IBD Risk Loci Are Enriched in Multigenic Regulatory Modules Encompassing Putative Causative Genes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
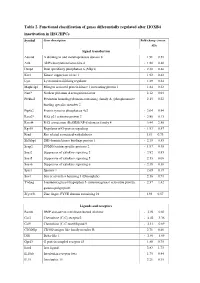
Table 2. Functional Classification of Genes Differentially Regulated After HOXB4 Inactivation in HSC/Hpcs
Table 2. Functional classification of genes differentially regulated after HOXB4 inactivation in HSC/HPCs Symbol Gene description Fold-change (mean ± SD) Signal transduction Adam8 A disintegrin and metalloprotease domain 8 1.91 ± 0.51 Arl4 ADP-ribosylation factor-like 4 - 1.80 ± 0.40 Dusp6 Dual specificity phosphatase 6 (Mkp3) - 2.30 ± 0.46 Ksr1 Kinase suppressor of ras 1 1.92 ± 0.42 Lyst Lysosomal trafficking regulator 1.89 ± 0.34 Mapk1ip1 Mitogen activated protein kinase 1 interacting protein 1 1.84 ± 0.22 Narf* Nuclear prelamin A recognition factor 2.12 ± 0.04 Plekha2 Pleckstrin homology domain-containing. family A. (phosphoinosite 2.15 ± 0.22 binding specific) member 2 Ptp4a2 Protein tyrosine phosphatase 4a2 - 2.04 ± 0.94 Rasa2* RAS p21 activator protein 2 - 2.80 ± 0.13 Rassf4 RAS association (RalGDS/AF-6) domain family 4 3.44 ± 2.56 Rgs18 Regulator of G-protein signaling - 1.93 ± 0.57 Rrad Ras-related associated with diabetes 1.81 ± 0.73 Sh3kbp1 SH3 domain kinase bindings protein 1 - 2.19 ± 0.53 Senp2 SUMO/sentrin specific protease 2 - 1.97 ± 0.49 Socs2 Suppressor of cytokine signaling 2 - 2.82 ± 0.85 Socs5 Suppressor of cytokine signaling 5 2.13 ± 0.08 Socs6 Suppressor of cytokine signaling 6 - 2.18 ± 0.38 Spry1 Sprouty 1 - 2.69 ± 0.19 Sos1 Son of sevenless homolog 1 (Drosophila) 2.16 ± 0.71 Ywhag 3-monooxygenase/tryptophan 5- monooxygenase activation protein. - 2.37 ± 1.42 gamma polypeptide Zfyve21 Zinc finger. FYVE domain containing 21 1.93 ± 0.57 Ligands and receptors Bambi BMP and activin membrane-bound inhibitor - 2.94 ± 0.62 -

Cisplatin and Phenanthriplatin Modulate Long-Noncoding
www.nature.com/scientificreports OPEN Cisplatin and phenanthriplatin modulate long‑noncoding RNA expression in A549 and IMR90 cells revealing regulation of microRNAs, Wnt/β‑catenin and TGF‑β signaling Jerry D. Monroe1,2, Satya A. Moolani2,3, Elvin N. Irihamye2,4, Katheryn E. Lett1, Michael D. Hebert1, Yann Gibert1* & Michael E. Smith2* The monofunctional platinum(II) complex, phenanthriplatin, acts by blocking transcription, but its regulatory efects on long‑noncoding RNAs (lncRNAs) have not been elucidated relative to traditional platinum‑based chemotherapeutics, e.g., cisplatin. Here, we treated A549 non‑small cell lung cancer and IMR90 lung fbroblast cells for 24 h with either cisplatin, phenanthriplatin or a solvent control, and then performed microarray analysis to identify regulated lncRNAs. RNA22 v2 microRNA software was subsequently used to identify microRNAs (miRNAs) that might be suppressed by the most regulated lncRNAs. We found that miR‑25‑5p, ‑30a‑3p, ‑138‑5p, ‑149‑3p, ‑185‑5p, ‑378j, ‑608, ‑650, ‑708‑5p, ‑1253, ‑1254, ‑4458, and ‑4516, were predicted to target the cisplatin upregulated lncRNAs, IMMP2L‑1, CBR3‑1 and ATAD2B‑5, and the phenanthriplatin downregulated lncRNAs, AGO2‑1, COX7A1‑2 and SLC26A3‑1. Then, we used qRT‑PCR to measure the expression of miR‑25‑5p, ‑378j, ‑4516 (A549) and miR‑149‑3p, ‑608, and ‑4458 (IMR90) to identify distinct signaling efects associated with cisplatin and phenanthriplatin. The signaling pathways associated with these miRNAs suggests that phenanthriplatin may modulate Wnt/β‑catenin and TGF‑β signaling through the MAPK/ ERK and PTEN/AKT pathways diferently than cisplatin. Further, as some of these miRNAs may be subject to dissimilar lncRNA targeting in A549 and IMR90 cells, the monofunctional complex may not cause toxicity in normal lung compared to cancer cells by acting through distinct lncRNA and miRNA networks. -

Atypical 11Q Deletions Identified by Array CGH May Be Missed by FISH
Letters to the Editor 1011 1 2 2 2 1 AC Ng , SK Kumar , SJ Russell , SV Rajkumar and MT Drake 2 Axelrod L. Glucocorticoid therapy. Medicine (Baltimore) 1976; 55: 1 Division of Endocrinology, Department of Medicine, 39–65. Mayo Clinic, Rochester, MN, USA and 3 Krasner AS. Glucocorticoid-induced adrenal insufficiency. JAMA 2Division of Hematology, Department of Medicine, 1999; 282: 671–676. Mayo Clinic, Rochester, MN, USA 4 Schlaghecke R, Kornely E, Santen RT, Ridderskamp P. The effect of E-mail: [email protected] long-term glucocorticoid therapy on pituitary-adrenal responses to exogenous corticotropin-releasing hormone. N Engl J Med 1992; 326: 226–230. References 5 Grinspoon SK, Biller BM. Clinical review 62: laboratory assessment of adrenal insufficiency. J Clin Endocrinol Metab 1994; 79: 1 Rajkumar SV, Jacobus S, Callander N, Fonseca R, Vesole D, Williams 923–931. M et al. A randomized trial of lenalidomide plus high-dose 6 Nieman LK. Dynamic evaluation of adrenal hypofunction. dexamethasone (RD) versus lenalidomide plus low-dose dexametha- J Endocrinol Invest 2003; 26 (7 Suppl): 74–82. sone (Rd) in newly diagnosed multiple myeloma (E4A03): a trial 7 Hagg E, Asplund K, Lithner F. Value of basal plasma cortisol assays coordinated by the Eastern Cooperative Oncology Group. Blood in the assessment of pituitary-adrenal insufficiency. Clin Endocrinol (ASH Annual Meeting Abstracts) 2006; 108:799. (Oxf) 1987; 26: 221–226. Atypical 11q deletions identified by array CGH may be missed by FISH panels for prognostic markers in chronic lymphocytic leukemia Leukemia (2009) 23, 1011–1017; doi:10.1038/leu.2008.393; results were because of small clonal cell populations that published online 22 January 2009 comprised o25–30% of the total sample. -

Multifactorial Erβ and NOTCH1 Control of Squamous Differentiation and Cancer
Multifactorial ERβ and NOTCH1 control of squamous differentiation and cancer Yang Sui Brooks, … , Karine Lefort, G. Paolo Dotto J Clin Invest. 2014;124(5):2260-2276. https://doi.org/10.1172/JCI72718. Research Article Oncology Downmodulation or loss-of-function mutations of the gene encoding NOTCH1 are associated with dysfunctional squamous cell differentiation and development of squamous cell carcinoma (SCC) in skin and internal organs. While NOTCH1 receptor activation has been well characterized, little is known about how NOTCH1 gene transcription is regulated. Using bioinformatics and functional screening approaches, we identified several regulators of the NOTCH1 gene in keratinocytes, with the transcription factors DLX5 and EGR3 and estrogen receptor β (ERβ) directly controlling its expression in differentiation. DLX5 and ERG3 are required for RNA polymerase II (PolII) recruitment to the NOTCH1 locus, while ERβ controls NOTCH1 transcription through RNA PolII pause release. Expression of several identified NOTCH1 regulators, including ERβ, is frequently compromised in skin, head and neck, and lung SCCs and SCC-derived cell lines. Furthermore, a keratinocyte ERβ–dependent program of gene expression is subverted in SCCs from various body sites, and there are consistent differences in mutation and gene-expression signatures of head and neck and lung SCCs in female versus male patients. Experimentally increased ERβ expression or treatment with ERβ agonists inhibited proliferation of SCC cells and promoted NOTCH1 expression and squamous differentiation both in vitro and in mouse xenotransplants. Our data identify a link between transcriptional control of NOTCH1 expression and the estrogen response in keratinocytes, with implications for differentiation therapy of squamous cancer. Find the latest version: https://jci.me/72718/pdf Research article Multifactorial ERβ and NOTCH1 control of squamous differentiation and cancer Yang Sui Brooks,1,2 Paola Ostano,3 Seung-Hee Jo,1,2 Jun Dai,1,2 Spiro Getsios,4 Piotr Dziunycz,5 Günther F.L. -

PLZF Targets Developmental Enhancers for Activation During Osteogenic Differentiation of Human Mesenchymal Stem Cells
RESEARCH ARTICLE PLZF targets developmental enhancers for activation during osteogenic differentiation of human mesenchymal stem cells Shuchi Agrawal Singh1,2,3*, Mads Lerdrup1,3, Ana-Luisa R Gomes1,3, Harmen JG van de Werken4,5,6, Jens Vilstrup Johansen1,3,7, Robin Andersson1,3,7, Albin Sandelin1,3,7, Kristian Helin8,9,10, Klaus Hansen1,3* 1Biotech Research and Innovation Centre (BRIC), Faculty of Health and Medical Sciences, University of Copenhagen, Copenhagen, Denmark; 2Department of Hematology, Cambridge Institute for Medical Research and Welcome Trust/MRC Stem Cell Institute, University of Cambridge, Cambridge, United Kingdom; 3Centre for Epigenetics, Faculty of Health and Medical Sciences, University of Copenhagen, Copenhagen, Denmark; 4Department of Cell Biology, University Medical Center, Rotterdam, Netherlands; 5Cancer Computational Biology Center, University Medical Center, Rotterdam, Netherlands; 6Department of Urology, University Medical Center, Rotterdam, Netherlands; 7Department of Biology, The Bioinformatics Centre, University of Copenhagen, Copenhagen, Denmark; 8The Novo Nordisk Center for Stem Cell Biology, Faculty of Health and Medical Sciences University of Copenhagen, Copenhagen, Denmark; 9Cell Biology Program, Memorial Sloan Kettering Cancer Center, New York, United States; 10Center for Epigenetics Research, Memorial Sloan Kettering Cancer Center, New York, United States *For correspondence: [email protected]; Abstract The PLZF transcription factor is essential for osteogenic differentiation of hMSCs; [email protected] (SAS); however, its regulation and molecular function during this process is not fully understood. Here, we [email protected] (KHA) revealed that the ZBTB16 locus encoding PLZF, is repressed by Polycomb (PcG) and H3K27me3 in Competing interests: The naive hMSCs. At the pre-osteoblast stage of differentiation, the locus lost PcG binding and authors declare that no H3K27me3, gained JMJD3 recruitment, and H3K27ac resulting in high expression of PLZF. -

Pharmacogenomic Characterization in Bipolar Spectrum Disorders
pharmaceutics Review Pharmacogenomic Characterization in Bipolar Spectrum Disorders Stefano Fortinguerra 1,2 , Vincenzo Sorrenti 1,2,3 , Pietro Giusti 2, Morena Zusso 2 and Alessandro Buriani 1,2,* 1 Maria Paola Belloni Center for Personalized Medicine, Data Medica Group (Synlab Limited), 35131 Padova, Italy; [email protected] (S.F.); [email protected] (V.S.) 2 Department of Pharmaceutical & Pharmacological Sciences, University of Padova, 35131 Padova, Italy; [email protected] (P.G.); [email protected] (M.Z.) 3 Bendessere™ Study Center, Solgar Italia Multinutrient S.p.A., 35131 Padova, Italy * Correspondence: [email protected] Received: 25 November 2019; Accepted: 19 December 2019; Published: 21 December 2019 Abstract: The holistic approach of personalized medicine, merging clinical and molecular characteristics to tailor the diagnostic and therapeutic path to each individual, is steadily spreading in clinical practice. Psychiatric disorders represent one of the most difficult diagnostic challenges, given their frequent mixed nature and intrinsic variability, as in bipolar disorders and depression. Patients misdiagnosed as depressed are often initially prescribed serotonergic antidepressants, a treatment that can exacerbate a previously unrecognized bipolar condition. Thanks to the use of the patient’s genomic profile, it is possible to recognize such risk and at the same time characterize specific genetic assets specifically associated with bipolar spectrum disorder, as well as with the individual response to the various therapeutic options. This provides the basis for molecular diagnosis and the definition of pharmacogenomic profiles, thus guiding therapeutic choices and allowing a safer and more effective use of psychotropic drugs. Here, we report the pharmacogenomics state of the art in bipolar disorders and suggest an algorithm for therapeutic regimen choice. -

Broad and Thematic Remodeling of the Surface Glycoproteome on Isogenic
bioRxiv preprint doi: https://doi.org/10.1101/808139; this version posted October 17, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Broad and thematic remodeling of the surface glycoproteome on isogenic cells transformed with driving proliferative oncogenes Kevin K. Leung1,5, Gary M. Wilson2,5, Lisa L. Kirkemo1, Nicholas M. Riley2,4, Joshua J. Coon2,3, James A. Wells1* 1Department of Pharmaceutical Chemistry, UCSF, San Francisco, CA, USA Departments of Chemistry2 and Biomolecular Chemistry3, University of Wisconsin- Madison, Madison, WI, 53706, USA 4Present address Department of Chemistry, Stanford University, Stanford, CA, 94305, USA 5These authors contributed equally *To whom correspondence should be addressed bioRxiv preprint doi: https://doi.org/10.1101/808139; this version posted October 17, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Abstract: The cell surface proteome, the surfaceome, is the interface for engaging the extracellular space in normal and cancer cells. Here We apply quantitative proteomics of N-linked glycoproteins to reveal how a collection of some 700 surface proteins is dramatically remodeled in an isogenic breast epithelial cell line stably expressing any of six of the most prominent proliferative oncogenes, including the receptor tyrosine kinases, EGFR and HER2, and downstream signaling partners such as KRAS, BRAF, MEK and AKT. -

MBNL1 Regulates Essential Alternative RNA Splicing Patterns in MLL-Rearranged Leukemia
ARTICLE https://doi.org/10.1038/s41467-020-15733-8 OPEN MBNL1 regulates essential alternative RNA splicing patterns in MLL-rearranged leukemia Svetlana S. Itskovich1,9, Arun Gurunathan 2,9, Jason Clark 1, Matthew Burwinkel1, Mark Wunderlich3, Mikaela R. Berger4, Aishwarya Kulkarni5,6, Kashish Chetal6, Meenakshi Venkatasubramanian5,6, ✉ Nathan Salomonis 6,7, Ashish R. Kumar 1,7 & Lynn H. Lee 7,8 Despite growing awareness of the biologic features underlying MLL-rearranged leukemia, 1234567890():,; targeted therapies for this leukemia have remained elusive and clinical outcomes remain dismal. MBNL1, a protein involved in alternative splicing, is consistently overexpressed in MLL-rearranged leukemias. We found that MBNL1 loss significantly impairs propagation of murine and human MLL-rearranged leukemia in vitro and in vivo. Through transcriptomic profiling of our experimental systems, we show that in leukemic cells, MBNL1 regulates alternative splicing (predominantly intron exclusion) of several genes including those essential for MLL-rearranged leukemogenesis, such as DOT1L and SETD1A.Wefinally show that selective leukemic cell death is achievable with a small molecule inhibitor of MBNL1. These findings provide the basis for a new therapeutic target in MLL-rearranged leukemia and act as further validation of a burgeoning paradigm in targeted therapy, namely the disruption of cancer-specific splicing programs through the targeting of selectively essential RNA binding proteins. 1 Division of Bone Marrow Transplantation and Immune Deficiency, Cincinnati Children’s Hospital Medical Center, Cincinnati, OH 45229, USA. 2 Cancer and Blood Diseases Institute, Cincinnati Children’s Hospital Medical Center, Cincinnati, OH 45229, USA. 3 Division of Experimental Hematology and Cancer Biology, Cincinnati Children’s Hospital Medical Center, Cincinnati, OH 45229, USA. -

Functional Characterization of the New 8Q21 Asthma Risk Locus
Functional characterization of the new 8q21 Asthma risk locus Cristina M T Vicente B.Sc, M.Sc A thesis submitted for the degree of Doctor of Philosophy at The University of Queensland in 2017 Faculty of Medicine Abstract Genome wide association studies (GWAS) provide a powerful tool to identify genetic variants associated with asthma risk. However, the target genes for many allergy risk variants discovered to date are unknown. In a recent GWAS, Ferreira et al. identified a new association between asthma risk and common variants located on chromosome 8q21. The overarching aim of this thesis was to elucidate the biological mechanisms underlying this association. Specifically, the goals of this study were to identify the gene(s) underlying the observed association and to study their contribution to asthma pathophysiology. Using genetic data from the 1000 Genomes Project, we first identified 118 variants in linkage disequilibrium (LD; r2>0.6) with the sentinel allergy risk SNP (rs7009110) on chromosome 8q21. Of these, 35 were found to overlap one of four Putative Regulatory Elements (PREs) identified in this region in a lymphoblastoid cell line (LCL), based on epigenetic marks measured by the ENCODE project. Results from analysis of gene expression data generated for LCLs (n=373) by the Geuvadis consortium indicated that rs7009110 is associated with the expression of only one nearby gene: PAG1 - located 732 kb away. PAG1 encodes a transmembrane adaptor protein localized to lipid rafts, which is highly expressed in immune cells. Results from chromosome conformation capture (3C) experiments showed that PREs in the region of association physically interacted with the promoter of PAG1. -

Integrating Single-Step GWAS and Bipartite Networks Reconstruction Provides Novel Insights Into Yearling Weight and Carcass Traits in Hanwoo Beef Cattle
animals Article Integrating Single-Step GWAS and Bipartite Networks Reconstruction Provides Novel Insights into Yearling Weight and Carcass Traits in Hanwoo Beef Cattle Masoumeh Naserkheil 1 , Abolfazl Bahrami 1 , Deukhwan Lee 2,* and Hossein Mehrban 3 1 Department of Animal Science, University College of Agriculture and Natural Resources, University of Tehran, Karaj 77871-31587, Iran; [email protected] (M.N.); [email protected] (A.B.) 2 Department of Animal Life and Environment Sciences, Hankyong National University, Jungang-ro 327, Anseong-si, Gyeonggi-do 17579, Korea 3 Department of Animal Science, Shahrekord University, Shahrekord 88186-34141, Iran; [email protected] * Correspondence: [email protected]; Tel.: +82-31-670-5091 Received: 25 August 2020; Accepted: 6 October 2020; Published: 9 October 2020 Simple Summary: Hanwoo is an indigenous cattle breed in Korea and popular for meat production owing to its rapid growth and high-quality meat. Its yearling weight and carcass traits (backfat thickness, carcass weight, eye muscle area, and marbling score) are economically important for the selection of young and proven bulls. In recent decades, the advent of high throughput genotyping technologies has made it possible to perform genome-wide association studies (GWAS) for the detection of genomic regions associated with traits of economic interest in different species. In this study, we conducted a weighted single-step genome-wide association study which combines all genotypes, phenotypes and pedigree data in one step (ssGBLUP). It allows for the use of all SNPs simultaneously along with all phenotypes from genotyped and ungenotyped animals. Our results revealed 33 relevant genomic regions related to the traits of interest. -

Deubiquitinase UCHL1 Maintains Protein Homeostasis Through PSMA7-APEH- Proteasome Axis in High-Grade Serous Ovarian Carcinoma
bioRxiv preprint doi: https://doi.org/10.1101/2020.09.28.316810; this version posted October 9, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Deubiquitinase UCHL1 Maintains Protein Homeostasis through PSMA7-APEH- Proteasome Axis in High-Grade Serous Ovarian Carcinoma Apoorva Tangri1*, Kinzie Lighty1*, Jagadish Loganathan1, Fahmi Mesmar2, Ram Podicheti3, Chi Zhang1, Marcin Iwanicki4, Harikrishna Nakshatri1,5, Sumegha Mitra1,5,# 1 Indiana University School of Medicine, Indianapolis, IN, USA 2 Indiana University, Bloomington, IN, USA 3Center for Genomics and Bioinformatics, Indiana University, Bloomington, IN, USA 4Stevens Institute of Technology, Hoboken, NJ, USA 5Indiana University Melvin & Bren Simon Cancer Center, Indianapolis, USA *Equal contribution # corresponding author; to whom correspondence may be addressed. E-mail: [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.09.28.316810; this version posted October 9, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract High-grade serous ovarian cancer (HGSOC) is characterized by chromosomal instability, DNA damage, oxidative stress, and high metabolic demand, which exacerbate misfolded, unfolded and damaged protein burden resulting in increased proteotoxicity. However, the underlying mechanisms that maintain protein homeostasis to promote HGSOC growth remain poorly understood. In this study, we report that the neuronal deubiquitinating enzyme, ubiquitin carboxyl-terminal hydrolase L1 (UCHL1) is overexpressed in HGSOC and maintains protein homeostasis. UCHL1 expression was markedly increased in HGSOC patient tumors and serous tubal intraepithelial carcinoma (HGSOC precursor lesions). -

Análise Integrativa De Perfis Transcricionais De Pacientes Com
UNIVERSIDADE DE SÃO PAULO FACULDADE DE MEDICINA DE RIBEIRÃO PRETO PROGRAMA DE PÓS-GRADUAÇÃO EM GENÉTICA ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Ribeirão Preto – 2012 ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Tese apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo para obtenção do título de Doutor em Ciências. Área de Concentração: Genética Orientador: Prof. Dr. Eduardo Antonio Donadi Co-orientador: Prof. Dr. Geraldo A. S. Passos Ribeirão Preto – 2012 AUTORIZO A REPRODUÇÃO E DIVULGAÇÃO TOTAL OU PARCIAL DESTE TRABALHO, POR QUALQUER MEIO CONVENCIONAL OU ELETRÔNICO, PARA FINS DE ESTUDO E PESQUISA, DESDE QUE CITADA A FONTE. FICHA CATALOGRÁFICA Evangelista, Adriane Feijó Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. Ribeirão Preto, 2012 192p. Tese de Doutorado apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo. Área de Concentração: Genética. Orientador: Donadi, Eduardo Antonio Co-orientador: Passos, Geraldo A. 1. Expressão gênica – microarrays 2. Análise bioinformática por module maps 3. Diabetes mellitus tipo 1 4. Diabetes mellitus tipo 2 5. Diabetes mellitus gestacional FOLHA DE APROVAÇÃO ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas.