Genome-Wide Association of Familial Late-Onset Alzheimer's Disease Replicates BIN1 and CLU and Nominates CUGBP2 in Interaction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

NIH Public Access Author Manuscript Pharmacogenet Genomics
NIH Public Access Author Manuscript Pharmacogenet Genomics. Author manuscript; available in PMC 2012 September 01. NIH-PA Author ManuscriptPublished NIH-PA Author Manuscript in final edited NIH-PA Author Manuscript form as: Pharmacogenet Genomics. 2011 September ; 21(9): 607–613. doi:10.1097/FPC.0b013e3283415515. PharmGKB summary: very important pharmacogene information for PTGS2 Caroline F. Thorna, Tilo Grosserc, Teri E. Kleina, and Russ B. Altmana,b aDepartment of Genetics, Stanford University Medical Center, Stanford, California bDepartment of Bioengineering, Stanford University Medical Center, Stanford, California cInstitute for Translational Medicine and Therapeutics, University of Pennsylvania, Pennsylvania, USA Keywords cyclooxygenase-2; coxibs; non-steroidal anti-inflammatory drugs; pharmacogenomics; PTGS2; rs20417; rs5275; rs689466 Very important pharmacogene: PTGS2 This PharmGKB summary briefly discusses the PTGS2 gene and current understanding of its function, structure, regulation, and pharmacogenomic relevance. We also present three variants with pharmacogenomic significance and highlight the gaps in our knowledge of PTGS2-drug interactions. Overview The PTGS2 gene codes for prostaglandin G/H synthase-2, which catalyses the first two steps in the metabolism of arachadonic acid. Prostaglandin G/H synthase-2 has two active sites, a hydroperoxidase and a cyclooxygenase (COX) site, and is colloquially termed COX-2. The bifunctional enzyme performs the bis-dioxygenation and reduction of arachadonic acid to form prostaglandin (PG)G2 and H2. PGH2 is then converted to other PGs that modulate inflammation, including PGD2, PGE2, PGF2α, PGI2, and thromboxane A2 (This pathway is shown in the Lipid maps database at http://www.lipidmaps.org/data/IntegratedPathways Data/SetupIntegratedPathways.pl? imgsize=730&Mode=RAW2647&DataType=FAEicosanoidsMedia). COX-2 is the target for nonsteroidal anti-inflammatory drugs (NSAIDS) including those that were purposefully designed (pd) to be selective for COX-2 (pdNSAIDs or coxibs). -

Molecular Genetic Analysis of Rbm45/Drbp1: Genomic Structure, Expression, and Evolution Lauren E
Journal of Student Research (2018) Volume 7, Issue 2, pp 49-61 Research Article Molecular Genetic Analysis of Rbm45/Drbp1: Genomic Structure, Expression, and Evolution Lauren E. Pricea,f, Abigail B. Loewen Faulb,f, Aleksandra Vuchkovskaa, Kevin J. Lopeza, Katie M. Fastb, Andrew G. Ecka, David W. Hoferera,e, and Jeffrey O. Hendersona,b,c,d,g RNA recognition motif-type RNA-binding domain containing proteins (RBDPs) participate in RNA metabolism including regulating mRNA stability, nuclear-cytoplasmic shuttling, and splicing. Rbm45 is an RBDP first cloned from rat brain and expressed spatiotemporally during rat neural development. More recently, RBM45 has been associated with pathological aggregates in the human neurological disorders amyotrophic lateral sclerosis, frontotemporal lobar degeneration, and Alzheimer’s. Rbm45 and the neural developmental protein musashi-1 are in the same family of RDBPs and have similar expression patterns. In contrast to Musashi-1, which is upregulated during colorectal carcinogenesis, we found no association of RBM45 overexpression in human colon cancer tissue. In order to begin characterizing RNA-binding partners of Rbm45, we have successfully cloned and expressed human RBM45 in an Intein fusion-protein expression system. Furthermore, to gain a better understanding of the molecular genetics and evolution of Rbm45, we used an in silico approach to analyze the gene structure of the human and mouse Rbm45 homologues and explored the evolutionary conservation of Rbm45 in metazoans. Human RBM45 and mouse Rbm45 span ~17 kb and 13 kb, respectively, and contain 10 exons, one of which is non-coding. Both genes have TATA-less promoters with an initiator and a GC-rich element. -

CELF RNA Binding Proteins Promote Axon Regeneration in C. Elegans and Mammals 1 Through Alternative Splicing of Syntaxins 2 Lizh
1 CELF RNA binding proteins promote axon regeneration in C. elegans and mammals 2 through alternative splicing of Syntaxins 3 Lizhen Chen1,2,§, Zhijie Liu3, Bing Zhou4, Chaoliang Wei4, Yu Zhou4, Michael G. Rosenfeld2,3, 4 Xiangdong Fu4, Andrew D. Chisholm1,*, Yishi Jin1,2,4,* 5 6 1 Section of Neurobiology, Division of Biological Sciences, University of California, San Diego, 7 La Jolla, CA92093 8 2 Howard Hughes Medical Institute, University of California, San Diego, La Jolla, CA 9 92093 10 3 Department of Medicine, School of Medicine, University of California, San Diego, La Jolla, CA 11 92093 12 4 Department of Cellular and Molecular Medicine, School of Medicine, University of California, 13 San Diego, La Jolla, CA 92093 14 15 * to whom correspondence should be addressed 16 § Current address: Barshop Institute for Longevity and Aging Studies, Department of Cellular 17 and Structural Biology, University of Texas Health Science Center San Antonio, San Antonio, 18 Texas 78245 19 With 7 Figures, 3 Videos, 9 figure supplements, 7 Supplementary Files 20 Key words: UNC-75, CLIP-seq, alternative splicing, SNARE, DRG, CUGBP, ETR3 21 1 22 Abstract 23 Axon injury triggers dramatic changes in gene expression. While transcriptional regulation 24 of injury-induced gene expression is widely studied, less is known about the roles of RNA 25 binding proteins (RBPs) in post-transcriptional regulation during axon regeneration. In C. 26 elegans the CELF (CUGBP and Etr-3 Like Factor) family RBP UNC-75 is required for axon 27 regeneration. Using crosslinking immunoprecipitation coupled with deep sequencing (CLIP-seq) 28 we identify a set of genes involved in synaptic transmission as mRNA targets of UNC-75. -

Supplementary Tables S1-S3
Supplementary Table S1: Real time RT-PCR primers COX-2 Forward 5’- CCACTTCAAGGGAGTCTGGA -3’ Reverse 5’- AAGGGCCCTGGTGTAGTAGG -3’ Wnt5a Forward 5’- TGAATAACCCTGTTCAGATGTCA -3’ Reverse 5’- TGTACTGCATGTGGTCCTGA -3’ Spp1 Forward 5'- GACCCATCTCAGAAGCAGAA -3' Reverse 5'- TTCGTCAGATTCATCCGAGT -3' CUGBP2 Forward 5’- ATGCAACAGCTCAACACTGC -3’ Reverse 5’- CAGCGTTGCCAGATTCTGTA -3’ Supplementary Table S2: Genes synergistically regulated by oncogenic Ras and TGF-β AU-rich probe_id Gene Name Gene Symbol element Fold change RasV12 + TGF-β RasV12 TGF-β 1368519_at serine (or cysteine) peptidase inhibitor, clade E, member 1 Serpine1 ARE 42.22 5.53 75.28 1373000_at sushi-repeat-containing protein, X-linked 2 (predicted) Srpx2 19.24 25.59 73.63 1383486_at Transcribed locus --- ARE 5.93 27.94 52.85 1367581_a_at secreted phosphoprotein 1 Spp1 2.46 19.28 49.76 1368359_a_at VGF nerve growth factor inducible Vgf 3.11 4.61 48.10 1392618_at Transcribed locus --- ARE 3.48 24.30 45.76 1398302_at prolactin-like protein F Prlpf ARE 1.39 3.29 45.23 1392264_s_at serine (or cysteine) peptidase inhibitor, clade E, member 1 Serpine1 ARE 24.92 3.67 40.09 1391022_at laminin, beta 3 Lamb3 2.13 3.31 38.15 1384605_at Transcribed locus --- 2.94 14.57 37.91 1367973_at chemokine (C-C motif) ligand 2 Ccl2 ARE 5.47 17.28 37.90 1369249_at progressive ankylosis homolog (mouse) Ank ARE 3.12 8.33 33.58 1398479_at ryanodine receptor 3 Ryr3 ARE 1.42 9.28 29.65 1371194_at tumor necrosis factor alpha induced protein 6 Tnfaip6 ARE 2.95 7.90 29.24 1386344_at Progressive ankylosis homolog (mouse) -

(CELF1), an RNA Binding Protein
ROLES OF CUG-BP, ELAV-LIKE FAMILY MEMBER 1 (CELF1), AN RNA BINDING PROTEIN, DURING VERTEBRATE HEART DEVELOPMENT by YOTAM N. BLECH-HERMONI Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy Advisor: Dr. Andrea N. Ladd Program in Cell Biology, Department of Molecular Biology and Microbiology, School of Medicine CASE WESTERN RESERVE UNIVERSITY January 2015 CASE WESTERN RESERVE UNIVERSITY SCHOOL OF GRADUATE STUDIES We hereby approve the dissertation of Yotam N. Blech-Hermoni Candidate for the degree of Doctor of Philosophy*. Committee Chair Dr. Donna M. Driscoll Committee Member Dr. Alan M. Tartakoff Committee Member Dr. Hua Lou Date of Defense November 20, 2014 *Published material is included in accordance with contracts and stipulations set forth by the publishers. i Table of Contents List of Tables ........................................................................................................................... vii List of Figures ........................................................................................................................ viii Acknowledgements ................................................................................................................. x List of Abbreviations ............................................................................................................. xi Abstract ................................................................................................................................... xiv Chapter 1: Introduction ....................................................................................................... -

Micrornas Coordinate an Alternative Splicing Network During Mouse Postnatal Heart Development
Downloaded from genesdev.cshlp.org on October 4, 2021 - Published by Cold Spring Harbor Laboratory Press RESEARCH COMMUNICATION genes are alternatively spliced, and more than half of alter- MicroRNAs coordinate an native splicing events differ between tissues, revealing an alternative splicing network extensive level of regulation (Castle et al. 2008; Pan et al. 2008; Wang et al. 2008). during mouse postnatal heart The mammalian heart undergoes a period of dramatic remodeling during the first 3 wk after birth that requires development transcriptional and post-transcriptional regulatory pro- Auinash Kalsotra,1 Kun Wang,2 Pei-Feng Li,2 grams not yet fully understood (Xu et al. 2005; Olson 1,3,4 2006). We recently identified a conserved set of alternative and Thomas A. Cooper splicing transitions during mouse heart development, and 1Department of Pathology and Immunology, Baylor College demonstrated that nearly half are responsive to the CUGBP of Medicine, Houston, Texas 77030, USA; 2Division of and ETR-3-like factor (CELF) family of splicing regulators Cardiovascular Research, National Key Laboratory of (Kalsotra et al. 2008). Two CELF proteins, CUGBP1 and Biomembrane and Membrane Biotechnology, Institute of CUGBP2, are highly expressed in the fetal heart, but are Zoology, Chinese Academy of Sciences, Beijing 100101, down-regulated >10 fold within 3 wk after birth without People’s Republic of China; 3Department of Molecular and a change in mRNA levels. Cellular Biology, Baylor College of Medicine, Houston, Texas Here we used targeted deletion of the Dicer gene 77030, USA specifically in adult mouse myocardium to test the role of miRNAs in the mechanism of CELF protein down- Alternative splicing transitions have been identified re- regulation during postnatal development. -

Chromosome Instability, Chromosome Transcriptome, and Clonal Evolution of Tumor Cell Populations
Chromosome instability, chromosome transcriptome, and clonal evolution of tumor cell populations ChongFeng Gao*, Kyle Furge†, Julie Koeman‡, Karl Dykema†, Yanli Su*, Mary Lou Cutler§, Adam Werts*, Pete Haak¶, and George F. Vande Woude*ʈ Laboratories of *Molecular Oncology, †Computational Biology, ‡Germline Modification, and ¶Microarray Technology, Van Andel Research Institute, 333 Bostwick Avenue, N.E., Grand Rapids, MI 49503; and §University Services University of the Health Sciences, 4301 Jones Bridge Road, Bethesda, MD 20814 Edited by Janet D. Rowley, University of Chicago Medical Center, Chicago, IL, and approved March 29, 2007 (received for review January 23, 2007) Chromosome instability and aneuploidy are hallmarks of cancer, Phenotypic switching is fundamental for malignant progression but it is not clear how changes in the chromosomal content of a cell (6), and therefore it is important to understand the responsible contribute to the malignant phenotype. Previously we have shown mechanisms. that we can readily isolate highly proliferative tumor cells and their Glioblastomas characteristically show extensive regional cytoge- revertants from highly invasive tumor cell populations, indicating netic heterogeneity (10, 11), and this diversity may be responsible how phenotypic shifting can contribute to malignant progression. for tumor evolution and progression (10, 12). Here we show that Here we show that chromosome instability and changes in chro- distinct changes in karyotype from chromosome instability accom- mosome content occur with phenotypic switching. Further, we pany phenotypic switching. These changes, in turn, dictate changes show that changes in the copy number of each chromosome in the chromosome transcriptome that provide the expression of quantitatively impose a proportional change in the chromosome individual genes that are necessary for the conversion between the transcriptome ratio. -

Gene Section Review
Atlas of Genetics and Cytogenetics in Oncology and Haematology INIST -CNRS OPEN ACCESS JOURNAL Gene Section Review CELF2 (CUGBP, Elav-like family member 2) Satish Ramalingam, Shrikant Anant Department of Molecular and Integrative Physiology, Kansas University Medical Center, Kansas City, KS, USA (SR, SA) Published in Atlas Database: May 2014 Online updated version : http://AtlasGeneticsOncology.org/Genes/CELF2ID52815ch10p14.html DOI: 10.4267/2042/56292 This work is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 2.0 France Licence. © 2015 Atlas of Genetics and Cytogenetics in Oncology and Haematology Abstract Location: 10p14 Note: Size: 331416 bases. Orientation: plus strand. CELF2 belongs to the family of RNA binding This gene is encoded by a gene located on proteins implicated in mRNA splicing, editing, chromosome 10p13-p14 between Généthon stability and translation. markers D10S547 and D10S223 (Li et al., 2001). This gene is encoded in a single large gene spanning over 159 kilo bases located on DNA/RNA chromosome 10 p13-p14 (between D10S547 and D10S223). Description This gene has 14 transcripts (splice variants) and The human CELF2 gene contains 14 exons the 3 major splice variants have distinct exon 1. spanning over approximately 159 kb of the This is an evolutionarily conserved ubiquitously genomic DNA. expressed protein. The members of the CELF protein family contain two N-terminal RNA Transcription recognition motif (RRM) domains and one C- Alternative promoters usage of CELF2 gene results terminal RRM domain, and a divergent segment of in three transcript variants, where the variants 2 and 160-230 amino acids between second and third 3 proteins have distinct exon 1 resulting in different RRM domains. -

Curcumin Modulates the Apolipoprotein B Mrna Editing By
Korean J Physiol Pharmacol 2019;23(3):181-189 https://doi.org/10.4196/kjpp.2019.23.3.181 Original Article Curcumin modulates the apolipoprotein B mRNA editing by coordinating the expression of cytidine deamination to uridine editosome components in primary mouse hepatocytes Pan He and Nan Tian* Institute of Molecular Medicine, Life Science College, Zhejiang Chinese Medical University, Hangzhou 310053, Zhejiang, China ARTICLE INFO ABSTRACT Curcumin, an active ingredient of Curcuma longa L., can reduce the Received June 23, 2018 Revised August 14, 2018 concentration of low-density lipoproteins in plasma, in different ways. We had first Accepted September 12, 2018 reported that curcumin exhibits hypocholesterolemic properties by improving the apolipoprotein B (apoB) mRNA editing in primary rat hepatocytes. However, the role *Correspondence of curcumin in the regulation of apoB mRNA editing is not clear. Thus, we investigat- Nan Tian ed the effect of curcumin on the expression of multiple editing components of apoB E-mail: [email protected] mRNA cytidine deamination to uridine (C-to-U) editosome. Our results demonstrated that treatment with 50 μM curcumin markedly increased the amount of edited apoB Key Words mRNA in primary mouse hepatocytes from 5.13%–8.05% to 27.63%–35.61%, and sig- APOBEC-1 nificantly elevated the levels of the core components apoB editing catalytic polypep- Curcumin tide-1 (APOBEC-1), apobec-1 complementation factor (ACF), and RNA-binding-motif- Hepatocytes RNA editing protein-47 (RBM47), as well as suppressed the level of the inhibitory component glycine-arginine-tyrosine-rich RNA binding protein. Moreover, the increased apoB RNA editing by 50 μM curcumin was significantly reduced by siRNA-mediated APO- BEC-1, ACF, and RBM47 knockdown. -

Functional Requirements of AID's Higher Order Structures And
Functional requirements of AID’s higher order PNAS PLUS structures and their interaction with RNA-binding proteins Samiran Mondala, Nasim A. Beguma, Wenjun Hua, and Tasuku Honjoa,1 aDepartment of Immunology and Genomic Medicine, Graduate School of Medicine, Kyoto University, Yoshida Sakyo-ku, Kyoto 606-8501, Japan Contributed by Tasuku Honjo, February 3, 2016 (sent for review October 27, 2015; reviewed by Atsushi Miyawaki and Kazuko Nishikura) Activation-induced cytidine deaminase (AID) is essential for the interaction, enabling AID to exert distinct physiological functions somatic hypermutation (SHM) and class-switch recombination (CSR) through its association with cofactors. Regrettably, however, there of Ig genes. Although both the N and C termini of AID have unique is little structural information available that can explain any of functions in DNA cleavage and recombination, respectively, during AID’s regulatory modes of action, including its cofactor association SHM and CSR, their molecular mechanisms are poorly understood. mechanisms, in the context of its physiological functions. Using a bimolecular fluorescence complementation (BiFC) assay Although a significant amount of structural information is available combined with glycerol gradient fractionation, we revealed that for a number of APOBEC family members, the 3D structures of A1 the AID C terminus is required for a stable dimer formation. Further- and AID are yet to be resolved (19, 20). The CDD family of enzymes more, AID monomers and dimers form complexes with distinct exists in nature in a variety of structural forms, including monomeric, dimeric, and tetrameric forms, and comparative structural modeling heterogeneous nuclear ribonucleoproteins (hnRNPs). AID monomers using the yeast CDD structure predicts a dimeric structure for both associate with DNA cleavage cofactor hnRNP K whereas AID dimers A1 and AID (21, 22). -
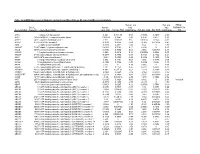
Mrna Expression in Human Leiomyoma and Eker Rats As Measured by Microarray Analysis
Table 3S: mRNA Expression in Human Leiomyoma and Eker Rats as Measured by Microarray Analysis Human_avg Rat_avg_ PENG_ Entrez. Human_ log2_ log2_ RAPAMYCIN Gene.Symbol Gene.ID Gene Description avg_tstat Human_FDR foldChange Rat_avg_tstat Rat_FDR foldChange _DN A1BG 1 alpha-1-B glycoprotein 4.982 9.52E-05 0.68 -0.8346 0.4639 -0.38 A1CF 29974 APOBEC1 complementation factor -0.08024 0.9541 -0.02 0.9141 0.421 0.10 A2BP1 54715 ataxin 2-binding protein 1 2.811 0.01093 0.65 0.07114 0.954 -0.01 A2LD1 87769 AIG2-like domain 1 -0.3033 0.8056 -0.09 -3.365 0.005704 -0.42 A2M 2 alpha-2-macroglobulin -0.8113 0.4691 -0.03 6.02 0 1.75 A4GALT 53947 alpha 1,4-galactosyltransferase 0.4383 0.7128 0.11 6.304 0 2.30 AACS 65985 acetoacetyl-CoA synthetase 0.3595 0.7664 0.03 3.534 0.00388 0.38 AADAC 13 arylacetamide deacetylase (esterase) 0.569 0.6216 0.16 0.005588 0.9968 0.00 AADAT 51166 aminoadipate aminotransferase -0.9577 0.3876 -0.11 0.8123 0.4752 0.24 AAK1 22848 AP2 associated kinase 1 -1.261 0.2505 -0.25 0.8232 0.4689 0.12 AAMP 14 angio-associated, migratory cell protein 0.873 0.4351 0.07 1.656 0.1476 0.06 AANAT 15 arylalkylamine N-acetyltransferase -0.3998 0.7394 -0.08 0.8486 0.456 0.18 AARS 16 alanyl-tRNA synthetase 5.517 0 0.34 8.616 0 0.69 AARS2 57505 alanyl-tRNA synthetase 2, mitochondrial (putative) 1.701 0.1158 0.35 0.5011 0.6622 0.07 AARSD1 80755 alanyl-tRNA synthetase domain containing 1 4.403 9.52E-05 0.52 1.279 0.2609 0.13 AASDH 132949 aminoadipate-semialdehyde dehydrogenase -0.8921 0.4247 -0.12 -2.564 0.02993 -0.32 AASDHPPT 60496 aminoadipate-semialdehyde -

Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations Fall 2010 Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress Renuka Nayak University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Computational Biology Commons, and the Genomics Commons Recommended Citation Nayak, Renuka, "Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress" (2010). Publicly Accessible Penn Dissertations. 1559. https://repository.upenn.edu/edissertations/1559 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/1559 For more information, please contact [email protected]. Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress Abstract Genes interact in networks to orchestrate cellular processes. Here, we used coexpression networks based on natural variation in gene expression to study the functions and interactions of human genes. We asked how these networks change in response to stress. First, we studied human coexpression networks at baseline. We constructed networks by identifying correlations in expression levels of 8.9 million gene pairs in immortalized B cells from 295 individuals comprising three independent samples. The resulting networks allowed us to infer interactions between biological processes. We used the network to predict the functions of poorly-characterized human genes, and provided some experimental support. Examining genes implicated in disease, we found that IFIH1, a diabetes susceptibility gene, interacts with YES1, which affects glucose transport. Genes predisposing to the same diseases are clustered non-randomly in the network, suggesting that the network may be used to identify candidate genes that influence disease susceptibility.