Learn to Scrap Dynamic Content Using Docker and Selenium
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Study on Functioning of Selenium Automation Testing Structure
Volume 7, Issue 5, May 2017 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Study on Functioning of Selenium Automation Testing Structure 1Jyoti Devi, 2Kirti Bhatia, 3Rohini Sharma* 1, 2 Sat Kabir Institute of Technology and College Management Bahadurgarh, Haryana, India 3 Jesus and Mary Delhi University Delhi, India DOI: 10.23956/ijarcsse/V7I5/0204 Abstract— In recent years, there is advancement in the field of software engineering, applications are getting automated. As the software is error prone, there should some easy and automated way to test the software application. It is very challenging to test such complicated web applications. Human intervention can be reduced by using automation tools. Selenium is an online web based software testing tool. In this article, we have study the design and functioning of the selenium tool and used it to test various online applications. In order to test an application, testers do need not to learn the selenium web driver tool completely. This tool is helpful for a developer and tester, they can analyse their code owing to screen shot characteristics of framework. It generates the adapted test report to the tester. It is very simple to sustain and restore the test suite for new version of the application by this tool. Keywords—Selenium; Automated Testing; Test Cases; Report Generation I. INTRODUCTION The objective of software testing is to discover faults and errors in a software application. Software testing utilizes more than 50 % time of software development lifecycle. Testing time depends upon the algorithm used, programming language, line of codes, function points, external and internal interfaces [1]. -

The Leading Search Engine Solution Used by 7 French Airports Liligo.Com Has Just Signed a Partnership with Strasbourg Airport
Press Release Paris, 31/03/2014 liligo.com: the leading search engine solution used by 7 French airports liligo.com has just signed a partnership with Strasbourg airport. To date, 7 main French airports have chosen liligo solution, making liligo.com the leading provider to power their websites with its innovative state of the art flights, hotels and car hire white label search engine product. liligo.com search engine white-label solution is comprehensive and unbiased. These core values are essential to airports websites as is also the ability to withstand very important search volumes. For these reasons, several French airports, representing 22.3% of passengers’ traffic in France, chose liligo.com’s “tailor-made” approach. Marseille Provence Airport, France’s 3rd largest regional airport for passenger traffic* with more than 8 million passengers and 108 direct destinations, has been using liligo.com’s white-label solution since 2008. The airport is Routes Europe 2014 host and liligo.com is sponsoring the event. Toulouse - Blagnac Airport, France’s 4th largest regional airport, with 7.5 million passengers in 2013*, hundreds of direct destinations and growing traffic, has also chosen liligo.com's white-label solution. Toulouse - Blagnac Airport is connected to all of Europe's major hubs. “Toulouse-Blagnac Airport has chosen liligo.com to help our passengers find the best travel solutions from Toulouse, whether they are looking for flights, holidays or hotels,” comments Jean- Michel Vernhes, Head of the Airport's Board of Directors. “With liligo.com, our passengers can compare the best travel offers and filter their searches by timetables, departure times, airlines, etc. -

Fast and Scalable Automation Framework : “Booster”
WHITEPAPER Fast and Scalable Automation Framework : “Booster” Testing is a form of software business insurance. More automation coverage means less risk. and that is good news for everyone. Sonal Pallewar Email : [email protected] “Automation Framework” and “Why do we need a framework for test automation?” A framework is a software solution that can be used in place of ordinary code that offers generic functions. Some of the challenges of automation are: ● Writing and maintaining test automation frameworks Booster– Linux based ● Scaling to high number of simultaneous tests in multithreaded various environments automation framework ● Reporting and analytics of large number of test results to assess test coverage and build quality ● Ease of use to extend and maintain the framework ● Rich libraries that can be leveraged for quick delivery of automation ”Booster” addresses the above challenges and is used to automate and test several web and mobile frontend applications as well as backend components by executing hundreds of simultaneous tests. Booster is a best-fit Linux based multithreaded automation framework that is fast, scalable and easily extensible. Booster also has readily available rich web, mobile, Linux libraries that can be leveraged to quickly build product specific tests without investing much time in interaction with web and mobile UI interfaces. 1 Need of Booster framework Linux Based Booster is a Linux based framework Supports remote execution of web tests Supports remote execution of tests in target environments with the help of paramiko python library. Supports frontend and backend automation Consists of a rich set of Selenium, mobile and Linux libraries Selenium Grid Supports serial and parallel execution of tests, Multi-platform support i.e. -

Selenium Python Bindings Release 2
Selenium Python Bindings Release 2 Baiju Muthukadan Sep 03, 2021 Contents 1 Installation 3 1.1 Introduction...............................................3 1.2 Installing Python bindings for Selenium.................................3 1.3 Instructions for Windows users.....................................3 1.4 Installing from Git sources........................................4 1.5 Drivers..................................................4 1.6 Downloading Selenium server......................................4 2 Getting Started 7 2.1 Simple Usage...............................................7 2.2 Example Explained............................................7 2.3 Using Selenium to write tests......................................8 2.4 Walkthrough of the example.......................................9 2.5 Using Selenium with remote WebDriver................................. 10 3 Navigating 13 3.1 Interacting with the page......................................... 13 3.2 Filling in forms.............................................. 14 3.3 Drag and drop.............................................. 15 3.4 Moving between windows and frames.................................. 15 3.5 Popup dialogs.............................................. 16 3.6 Navigation: history and location..................................... 16 3.7 Cookies.................................................. 16 4 Locating Elements 17 4.1 Locating by Id.............................................. 18 4.2 Locating by Name............................................ 18 4.3 -

Economics of Airport Operations(Pp
Accepted manuscript. Not for distribution. Please quote as: Beria, P., Laurino, A., & Nadia Postorino, M. (2017). Low-Cost Carriers and Airports: A Complex Relationship. In The Economics of Airport Operations(pp. 361-386). Emerald Publishing Limited. Book series: Advances in Airline Economics Volume 6: “Economics of airport operations” CHAPTER 14 Low-cost carriers and airports: A complex relationship Paolo Beria*, Antonio Laurino and Maria Nadia Postorino *author contact information: [email protected] Abstract In the last decades, low-cost carriers have generated several changes in the air market for both passengers and airports. Mainly for regional airports, low-cost carriers have represented an important opportunity to improve their connectivity levels and passenger traffic. Furthermore, many regional airports have become key factors to regenerate the local economy by improving accessibility and stimulating several markets, such as tourism. However, the relationship between low-cost carriers and airports is rather complex and the outcomes not always predictable. In order to analyse and understand better such relationship and its outcomes, this chapter discusses the main underlying factors identified in: relation with the regional air market (secondary/primary airports), balance of power (dominated/non-dominated airports) and industrial organisation (bases/non-bases). Starting from the proposed Relative Closeness Index, which combines yearly airport passengers and distance between airport pairs, a large sample of European airports is analysed. Then, a smaller sub-sample – which includes selected, significant case studies referring to mid-sized airports – is discussed in detail. Among the main findings, airports sharing their catchment area with others are in a very risky position, due to the potential mobility of LCCs, while geographically isolated airports in good catchment areas can better counterbalance the power of carriers. -

"Airports" (PDF)
Specialist services for the airport life cycle Let's talk aeronautics Specialist services for the airport life cycle AERTEC provides specialist Aviation consultancy and design services to a wealth of Aviation- sector clients, including airport operators, construction firms, service providers, airlines, government agencies, investors, and financial aeronautics institutions. Our company also provides consultancy services and solutions development for Airport Technological Systems. Adolfo Suárez Madrid-Barajas Airport Spain Let's talk Let's M A D We create value for Aviation clients Consultancy through integrated Conception services and independent specialist advice Operations Development Operational Planning assessment & Design Airport Technology #Airports Our Services Feasibility studies Airport solutions for landside/airside and analysis Studies and plans ¬ Policy and sector studies ¬ Airport masterplanning ¬ Air transport market studies ¬ Feasibility studies ¬ Traffic forecasting ¬ Airport planning studies ¬ Business advisory ¬ Aeronautical safety studies ¬ Transaction support ¬ Design of flight procedures and Consultancy and due diligence airspace compatibility studies ¬ Obstacle limitation surface studies ¬ Operational safety studies ¬ Capacity studies: airside and landside Brussels South Charleroi Airport Planning & Design ¬ Aircraft flow simulations (AirTop/Simmod/AeroTURN) C R L Belgium ¬ Passenger flow simulations (AirTop/CAST) ¬ Aircraft noise contour studies (AEDT) ¬ Airport planning application Airfields ¬ Preliminary plans, -

Scraping Sites That Use Search Forms
Chapter 9 Scraping Sites that Don’t Want to be Scraped/ Scraping Sites that Use Search Forms Skills you will learn: Basic setup of the Selenium library, which allows you to control a web browser from a Python script. Filling out a form on a website and scraping the returned records. Introduction: Sometimes, websites throw up hurdles, deliberately or incidentally, that can make scraping more difficult. For example, they may place cookies on your computer containing values that must be resubmitted with the next request to the server, failing which the request will be ignored or redirected to the landing page. These cookies may expire after a set period of time and have to be regenerated by the server. Ordinary scraping scripts using libraries such as urllib2 may fail when you attempt to scrape these kinds of sites because the script doesn’t send the expected values. Similarly, pages may contain hidden import fields (basically form fields that are not visible to the user) that automatically submit long strings of alphanumeric characters to validate the request. Again, the script fails to submit the required string, and the request fails or is redirected. On other occasions, you may need to fill out a form before the server will send data, or you may wish to use the form to selectively choose which data to scrape. Selenium allows us to deal with these challenges because it controls an actual browser, such as Firefox, and when the script “clicks” a submit button, as an example, any cookies, hidden form fields, or JavaScript routines are handled by the browser just as they would be if a human user had clicked the button. -

Airport Operation Brest Bretagne Airport Quimper
AIRPORT OPERATION FRANCE BREST BRETAGNE AIRPORT QUIMPER BRETAGNE AIRPORT In Western Brittany, more than in any other region of France, opening to the outside is a means of stimulating development and creating sustainable employment. In this context, the Brittany Region has delegated for a period of 20 years the management and operation of Brest and Quimper airports to a consortium made up of Chamber of Commerce & Industry of Western Brittany, Egis and local partners. This innovative structure is based on complementary characteris- tics of the two airports and sharing of resources via a principal structure Aéroport Bretagne Ouest (ABO) and its subsidiary dedi- cated to Quimper, Aéroport de Cornouaille (ADC). Shareholders: Since 2012, Brest airport welcomes more than a million passengers a year. This is mainly due to solid demand for flights to and from Egis: 5% Caisse Paris (Orly and Charles de Gaulle airports). A key competitor for des Dépôts this route is the High-Speed Rail Line, which has been in service Transdev: 5% Group since 2017. diversification strategy, the objective is to double the number of passengers. As the 18th largest airport in France, CCI Bretagne Ouest: 66% Brest demonstrates an impressive standard of high performance ADLMS: 10% equipment in particular a reduced visibility landing assistance system and a runway length of 3,100 m enabling landing of all Crédit Agricole: 5% types of aircraft. Crédit Mutuel: 5% Brest AIM: 4% EGIS KNOW-HOW Egis is a preferred technical partner for ABP and ADC’s consortium, using its combined expertise to develop, operate Concession period: 20 years and manage the two airports in Brittany. -

Envies D'ailleurs
IN ][ OUT MAGAZINE DE L'AÉROPORT DE LILLE LILFÉVRIER-MARS-AVRIL 2017 ENVIES D’AILLEURS L’Algarve, Faro, Venise, Brest Guide des vols & séjours Vluchten- en reisgids www.lille.aeroport.fr Une adresse intime en bord de mer... Plage de Pinarello 20144 Sainte Lucie de Porto-Vecchio - Corse Tél : 04.95.71.44.39 - [email protected] www.lepinarello.com 04 News Édito LIL, Éco, Tourisme, Culture 8 Rencontre Chers passagers, Alexandre Bloch L’année 2016 s’est achevée sur de bonnes nouvelles pour votre 20 aéroport régional : l’aéroport de Lille a enregistré en 2016, un trafic Art de vivre & Culture record de 1.781.490 passagers, soit une progression de plus de Musée du Louvre-Lens : Quand la 15 %, grâce aussi au soutien des grandes compagnies aériennes culture redessine un bassin minier européennes et d'acteurs majeurs du tourisme. D’autre part, easyJet ouvrira prochainement 3 nouvelles lignes : Naples, Venise et Faro. 25 De son côté, Volotea confirme un programme renforcé sur la Corse et Envies D’ailleurs ouvrira bientôt Montpellier. Le groupe TUI France vous emmène quant L’Algarve, Faro, Venise, Brest à lui à Araxos, Kalamata, Split, Cagliari, en plus d'Athènes et du Cap- Vert, portant à 30 le total des destinations Vacances. Sans oublier 45 Tendance Flykiss qui a ouvert récemment Brest et Clermont Ferrand. Au total, 55 destinations vous sont proposées au départ de Lille cette année. 46 Guide des vols Autant de bonnes raisons de regarder 2017, avec envie et optimisme, & des voyages et de vous inviter à voyager, partir à la découverte d'autres horizons et Plannings des vols 2017 d'aller à la rencontre des autres. -

Ready to Use Industrial Sites France, an Attractive Destination for Manufacturers
INVEST IN FRANCE READY TO USE INDUSTRIAL SITES FRANCE, AN ATTRACTIVE DESTINATION FOR MANUFACTURERS st 1 Better tax European Over 28,000 destination industrial treatment for for foreign companies R&D tax investment in created in 2018 of all OECD countries industry For 15 years, France has The business environment is The French ecosystem is been the leading European conducive to entrepreneurship recognised as encouraging country in regard to receiving and the industrial sector in innovation. The manufacturing industrial Investments in particular. industry generated €23.5bn industry. of R&D expenditure in 2017. BUSINESS FRANCE SUPPORTS YOU Two out of three investments are supported Business France helps international investors by the Business France teams, which offer in France, via a network operating in over companies a personalised and confidential 40 countries and regional partner agencies. service. READY TO USE INDUSTRIAL SITES, A STRATEGY AT THE SERVICE OF BUSINESSES Following a call for projects launched by the Delegation to Industry Territories, the territories have identified industrial sites «Ready to use» to respond in a way effective for international investors needs, within competitive deadlines ACCELERATE AND STRENGTHEN GOOD INDUSTRIAL PRESENCE PRACTICES French government’s objective is to accelerate compulsory Beyond this first inventory of the turnkey industrial sites, the preliminary procedures to an industrial creation. 5 priorities objective is to better know the good practices of the local have been identified and will be addressed in 2020, economic actors to welcome foreign direct investments for instance how to better anticipate the aforementioned (FDI). procedures and the provision of turnkey industrial sites. Additional ready to use industrial sites will progressively be identified in 2020. -

City/Airport Country IATA Codes
City/Airport Country IATA Codes Aarhus Denmark AAR Abadan Iran ABD Abeche Chad AEH Aberdeen United Kingdom ABZ Aberdeen (SD) USA ABR Abidjan Cote d'Ivoire ABJ Abilene (TX) USA ABI Abu Dhabi - Abu Dhabi International United Arab Emirates AUH Abuja - Nnamdi Azikiwe International Airport Nigeria ABV Abu Rudeis Egypt AUE Abu Simbel Egypt ABS Acapulco Mexico ACA Accra - Kotoka International Airport Ghana ACC Adana Turkey ADA Addis Ababa - Bole International Airport Ethiopia ADD Adelaide Australia ADL Aden - Aden International Airport Yemen ADE Adiyaman Turkey ADF Adler/Sochi Russia AER Agades Niger AJY Agadir Morocco AGA Agana (Hagåtña) Guam SUM Aggeneys South Africa AGZ Aguadilla Puerto Rico BQN Aguascaliente Mexico AGU Ahmedabad India AMD Aiyura Papua New Guinea AYU Ajaccio France AJA Akita Japan AXT Akron (OH) USA CAK Akrotiri - RAF Cyprus AKT Al Ain United Arab Emirates AAN Al Arish Egypt AAC Albany Australia ALH Albany (GA) USA ABY Albany (NY) - Albany International Airport USA ALB Albi France LBI Alborg Denmark AAL Albuquerque (NM) USA ABQ Albury Australia ABX Alderney Channel Islands ACI Aleppo Syria ALP Alesund Norway AES Alexander Bay - Kortdoorn South Africa ALJ Alexandria - Borg el Arab Airport Egypt HBH Alexandria - El Nhouza Airport Egypt ALY Alexandria - Esler Field USA (LA) ESF Alfujairah (Fujairah) United Arab Emirates FJR Alghero Sassari Italy AHO Algiers, Houari Boumediene Airport Algeria ALG Al Hoceima Morocco AHU Alicante Spain ALC Alice Springs Australia ASP Alldays South Africa ADY Allentown (PA) USA ABE Almaty (Alma -
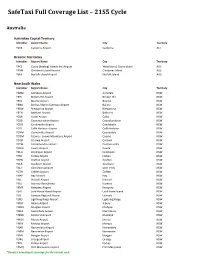
Safetaxi Full Coverage List – 21S5 Cycle
SafeTaxi Full Coverage List – 21S5 Cycle Australia Australian Capital Territory Identifier Airport Name City Territory YSCB Canberra Airport Canberra ACT Oceanic Territories Identifier Airport Name City Territory YPCC Cocos (Keeling) Islands Intl Airport West Island, Cocos Island AUS YPXM Christmas Island Airport Christmas Island AUS YSNF Norfolk Island Airport Norfolk Island AUS New South Wales Identifier Airport Name City Territory YARM Armidale Airport Armidale NSW YBHI Broken Hill Airport Broken Hill NSW YBKE Bourke Airport Bourke NSW YBNA Ballina / Byron Gateway Airport Ballina NSW YBRW Brewarrina Airport Brewarrina NSW YBTH Bathurst Airport Bathurst NSW YCBA Cobar Airport Cobar NSW YCBB Coonabarabran Airport Coonabarabran NSW YCDO Condobolin Airport Condobolin NSW YCFS Coffs Harbour Airport Coffs Harbour NSW YCNM Coonamble Airport Coonamble NSW YCOM Cooma - Snowy Mountains Airport Cooma NSW YCOR Corowa Airport Corowa NSW YCTM Cootamundra Airport Cootamundra NSW YCWR Cowra Airport Cowra NSW YDLQ Deniliquin Airport Deniliquin NSW YFBS Forbes Airport Forbes NSW YGFN Grafton Airport Grafton NSW YGLB Goulburn Airport Goulburn NSW YGLI Glen Innes Airport Glen Innes NSW YGTH Griffith Airport Griffith NSW YHAY Hay Airport Hay NSW YIVL Inverell Airport Inverell NSW YIVO Ivanhoe Aerodrome Ivanhoe NSW YKMP Kempsey Airport Kempsey NSW YLHI Lord Howe Island Airport Lord Howe Island NSW YLIS Lismore Regional Airport Lismore NSW YLRD Lightning Ridge Airport Lightning Ridge NSW YMAY Albury Airport Albury NSW YMDG Mudgee Airport Mudgee NSW YMER