Network Working Group H. Birkholz Internet-Draft Fraunhofer SIT Intended Status: Informational C
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cumberland Tech Ref.Book
Forms Printer 258x/259x Technical Reference DRAFT document - Monday, August 11, 2008 1:59 pm Please note that this is a DRAFT document. More information will be added and a final version will be released at a later date. August 2008 www.lexmark.com Lexmark and Lexmark with diamond design are trademarks of Lexmark International, Inc., registered in the United States and/or other countries. © 2008 Lexmark International, Inc. All rights reserved. 740 West New Circle Road Lexington, Kentucky 40550 Draft document Edition: August 2008 The following paragraph does not apply to any country where such provisions are inconsistent with local law: LEXMARK INTERNATIONAL, INC., PROVIDES THIS PUBLICATION “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do not allow disclaimer of express or implied warranties in certain transactions; therefore, this statement may not apply to you. This publication could include technical inaccuracies or typographical errors. Changes are periodically made to the information herein; these changes will be incorporated in later editions. Improvements or changes in the products or the programs described may be made at any time. Comments about this publication may be addressed to Lexmark International, Inc., Department F95/032-2, 740 West New Circle Road, Lexington, Kentucky 40550, U.S.A. In the United Kingdom and Eire, send to Lexmark International Ltd., Marketing and Services Department, Westhorpe House, Westhorpe, Marlow Bucks SL7 3RQ. Lexmark may use or distribute any of the information you supply in any way it believes appropriate without incurring any obligation to you. -

PCL PC-8, Code Page 437 Page 1 of 5 PCL PC-8, Code Page 437
PCL PC-8, Code Page 437 Page 1 of 5 PCL PC-8, Code Page 437 PCL Symbol Set: 10U Unicode glyph correspondence tables. Contact:[email protected] http://pcl.to -- -- -- -- $90 U00C9 Ê Uppercase e acute $21 U0021 Ë Exclamation $91 U00E6 Ì Lowercase ae diphthong $22 U0022 Í Neutral double quote $92 U00C6 Î Uppercase ae diphthong $23 U0023 Ï Number $93 U00F4 & Lowercase o circumflex $24 U0024 ' Dollar $94 U00F6 ( Lowercase o dieresis $25 U0025 ) Per cent $95 U00F2 * Lowercase o grave $26 U0026 + Ampersand $96 U00FB , Lowercase u circumflex $27 U0027 - Neutral single quote $97 U00F9 . Lowercase u grave $28 U0028 / Left parenthesis $98 U00FF 0 Lowercase y dieresis $29 U0029 1 Right parenthesis $99 U00D6 2 Uppercase o dieresis $2A U002A 3 Asterisk $9A U00DC 4 Uppercase u dieresis $2B U002B 5 Plus $9B U00A2 6 Cent sign $2C U002C 7 Comma, decimal separator $9C U00A3 8 Pound sterling $2D U002D 9 Hyphen $9D U00A5 : Yen sign $2E U002E ; Period, full stop $9E U20A7 < Pesetas $2F U002F = Solidus, slash $9F U0192 > Florin sign $30 U0030 ? Numeral zero $A0 U00E1 ê Lowercase a acute $31 U0031 A Numeral one $A1 U00ED B Lowercase i acute $32 U0032 C Numeral two $A2 U00F3 D Lowercase o acute $33 U0033 E Numeral three $A3 U00FA F Lowercase u acute $34 U0034 G Numeral four $A4 U00F1 H Lowercase n tilde $35 U0035 I Numeral five $A5 U00D1 J Uppercase n tilde $36 U0036 K Numeral six $A6 U00AA L Female ordinal (a) http://www.pclviewer.com (c) RedTitan Technology 2005 PCL PC-8, Code Page 437 Page 2 of 5 $37 U0037 M Numeral seven $A7 U00BA N Male ordinal (o) $38 U0038 -

Bibliography of Erik Wilde
dretbiblio dretbiblio Erik Wilde's Bibliography References [1] AFIPS Fall Joint Computer Conference, San Francisco, California, December 1968. [2] Seventeenth IEEE Conference on Computer Communication Networks, Washington, D.C., 1978. [3] ACM SIGACT-SIGMOD Symposium on Principles of Database Systems, Los Angeles, Cal- ifornia, March 1982. ACM Press. [4] First Conference on Computer-Supported Cooperative Work, 1986. [5] 1987 ACM Conference on Hypertext, Chapel Hill, North Carolina, November 1987. ACM Press. [6] 18th IEEE International Symposium on Fault-Tolerant Computing, Tokyo, Japan, 1988. IEEE Computer Society Press. [7] Conference on Computer-Supported Cooperative Work, Portland, Oregon, 1988. ACM Press. [8] Conference on Office Information Systems, Palo Alto, California, March 1988. [9] 1989 ACM Conference on Hypertext, Pittsburgh, Pennsylvania, November 1989. ACM Press. [10] UNIX | The Legend Evolves. Summer 1990 UKUUG Conference, Buntingford, UK, 1990. UKUUG. [11] Fourth ACM Symposium on User Interface Software and Technology, Hilton Head, South Carolina, November 1991. [12] GLOBECOM'91 Conference, Phoenix, Arizona, 1991. IEEE Computer Society Press. [13] IEEE INFOCOM '91 Conference on Computer Communications, Bal Harbour, Florida, 1991. IEEE Computer Society Press. [14] IEEE International Conference on Communications, Denver, Colorado, June 1991. [15] International Workshop on CSCW, Berlin, Germany, April 1991. [16] Third ACM Conference on Hypertext, San Antonio, Texas, December 1991. ACM Press. [17] 11th Symposium on Reliable Distributed Systems, Houston, Texas, 1992. IEEE Computer Society Press. [18] 3rd Joint European Networking Conference, Innsbruck, Austria, May 1992. [19] Fourth ACM Conference on Hypertext, Milano, Italy, November 1992. ACM Press. [20] GLOBECOM'92 Conference, Orlando, Florida, December 1992. IEEE Computer Society Press. http://github.com/dret/biblio (August 29, 2018) 1 dretbiblio [21] IEEE INFOCOM '92 Conference on Computer Communications, Florence, Italy, 1992. -

CBOR (RFC 7049) Concise Binary Object Representation
CBOR (RFC 7049) Concise Binary Object Representation Carsten Bormann, 2015-11-01 1 CBOR: Agenda • What is it, and when might I want it? • How does it work? • How do I work with it? 2 CBOR: Agenda • What is it, and when might I want it? • How does it work? • How do I work with it? 3 Slide stolen from Douglas Crockford History of Data Formats • Ad Hoc • Database Model • Document Model • Programming Language Model Box notation TLV 5 XML XSD 6 Slide stolen from Douglas Crockford JSON • JavaScript Object Notation • Minimal • Textual • Subset of JavaScript Values • Strings • Numbers • Booleans • Objects • Arrays • null Array ["Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"] [ [0, -1, 0], [1, 0, 0], [0, 0, 1] ] Object { "name": "Jack B. Nimble", "at large": true, "grade": "A", "format": { "type": "rect", "width": 1920, "height": 1080, "interlace": false, "framerate": 24 } } Object Map { "name": "Jack B. Nimble", "at large": true, "grade": "A", "format": { "type": "rect", "width": 1920, "height": 1080, "interlace": false, "framerate": 24 } } JSON limitations • No binary data (byte strings) • Numbers are in decimal, some parsing required • Format requires copying: • Escaping for strings • Base64 for binary • No extensibility (e.g., date format?) • Interoperability issues • I-JSON further reduces functionality (RFC 7493) 12 BSON and friends • Lots of “binary JSON” proposals • Often optimized for data at rest, not protocol use (BSON ➔ MongoDB) • Most are more complex than JSON 13 Why a new binary object format? • Different design goals from current formats – stated up front in the document • Extremely small code size – for work on constrained node networks • Reasonably compact data size – but no compression or even bit-fiddling • Useful to any protocol or application that likes the design goals 14 Concise Binary Object Representation (CBOR) 15 “Sea Boar” “Sea Boar” 16 Design goals (1 of 2) 1. -

Bookings of Westin Diplomat Bookings
RESTful Web Applications with Spring 3.0 Arjen Poutsma Senior Software Engineer SpringSource Speaker’s qualifications • Fifteen years of experience in Enterprise Software Development • Six years of Web service experience • Development lead of Spring Web Services • Working on Spring 3.0 • Contributor to various Open Source frameworks: (XFire, Axis2, NEO, ...) SpringSource Confidential. Do not distribute without express permission Overview • RESTful URLs • URI templates • Content negotiation • HTTP method conversion • ETag support SpringSource Confidential. Do not distribute without express permission RESTful URLs Resources • URLs are unique identifiers for Resources • Typically nouns • Customer • Orders • Shopping cart URLs [scheme:][//authority][path][?query][#fragment] http://www.springsource.com https://mybank.com http://www.google.com/search?q=arjen %20poutsma http://java.sun.com/j2se/1.4.2/docs/api/java/lang/ String.html#indexOf(int) SpringSource Confidential. Do not distribute without express permission Paths • Represents hierarchy • Represents value for consumers • Collections on higher levels SpringSource Confidential. Do not distribute without express permission Example Path Description /hotels List of all hotels /hotels/westindiplomat Details of Westin Diplomat /hotels/westindiplomat/ List of bookings of Westin Diplomat bookings /hotels/westindiplomat/ Individual booking bookings/42584 No Hierarchy? Path Description maps/24.9195,17.821 Commas maps/24.9195;17.821 Semicolons Query Variables • Input for algorithms • Get ignored by proxies -

Bitmap Fonts
.com Bitmap Fonts 1 .com Contents Introduction .................................................................................................................................................. 3 Writing Code to Write Code.......................................................................................................................... 4 Measuring Your Grid ..................................................................................................................................... 5 Converting an Image with PHP ..................................................................................................................... 6 Step 1: Load the Image ............................................................................................................................. 6 Step 2: Scan the Image .............................................................................................................................. 7 Step 3: Save the Header File ..................................................................................................................... 8 The 1602 Character Set ............................................................................................................................... 10 The 1602 Character Map ............................................................................................................................ 11 Converting the Image to Code .................................................................................................................... 12 Conclusion -
UK Research Data Registry Mapping Schemes
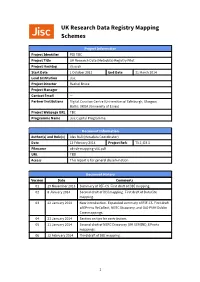
UK Research Data Registry Mapping Schemes Project Information Project Identifier PID TBC Project Title UK Research Data (Metadata) Registry Pilot Project Hashtag #jiscrdr Start Date 1 October 2013 End Date 31 March 2014 Lead Institution Jisc Project Director Rachel Bruce Project Manager — Contact Email — Partner Institutions Digital Curation Centre (Universities of Edinburgh, Glasgow, Bath); UKDA (University of Essex) Project Webpage URL TBC Programme Name Jisc Capital Programme Document Information Author(s) and Role(s) Alex Ball (Metadata Coordinator) Date 12 February 2014 Project Refs T3.1; D3.1 Filename uk-rdr-mapping-v06.pdf URL TBD Access This report is for general dissemination Document History Version Date Comments 01 29 November 2013 Summary of RIF-CS. First draft of DDI mapping. 02 8 January 2014 Second draft of DDI mapping. First draft of DataCite mapping. 03 22 January 2014 New introduction. Expanded summary of RIF-CS. First draft of EPrints ReCollect, NERC Discovery, and OAI-PMH Dublin Core mappings. 04 23 January 2014 Section on tips for contributors. 05 31 January 2014 Second draft of NERC Discovery (UK GEMINI), EPrints mappings. 06 12 February 2014 Third draft of DDI mapping. 1 Contents 1 Introduction 3 1.1 Typographical conventions . 3 2 RIF-CS 4 2.1 Elements . 4 2.2 Controlled vocabularies . 8 3 Internally managed RIF-CS elements 20 4 Mapping from DDI to RIF-CS 21 4.1 Related Objects . 22 5 Mapping from UK GEMINI 2 to RIF-CS 24 5.1 Related Objects . 26 6 Mapping from DataCite to RIF-CS 27 6.1 Related Objects . -

Gemini and NTS Exit Reform API Usage Guidelines
Gemini and NTS Exit Reform API Usage Guidelines ~ 1 ~ Table of Contents 1. Introduction ............................................................................................................................................6 1.1. API Technology Overview ....................................................................................................................6 2. API Client Development Guidelines .....................................................................................................8 2.1. HTTPS and SSL ...................................................................................................................................9 2.2. Authentication and Authorization ...................................................................................................... 10 2.3. Maintaining the Session .................................................................................................................... 10 2.4. Authentication / Loss of Session / Authorization Failures ................................................................. 10 2.5. Request a Compressed Response to your API Client ...................................................................... 11 3. API Configuration Details ................................................................................................................... 14 3.1. API Technology Overview ................................................................................................................. 14 3.2. Network Requirements ..................................................................................................................... -

User Guide IGP for SIDM Printers
User Guide IGP for Dot Matrix Printers Mantenimiento Periféricos Informaticos C/Canteras, 15 28860 Paracauellos de Jarama (Madrid) Tel: 00 34 917481604 Web: https://mpi.com.es/ IGP for Dot Matrix Printers User Guide Scope This User Guide is to be considered as an enhancement to the standard documentation of your printer. Hence keep the printer’s standard documentation ready as your particular printer model is pictured in detail. 2 Mantenimiento Periféricos Informaticos C/Canteras, 15 28860 Paracauellos de Jarama (Madrid) Tel: 00 34 917481604 Web: https://mpi.com.es/ Table of Contents Table of Contents Subject Listing SCOPE........................................................................................................................................................... 2 CHAPTER 1: CONTROL PANEL ............................................................................................................ 7 BASIC ELEMENTS ........................................................................................................................................ 7 MENU STRUCTURE ...................................................................................................................................... 8 MENU PARAMETERS.................................................................................................................................... 9 MENU PRINTOUT EXAMPLE....................................................................................................................... 17 WEBPANEL ENHANCEMENTS ................................................................................................................... -

Forms Printer 248X/249X
Forms Printer 248x/249x Technical Reference October 2000 www.lexmark.com Third Edition (October 2000) The following paragraph does not apply to the United Kingdom or any country where such provisions are inconsistent with local law: LEXMARK INTERNA- TIONAL, INC. PROVIDES THIS PUBLICATION “AS IS” WITHOUT WAR- RANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do not allow disclaimer of express or implied warranties in certain transactions, therefore, this statement may not apply to you. This publication could include technical inaccuracies or typographical errors. Changes are periodically made to the information herein; these changes will be incorporated in later editions of the publication. Improvements and/or changes in the product(s) and/or the program(s) described in this publication may be made at any time. Publications are not stocked at the address given below; requests for publications should be made to your point of purchase. A form for reader's comments is provided at the back of this publication. If the form has been removed, comments may be addressed to Lexmark International, Inc., Department F95/035-3, 740 New Circle Road N.W., Lexington, Kentucky 40511-1876, U.S.A. Lexmark may use or distribute any of the information you sup- ply in any way it believes appropriate without incurring any obligation to you. Lexmark is a trademark of Lexmark International, Inc. Other trademarks are the property of their respective owners. © Copyright Lexmark International, Inc. 1993, 2000. All rights reserved. UNITED STATES GOVERNMENT RESTRICTED RIGHTS This software and documentation are provided with RESTRICTED RIGHTS. -

Decentralized Identifier WG F2F Sessions
Decentralized Identifier WG F2F Sessions Day 1: January 29, 2020 Chairs: Brent Zundel, Dan Burnett Location: Microsoft Schiphol 1 Welcome! ● Logistics ● W3C WG IPR Policy ● Agenda ● IRC and Scribes ● Introductions & Dinner 2 Logistics ● Location: “Spaces”, 6th floor of Microsoft Schiphol ● WiFi: SSID Publiek_theOutlook, pwd Hello2020 ● Dial-in information: +1-617-324-0000, Meeting ID ● Restrooms: End of the hall, turn right ● Meeting time: 8 am - 5 pm, Jan. 29-31 ● Breaks: 10:30-11 am, 12:30-1:30 pm, 2:30-3 pm ● DID WG Agenda: https://tinyurl.com/didwg-ams2020-agenda (HTML) ● Live slides: https://tinyurl.com/didwg-ams2020-slides (Google Slides) ● Dinner Details: See the “Dinner Tonight” slide at the end of each day 3 W3C WG IPR Policy ● This group abides by the W3C patent policy https://www.w3.org/Consortium/Patent-Policy-20040205 ● Only people and companies listed at https://www.w3.org/2004/01/pp-impl/117488/status are allowed to make substantive contributions to the specs ● Code of Conduct https://www.w3.org/Consortium/cepc/ 4 Today’s agenda 8:00 Breakfast 8:30 Welcome, Introductions, and Logistics Chairs 9:00 Level setting Chairs 9:30 Security issues Brent 10:15 DID and IoT Sam Smith 10:45 Break 11:00 Multiple Encodings/Different Syntaxes: what might we want to support Markus 11:30 Different encodings: model incompatibilities Manu 12:00 Abstract data modeling options Dan Burnett 12:30 Lunch (brief “Why Are We Here?” presentation) Christopher Allen 13:30 DID Doc Extensibility via Registries Mike 14:00 DID Doc Extensibility via JSON-LD Manu -

Interoperability for the Semantic Web: a Loosely Coupled Mediation Approach Antoine Zimmermann
Interoperability for the Semantic Web: A Loosely Coupled Mediation Approach Antoine Zimmermann To cite this version: Antoine Zimmermann. Interoperability for the Semantic Web: A Loosely Coupled Mediation Ap- proach. Modeling and Simulation. Université Jean Monnet, 2021. tel-03163932 HAL Id: tel-03163932 https://tel.archives-ouvertes.fr/tel-03163932 Submitted on 9 Mar 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. These` d'habilitation Universite´ Jean Monnet Ecole´ doctorale 488 Sciences, Ing´enierieet Sant´e(SIS) Interop´erabilit´epour le Web s´emantique : une approche par m´ediationfaiblement coupl´ee Soutenue publiquement par : Antoine Zimmermann MINES Saint-Etienne´ Membres du jury : Olivier Boissier Professeur, MINES Saint-Etienne´ Tuteur de recherche Pierre-Antoine Champin Ma^ıtrede conf´erenceHDR, Universit´eClaude-Bernard Examinateur J´er^ome Euzenat Directeur de recherche, Inria Examinateur Fabien Gandon Directeur de recherche, Inria Rapporteur Andreas Harth Professeur, Friedrich-Alexander-Universit¨atErlangen-N¨urnberg Rapporteur