Cut out Selected Fields of Each Line of a File
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to Command Line and Accessing Servers Remotely
Introduction to command line and accessing servers remotely Marco Büchler, Emily Franzini, Greta Franzini, Maria Moritz eTRAP Research Group Göttingen Centre for Digital Humanities Institute of Computer Science Georg August University Göttingen, Germany DH Estonia 2015 - Text Reuse Hackathon 20. Oktober 2015 Who am I? • 2001/2 Head of Quality Assurance department in a software company • 2006 Diploma in Computer Science on big • scale co-occurrence analysis • 2007- Consultant for several SMEs in IT sector • 2008 Technical project management of eAQUA project • 2011 PI and project manager of eTRACES project • 2013 PhD in „Digital Humanities“ on Text Reuse • 2014- Head of Early Career Research Group eTRAP at Göttingen Centre for Digital Humanities DH Estonia 2015 - Text Reuse Hackathon 20. Oktober 2015 Agenda 1) Connecting to the server 2) Some command line introduction DH Estonia 2015 - Text Reuse Hackathon 20. Oktober 2015 Connecting to the server 1) Windows: Start Putty 2) Mac + Linux: Open a terminal 3) Connecting to server via ssh -l <login> 192.168.11.4 4) Enter password DH Estonia 2015 - Text Reuse Hackathon 20. Oktober 2015 Which folder am I on the server? Command: pwd (parent working directory) Usage: pwd <ENTER> Example: pwd <ENTER> DH Estonia 2015 - Text Reuse Hackathon 20. Oktober 2015 Which files and directories are contained in my pwd? Command: ls (list) Usage: ls -l <FOLDER> <ENTER> // list all files and directory one on each line ls -la <FOLDER> <ENTER> // show also hidden files ls -lh <FOLDER> <ENTER> // show e.g. files sizes in human- friendly version Example: ls -l <ENTER> ls -lh /home/mbuechler <ENTER> DH Estonia 2015 - Text Reuse Hackathon 20. -

Introduction to Linux – Part 1
Introduction to Linux – Part 1 Brett Milash and Wim Cardoen Center for High Performance Computing May 22, 2018 ssh Login or Interactive Node kingspeak.chpc.utah.edu Batch queue system … kp001 kp002 …. kpxxx FastX ● https://www.chpc.utah.edu/documentation/software/fastx2.php ● Remote graphical sessions in much more efficient and effective way than simple X forwarding ● Persistence - can be disconnected from without closing the session, allowing users to resume their sessions from other devices. ● Licensed by CHPC ● Desktop clients exist for windows, mac, and linux ● Web based client option ● Server installed on all CHPC interactive nodes and the frisco nodes. Windows – alternatives to FastX ● Need ssh client - PuTTY ● http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html - XShell ● http://www.netsarang.com/download/down_xsh.html ● For X applications also need X-forwarding tool - Xming (use Mesa version as needed for some apps) ● http://www.straightrunning.com/XmingNotes/ - Make sure X forwarding enabled in your ssh client Linux or Mac Desktop ● Just need to open up a terminal or console ● When running applications with graphical interfaces, use ssh –Y or ssh –X Getting Started - Login ● Download and install FastX if you like (required on windows unless you already have PuTTY or Xshell installed) ● If you have a CHPC account: - ssh [email protected] ● If not get a username and password: - ssh [email protected] Shell Basics q A Shell is a program that is the interface between you and the operating system -

Download the Specification
Internationalizing and Localizing Applications in Oracle Solaris Part No: E61053 November 2020 Internationalizing and Localizing Applications in Oracle Solaris Part No: E61053 Copyright © 2014, 2020, Oracle and/or its affiliates. License Restrictions Warranty/Consequential Damages Disclaimer This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. Warranty Disclaimer The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. Restricted Rights Notice If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial -

Linux Software User's Manual
New Generation Systems (NGS) Linux Software User’s Manual Version 1.0, September 2019 www.moxa.com/product © 2019 Moxa Inc. All rights reserved. New Generation Systems (NGS) Linux Software User’s Manual The software described in this manual is furnished under a license agreement and may be used only in accordance with the terms of that agreement. Copyright Notice © 2019 Moxa Inc. All rights reserved. Trademarks The MOXA logo is a registered trademark of Moxa Inc. All other trademarks or registered marks in this manual belong to their respective manufacturers. Disclaimer Information in this document is subject to change without notice and does not represent a commitment on the part of Moxa. Moxa provides this document as is, without warranty of any kind, either expressed or implied, including, but not limited to, its particular purpose. Moxa reserves the right to make improvements and/or changes to this manual, or to the products and/or the programs described in this manual, at any time. Information provided in this manual is intended to be accurate and reliable. However, Moxa assumes no responsibility for its use, or for any infringements on the rights of third parties that may result from its use. This product might include unintentional technical or typographical errors. Changes are periodically made to the information herein to correct such errors, and these changes are incorporated into new editions of the publication. Technical Support Contact Information www.moxa.com/support Moxa Americas Moxa China (Shanghai office) Toll-free: 1-888-669-2872 Toll-free: 800-820-5036 Tel: +1-714-528-6777 Tel: +86-21-5258-9955 Fax: +1-714-528-6778 Fax: +86-21-5258-5505 Moxa Europe Moxa Asia-Pacific Tel: +49-89-3 70 03 99-0 Tel: +886-2-8919-1230 Fax: +49-89-3 70 03 99-99 Fax: +886-2-8919-1231 Moxa India Tel: +91-80-4172-9088 Fax: +91-80-4132-1045 Table of Contents 1. -

Programming IBM PASE for I 7.1
IBM IBM i Programming IBM PASE for i 7.1 IBM IBM i Programming IBM PASE for i 7.1 Note Before using this information and the product it supports, be sure to read the information in “Notices,” on page 71. This edition applies to IBM AIX 6 Technology Level 1 and to IBM i 7.1 (product number 5770-SS1) and to all subsequent releases and modifications until otherwise indicated in new editions. This version does not run on all reduced instruction set computer (RISC) models nor does it run on CISC models. © Copyright IBM Corporation 2000, 2010. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents IBM PASE for i ............ 1 Using IBM PASE for i native methods from What's new for IBM i 7.1 .......... 1 Java ............... 28 PDF file for IBM PASE for i ......... 2 Working with environment variables .... 28 IBM PASE for i overview .......... 3 Calling IBM i programs and procedures from IBM PASE for i concepts ......... 3 your IBM PASE for i programs ....... 29 IBM PASE for i as a useful option for application Calling ILE procedures ........ 29 development ............. 4 Examples: Calling ILE procedures .... 31 Installing IBM PASE for i .......... 5 Calling IBM i programs from IBM PASE for i 37 Planning for IBM PASE for i ......... 6 Example: Calling IBM i programs from Preparing programs to run in IBM PASE for i ... 7 IBM PASE for i .......... 37 Analyzing program compatibility with IBM PASE Running IBM i commands from IBM PASE for for i ............... -

Institutionen För Datavetenskap Department of Computer and Information Science
Institutionen för datavetenskap Department of Computer and Information Science Final thesis NetworkPerf – A tool for the investigation of TCP/IP network performance at Saab Transpondertech by Magnus Johansson LIU-IDA/LITH-EX-A--09/039--SE 2009-08-13 Linköpings universitet Linköpings universitet SE-581 83 Linköping, Sweden 581 83 Linköping Final thesis NetworkPerf - A tool for the investigation of TCP/IP network performance at Saab Transpondertech Version 1.0.2 by Magnus Johansson LIU-IDA/LITH-EX-A09/039SE 2009-08-13 Supervisor: Hannes Persson, Attentec AB Examiner: Dr Juha Takkinen, IDA, Linköpings universitet Abstract In order to detect network changes and network troubles, Saab Transpon- dertech needs a tool that can make network measurements. The purpose of this thesis has been to nd measurable network proper- ties that best reect the status of a network, to nd methods to measure these properties and to implement these methods in one single tool. The resulting tool is called NetworkPerf and can measure the following network properties: availability, round-trip delay, delay variation, number of hops, intermediate hosts, available bandwidth, available ports, and maximum al- lowed packet size. The thesis also presents the methods used for measuring these properties in the tool: ping, traceroute, port scanning, and bandwidth measurement. iii iv Acknowledgments This master's thesis would not be half as good as it is, if I had not received help and support from several people. Many thanks to my examiner Dr Juha Takkinen, without whose countin- uous feedback this report would not have been more than a few confusing pages. -

Unix: Beyond the Basics
Unix: Beyond the Basics BaRC Hot Topics – September, 2018 Bioinformatics and Research Computing Whitehead Institute http://barc.wi.mit.edu/hot_topics/ Logging in to our Unix server • Our main server is called tak4 • Request a tak4 account: http://iona.wi.mit.edu/bio/software/unix/bioinfoaccount.php • Logging in from Windows Ø PuTTY for ssh Ø Xming for graphical display [optional] • Logging in from Mac ØAccess the Terminal: Go è Utilities è Terminal ØXQuartz needed for X-windows for newer OS X. 2 Log in using secure shell ssh –Y user@tak4 PuTTY on Windows Terminal on Macs Command prompt user@tak4 ~$ 3 Hot Topics website: http://barc.wi.mit.edu/education/hot_topics/ • Create a directory for the exercises and use it as your working directory $ cd /nfs/BaRC_training $ mkdir john_doe $ cd john_doe • Copy all files into your working directory $ cp -r /nfs/BaRC_training/UnixII/* . • You should have the files below in your working directory: – foo.txt, sample1.txt, exercise.txt, datasets folder – You can check they’re there with the ‘ls’ command 4 Unix Review: Commands Ø command [arg1 arg2 … ] [input1 input2 … ] $ sort -k2,3nr foo.tab -n or -g: -n is recommended, except for scientific notation or start end a leading '+' -r: reverse order $ cut -f1,5 foo.tab $ cut -f1-5 foo.tab -f: select only these fields -f1,5: select 1st and 5th fields -f1-5: select 1st, 2nd, 3rd, 4th, and 5th fields $ wc -l foo.txt How many lines are in this file? 5 Unix Review: Common Mistakes • Case sensitive cd /nfs/Barc_Public vs cd /nfs/BaRC_Public -bash: cd: /nfs/Barc_Public: -

LAB MANUAL for Computer Network
LAB MANUAL for Computer Network CSE-310 F Computer Network Lab L T P - - 3 Class Work : 25 Marks Exam : 25 MARKS Total : 50 Marks This course provides students with hands on training regarding the design, troubleshooting, modeling and evaluation of computer networks. In this course, students are going to experiment in a real test-bed networking environment, and learn about network design and troubleshooting topics and tools such as: network addressing, Address Resolution Protocol (ARP), basic troubleshooting tools (e.g. ping, ICMP), IP routing (e,g, RIP), route discovery (e.g. traceroute), TCP and UDP, IP fragmentation and many others. Student will also be introduced to the network modeling and simulation, and they will have the opportunity to build some simple networking models using the tool and perform simulations that will help them evaluate their design approaches and expected network performance. S.No Experiment 1 Study of different types of Network cables and Practically implement the cross-wired cable and straight through cable using clamping tool. 2 Study of Network Devices in Detail. 3 Study of network IP. 4 Connect the computers in Local Area Network. 5 Study of basic network command and Network configuration commands. 6 Configure a Network topology using packet tracer software. 7 Configure a Network topology using packet tracer software. 8 Configure a Network using Distance Vector Routing protocol. 9 Configure Network using Link State Vector Routing protocol. Hardware and Software Requirement Hardware Requirement RJ-45 connector, Climping Tool, Twisted pair Cable Software Requirement Command Prompt And Packet Tracer. EXPERIMENT-1 Aim: Study of different types of Network cables and Practically implement the cross-wired cable and straight through cable using clamping tool. -

Install and Run External Command Line Softwares
job monitor and control top: similar to windows task manager (space to refresh, q to exit) w: who is there ps: all running processes, PID, status, type ps -ef | grep yyin bg: move current process to background fg: move current process to foreground jobs: list running and suspended processes kill: kill processes kill pid (could find out using top or ps) 1 sort, cut, uniq, join, paste, sed, grep, awk, wc, diff, comm, cat All types of bioinformatics sequence analyses are essentially text processing. Unix Shell has the above commands that are very useful for processing texts and also allows the output from one command to be passed to another command as input using pipe (“|”). less cosmicRaw.txt | cut -f2,3,4,5,8,13 | awk '$5==22' | cut -f1 | sort -u | wc This makes the processing of files using Shell very convenient and very powerful: you do not need to write output to intermediate files or load all data into the memory. For example, combining different Unix commands for text processing is like passing an item through a manufacturing pipeline when you only care about the final product 2 Hands on example 1: cosmic mutation data - Go to UCSC genome browser website: http://genome.ucsc.edu/ - On the left, find the Downloads link - Click on Human - Click on Annotation database - Ctrl+f and then search “cosmic” - On “cosmic.txt.gz” right-click -> copy link address - Go to the terminal and wget the above link (middle click or Shift+Insert to paste what you copied) - Similarly, download the “cosmicRaw.txt.gz” file - Under your home, create a folder -
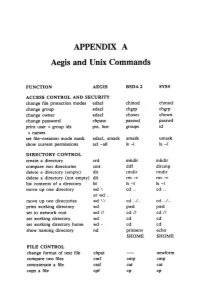
APPENDIX a Aegis and Unix Commands
APPENDIX A Aegis and Unix Commands FUNCTION AEGIS BSD4.2 SYSS ACCESS CONTROL AND SECURITY change file protection modes edacl chmod chmod change group edacl chgrp chgrp change owner edacl chown chown change password chpass passwd passwd print user + group ids pst, lusr groups id +names set file-creation mode mask edacl, umask umask umask show current permissions acl -all Is -I Is -I DIRECTORY CONTROL create a directory crd mkdir mkdir compare two directories cmt diff dircmp delete a directory (empty) dlt rmdir rmdir delete a directory (not empty) dlt rm -r rm -r list contents of a directory ld Is -I Is -I move up one directory wd \ cd .. cd .. or wd .. move up two directories wd \\ cd . ./ .. cd . ./ .. print working directory wd pwd pwd set to network root wd II cd II cd II set working directory wd cd cd set working directory home wd- cd cd show naming directory nd printenv echo $HOME $HOME FILE CONTROL change format of text file chpat newform compare two files emf cmp cmp concatenate a file catf cat cat copy a file cpf cp cp Using and Administering an Apollo Network 265 copy std input to std output tee tee tee + files create a (symbolic) link crl In -s In -s delete a file dlf rm rm maintain an archive a ref ar ar move a file mvf mv mv dump a file dmpf od od print checksum and block- salvol -a sum sum -count of file rename a file chn mv mv search a file for a pattern fpat grep grep search or reject lines cmsrf comm comm common to 2 sorted files translate characters tic tr tr SHELL SCRIPT TOOLS condition evaluation tools existf test test -

ANSWERS ΤΟ EVEN-Numbered
8 Answers to Even-numbered Exercises 2.1. WhatExplain the following unexpected are result: two ways you can execute a shell script when you do not have execute permission for the file containing the script? Can you execute a shell script if you do not have read permission for the file containing the script? You can give the name of the file containing the script as an argument to the shell (for example, bash scriptfile or tcsh scriptfile, where scriptfile is the name of the file containing the script). Under bash you can give the following command: $ . scriptfile Under both bash and tcsh you can use this command: $ source scriptfile Because the shell must read the commands from the file containing a shell script before it can execute the commands, you must have read permission for the file to execute a shell script. 4.3. AssumeWhat is the purpose ble? you have made the following assignment: $ person=zach Give the output of each of the following commands. a. echo $person zach b. echo '$person' $person c. echo "$person" zach 1 2 6.5. Assumengs. the /home/zach/grants/biblios and /home/zach/biblios directories exist. Specify Zach’s working directory after he executes each sequence of commands. Explain what happens in each case. a. $ pwd /home/zach/grants $ CDPATH=$(pwd) $ cd $ cd biblios After executing the preceding commands, Zach’s working directory is /home/zach/grants/biblios. When CDPATH is set and the working directory is not specified in CDPATH, cd searches the working directory only after it searches the directories specified by CDPATH. -

Converting a Hebrew Code Page CP1255 to the UTF-8 Format
LIBICONV – An Interface to Team Developer By Jean-Marc Gemperle Technical Support Engineer November, 2005 Abstract ..................................................................................... 3 Introduction............................................................................... 3 What Is LIBICONV?.................................................................... 4 Obtaining and Building LIBICONV for Win32.............................. 4 A DLL Interface to Team Developer............................................ 4 Team Developer ICONV Samples and Tests................................ 5 A Brief Description of the Application......................................... 6 Converting a Hebrew Code Page CP1255 to the UTF-8 Format................................................................................. 7 Converting the Generated UTF-8 Back to the CP1255 Hebrew Code Page .............................................................. 8 Chinese ISO-2022-CN-EXT to UTF-8 .................................... 9 ISO-8859-1 to DOS 437..................................................... 10 ISO-8859-1 to WINDOWS-1250 Cannot Convert ............... 11 ISO88591 to WINDOWS-1250 Using Translit .................... 11 Conclusions .............................................................................. 12 Abstract This technical white paper proposes an interface from GUPTA Team Developer to the GNU LIBICONV allowing a Team Developer programmer to convert their documents to a different form of encoding. See http://www.gnu.org/software/libiconv/