A Faster Parameterized Algorithm for Pseudoforest Deletion∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Directed Graph Algorithms
Directed Graph Algorithms CSE 373 Data Structures Readings • Reading Chapter 13 › Sections 13.3 and 13.4 Digraphs 2 Topological Sort 142 322 143 321 Problem: Find an order in which all these courses can 326 be taken. 370 341 Example: 142 Æ 143 Æ 378 Æ 370 Æ 321 Æ 341 Æ 322 Æ 326 Æ 421 Æ 401 378 421 In order to take a course, you must 401 take all of its prerequisites first Digraphs 3 Topological Sort Given a digraph G = (V, E), find a linear ordering of its vertices such that: for any edge (v, w) in E, v precedes w in the ordering B C A F D E Digraphs 4 Topo sort – valid solution B C Any linear ordering in which A all the arrows go to the right F is a valid solution D E A B F C D E Note that F can go anywhere in this list because it is not connected. Also the solution is not unique. Digraphs 5 Topo sort – invalid solution B C A Any linear ordering in which an arrow goes to the left F is not a valid solution D E A B F C E D NO! Digraphs 6 Paths and Cycles • Given a digraph G = (V,E), a path is a sequence of vertices v1,v2, …,vk such that: ›(vi,vi+1) in E for 1 < i < k › path length = number of edges in the path › path cost = sum of costs of each edge • A path is a cycle if : › k > 1; v1 = vk •G is acyclic if it has no cycles. -
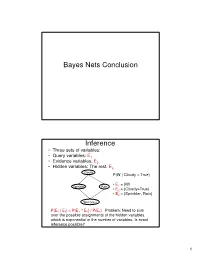
Bayes Nets Conclusion Inference
Bayes Nets Conclusion Inference • Three sets of variables: • Query variables: E1 • Evidence variables: E2 • Hidden variables: The rest, E3 Cloudy P(W | Cloudy = True) • E = {W} Sprinkler Rain 1 • E2 = {Cloudy=True} • E3 = {Sprinkler, Rain} Wet Grass P(E 1 | E 2) = P(E 1 ^ E 2) / P(E 2) Problem: Need to sum over the possible assignments of the hidden variables, which is exponential in the number of variables. Is exact inference possible? 1 A Simple Case A B C D • Suppose that we want to compute P(D = d) from this network. A Simple Case A B C D • Compute P(D = d) by summing the joint probability over all possible values of the remaining variables A, B, and C: P(D === d) === ∑∑∑ P(A === a, B === b,C === c, D === d) a,b,c 2 A Simple Case A B C D • Decompose the joint by using the fact that it is the product of terms of the form: P(X | Parents(X)) P(D === d) === ∑∑∑ P(D === d | C === c)P(C === c | B === b)P(B === b | A === a)P(A === a) a,b,c A Simple Case A B C D • We can avoid computing the sum for all possible triplets ( A,B,C) by distributing the sums inside the product P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a 3 A Simple Case A B C D This term depends only on B and can be written as a 2- valued function fA(b) P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a A Simple Case A B C D This term depends only on c and can be written as a 2- valued function fB(c) === === === === === === P(D d) ∑∑∑ P(D d | C c)∑∑∑P(C c | B b)f A(b) c b …. -

Graph Varieties Axiomatized by Semimedial, Medial, and Some Other Groupoid Identities
Discussiones Mathematicae General Algebra and Applications 40 (2020) 143–157 doi:10.7151/dmgaa.1344 GRAPH VARIETIES AXIOMATIZED BY SEMIMEDIAL, MEDIAL, AND SOME OTHER GROUPOID IDENTITIES Erkko Lehtonen Technische Universit¨at Dresden Institut f¨ur Algebra 01062 Dresden, Germany e-mail: [email protected] and Chaowat Manyuen Department of Mathematics, Faculty of Science Khon Kaen University Khon Kaen 40002, Thailand e-mail: [email protected] Abstract Directed graphs without multiple edges can be represented as algebras of type (2, 0), so-called graph algebras. A graph is said to satisfy an identity if the corresponding graph algebra does, and the set of all graphs satisfying a set of identities is called a graph variety. We describe the graph varieties axiomatized by certain groupoid identities (medial, semimedial, autodis- tributive, commutative, idempotent, unipotent, zeropotent, alternative). Keywords: graph algebra, groupoid, identities, semimediality, mediality. 2010 Mathematics Subject Classification: 05C25, 03C05. 1. Introduction Graph algebras were introduced by Shallon [10] in 1979 with the purpose of providing examples of nonfinitely based finite algebras. Let us briefly recall this concept. Given a directed graph G = (V, E) without multiple edges, the graph algebra associated with G is the algebra A(G) = (V ∪ {∞}, ◦, ∞) of type (2, 0), 144 E. Lehtonen and C. Manyuen where ∞ is an element not belonging to V and the binary operation ◦ is defined by the rule u, if (u, v) ∈ E, u ◦ v := (∞, otherwise, for all u, v ∈ V ∪ {∞}. We will denote the product u ◦ v simply by juxtaposition uv. Using this representation, we may view any algebraic property of a graph algebra as a property of the graph with which it is associated. -

Networkx: Network Analysis with Python
NetworkX: Network Analysis with Python Salvatore Scellato Full tutorial presented at the XXX SunBelt Conference “NetworkX introduction: Hacking social networks using the Python programming language” by Aric Hagberg & Drew Conway Outline 1. Introduction to NetworkX 2. Getting started with Python and NetworkX 3. Basic network analysis 4. Writing your own code 5. You are ready for your project! 1. Introduction to NetworkX. Introduction to NetworkX - network analysis Vast amounts of network data are being generated and collected • Sociology: web pages, mobile phones, social networks • Technology: Internet routers, vehicular flows, power grids How can we analyze this networks? Introduction to NetworkX - Python awesomeness Introduction to NetworkX “Python package for the creation, manipulation and study of the structure, dynamics and functions of complex networks.” • Data structures for representing many types of networks, or graphs • Nodes can be any (hashable) Python object, edges can contain arbitrary data • Flexibility ideal for representing networks found in many different fields • Easy to install on multiple platforms • Online up-to-date documentation • First public release in April 2005 Introduction to NetworkX - design requirements • Tool to study the structure and dynamics of social, biological, and infrastructure networks • Ease-of-use and rapid development in a collaborative, multidisciplinary environment • Easy to learn, easy to teach • Open-source tool base that can easily grow in a multidisciplinary environment with non-expert users -

1 Hamiltonian Path
6.S078 Fine-Grained Algorithms and Complexity MIT Lecture 17: Algorithms for Finding Long Paths (Part 1) November 2, 2020 In this lecture and the next, we will introduce a number of algorithmic techniques used in exponential-time and FPT algorithms, through the lens of one parametric problem: Definition 0.1 (k-Path) Given a directed graph G = (V; E) and parameter k, is there a simple path1 in G of length ≥ k? Already for this simple-to-state problem, there are quite a few radically different approaches to solving it faster; we will show you some of them. We’ll see algorithms for the case of k = n (Hamiltonian Path) and then we’ll turn to “parameterizing” these algorithms so they work for all k. A number of papers in bioinformatics have used quick algorithms for k-Path and related problems to analyze various networks that arise in biology (some references are [SIKS05, ADH+08, YLRS+09]). In the following, we always denote the number of vertices jV j in our given graph G = (V; E) by n, and the number of edges jEj by m. We often associate the set of vertices V with the set [n] := f1; : : : ; ng. 1 Hamiltonian Path Before discussing k-Path, it will be useful to first discuss algorithms for the famous NP-complete Hamiltonian path problem, which is the special case where k = n. Essentially all algorithms we discuss here can be adapted to obtain algorithms for k-Path! The naive algorithm for Hamiltonian Path takes time about n! = 2Θ(n log n) to try all possible permutations of the nodes (which can also be adapted to get an O?(k!)-time algorithm for k-Path, as we’ll see). -

Network Analysis of the Multimodal Freight Transportation System in New York City
Network Analysis of the Multimodal Freight Transportation System in New York City Project Number: 15 – 2.1b Year: 2015 FINAL REPORT June 2018 Principal Investigator Qian Wang Researcher Shuai Tang MetroFreight Center of Excellence University at Buffalo Buffalo, NY 14260-4300 Network Analysis of the Multimodal Freight Transportation System in New York City ABSTRACT The research is aimed at examining the multimodal freight transportation network in the New York metropolitan region to identify critical links, nodes and terminals that affect last-mile deliveries. Two types of analysis were conducted to gain a big picture of the region’s freight transportation network. First, three categories of network measures were generated for the highway network that carries the majority of last-mile deliveries. They are the descriptive measures that demonstrate the basic characteristics of the highway network, the network structure measures that quantify the connectivity of nodes and links, and the accessibility indices that measure the ease to access freight demand, services and activities. Second, 71 multimodal freight terminals were selected and evaluated in terms of their accessibility to major multimodal freight demand generators such as warehousing establishments. As found, the most important highways nodes that are critical in terms of connectivity and accessibility are those in and around Manhattan, particularly the bridges and tunnels connecting Manhattan to neighboring areas. Major multimodal freight demand generators, such as warehousing establishments, have better accessibility to railroad and marine port terminals than air and truck terminals in general. The network measures and findings in the research can be used to understand the inventory of the freight network in the system and to conduct freight travel demand forecasting analysis. -

Matroid Theory
MATROID THEORY HAYLEY HILLMAN 1 2 HAYLEY HILLMAN Contents 1. Introduction to Matroids 3 1.1. Basic Graph Theory 3 1.2. Basic Linear Algebra 4 2. Bases 5 2.1. An Example in Linear Algebra 6 2.2. An Example in Graph Theory 6 3. Rank Function 8 3.1. The Rank Function in Graph Theory 9 3.2. The Rank Function in Linear Algebra 11 4. Independent Sets 14 4.1. Independent Sets in Graph Theory 14 4.2. Independent Sets in Linear Algebra 17 5. Cycles 21 5.1. Cycles in Graph Theory 22 5.2. Cycles in Linear Algebra 24 6. Vertex-Edge Incidence Matrix 25 References 27 MATROID THEORY 3 1. Introduction to Matroids A matroid is a structure that generalizes the properties of indepen- dence. Relevant applications are found in graph theory and linear algebra. There are several ways to define a matroid, each relate to the concept of independence. This paper will focus on the the definitions of a matroid in terms of bases, the rank function, independent sets and cycles. Throughout this paper, we observe how both graphs and matrices can be viewed as matroids. Then we translate graph theory to linear algebra, and vice versa, using the language of matroids to facilitate our discussion. Many proofs for the properties of each definition of a matroid have been omitted from this paper, but you may find complete proofs in Oxley[2], Whitney[3], and Wilson[4]. The four definitions of a matroid introduced in this paper are equiv- alent to each other. -

Tree Structures
Tree Structures Definitions: o A tree is a connected acyclic graph. o A disconnected acyclic graph is called a forest o A tree is a connected digraph with these properties: . There is exactly one node (Root) with in-degree=0 . All other nodes have in-degree=1 . A leaf is a node with out-degree=0 . There is exactly one path from the root to any leaf o The degree of a tree is the maximum out-degree of the nodes in the tree. o If (X,Y) is a path: X is an ancestor of Y, and Y is a descendant of X. Root X Y CSci 1112 – Algorithms and Data Structures, A. Bellaachia Page 1 Level of a node: Level 0 or 1 1 or 2 2 or 3 3 or 4 Height or depth: o The depth of a node is the number of edges from the root to the node. o The root node has depth zero o The height of a node is the number of edges from the node to the deepest leaf. o The height of a tree is a height of the root. o The height of the root is the height of the tree o Leaf nodes have height zero o A tree with only a single node (hence both a root and leaf) has depth and height zero. o An empty tree (tree with no nodes) has depth and height −1. o It is the maximum level of any node in the tree. CSci 1112 – Algorithms and Data Structures, A. -

A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width
Introduction Preliminary Definitions Pathwidth Algorithm Summary A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width Kevin Cattell Michael J. Dinneen Michael R. Fellows Department of Computer Science University of Victoria Victoria, B.C. Canada V8W 3P6 Information Processing Letters 57 (1996) 197–203 Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Pathwidth Algorithm Summary Outline 1 Introduction Motivation History 2 Preliminary Definitions Boundaried graphs Path-decompositions Topological tree obstructions 3 Pathwidth Algorithm Main result Linear-time algorithm Proof of correctness Other results Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary Motivation Pathwidth is related to several VLSI layout problems: vertex separation link gate matrix layout edge search number ... Usefullness of bounded treewidth in: study of graph minors (Robertson and Seymour) input restrictions for many NP-complete problems (fixed-parameter complexity) Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary History General problem(s) is NP-complete Input: Graph G, integer t Question: Is tree/path-width(G) ≤ t? Algorithmic development (fixed t): O(n2) nonconstructive treewidth algorithm by Robertson and Seymour (1986) O(nt+2) treewidth algorithm due to Arnberg, Corneil and Proskurowski (1987) O(n log n) treewidth algorithm due to Reed (1992) 2 O(2t n) treewidth algorithm due to Bodlaender (1993) O(n log2 n) pathwidth algorithm due to Ellis, Sudborough and Turner (1994) Kevin Cattell, Michael J. Dinneen, Michael R. -

Networkx Reference Release 1.9.1
NetworkX Reference Release 1.9.1 Aric Hagberg, Dan Schult, Pieter Swart September 20, 2014 CONTENTS 1 Overview 1 1.1 Who uses NetworkX?..........................................1 1.2 Goals...................................................1 1.3 The Python programming language...................................1 1.4 Free software...............................................2 1.5 History..................................................2 2 Introduction 3 2.1 NetworkX Basics.............................................3 2.2 Nodes and Edges.............................................4 3 Graph types 9 3.1 Which graph class should I use?.....................................9 3.2 Basic graph types.............................................9 4 Algorithms 127 4.1 Approximation.............................................. 127 4.2 Assortativity............................................... 132 4.3 Bipartite................................................. 141 4.4 Blockmodeling.............................................. 161 4.5 Boundary................................................. 162 4.6 Centrality................................................. 163 4.7 Chordal.................................................. 184 4.8 Clique.................................................. 187 4.9 Clustering................................................ 190 4.10 Communities............................................... 193 4.11 Components............................................... 194 4.12 Connectivity.............................................. -

K-Path Centrality: a New Centrality Measure in Social Networks
Centrality Metrics in Social Network Analysis K-path: A New Centrality Metric Experiments Summary K-Path Centrality: A New Centrality Measure in Social Networks Adriana Iamnitchi University of South Florida joint work with Tharaka Alahakoon, Rahul Tripathi, Nicolas Kourtellis and Ramanuja Simha Adriana Iamnitchi K-Path Centrality: A New Centrality Measure in Social Networks 1 of 23 Centrality Metrics in Social Network Analysis Centrality Metrics Overview K-path: A New Centrality Metric Betweenness Centrality Experiments Applications Summary Computing Betweenness Centrality Centrality Metrics in Social Network Analysis Betweenness Centrality - how much a node controls the flow between any other two nodes Closeness Centrality - the extent a node is near all other nodes Degree Centrality - the number of ties to other nodes Eigenvector Centrality - the relative importance of a node Adriana Iamnitchi K-Path Centrality: A New Centrality Measure in Social Networks 2 of 23 Centrality Metrics in Social Network Analysis Centrality Metrics Overview K-path: A New Centrality Metric Betweenness Centrality Experiments Applications Summary Computing Betweenness Centrality Betweenness Centrality measures the extent to which a node lies on the shortest path between two other nodes betweennes CB (v) of a vertex v is the summation over all pairs of nodes of the fractional shortest paths going through v. Definition (Betweenness Centrality) For every vertex v 2 V of a weighted graph G(V ; E), the betweenness centrality CB (v) of v is defined by X X σst (v) CB -

Matroids You Have Known
26 MATHEMATICS MAGAZINE Matroids You Have Known DAVID L. NEEL Seattle University Seattle, Washington 98122 [email protected] NANCY ANN NEUDAUER Pacific University Forest Grove, Oregon 97116 nancy@pacificu.edu Anyone who has worked with matroids has come away with the conviction that matroids are one of the richest and most useful ideas of our day. —Gian Carlo Rota [10] Why matroids? Have you noticed hidden connections between seemingly unrelated mathematical ideas? Strange that finding roots of polynomials can tell us important things about how to solve certain ordinary differential equations, or that computing a determinant would have anything to do with finding solutions to a linear system of equations. But this is one of the charming features of mathematics—that disparate objects share similar traits. Properties like independence appear in many contexts. Do you find independence everywhere you look? In 1933, three Harvard Junior Fellows unified this recurring theme in mathematics by defining a new mathematical object that they dubbed matroid [4]. Matroids are everywhere, if only we knew how to look. What led those junior-fellows to matroids? The same thing that will lead us: Ma- troids arise from shared behaviors of vector spaces and graphs. We explore this natural motivation for the matroid through two examples and consider how properties of in- dependence surface. We first consider the two matroids arising from these examples, and later introduce three more that are probably less familiar. Delving deeper, we can find matroids in arrangements of hyperplanes, configurations of points, and geometric lattices, if your tastes run in that direction.