑induced EGFR expression. In RNA‑sequencing and qPCR experiments in heart tissue of EGFR KO and WT mice, changes in EGFR abundance led to diferential expression of cardiac ion channels, especially of the T‑type calcium channel CACNA1H. Accordingly, CACNA1H expression was increased in WT mice after in vivo MR activation by aldosterone but not in respective EGFR KO mice. Aldosterone‑ and EGF‑responsiveness of CACNA1H expression was confrmed in HL‑1 cells by Western blot and by measuring peak current density of T‑type calcium channels. Aldosterone‑induced CACNA1H protein expression could be abrogated by the EGFR inhibitor AG1478. Furthermore, inhibition of T‑type calcium channels with mibefradil or ML218 reduced diameter, volume and BNP levels in HL‑1 cells. In conclusion the MR regulates EGFR and CACNA1H expression, which has an efect on HL‑1 cell diameter, and the extent of this regulation seems to depend on the SNP‑216 (G/T) genotype. -

CACNB1 Antibody (C-Term) Blocking Peptide Synthetic Peptide Catalog # Bp16144b
10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 CACNB1 Antibody (C-term) Blocking Peptide Synthetic peptide Catalog # BP16144b Specification CACNB1 Antibody (C-term) Blocking CACNB1 Antibody (C-term) Blocking Peptide - Peptide - Background Product Information The protein encoded by this gene belongs to Primary Accession Q02641 the calciumchannel beta subunit family. It plays an important role in thecalcium channel by modulating G protein inhibition, increasing CACNB1 Antibody (C-term) Blocking Peptide - Additional Information peakcalcium current, controlling the alpha-1 subunit membrane targetingand shifting the voltage dependence of activation and Gene ID 782 inactivation.Alternative splicing occurs at this locus and three transcriptvariants encoding Other Names three distinct isoforms have been identified. Voltage-dependent L-type calcium channel subunit beta-1, CAB1, Calcium channel CACNB1 Antibody (C-term) Blocking voltage-dependent subunit beta 1, CACNB1, Peptide - References CACNLB1 Format Jangsangthong, W., et al. Pflugers Arch. Peptides are lyophilized in a solid powder 459(3):399-411(2010)Olsen, J.V., et al. Cell format. Peptides can be reconstituted in 127(3):635-648(2006)Olsen, J.V., et al. Cell solution using the appropriate buffer as 127(3):635-648(2006)Lim, J., et al. Cell needed. 125(4):801-814(2006)Foell, J.D., et al. Physiol. Genomics 17(2):183-200(2004) Storage Maintain refrigerated at 2-8°C for up to 6 months. For long term storage store at -20°C. Precautions This product is for -

Monogenic Causation in Chronic Kidney Disease
University of Dublin, Trinity College School of Medicine, Department of Medicine Investigation of the monogenic causes of chronic kidney disease PhD Thesis April 2020 Dervla Connaughton Supervisor: Professor Mark Little Co-Supervisors: Professor Friedhelm Hildebrandt and Professor Peter Conlon 1 DECLARATION I declare that this thesis has not been submitted as an exercise for a degree at this or any other university and it is entirely my own work. This work was funding by the Health Research Board, Ireland (HPF-206-674), the International Pediatric Research Foundation Early Investigators’ Exchange Program and the Amgen® Irish Nephrology Society Specialist Registrar Bursary. I agree to deposit this thesis in the University’s open access institutional repository or allow the Library to do so on my behalf, subject to Irish Copyright Legislation and Trinity College Library conditions of use and acknowledgement. I consent to the examiner retaining a copy of the thesis beyond the examining period, should they so wish (EU GDPR May 2018). _____________________ Dervla Connaughton 2 SUMMARY Chapter 1 provides an introduction to the topic while Chapter 2 provides details of the methods employed in this work. In Chapter 3 I provide an overview of the currently known monogenic causes for human chronic kidney disease (CKD). I also describe how next- generation sequencing can facilitate molecular genetic diagnostics in individuals with suspected genetic kidney disease. Chapter 4 details the findings of a multi-centre, cross-sectional study of patients with CKD in the Republic of Ireland. The primary aim of this study (the Irish Kidney Gene Project) was to describe the prevalence of reporting a positive family history of CKD among a representation sample of the CKD population. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
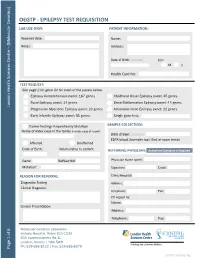
Oegtp - Epilepsy Test Requisition Lab Use Only: Patient Information
OEGTP - EPILEPSY TEST REQUISITION LAB USE ONLY: PATIENT INFORMATION: Received date: Name: Notes: Address: Date of Birth: YY/MM/DD Sex: M F Health Card No: TEST REQUEST: See page 2 for gene list for each of the panels below Epilepsy Comprehensive panel: 167 genes Childhood Onset Epilepsy panel: 45 genes Focal Epilepsy panel: 14 genes Brain Malformation Epilepsy panel: 44 genes London Health Sciences Centre – (Molecular Genetics) London Health Sciences Centre Progressive Myoclonic Epilepsy panel: 20 genes Actionable Gene Epilepsy panel: 22 genes Early Infantile Epilepsy panel: 51 genes Single gene test: Carrier Testing/ KnownFamily Mutation SAMPLE COLLECTION: Name of index case in the family (include copy of report) Date drawn: YY/MM/DD EDTA blood (lavender top) (5ml at room temp) Affected Unaffected Date of Birth: Relationship to patient: REFERRING PHYSICIAN: Authorized Signature is Required Gene: RefSeq:NM Physician Name (print): Mutation: Signature: Email: REASON FOR REFERRAL: Clinic/Hospital: Diagnostic Testing Address: Clinical Diagnosis: Telephone: Fax: CC report to: Name: Clinical Presentation: Address: Telephone: Fax: Molecular Genetics Laboratory Victoria Hospital, Room B10-123A 800 Commissioners Rd. E. London, Ontario | N6A 5W9 Pathology and Laboratory Medicine Ph: 519-685-8122 | Fax: 519-685-8279 Page 1 of 6 Page OEGTP (2021/05/28) OEGTP - EPILEPSY TEST PANELS Patient Identifier: COMPREHENSIVE EPILEPSY PANEL: 167 Genes ACTB, ACTG1, ADSL, AKT3, ALDH7A1, AMT, AP3B2, ARFGEF2, ARHGEF9, ARV1, ARX, ASAH1, ASNS, ATP1A3, ATP6V0A2, ATP7A, -

Cardiomyopathy Precision Panel Overview Indications
Cardiomyopathy Precision Panel Overview Cardiomyopathies are a group of conditions with a strong genetic background that structurally hinder the heart to pump out blood to the rest of the body due to weakness in the heart muscles. These diseases affect individuals of all ages and can lead to heart failure and sudden cardiac death. If there is a family history of cardiomyopathy it is strongly recommended to undergo genetic testing to be aware of the family risk, personal risk, and treatment options. Most types of cardiomyopathies are inherited in a dominant manner, which means that one altered copy of the gene is enough for the disease to present in an individual. The symptoms of cardiomyopathy are variable, and these diseases can present in different ways. There are 5 types of cardiomyopathies, the most common being hypertrophic cardiomyopathy: 1. Hypertrophic cardiomyopathy (HCM) 2. Dilated cardiomyopathy (DCM) 3. Restrictive cardiomyopathy (RCM) 4. Arrhythmogenic Right Ventricular Cardiomyopathy (ARVC) 5. Isolated Left Ventricular Non-Compaction Cardiomyopathy (LVNC). The Igenomix Cardiomyopathy Precision Panel serves as a diagnostic and tool ultimately leading to a better management and prognosis of the disease. It provides a comprehensive analysis of the genes involved in this disease using next-generation sequencing (NGS) to fully understand the spectrum of relevant genes. Indications The Igenomix Cardiomyopathy Precision Panel is indicated in those cases where there is a clinical suspicion of cardiomyopathy with or without the following manifestations: - Shortness of breath - Fatigue - Arrythmia (abnormal heart rhythm) - Family history of arrhythmia - Abnormal scans - Ventricular tachycardia - Ventricular fibrillation - Chest Pain - Dizziness - Sudden cardiac death in the family 1 Clinical Utility The clinical utility of this panel is: - The genetic and molecular diagnosis for an accurate clinical diagnosis of a patient with personal or family history of cardiomyopathy, channelopathy or sudden cardiac death. -

An Integrated Genomic Analysis of Gene-Function Correlation on Schizophrenia Susceptibility Genes
Journal of Human Genetics (2010) 55, 285–292 & 2010 The Japan Society of Human Genetics All rights reserved 1434-5161/10 $32.00 www.nature.com/jhg ORIGINAL ARTICLE An integrated genomic analysis of gene-function correlation on schizophrenia susceptibility genes Tearina T Chu and Ying Liu Schizophrenia is a highly complex inheritable disease characterized by numerous genetic susceptibility elements, each contributing a modest increase in risk for the disease. Although numerous linkage or association studies have identified a large set of schizophrenia-associated loci, many are controversial. In addition, only a small portion of these loci overlaps with the large cumulative pool of genes that have shown changes of expression in schizophrenia. Here, we applied a genomic gene-function approach to identify susceptibility loci that show direct effect on gene expression, leading to functional abnormalities in schizophrenia. We carried out an integrated analysis by cross-examination of the literature-based susceptibility loci with the schizophrenia-associated expression gene list obtained from our previous microarray study (Journal of Human Genetics (2009) 54: 665–75) using bioinformatic tools, followed by confirmation of gene expression changes using qPCR. We found nine genes (CHGB, SLC18A2, SLC25A27, ESD, C4A/C4B, TCP1, CHL1 and CTNNA2) demonstrate gene-function correlation involving: synapse and neurotransmission; energy metabolism and defense mechanisms; and molecular chaperone and cytoskeleton. Our findings further support the roles of these genes in genetic influence and functional consequences on the development of schizophrenia. It is interesting to note that four of the nine genes are located on chromosome 6, suggesting a special chromosomal vulnerability in schizophrenia. -

Anticancer Drug Oxaliplatin Induces Acute Cooling-Aggravated
Anticancer drug oxaliplatin induces acute cooling-aggravated neuropathy via sodium channel subtype NaV1.6-resurgent and persistent current Ruth Sittla,1, Angelika Lampertb,1, Tobias Huthb, E. Theresa Schuyb, Andrea S. Linkb, Johannes Fleckensteinc, Christian Alzheimerb, Peter Grafea, and Richard W. Carra,d,2 aInstitute of Physiology and cDepartment of Anesthesiology, Ludwig-Maximilians University, 80336 Munich, Germany; bInstitute of Physiology and Pathophysiology, Friedrich-Alexander Universität Erlangen-Nürnberg, 91054 Erlangen, Germany; and dDepartment of Anesthesia and Intensive Care Medicine, Medical Faculty Mannheim, Heidelberg University, 68167 Mannheim, Germany Edited by Richard W. Aldrich, University of Texas, Austin, TX, and approved March 8, 2012 (received for review November 2, 2011) Infusion of the chemotherapeutic agent oxaliplatin leads to an arrhythmia (NaV1.5) (14), paramyotonia congenita (Nav1.4) (15, acute and a chronic form of peripheral neuropathy. Acute oxaliplatin 16), and pain (Nav1.7) (15, 17). INaR was first described in cerebellar neuropathy is characterized by sensory paresthesias and muscle Purkinje neurons and refers to a transient surge of inward sodium cramps that are notably exacerbated by cooling. Painful dysesthesias current occurring upon repolarization from a preceding period of are rarely reported for acute oxaliplatin neuropathy, whereas a strong depolarization (18). Because of its unorthodox activation common symptom of chronic oxaliplatin neuropathy is pain. Here profile, INaR is thought to promote burst discharge (11, 12). we examine the role of the sodium channel isoform NaV1.6 in medi- Pain associated with paroxysmal extreme pain disorder (17) and ating the symptoms of acute oxaliplatin neuropathy. Compound and muscle cramps experienced by paramyotonia patients (16) are of- single-action potential recordings from human and mouse peripheral ten exacerbated or triggered by cooling, similar to the symptoms of axons showed that cooling in the presence of oxaliplatin (30–100 μM; acute oxaliplatin neuropathy. -

Dominant-Negative Calcium Channel Suppression by Truncated Constructs Involves a Kinase Implicated in the Unfolded Protein Response
5400 • The Journal of Neuroscience, June 9, 2004 • 24(23):5400–5409 Cellular/Molecular Dominant-Negative Calcium Channel Suppression by Truncated Constructs Involves a Kinase Implicated in the Unfolded Protein Response Karen M. Page,* Fay Heblich,* Anthony Davies,* Adrian J. Butcher,* Jeroˆme Leroy, Federica Bertaso, Wendy S. Pratt, and Annette C. Dolphin Department of Pharmacology, University College London, London WC1E 6BT, United Kingdom Expression of the calcium channel CaV2.2 is markedly suppressed by coexpression with truncated constructs of CaV2.2. Furthermore, a two-domain construct of CaV2.1 mimicking an episodic ataxia-2 mutation strongly inhibited CaV2.1 currents. We have now determined the specificity of this effect, identified a potential mechanism, and have shown that such constructs also inhibit endogenous calcium currents when transfected into neuronal cell lines. Suppression of calcium channel expression requires interaction between truncated and full-length channels, because there is inter-subfamily specificity. Although there is marked cross-suppression within the CaV2 calcium channel family, there is no cross-suppression between CaV2 and CaV3 channels. The mechanism involves activation of a compo- nent of the unfolded protein response, the endoplasmic reticulum resident RNA-dependent kinase (PERK), because it is inhibited by expression of dominant-negative constructs of this kinase. Activation of PERK has been shown previously to cause translational arrest, which has the potential to result in a generalized effect on protein synthesis. In agreement with this, coexpression of the truncated domain ␣ ␦ IofCaV2.2, together with full-length CaV2.2, reduced the level not only of CaV2.2 protein but also the coexpressed 2 -2. -

Inhibition of Radiation and Temozolomide-Induced Glioblastoma Invadopodia Activity Using Ion Channel Drugs
cancers Article Inhibition of Radiation and Temozolomide-Induced Glioblastoma Invadopodia Activity Using Ion Channel Drugs Marija Dinevska 1 , Natalia Gazibegovic 2 , Andrew P. Morokoff 1,3, Andrew H. Kaye 1,4, Katharine J. Drummond 1,3, Theo Mantamadiotis 1,5 and Stanley S. Stylli 1,3,* 1 Department of Surgery, The University of Melbourne, The Royal Melbourne Hospital, Parkville 3050, Victoria, Australia; [email protected] (M.D.); morokoff@unimelb.edu.au (A.P.M.); [email protected] (A.H.K.); [email protected] (K.J.D.); [email protected] (T.M.) 2 Victoria University, St. Albans 3021, Victoria, Australia; [email protected] 3 Department of Neurosurgery, The Royal Melbourne Hospital, Parkville 3050, Victoria, Australia 4 Hadassah University Medical Centre, Jerusalem 91120, Israel 5 Department of Microbiology & Immunology, School of Biomedical Sciences, The University of Melbourne, Parkville 3010, Victoria, Australia * Correspondence: [email protected] or [email protected] Received: 8 September 2020; Accepted: 30 September 2020; Published: 8 October 2020 Simple Summary: Glioblastoma accounts for approximately 40–50% of all primary brain cancers and is a highly aggressive cancer that rapidly disseminates within the surrounding normal brain. Dynamic actin-rich protrusions known as invadopodia facilitate this invasive process. Ion channels have also been linked to a pro-invasive phenotype and may contribute to facilitating invadopodia activity in cancer cells. The aim of our study was to screen ion channel-targeting drugs for their cytotoxic efficacy and potential anti-invadopodia properties in glioblastoma cells. We demonstrated that the targeting of ion channels in glioblastoma cells can lead to a reduction in invadopodia activity and protease secretion. -

(12) Patent Application Publication (10) Pub. No.: US 2016/0281166 A1 BHATTACHARJEE Et Al
US 20160281 166A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2016/0281166 A1 BHATTACHARJEE et al. (43) Pub. Date: Sep. 29, 2016 (54) METHODS AND SYSTEMIS FOR SCREENING Publication Classification DISEASES IN SUBJECTS (51) Int. Cl. (71) Applicant: PARABASE GENOMICS, INC., CI2O I/68 (2006.01) Boston, MA (US) C40B 30/02 (2006.01) (72) Inventors: Arindam BHATTACHARJEE, G06F 9/22 (2006.01) Andover, MA (US); Tanya (52) U.S. Cl. SOKOLSKY, Cambridge, MA (US); CPC ............. CI2O 1/6883 (2013.01); G06F 19/22 Edwin NAYLOR, Mt. Pleasant, SC (2013.01); C40B 30/02 (2013.01); C12O (US); Richard B. PARAD, Newton, 2600/156 (2013.01); C12O 2600/158 MA (US); Evan MAUCELI, (2013.01) Roslindale, MA (US) (21) Appl. No.: 15/078,579 (57) ABSTRACT (22) Filed: Mar. 23, 2016 Related U.S. Application Data The present disclosure provides systems, devices, and meth (60) Provisional application No. 62/136,836, filed on Mar. ods for a fast-turnaround, minimally invasive, and/or cost 23, 2015, provisional application No. 62/137,745, effective assay for Screening diseases, such as genetic dis filed on Mar. 24, 2015. orders and/or pathogens, in Subjects. Patent Application Publication Sep. 29, 2016 Sheet 1 of 23 US 2016/0281166 A1 SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS S{}}\\93? sau36 Patent Application Publication Sep. 29, 2016 Sheet 2 of 23 US 2016/0281166 A1 &**** ? ???zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz??º & %&&zzzzzzzzzzzzzzzzzzzzzzz &Sssssssssssssssssssssssssssssssssssssssssssssssssssssssss & s s sS ------------------------------ Patent Application Publication Sep. 29, 2016 Sheet 3 of 23 US 2016/0281166 A1 23 25 20 FG, 2. Patent Application Publication Sep. 29, 2016 Sheet 4 of 23 US 2016/0281166 A1 : S Patent Application Publication Sep.