33Rd Research Students' Conference in Probability and Statistics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The London Gazette, 14Th February 1986
2254 THE LONDON GAZETTE, 14TH FEBRUARY 1986 Ibridgeshire (occupation unknown.)). Court—CAM- DIX, Jack Simpson, of 24 Sopers, Codmore Hill. Pul- BRIDGE. No. of Matter—10 of 1980. Date of Order— borough. formerly carrying on business at The Country- 10th December 1980. Date of Adjudication Order—28th man Inn, Whitehall. Shipley, near Horsham, both in October 1980. Date of operation of Order of Discharge the county of West Sussex as a PUBLICAN, now unem- —28th October 198=5. ployed. Court—BRIGHTON. No. of Matter—173 of 1984. Trustee's Name, Address and Description—Official GRIFFITHS, Robert Peter, a CONTRACT CLEANER, of Receiver, Windsor House (East Entrance), 30-35 Edward and 'trading at 7 Howells Close, West Kingsdown, Seven- Street, Brighton, East Sussex BN2 2JZ. Date of Release oaks, Kent TNI5 1XX, as R. Griffiths and Sons. Court —29th January 1986. —MEDWAY. No. of Matter—2A of 1981. Date of Order—19th May 1981. Date of Operation of Order of DOBSON, Graham Stuart, of 30 East Fountains, Illing- Discharge—16th January 1986. worth, Halifax, in the county of West Yorkshire, BAKER, lately residing at 36 Hunter Hill Road, Mixen- den, Halifax, aforesaid. Court—HALIFAX. No. of Matter—32 of 1984. Trustee's Name, Address and Des- APPOINTMENT OF TRUSTEES cription—Official Receiver, 1st Floor, City House, New DICKSON. Michael Gordon, of Flat 2, 113 Poland Street, Station Street, Leeds LSI 4JQ. Date of Release—27th London W1V 3DG, Account Executive lately of and January 1986. trading at Flat 1, 41 Lexington Street, London Wl 3LG as Foresight Management Consultants as a 'Management DUFFY, Denis Stanley, of 6 Marton Heights, Hollins Consultant, described in the Receiving Order as whose Lane, Sowerby Bridge, West Yorkshire, lately residing at present address is unknown, occupation COMPANY and carrying on business at The Queen Hotel, Rippon- DIRECTOR. -

Arrivals Guide.Pdf
IB World Student Conference — the University of Warwick, UK We are delighted that you will be joining the IB World Student Conference, being held at the University of Warwick. We hope that the information provided within this guide, together with the programme of events - will help you make the most of the conference. Before you arrive, please ensure that you have read this guide thoroughly. Please also complete the registration form online at www.warwick.ac.uk/go/ibwsc/registration so that we have your flight arrival time and all the details we need about you. Connecting with us Throughout the conference, and before your arrival, you will be able to interact with fellow participants by joining us on Facebook—www.facebook.com/ibwsc-uk . We also encourage you to tweet and post pictures on Instagram during the conference by using this tag #ibwsc-uk Important information Arriving at the University of Warwick When you arrive at the University of Warwick, either by arranged transfer or independently, please report directly to the conference reception. This is located next to Senate House and car park 7 (see the map at the end of this guide). You will be able to collect your keys from here, as well as: Acquire general information Arrange for secure luggage storage Arrange your log in codes for WiFi access around campus Ask about lost property Request additional bedroom supplies Preparing for the Conference Talent Show & Music Workshops If you have indicated that you would like to participate in the Music Work- shops, or if you going to be taking part in the Talent Show, please ensure that you bring with your musical instrument. -
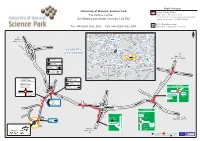
Uni of Warwick Science Park.New
Public Transport University of Warwick Science Park By Rail, Coventry Station. The Venture Centre, Approximately 10 minutes by taxi. For information on train operators and times phone Sir William Lyons Road, Coventry CV4 7EZ National Rail Enquiries on 0845 7484950. By Air, Birmingham Airport. Tel: +44 (0)24 7632 3000 Fax: +44 (0)24 7632 3001 Approximately 20 minutes drive away. Leicester A444 A47 21 A452 A5 10 N M6 Walsall A447 A45 TO M6 M69 Wolverhampton 9 TOLL ROAD M42 M42 JCT 6 8 7 A452 A5 A38 9 M1 1 M6 Nuneaton 1 6 A5199 4 A444 A411 A449 2 M69 A426 A BIRMINGHAM 7 AIRPORT M6 4 COVENTRYA458 Birmingham 3 5 A5 20 3 A45 A45 6 2 Stourbridge M6 CITY CENTRE M5 A38 A41 Coventry A456 A34 A14 Solihull A452 19 A428 A46 TO A441 4 A435 M1 M6 JCT 2 & M69 M42 A4141 Rugby Baginton 5 14 A45 2 COVENTRY F M42 A4177 18 1 3 3a AIRPORT L 4a M45 E Earlsdon 1 16 17 T A448 Honiley Royal C City Centre 2 34 Bromsgrove H M40 Leamington A4189 A45 A46 A A449 A426 M Canley 34 A38 Spa S Redditch T University 114 5 Daventry E A435 Warwick A A 15 428 D Coventry A46 A425 16 51 A45 H Airport 2 M5 A441 A3400 I A G 45 H A429 W 6 A422 M40 A423 S A Stratford Worcester S Y A361 A422 Upon Avon A Cannon Park 3 P Tile Hill 1 4 7 A46 - Shopping Centre 1 Y S Allesley 3 4 B University of Warwick E K 3 A422 6 N Science Park R Canley 4 R A 4 E POLICE A 1 Westwood Heath 4 D University 1 4 A T P S STATION A Business Park 5 Evesham A TOLLBAR END Y O Earlsdon 1 E R Athletics Track R 3 Y N City Centre 2 4 E R T FIRE H N Birmingham L STATION O E A45 Crematorium Canley ND V London ON O (M40) Charter Ave R C (M45, M1(S)) A O R 4 A Warwick Ind. -

West Midlands Local Transport Plan
West Midlands Local Transport Plan Local Transport Strategy Making the Connections Appendices Detailed Topic Areas Relating to the Ten Long Term Themes 2011 – 2026 2 Contents 04 Policy List and Centro’s Delivery Partners 12 1: REGENERATION, THRIVING CENTRES, Appendices – CORRIDORS AND GATEWAYS 13 Land Use, Transport and Regeneration Detailed Topic Areas 18 High Speed Rail relating to the 10 24 Coach Travel to Centres and Major Attractions 29 Birmingham Airport Long Term Themes 32 National Exhibition Centre 34 2: MAKING BEST USE OF THE HIGHWAY NETWORK 35 Highway Network Management, including relationship with the Highways Agency Regional Network 51 Urban Traffic Management and Control 57 Smart Routes – Developing a Strategic Network 70 3: MODAL TRANSFER AND THE CREATION OF SUSTAINABLE TRAVEL PATTERNS 71 Car Parking 75 Demand Management and Reducing the Need to Travel 81 Changing Travel Behaviour and Smarter Choices (including Active Travel) 98 Waterways 104 4: ASSET MANAGEMENT AND MAINTENANCE – A FOUNDATION FOR GROWTH 105 Asset Management Plans (AMPS) 113 Carriageway (Road Pavement) 126 Footways & Cycleways 135 Structures 147 Street Lighting 156 Procurement and Commissioning 3 168 5: A RAIL AND RAPID TRANSIT NETWORK “BACKBONE FOR DEVELOPMENT” 169 Passenger Rail (Network Rail and Centro Schemes) 180 Metro and Rapid Transit 188 6: IMPROVED LOCAL ACCESSIBILITY AND CONNECTIVITY 189 Accessibility Planning 201 Bus 211 Complementary travel services 218 7: SUSTAINABLE AND EFFICIENT FREIGHT TRANSPORT 219 Sustainable Freight Distribution – Road and -

FUL/2018/2651 Site: Land Off De Montfort Way, Coventry. CV4 7EH
Planning Committee Report Planning Ref: FUL/2018/2651 Site: Land off De Montfort Way, Coventry. CV4 7EH Ward: Wainbody Proposal: Redevelopment of the existing car park to provide a new student accommodation building and associated amenities, a new multi-storey car park, landscaping enhancements, new pedestrian crossing and other public realm improvements. Case Officer: Mary-Ann Jones SUMMARY The application seeks planning permission for the redevelopment of the existing surface level car park located to the east of De Montfort Way. The scheme proposes a new student accommodation building comprising 808 bedspaces, a new multi-storey car park, landscaping and a new pedestrian crossing. BACKGROUND The application site is located within the Cannon Park District Centre. The Cannon Park Shopping Centre is located to the west of the site. KEY FACTS Reason for report to Over 5 objections against the officer recommendation. committee: Current use of site: Surface level car park located within the Cannon Park Major District Centre Proposed use of site: Student accommodation and multi storey car park RECOMMENDATION Planning committee are recommended to delegate the granting of planning permission to the Head of Planning and Regulatory Services, subject to the conditions listed in the report and the completion of the S106 legal agreement to secure the contributions listed within the report. REASON FOR DECISION The proposal is acceptable in principle. The proposal will not adversely impact upon highway safety. The proposal will not adversely impact upon the amenity of neighbours. The proposal makes provision for necessary developer contributions. The proposal accords with Policies DS1, DS3, DS4 (Part A), H3, H10, R1, R3, GE3, GE4, JE7, DE1, HE2, AC1, AC2, AC3, AC4, EM1, EM2, EM3, EM4, EM5, EM7, IM1 of the Coventry Local Plan 2016, together with the aims of the NPPF. -

Erasmus Erfahrungsbericht
Erasmus Erfahrungsbericht Gastland: UK Gasthochschule: University of Warwick, Warwick Business School Dauer des Studienaufenthaltes: 29.09.2015-18.03.2016 Programmbeauftrager ERASMUS Kiel: Herrn Prof. Dr. Dr. h.c. J. Wolf Vorab: Orientation Week Die Orientation Week ist nicht ganz billig, lohnt sich aber auf jeden Fall. Man bekommt den Campus sehr gut gezeigt, wird zum Campus gefahren vom Flughafen (auf der Fahrt kann man schon einmal nette Leute kennenlernen!), bekommt eine Willkommenstüte mit Informationen, USB-Stick und anderem Kleinkram. Außerdem bietet sich die Möglichkeit, einen Ausflug nach Coventry zu unternehmen (Tipp: freie Zeit zum Kauf von Küchenutensilien bei IKEA nutzen wie Töpfe, Pfannen, Teller, Besteck, Gläser etc. da dies nicht vorhanden ist!). Insbesondere bei den Essenszeiten oder Abendveranstaltungen kann man viele Leute kennenlernen, auch wenn man dort oft auf Erasmusstudenten oder internationale Studenten trifft, weil viele Engländer erst bei Studienbeginn eintreffen. Es gibt außerdem Einführungsveranstaltungen der WBS, eine kostenlose Laptoptasche mit deren Logo ( :-P ), einen kleinen Empfang mit dem Tutor und Unmengen an Scones mit Marmelade und Sandwiches. Formales: Finanzen Vorweg: Billig ist in England nichts und man sollte definitiv etwas gespart haben, da man mit BAföG und Erasmusförderung alleine nicht über die Runden kommt. Die Miete ist im Vergleich zu Kieler Verhältnissen zwei- bis dreifach so hoch, Nahrungsmittel und Bustickets sind sehr teuer. Wenn man dann auch am sozialen Leben wie z.B. kulturellen Veranstaltungen, Kurztrips oder Society-Treffen teilnehmen möchte, schlägt das zusätzlich zu Buche. Bafög Ein leidiges Thema. Das Bafögamt Hannover ist für die UK zuständig und hat auch eigene spezielle Formulare zum Ausfüllen. Das Auslandsbafög ist nicht höher als das Inlandsbafög und man erhält es nur, wenn man mindestens 3 Monate auf den Tag genau bleibt. -

Exchange Report University of Warwick, United Kingdom Warwick Business School
Exchange Report University of Warwick, United Kingdom Warwick Business School Marie Chan Fall 2019 Finance and Economics I. Monthly Activity Log September I arrived Warwick on Sep 23 as it is the first day of its Welcome Week. I was amazed when I arrived there. The university was so lively. The piazza and the student union were packed with fairs and society promotion. I settled down in my dormitory in Lakeside. It is a beautiful student accommodation as its name suggests – next to a lake and with waterfowl around. I met other exchange students in a Welcoming Party organized by the Warwick Business School. We hanged around afterwards. The campus is compact and easily accessible. We went to the new sports hub for the sports and society fairs. There were food booths in the piazza on every Wednesday. We tried out a few of them and joined the local students to explore the campus. A week later, three exchange students and I went on a trip to Stratford-Upon-Avon, the birthplace of Shakespeare. My exchange life in Warwick kicked off with a warm welcome from Warwick and the friendly students. October Since Warwick is located at the midland of the UK, it is not far away to travel to London. It only takes one and a half hour to get there. We spent our weekend break in there. It was a lovely trip. We got to see the British Museum, London Bridge, the Regent’s Park, Buckingham Palace. We had the best Fish and Chips there. Sure, a weekend wasn’t long enough to visit the whole London and we had missed out on a lot of famous tourist spots so we decided to visit London again. -

87 Bus Time Schedule & Line Route
87 bus time schedule & line map 87 Coventry View In Website Mode The 87 bus line (Coventry) has 2 routes. For regular weekdays, their operation hours are: (1) Coventry: 6:20 AM - 6:30 PM (2) Solihull: 7:32 AM - 6:52 PM Use the Moovit App to ƒnd the closest 87 bus station near you and ƒnd out when is the next 87 bus arriving. Direction: Coventry 87 bus Time Schedule 59 stops Coventry Route Timetable: VIEW LINE SCHEDULE Sunday Not Operational Monday 6:20 AM - 6:30 PM Solihull Station Interchange Station Approach, Birmingham/Wolverhampton/Walsall/Dudley Tuesday 6:20 AM - 6:30 PM Solihull Town Centre, Solihull Wednesday 6:20 AM - 6:30 PM Poplar Road, Birmingham/Wolverhampton/Walsall/Dudley Thursday 6:20 AM - 6:30 PM House Of Fraser, Solihull Friday 6:20 AM - 6:30 PM The Courtyard, Birmingham/Wolverhampton/Walsall/Dudley Saturday 6:20 AM - 6:25 PM Solihull School, Solihull Brueton Avenue, Solihull 909 Warwick Road, Birmingham/Wolverhampton/Walsall/Dudley 87 bus Info Marsh Lane, Solihull Direction: Coventry B4025, Birmingham/Wolverhampton/Walsall/Dudley Stops: 59 Trip Duration: 67 min Ravenshaw Way, Copt Heath Line Summary: Solihull Station Interchange, Solihull Town Centre, Solihull, House Of Fraser, Solihull, Lady Byron Lane, Copt Heath Solihull School, Solihull, Brueton Avenue, Solihull, Marsh Lane, Solihull, Ravenshaw Way, Copt Heath, Jacobean Lane, Copt Heath Lady Byron Lane, Copt Heath, Jacobean Lane, Copt Heath, Lightwood Close, Copt Heath, Arden Vale Rd, Lightwood Close, Copt Heath Knowle, Lodge Rd, Knowle, Knowle Green Church, Copt -

Every Innovation Starts Somewhere Welcome to One of Europe’S Premier University Linked Science Parks
Every innovation starts somewhere Welcome to one of Europe’s premier University linked Science Parks The Science Park provides attractive space, in a well-equipped environment for tech-based businesses to grow in an excellent location, with the added bonus of a direct relationship with one of the country’s top universities. A premier location in the heart of the country... The Science Park is located on the edge of Coventry in the heart of the West Midlands. With excellent motorway niversity of Warwick connectivity, Coventry railway station is 10 minutes away dinburgh Science Park and Birmingham International Airport just 20 minutes. anchester niversity of Warwick Birmingham Science Park M6 TOLL ondon M6 11 M1 10A M42 54 CAFCASS M6 21 9 8 6 M69 I-House 7/4 Viscount Centre C & D BIRMINHAM M5 2 BIRMINHAM T CVENTRY Viscount Centre A & B APORT 19 A5 Coventry to Riley Court M42 4A 3A A 17 M1 WARWICK M45 London d a Heron Court o R l l 15 i H 59 mins n r u b l i M5 STRATFORD-UPON-AVON byM train M40 50 Vanguard 8 Centre (ATU2 ) M5 Sovereign Court 1 & 2 The Venture Centre Advanced Technology Unit (ATU1 ) To the University d a Sir William Lyons Road o R SITE ENTRANCE r e n r o C y b r i K Tesco To Birmingham Garage Fire 5 Lynchgate Road 4 Station A Homebase 5 4 A To London The Science Park Schneider 400,000 sq. ft. (37,161 sq. m.) across a leafy campus site a short walk from all the facilities IOM of the University of Warwick. -
Equity Costa Store List 2019 Live from 2Nd March 2019 Version 3.Xlsx
Store Name Address Blackheath 41 Tranquil Vale London SE3 0BU Hempstead Valley Shopping Centre 2 Unit F11a, Hempstead Valley Shopping Centre Kent ME7 3PD Aberdeen - Academy Unit 15, The Academy Aberdeen AB10 1LB Aberdeen - Bon Accord Centre Bon Accord Shopping Centre Aberdeen AB25 1HZ Aberdeen - Union Square Mall Café Aberdeen AB11 5PS Aberdeen - Cults 2-3 The Courtyard Aberdeen AB15 9SD Aberdeen - Tesco, Rousay Drive Rousay Drive Aberdeen AB15 6XS Aberdeen, Westhill SC, 27 Unit 27, Westhill Shopping Centre Aberdeen AB32 6RL Debenhams Aberdeen Debenhams, Unit 7 Aberdeen AB11 6BE Aberdeen, Next, Berryden Rd, 4 NEXT, Unit 4, Berryden Road Aberdeen AB25 3SG Aberdeen, Abbotswell Rd, DT Drive Thru Aberdeen AB12 3AD Aberdeen Bridge of Don DT Drive Thru, Bridge of Don Retail Park Aberdeen AB23 8JW Aberdeen, Marischal Sq Unit 1a, Marischal Square Aberdeen AB10 1BL Abergavenny, Head of the Valleys DT Westgate Abergavenny NP7 9LL Abergavenny 11 High Street Abergavenny NP7 5RY Aberystwth 5 Great Darkgate Street Aberystwth SY23 1DE Aberystwyth Parc Y Llyn RP, Next Costa Coffee, NEXT, Parc Y Llyn Retail Park Aberystwyth SY23 3TL Milton, Milton Gate 2, DT Drive Thru, 2 Milton Gate Abingdon OX14 4TX Accrington Unit 6 Broadway Accrington BB5 1EY Alderley Edge 24 London Road Alderley Edge SK9 7DZ Aldershot 49-51 Union Street Aldershot GU11 1EP Alnwick 69-71 Bondgate Within Alnwick NE66 1HZ Altrincham - George Street Unit SU207 Altrincham WA14 1RJ Timperley Paul House Altrincham WA15 7UG Hale Barns Unit 5, The Square Altrincham WA15 8ST Amersham 35-37 Sycamore -
(Public Pack)Agenda Document for Pensions Committee, 23/09/2015
[NOT PROTECTIVELY MARKED] Pensions Committee 23 September 2015 Time 1.30 pm Public Meeting? YES Type of meeting Pensions Venue Committee Room 3 - Civic Centre, St Peter's Square, Wolverhampton WV1 1SH Membership Chair Cllr Bert Turner (Lab) Vice-chair Cllr Lorna McGregor (Lab) Labour Conservative Liberal Democrat Cllr Peter Bilson Cllr Paul Singh Cllr Ian Brookfield Cllr Wendy Thompson Cllr Keith Inston Cllr Jasbir Jaspal Cllr Phil Page Cllr Tersaim Singh District Members Trade union observers Cllr Muhammad Afzal (Birmingham City Council) Mr Malcolm Cantello Cllr Mohammed Arif (Walsall Metropolitan Borough Council) Mr Martin Clift Cllr Damian Gannon (Coventry City Council) Mr Victor Silvester Cllr Sandra Hevican (Sandwell Metropolitan Borough Council) Mr Ian Smith Cllr Angela Sandison (Solihull Metropolitan Borough Council) Cllr David Sparks (Dudley Metropolitan Borough Council) Quorum for this meeting is four Councillors. Information for the Public If you have any queries about this meeting, please contact the democratic support team: Contact Dereck Francis Tel/Email Tel:01902 555835 or [email protected] Address Democratic Support, Civic Centre, 1st floor, St Peter’s Square, Wolverhampton WV1 1RL Copies of other agendas and reports are available from: Website http://wolverhampton.cmis.uk.com/decisionmaking Email [email protected] Tel 01902 555043 Please take note of the protocol for filming and recording of, and use of social media in, meetings, copies of which are displayed in the meeting room. Some items are discussed in private because of their confidential or commercial nature. These reports are not available to the public. Agenda Page 1 of 3 [NOT PROTECTIVELY MARKED] Agenda Part 1 – items open to the press and public Item No. -

Coronavirus: Higher and Further Education Back to Campus in England in 2020/21?
Age 25-29 700 Age 20-24 600 500 Age 15-19 400 300 Age 10-14 200 100 0 01 Sep 14 Sep 27 Sep 10 Oct 23 Oct 05 Nov 18 Nov 01 Dec 14 Dec 27 Dec • • • • • • Age 25-29 700 Age 20-24 600 500 Age 15-19 400 300 Age 10-14 200 100 0 01 Sep 14 Sep 27 Sep 10 Oct 23 Oct 05 Nov 18 Nov 01 Dec 14 Dec 27 Dec • Age 2 to school year 6 (early years and primary school age) • School years 7 to 11 (secondary school age) • School year 12 to age 24 (those of sixth form age and young adults who may be in further or higher education) 3.5% 3.0% 2.5% 2.0% 95% 1.5% credible Modelled interval 1.0% % testing positive 0.5% 0.0% 16 May 13 Jun 11 Jul 08 Aug 05 Sep 03 Oct 31 Oct 28 Nov Two-week period ending 3.5% 3.0% 95% 2.5% credible interval 2.0% 1.5% 1.0% Modelled 0.5% % testing positive 0.0% 07-Nov 14-Nov 21-Nov 28-Nov 05-Dec 12-Dec 4% 4% 4% 3% 3% 3% 2% 2% 2% 1% 1% 1% 0% 0% 0% 07/11 17/11 27/11 07/12 17/12 07/11 17/11 27/11 07/12 17/12 07/11 17/11 27/11 07/12 17/12 4% 4% 4% 3% 3% 3% 2% 2% 2% 1% 1% 1% 0% 0% 0% 07/11 17/11 27/11 07/12 17/12 07/11 17/11 27/11 07/12 17/12 07/11 17/11 27/11 07/12 17/12 4% 95% credible interval 3% Estimate 2% 1% 0% 07/11 17/11 27/11 07/12 17/12 Minimum number Minimum number Local authority MSOA name of cases Local authority MSOA name of cases County Durham Durham City 2,091 Leeds Headingley 607 Newcastle upon Tyne Shieldfield & Heaton Park 1,859 Sheffield Broomhall 593 Manchester Fallowfield Central 1,686 Birmingham Edgbaston South & University 593 Nottingham Arboretum, Forest & Trent University 1,572 Liverpool Edge Hill 589 Newcastle upon