An Advanced 4.3BSD Interprocess Communication Tutorial
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical UNIX Capability System
A Practical UNIX Capability System Adam Langley <[email protected]> 22nd June 2005 ii Abstract This report seeks to document the development of a capability security system based on a Linux kernel and to follow through the implications of such a system. After defining terms, several other capability systems are discussed and found to be excellent, but to have too high a barrier to entry. This motivates the development of the above system. The capability system decomposes traditionally monolithic applications into a number of communicating actors, each of which is a separate process. Actors may only communicate using the capabilities given to them and so the impact of a vulnerability in a given actor can be reasoned about. This design pattern is demonstrated to be advantageous in terms of security, comprehensibility and mod- ularity and with an acceptable performance penality. From this, following through a few of the further avenues which present themselves is the two hours traffic of our stage. Acknowledgments I would like to thank my supervisor, Dr Kelly, for all the time he has put into cajoling and persuading me that the rest of the world might have a trick or two worth learning. Also, I’d like to thank Bryce Wilcox-O’Hearn for introducing me to capabilities many years ago. Contents 1 Introduction 1 2 Terms 3 2.1 POSIX ‘Capabilities’ . 3 2.2 Password Capabilities . 4 3 Motivations 7 3.1 Ambient Authority . 7 3.2 Confused Deputy . 8 3.3 Pervasive Testing . 8 3.4 Clear Auditing of Vulnerabilities . 9 3.5 Easy Configurability . -

Beej's Guide to Unix IPC
Beej's Guide to Unix IPC Brian “Beej Jorgensen” Hall [email protected] Version 1.1.3 December 1, 2015 Copyright © 2015 Brian “Beej Jorgensen” Hall This guide is written in XML using the vim editor on a Slackware Linux box loaded with GNU tools. The cover “art” and diagrams are produced with Inkscape. The XML is converted into HTML and XSL-FO by custom Python scripts. The XSL-FO output is then munged by Apache FOP to produce PDF documents, using Liberation fonts. The toolchain is composed of 100% Free and Open Source Software. Unless otherwise mutually agreed by the parties in writing, the author offers the work as-is and makes no representations or warranties of any kind concerning the work, express, implied, statutory or otherwise, including, without limitation, warranties of title, merchantibility, fitness for a particular purpose, noninfringement, or the absence of latent or other defects, accuracy, or the presence of absence of errors, whether or not discoverable. Except to the extent required by applicable law, in no event will the author be liable to you on any legal theory for any special, incidental, consequential, punitive or exemplary damages arising out of the use of the work, even if the author has been advised of the possibility of such damages. This document is freely distributable under the terms of the Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 License. See the Copyright and Distribution section for details. Copyright © 2015 Brian “Beej Jorgensen” Hall Contents 1. Intro................................................................................................................................................................1 1.1. Audience 1 1.2. Platform and Compiler 1 1.3. -

Sockets in the Kernel
Linux Kernel Networking – advanced topics (6) Sockets in the kernel Rami Rosen [email protected] Haifux, August 2009 www.haifux.org All rights reserved. Linux Kernel Networking (6)- advanced topics ● Note: ● This lecture is a sequel to the following 5 lectures I gave in Haifux: 1) Linux Kernel Networking lecture – http://www.haifux.org/lectures/172/ – slides:http://www.haifux.org/lectures/172/netLec.pdf 2) Advanced Linux Kernel Networking - Neighboring Subsystem and IPSec lecture – http://www.haifux.org/lectures/180/ – slides:http://www.haifux.org/lectures/180/netLec2.pdf Linux Kernel Networking (6)- advanced topics 3) Advanced Linux Kernel Networking - IPv6 in the Linux Kernel lecture ● http://www.haifux.org/lectures/187/ – Slides: http://www.haifux.org/lectures/187/netLec3.pdf 4) Wireless in Linux http://www.haifux.org/lectures/206/ – Slides: http://www.haifux.org/lectures/206/wirelessLec.pdf 5) Sockets in the Linux Kernel ● http://www.haifux.org/lectures/217/ – Slides: http://www.haifux.org/lectures/217/netLec5.pdf Note ● Note: This is the second part of the “Sockets in the Linux Kernel” lecture which was given in Haifux in 27.7.09. You may find some background material for this lecture in its slides: ● http://www.haifux.org/lectures/217/netLec5.pdf TOC ● TOC: – RAW Sockets – UNIX Domain Sockets – Netlink sockets – SCTP sockets. – Appendices ● Note: All code examples in this lecture refer to the recent 2.6.30 version of the Linux kernel. RAW Sockets ● There are cases when there is no interface to create sockets of a certain protocol (ICMP protocol, NETLINK protocol) => use Raw sockets. -

Flatpak a Desktop Version of Containers
Flatpak a desktop version of containers Alexander Larsson, Red Hat What is Flatpak? A distribution-independent, Linux-based application distribution and deployment mechanism for desktop applications distribution-independent ● run on any distribution ● build on any distribution ● Any version of the distribution Linux-based ● Flatpak runs only on Linux ● Uses linux-specific features ● However, needs to run on older kernel ● Current minimum target – RHEL 7 – Ubuntu 16.04 (Xenial) – Debian 9 (Stretch) Distribution mechanism ● Built in support for install ● Built in support for updates ● Anyone can set up a repository Deployment mechanism ● Run apps in a controlled environment – “container” ● Sandbox for improved security – Default sandbox is very limited – Apps can ask for more permissions Desktop application ● Focus on GUI apps ● No root permissions ● Automatically integrates with desktop ● App lifetimes are ad-hoc and transient ● Nothing assumes a “sysadmin” being available How is flatpak different from containers Filesystem layout Docker requirements ● Examples: – REST API micro-service – Website back-end ● Few dependencies, all hand-picked ● Runs as a daemon user ● Writes to nonstandard locations in file-system ● Not a lot of integration with host – DNS – Port forwarding – Volumes for data ● No access to host filesystem ● Updates are managed Docker layout ● One image for the whole fs – Bring your own dependencies – Layout up to each app ● Independent of host filesystem layout Flatpak requirements ● Examples – Firefox – Spotify – gedit -

Programmation Systèmes Cours 9 — UNIX Domain Sockets
Programmation Systèmes Cours 9 — UNIX Domain Sockets Stefano Zacchiroli [email protected] Laboratoire PPS, Université Paris Diderot 2013–2014 URL http://upsilon.cc/zack/teaching/1314/progsyst/ Copyright © 2013 Stefano Zacchiroli License Creative Commons Attribution-ShareAlike 4.0 International License http://creativecommons.org/licenses/by-sa/4.0/deed.en_US Stefano Zacchiroli (Paris Diderot) UNIX Domain Sockets 2013–2014 1 / 48 Outline 1 Sockets 2 Stream sockets 3 UNIX domain sockets 4 Datagram sockets Stefano Zacchiroli (Paris Diderot) UNIX Domain Sockets 2013–2014 2 / 48 Outline 1 Sockets 2 Stream sockets 3 UNIX domain sockets 4 Datagram sockets Stefano Zacchiroli (Paris Diderot) UNIX Domain Sockets 2013–2014 3 / 48 Sockets Sockets are IPC objects that allow to exchange data between processes running: either on the same machine( host), or on different ones over a network. The UNIX socket API first appeared in 1983 with BSD 4.2. It has been finally standardized for the first time in POSIX.1g (2000), but has been ubiquitous to every UNIX implementation since the 80s. Disclaimer The socket API is best discussed in a network programming course, which this one is not. We will only address enough general socket concepts to describe how to use a specific socket family: UNIX domain sockets. Stefano Zacchiroli (Paris Diderot) UNIX Domain Sockets 2013–2014 4 / 48 Client-server setup Let’s consider a typical client-server application scenario — no matter if they are located on the same or different hosts. Sockets are used as follows: each application: create a socket ñ idea: communication between the two applications will flow through an imaginary “pipe” that will connect the two sockets together server: bind its socket to a well-known address ñ we have done the same to set up rendez-vous points for other IPC objects, e.g. -

CUPS Plenary Joint PWG / Open Printing Summit - May 2021 Michael R Sweet (Lakeside Robotics) Before We Begin
CUPS Plenary Joint PWG / Open Printing Summit - May 2021 Michael R Sweet (Lakeside Robotics) Before We Begin... ● PWG Antitrust Policy: ● https://www.pwg.org/chair/membership_docs/pwg-antitrust-policy.pdf ● The IEEE-ISTO Printer Working Group ("PWG") will not become involved in the business decisions of its Members. The PWG strictly complies with applicable antitrust laws. Every PWG meeting attendee shall comply with this policy. The PWG Officers and PWG Workgroup Officers are responsible to ensure that this policy is adhered to in all PWG activities. ● PWG Intellectual Property Policy: ● https://www.pwg.org/chair/membership_docs/pwg-ip-policy.pdf ● TL;DR: Anything you say in a PWG meeting or email to a PWG address can be used in a PWG standard ● (but please do read the IP policy above if you haven't done so) 2 Topics ● Introduction ● Apple, Open Printing, and CUPS ● CUPS 2.4 ● Deprecations ● Future Stuff ● Q&A ● Resources 3 Introduction ● CUPS is the standards-based, open source printing system developed by OpenPrinting for Linux® and other Unix®-like operating systems. CUPS uses IPP Everywhere™ to support printing to local and network printers ● CUPS is provided under the Apache License v2.0 with an exception that allows linking to GPL2-only software (like Gutenprint) ● The CUPS web site, source code, and bug database are hosted on Github ○ https://openprinting.github.io/cups ○ https://github.com/openprinting/cups/ ● But wait, I thought that Apple was developing CUPS?!? 4 Apple, OpenPrinting, and CUPS - 1/2 ● Apple hasn't been actively -

Signals and Inter-Process Communication
2/21/20 COMP 790: OS Implementation COMP 790: OS Implementation Housekeeping Signals and Inter-Process • Paper reading assigned for next class Communication Don Porter 1 2 1 2 COMP 790: OS Implementation COMP 790: OS Implementation Logical Diagram Last time… Binary Memory • We’ve discussed how the OS schedules the CPU Threads Formats Allocators User – And how to block a process on a resource (disk, network) Today’s Lecture System Calls Kernel Process • Today: RCU FileCoordination System Networking Sync – How do processes block on each other? – And more generally communicate? Memory Device CPU Management Drivers Scheduler Hardware Interrupts Disk Net Consistency 3 4 3 4 COMP 790: OS Implementation COMP 790: OS Implementation Outline What is a signal? • Signals • Like an interrupt, but for applications – Overview and APIs – <64 numbers with specific meanings – Handlers – A process can raise a signal to another process or thread – Kernel-level delivery – A process or thread registers a handler function – Interrupted system calls • For both IPC and delivery of hardware exceptions • Interprocess Communication (IPC) – Application-level handlers: divzero, segfaults, etc. – Pipes and FIFOs • No “message” beyond the signal was raised – System V IPC – And maybe a little metadata – Windows Analogs • PID of sender, faulting address, etc. • But platform-specific (non-portable) 5 6 5 6 1 2/21/20 COMP 790: OS Implementation COMP 790: OS Implementation Example Example Pid 300 Pid 300 Pid 400 int main() { int main() { ... ... PC signal(SIGUSR1, &usr_handler); -

B SD Portals for LINUX 2.0
B SD Portals for LINUX 2.0 A. David McNab t NAS Technical Report NAS-99-XXX NASA Ames Research Center Mail Stop 258-6 Moffett Field, CA 94035-1000 mcnab@nas, nasa. gov Abstract Portals, an experimental feature of 4.4BSD, extend the filesystem namespace by exporting certain open ( ) requests to a user-space daemon. A portal daemon is mounted into the file namespace as if it were a standard filesystem. When the kernel resolves a pathname and encounters a portal mount point, the remainder of the path is passed to the portal daemon. Depending on the portal "pathname" and the daemon's configuration, some type of open (2 ) is performed. The resulting file descriptor is passed back to the kernel which eventually returns it to the user, to whom it appears that a "normal" open has occurred. A proxy portalfs filesystem is responsible for kernel interaction with the daemon. The overall effect is that the portal daemon performs an open ( 2 ) on behalf of the kernel, possibly hiding substantial complexity from the calling process. One particularly useful application is implementing a connection service that allows simple scripts to open network sockets. This paper describes the implementation of portals for LINUX 2.0. tDavid McNab is an employee of MRJ Technology Solutions, Inc. 2. OVERVIEW OF PORTALS 2/ OVERVIEW OF PORTALS In 1985 Presotto and Ritchie described a connection server[4]: a service process that accepts requests to open 1/ INTRODUCTION connections of some sort, whether they be to a network resource or instructions to dial a modem and connect to a One of the fundamental design commitments of UNIX is service provide, and then processes them on behalf of its that all I/O devices can be represented as simple files in a clients. -

Sockets Lecture 08.01
Sockets Lecture 08.01 https://src-code.simons-rock.edu/git/mbarsky/socket_demo.git Inter-process communication • Wait for exit status (report when done) • Only short integer status • Pipe (always open for communication) • Only between related processes • Signals (send when you want, handle or ignore) • Just a poke Inter-process communication • Wait for exit status (report when done) • Pipe (always open for communication) • Signals (send when you want, handle or ignore) • Sockets (open connection with the world) Sockets • We want two unrelated processes to talk with each other: • Created by different shells • Created by different users • Running on different machines • Sockets are communication points on the same or different computers to exchange data • Sockets are supported by Unix, Windows, Mac, and many other operating systems • Now they are also supported by all modern browsers Sockets use file descriptors to talk • Every I/O action is done by writing or reading to/from a stream using file descriptor • To a programmer, a socket looks and behaves much like a low-level file descriptor: has read(), write(), close() • Sockets are full-duplex (2 way) – as if opening a stream for both reading and writing • The only difference – how we set up the socket If 2 processes are unrelated – we need a protocol for communication • What to say • In what context • When Communication protocols • TCP protocol – how to transfer and receive byte streams • IP protocol – how to locate and connect to a machine on the internet • HTTP protocol establishes rules of communication between browser and web server • Application-level protocols: FTP, SMTP, and POP3 Socket protocols • The two most common socket protocols: • TCP (Transmission Control Protocol) • UDP (User Datagram Protocol) Stream sockets (TCP) • Message delivery is guaranteed. -

The Misuse of Android Unix Domain Sockets and Security Implications
The Misuse of Android Unix Domain Sockets and Security Implications Yuru Shaoy, Jason Ott∗, Yunhan Jack Jiay, Zhiyun Qian∗, Z. Morley Maoy yUniversity of Michigan, ∗University of California, Riverside {yurushao, jackjia, zmao}@umich.edu, [email protected], [email protected] ABSTRACT eral vulnerabilities (e.g., CVE-2011-1823, CVE-2011-3918, In this work, we conduct the first systematic study in un- and CVE-2015-6841) have already been reported. Vendor derstanding the security properties of the usage of Unix do- customizations make things worse, as they expose additional main sockets by both Android apps and system daemons Linux IPC channels: CVE-2013-4777 and CVE-2013-5933. as an IPC (Inter-process Communication) mechanism, espe- Nevertheless, unlike Android IPCs, the use of Linux IPCs cially for cross-layer communications between the Java and on Android has not yet been systematically studied. native layers. We propose a tool called SInspector to ex- In addition to the Android system, apps also have access pose potential security vulnerabilities in using Unix domain to the Linux IPCs implemented within Android. Among sockets through the process of identifying socket addresses, them, Unix domain sockets are the only one apps can easily detecting authentication checks, and performing data flow make use of: signals are not capable of carrying data and analysis. Our in-depth analysis revealed some serious vul- not suitable for bidirectional communications; Netlink sock- nerabilities in popular apps and system daemons, such as ets are geared for communications across the kernel space root privilege escalation and arbitrary file access. Based and the user space. -

Ndnblue: NDN Over Bluetooth
NDN, Technical Report NDN-0015, 2013. http://named-data.net/techreports.html Revision 1: November 7, 2013 NDNBlue: NDN over Bluetooth Arjun Attam∗, Ilya Moiseenkoy ∗Indian Institute of Technology, Delhi. [email protected] yUniversity of California, Los Angeles. [email protected] Abstract—Named Data Networking is a network protocol that III. CONFIGURATION in future is able to displace IP protocol from its current role of a dominating inter-networking layer and also to have an edge in The process of establishing a Bluetooth connection to run such areas of networking as PAN (Personal Area Networking) NDN is initiated by devices finding other physically proximate where IP protocol has never been universally used. This project Bluetooth enabled devices. The user needs to decide between looks into the problem of fitting Named Data Networking request- response communication model into constrained Bluetooth net- an incoming connection (server) or an outgoing connection working stack for both mobile and desktop platforms. We provide (client.) a cross platform proxy layer, which works between NDN stack and Bluetooth stack to achieve NDN connectivity over Bluetooth A. Discovering Devices links for multiple platforms. Index Terms—Information-centric networks, named-data net- NDNBlue for Android can discover nearby Bluetooth de- working, bluetooth, device-to-device communication vices to identify the server device for outgoing connections. The process requires that the server be set as discoverable by I. INTRODUCTION other Bluetooth devices. NDNBlue is an endeavor to extend the scope of NDN ap- plications with Bluetooth. The present CCNx software router B. Security caveats [1] implementation for Named Data Networking works with TCP and UDP tunnels and also can be extended with NDNLP It is recommended that the devices should be authenticated [2] — a link level protocol for Ethernet. -
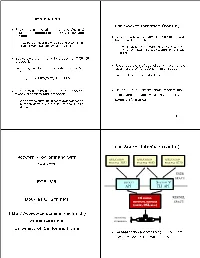
Network Programming with Sockets ECE 255 Douglas C. Schmidt Http
Intro duction The So cket Interface cont'd So ckets are a lo cal and remote OS IPC abstraction de ned in 4.2 BSD UNIX and beyond Originally, so ckets were implemented as a set of system calls { Now part of most major op erating systems, in- cluding Windows and Win32 systems { For eciency, they were tightly-coupled with the BSD networking architecture in the OS kernel So ckets were originally develop ed for TCP/IP proto cols Recent versions of so ckets are implemented { Later generalized to include other proto col fam- as a library of functions in user-space ilies { e.g., SVR4 UNIX and Win32 e.g., Novell IPX/SPX, TP4, ATM User-space implementations improve ex- So cket routine control communication be- tween pro cesses and proto cols ibility and portability at the exp ense of some p erformance { Also provide bu ering between synchronous ap- plication domain and the asynchronous kernel domain 2 4 The So cket Interface cont'd work Programming with Net DISTRIBUTEDAPPLICATION DISTRIBUTEDAPPLICATION DISTRIBUTEDAPPLICATION PROCESS 3592 PROCESS 4183 PROCESS 8729 APPLICATION 1 APPLICATION 2 APPLICATION 3 So ckets USER SPACE 255 ECE BSDSOCKET SOCKET SSYSTEMYSTEM V APIAPI TLITLI APIAPI OS KERNEL KERNEL C. Schmidt Douglas PROTOCOL SERVICES SPACE (TCP/IP, OSI, ETC.) http://www.ece.uci.edu/schmidt/ NETWORK INTERFACE [email protected] University of California, Irvine An application pro cess using TCP/IP pro- to cols resides in its own address space 1 3 Communication Domains cont'd Internet domain or TCP/IP PF INET Communication Domains cont'd