AMD's Family 11H
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Titan X Amd 1.2 V4 Ig 20210319
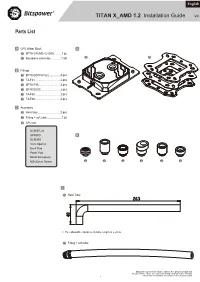
English TITAN X_AMD 1.2 Installation Guide V4 Parts List A CPU Water Block A A-1 BPTA-CPUMS-V2-SKA ..........1 pc A-1 A-2 A-2 Backplane assembly ..............1 set B Fittings B-1 BPTA-DOTFH1622 ...............4 pcs B-2 TA-F61 ...................................2 pcs B-3 BPTA-F95 ..............................2 pcs B-4 BP-RIGOS5 ...........................2 pcs B-5 TA-F60 ..................................2 pcs B-6 TA-F40 ..................................2 pcs C Accessory C-1 Hard tube ..............................2 pcs C-2 Fitting + soft tube ....................1 pc C-3 CPU set SCM3FL20 SPRING B SCM3F6 1mm Spacer Back Pad Paste Pad Metal Backplane M3x32mm Screw B-1 B-2 B-3 B-4 B-5 B-6 C C-1 Hard Tube ※ The allowable variance in tube length is ± 2mm C-2 Fitting + soft tube Bitspower reserves the right to change the product design and interpretations. These are subject to change without notice. Product colors and accessories are based on the actual product. — 1 — I. AMD Motherboard system 54 AMD SOCKET 939 / 754 / 940 IN 48 AMD SOCKET AM4 AMD SOCKET AM3 / AM3+ AMD SOCKET AM2 / AM2+ AMD SOCKET FM1 / FM2+ Bitspower Fan and DRGB RF Remote Controller Hub (Not included) are now available at microcenter.com DRGB PIN on Motherboard or other equipment. 96 90 BPTA-RFCHUB The CPU water block has a DRGB cable, which AMD SOCKET AM4 AMD SOCKET AM3 AM3+ / AMD SOCKET AM2 AM2+ / AMD SOCKET FM1 / FM2+ can be connected to the DRGB extension cable of the radiator fans. Fan and DRGB RF Remote Motherboard Controller Hub (Not included) OUT DRGB LED Do not over-tighten the thumb screws Installation (SCM3FL20). -

GPTPU: Accelerating Applications Using Edge Tensor Processing Units Kuan-Chieh Hsu and Hung-Wei Tseng University of California, Riverside {Khsu037, Htseng}@Ucr.Edu
GPTPU: Accelerating Applications using Edge Tensor Processing Units Kuan-Chieh Hsu and Hung-Wei Tseng University of California, Riverside {khsu037, htseng}@ucr.edu This paper is a pre-print of a paper in the 2021 SC, the Interna- Two decades ago, graphics processing units (GPUs) were just tional Conference for High Performance Computing, Networking, domain-specific accelerators used for shading and rendering. But Storage and Analysis. Please refer to the conference proceedings intensive research into high-performance algorithms, architectures, for the most complete version. systems, and compilers [3–12] and the availability of frameworks like CUDA [13] and OpenCL [14], have revolutionized GPUs and ABSTRACT transformed them into high-performance, general-purpose vector Neural network (NN) accelerators have been integrated into a wide- processors. We expect a similar revolution to take place with NN spectrum of computer systems to accommodate the rapidly growing accelerators—a revolution that will create general-purpose matrix demands for artificial intelligence (AI) and machine learning (ML) processors for a broader spectrum of applications. However, de- applications. NN accelerators share the idea of providing native mocratizing these NN accelerators for non-AI/ML workloads will hardware support for operations on multidimensional tensor data. require the system framework and the programmer to tackle the Therefore, NN accelerators are theoretically tensor processors that following issues: can improve system performance for any problem that uses ten- (1) The microarchitectures and instructions of NN accelerators sors as inputs/outputs. Unfortunately, commercially available NN are optimized for NN workloads, instead of general matrix/tensor accelerators only expose computation capabilities through AI/ML- algebra. -

Amd Filed: February 24, 2009 (Period: December 27, 2008)
FORM 10-K ADVANCED MICRO DEVICES INC - amd Filed: February 24, 2009 (period: December 27, 2008) Annual report which provides a comprehensive overview of the company for the past year Table of Contents 10-K - FORM 10-K PART I ITEM 1. 1 PART I ITEM 1. BUSINESS ITEM 1A. RISK FACTORS ITEM 1B. UNRESOLVED STAFF COMMENTS ITEM 2. PROPERTIES ITEM 3. LEGAL PROCEEDINGS ITEM 4. SUBMISSION OF MATTERS TO A VOTE OF SECURITY HOLDERS PART II ITEM 5. MARKET FOR REGISTRANT S COMMON EQUITY, RELATED STOCKHOLDER MATTERS AND ISSUER PURCHASES OF EQUITY SECURITIES ITEM 6. SELECTED FINANCIAL DATA ITEM 7. MANAGEMENT S DISCUSSION AND ANALYSIS OF FINANCIAL CONDITION AND RESULTS OF OPERATIONS ITEM 7A. QUANTITATIVE AND QUALITATIVE DISCLOSURE ABOUT MARKET RISK ITEM 8. FINANCIAL STATEMENTS AND SUPPLEMENTARY DATA ITEM 9. CHANGES IN AND DISAGREEMENTS WITH ACCOUNTANTS ON ACCOUNTING AND FINANCIAL DISCLOSURE ITEM 9A. CONTROLS AND PROCEDURES ITEM 9B. OTHER INFORMATION PART III ITEM 10. DIRECTORS, EXECUTIVE OFFICERS AND CORPORATE GOVERNANCE ITEM 11. EXECUTIVE COMPENSATION ITEM 12. SECURITY OWNERSHIP OF CERTAIN BENEFICIAL OWNERS AND MANAGEMENT AND RELATED STOCKHOLDER MATTERS ITEM 13. CERTAIN RELATIONSHIPS AND RELATED TRANSACTIONS AND DIRECTOR INDEPENDENCE ITEM 14. PRINCIPAL ACCOUNTANT FEES AND SERVICES PART IV ITEM 15. EXHIBITS, FINANCIAL STATEMENT SCHEDULES SIGNATURES EX-10.5(A) (OUTSIDE DIRECTOR EQUITY COMPENSATION POLICY) EX-10.19 (SEPARATION AGREEMENT AND GENERAL RELEASE) EX-21 (LIST OF AMD SUBSIDIARIES) EX-23.A (CONSENT OF ERNST YOUNG LLP - ADVANCED MICRO DEVICES) EX-23.B -

Improving Resource Utilization in Heterogeneous CPU-GPU Systems
Improving Resource Utilization in Heterogeneous CPU-GPU Systems A Dissertation Presented to the Faculty of the School of Engineering and Applied Science University of Virginia In Partial Fulfillment of the requirements for the Degree Doctor of Philosophy (Computer Engineering) by Michael Boyer May 2013 c 2013 Michael Boyer Abstract Graphics processing units (GPUs) have attracted enormous interest over the past decade due to substantial increases in both performance and programmability. Programmers can potentially leverage GPUs for substantial performance gains, but at the cost of significant software engineering effort. In practice, most GPU applications do not effectively utilize all of the available resources in a system: they either fail to use use a resource at all or use a resource to less than its full potential. This underutilization can hurt both performance and energy efficiency. In this dissertation, we address the underutilization of resources in heterogeneous CPU-GPU systems in three different contexts. First, we address the underutilization of a single GPU by reducing CPU-GPU interaction to improve performance. We use as a case study a computationally-intensive video-tracking application from systems biology. Because of the high cost of CPU-GPU coordination, our initial, straightforward attempts to accelerate this application failed to effectively utilize the GPU. By leveraging some non-obvious optimization strategies, we significantly decreased the amount of CPU-GPU interaction and improved the performance of the GPU implementation by 26x relative to the best CPU implementation. Based on the lessons we learned, we present general guidelines for optimizing GPU applications as well as recommendations for system-level changes that would simplify the development of high-performance GPU applications. -

System Management BIOS (SMBIOS) Reference 6 Specification
1 2 Document Number: DSP0134 3 Date: 2011-01-26 4 Version: 2.7.1 5 System Management BIOS (SMBIOS) Reference 6 Specification 7 Document Type: Specification 8 Document Status: DMTF Standard 9 Document Language: en-US 10 System Management BIOS (SMBIOS) Reference Specification DSP0134 11 Copyright Notice 12 Copyright © 2000, 2002, 2004–2011 Distributed Management Task Force, Inc. (DMTF). All rights 13 reserved. 14 DMTF is a not-for-profit association of industry members dedicated to promoting enterprise and systems 15 management and interoperability. Members and non-members may reproduce DMTF specifications and 16 documents, provided that correct attribution is given. As DMTF specifications may be revised from time to 17 time, the particular version and release date should always be noted. 18 Implementation of certain elements of this standard or proposed standard may be subject to third party 19 patent rights, including provisional patent rights (herein "patent rights"). DMTF makes no representations 20 to users of the standard as to the existence of such rights, and is not responsible to recognize, disclose, 21 or identify any or all such third party patent right, owners or claimants, nor for any incomplete or 22 inaccurate identification or disclosure of such rights, owners or claimants. DMTF shall have no liability to 23 any party, in any manner or circumstance, under any legal theory whatsoever, for failure to recognize, 24 disclose, or identify any such third party patent rights, or for such party’s reliance on the standard or 25 incorporation -

Quad-Core Catamount and R&D in Multi-Core Lightweight Kernels
Quad-core Catamount and R&D in Multi-core Lightweight Kernels Salishan Conference on High-Speed Computing Gleneden Beach, Oregon April 21-24, 2008 Kevin Pedretti Senior Member of Technical Staff Scalable System Software, Dept. 1423 [email protected] SAND Number: 2008-1725A Sandia is a multiprogram laboratory operated by Sandia Corporation, a Lockheed Martin Company, for the United States Department of Energy's National Nuclear Security Administration under contract DE-AC04-94AL85000. Outline • Introduction • Quad-core Catamount LWK results • Open-source LWK • Research directions • Conclusion Going on Four Decades of UNIX Operating System = Collection of software and APIs Users care about environment, not implementation details LWK is about getting details right for scalability LWK Overview Basic Architecture Memory Management … … Policy n 1 n N tio tio Page 3 Page 3 Maker ca ca i l Libc.a Libc.a (PCT) pp ppli Page 2 Page 2 A libmpi.a A libmpi.a Page 1 Page 1 Policy Enforcer/HAL (QK) Page 0 Page 0 Privileged Hardware Physical Application Memory Virtual • POSIX-like environment Memory • Inverted resource management • Very low noise OS noise/jitter • Straight-forward network stack (e.g., no pinning) • Simplicity leads to reliability Nov 2007 Top500 Top 10 System Lightweight Kernel Compute Processors: Timeline 82% run a LWK 1990 – Sandia/UNM OS (SUNMOS), nCube-2 1991 – Linux 0.02 1993 – SUNMOS ported to Intel Paragon (1800 nodes) 1993 – SUNMOS experience used to design Puma First implementation of Portals communication architecture 1994 -

Family 12H AMD Sempron Processor Product Data Sheet
Family 12h AMD Sempron™ Processor Product Data Sheet Publication # 50321 Revision: 3.00 Issue Date: December 2011 Advanced Micro Devices © 2011 Advanced Micro Devices, Inc. All rights reserved. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. The information contained herein may be of a preliminary or advance nature and is subject to change without notice. No license, whether express, implied, arising by estoppel or otherwise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as components in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other application in which the failure of AMD’s product could create a situation where personal injury, death, or severe property or environmental damage may occur. AMD reserves the right to discontinue or make changes to its products at any time without notice. Trademarks AMD, the AMD Arrow logo, AMD PowerNow!, 3DNow!, AMD Virtualization, AMD-V, Sempron, and combinations thereof are trademarks of Advanced Micro Devices, Inc. -

ADVANCED MICRO DEVICES, INC. (Exact Name of Registrant As Specified in Its Charter)
UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 FORM 8-K CURRENT REPORT Pursuant to Section 13 or 15(d) of the Securities Exchange Act of 1934 July 19, 2007 Date of Report (Date of earliest event reported) ADVANCED MICRO DEVICES, INC. (Exact name of registrant as specified in its charter) Delaware 001-07882 94-1692300 (State of Incorporation) (Commission File Number) (IRS Employer Identification Number) One AMD Place P.O. Box 3453 Sunnyvale, California 94088-3453 (Address of principal executive offices) (Zip Code) (408) 749-4000 (Registrant’s telephone number, including area code) N/A (Former Name or Former Address, if Changed Since Last Report) Check the appropriate box below if the Form 8-K filing is intended to simultaneously satisfy the filing obligation of the registrant under any of the following provisions: ¨ Written communications pursuant to Rule 425 under the Securities Act (17 CFR 230.425) ¨ Soliciting material pursuant to Rule 14a-12 under the Exchange Act (17 CFR 240.14a-12) ¨ Pre-commencement communications pursuant to Rule 14d-2(b) under the Exchange Act (17 CFR 240.14d-2(b)) ¨ Pre-commencement communications pursuant to Rule 13e-4(c) under the Exchange Act (17 CFR 240.13e-4(c)) Item 2.02 Results of Operations and Financial Condition. Item 7.01 Regulation FD Disclosure. The information in this Report, including the Exhibit 99.1 attached hereto, is furnished pursuant to Item 2.02 and Item 7.01 of this Form 8-K. Consequently, it is not deemed “filed” for the purposes of Section 18 of the Securities and Exchange Act of 1934, as amended, or otherwise subject to the liabilities of that section. -

I Processori Amd Trinity
UNIVERSITA’ DEGLI STUDI DI PADOVA __________________________________________________ Facoltà di Ingegneria Corso di laurea in Ingegneria Informatica I PROCESSORI AMD TRINITY Laureando Relatore Luca Marzaro Prof. Sergio Congiu ___________________________________________________________ ANNO ACCADEMICO 2012/2013 ii iii A Giulia, mamma, papà e Diego iv Indice 1. Introduzione 1 1.1 Cenni storici AMD . 1 1.2 Evoluzione del processore: dall' Am386 alle APU Trinity . 2 2. Trinity: Architettura 5 2.1 Introduzione . 5 2.2 Da Llano a Trinity: architettura Piledriver . 6 2.3 Graphics Memory Controller: architettura VLIW4 . 8 2.4 Un nuovo socket: FM2 . 12 3. Specifiche tecniche 15 3.1 Modelli e dati tecnici . 15 3.2 Comparazione con Llano e Intel core i3 . 17 4. Prestazioni 19 4.1 Introduzione . 19 4.2 Applicazioni multimediali . 22 4.3 Calcolo e compressione . 25 4.4 Consumi . 30 5. Considerazioni finali 35 vi INDICE Bibliografia 37 Capitolo 1 Introduzione 1.1 Cenni storici AMD AMD (Advanced Micro Devices) è una multinazionale americana produttrice di semiconduttori la cui sede si trova a Sunnyvale in California. La peculiarità di tale azienda è la produzione di microprocessori, workstation e server, di chip grafici e di chipset. Si classifica seconda al mondo Figura 1.1: Jerry Sanders nella produzione di microprocessori con architettuta x86 dopo Intel. Il primo maggio 1969 Jerry Sanders (vedi Figura 1.1) e sette amici fondano la AMD. Sei anni più tardi, lanciano nel mercato la prima memoria RAM marchiata AMD, la Am9102 e presentano AMD 8080, una variante dell'INTEL 8080 che lancia l'azienda nel mondo dei microprocessori. Dal 1980 AMD si impone come uno dei principali concorrenti di Intel nel mercato dei processori x86- compatibili. -

Communication Theory II
Microprocessor (COM 9323) Lecture 2: Review on Intel Family Ahmed Elnakib, PhD Assistant Professor, Mansoura University, Egypt Feb 17th, 2016 1 Text Book/References Textbook: 1. The Intel Microprocessors, Architecture, Programming and Interfacing, 8th edition, Barry B. Brey, Prentice Hall, 2009 2. Assembly Language for x86 processors, 6th edition, K. R. Irvine, Prentice Hall, 2011 References: 1. Computer Architecture: A Quantitative Approach, 5th edition, J. Hennessy, D. Patterson, Elsevier, 2012. 2. The 80x86 Family, Design, Programming and Interfacing, 3rd edition, Prentice Hall, 2002 3. The 80x86 IBM PC and Compatible Computers, Assembly Language, Design, and Interfacing, 4th edition, M.A. Mazidi and J.G. Mazidi, Prentice Hall, 2003 2 Lecture Objectives 1. Provide an overview of the various 80X86 and Pentium family members 2. Define the contents of the memory system in the personal computer 3. Convert between binary, decimal, and hexadecimal numbers 4. Differentiate and represent numeric and alphabetic information as integers, floating-point, BCD, and ASCII data 5. Understand basic computer terminology (bit, byte, data, real memory system, protected mode memory system, Windows, DOS, I/O) 3 Brief History of the Computers o1946 The first generation of Computer ENIAC (Electrical and Numerical Integrator and Calculator) was started to be used based on the vacuum tube technology, University of Pennsylvania o1970s entire CPU was put in a single chip. (1971 the first microprocessor of Intel 4004 (4-bit data bus and 2300 transistors and 45 instructions) 4 Brief History of the Computers (cont’d) oLate 1970s Intel 8080/85 appeared with 8-bit data bus and 16-bit address bus and used from traffic light controllers to homemade computers (8085: 246 instruction set, RISC*) o1981 First PC was introduced by IBM with Intel 8088 (CISC**: over 20,000 instructions) microprocessor oMotorola emerged with 6800. -

Upgrading and Repairing Pcs, 21St Edition Editor-In-Chief Greg Wiegand Copyright © 2013 by Pearson Education, Inc
Contents at a Glance Introduction 1 1 Development of the PC 5 2 PC Components, Features, and System Design 19 3 Processor Types and Specifications 29 4 Motherboards and Buses 155 5 BIOS 263 UPGRADING 6 Memory 325 7 The ATA/IDE Interface 377 AND 8 Magnetic Storage Principles 439 9 Hard Disk Storage 461 REPAIRING PCs 10 Flash and Removable Storage 507 21st Edition 11 Optical Storage 525 12 Video Hardware 609 13 Audio Hardware 679 14 External I/O Interfaces 703 15 Input Devices 739 16 Internet Connectivity 775 17 Local Area Networking 799 18 Power Supplies 845 19 Building or Upgrading Systems 929 20 PC Diagnostics, Testing, and Maintenance 975 Index 1035 Scott Mueller 800 East 96th Street, Indianapolis, Indiana 46240 Upgrading.indb i 2/15/13 10:33 AM Upgrading and Repairing PCs, 21st Edition Editor-in-Chief Greg Wiegand Copyright © 2013 by Pearson Education, Inc. Acquisitions Editor All rights reserved. No part of this book shall be reproduced, stored in a retrieval Rick Kughen system, or transmitted by any means, electronic, mechanical, photocopying, Development Editor recording, or otherwise, without written permission from the publisher. No patent Todd Brakke liability is assumed with respect to the use of the information contained herein. Managing Editor Although every precaution has been taken in the preparation of this book, the Sandra Schroeder publisher and author assume no responsibility for errors or omissions. Nor is any Project Editor liability assumed for damages resulting from the use of the information contained Mandie Frank herein. Copy Editor ISBN-13: 978-0-7897-5000-6 Sheri Cain ISBN-10: 0-7897-5000-7 Indexer Library of Congress Cataloging-in-Publication Data in on file. -

Application-Controlled Frequency Scaling Explained
The TURBO Diaries: Application-controlled Frequency Scaling Explained Jons-Tobias Wamhoff, Stephan Diestelhorst, and Christof Fetzer, Technische Universät Dresden; Patrick Marlier and Pascal Felber, Université de Neuchâtel; Dave Dice, Oracle Labs https://www.usenix.org/conference/atc14/technical-sessions/presentation/wamhoff This paper is included in the Proceedings of USENIX ATC ’14: 2014 USENIX Annual Technical Conference. June 19–20, 2014 • Philadelphia, PA 978-1-931971-10-2 Open access to the Proceedings of USENIX ATC ’14: 2014 USENIX Annual Technical Conference is sponsored by USENIX. The TURBO Diaries: Application-controlled Frequency Scaling Explained Jons-Tobias Wamhoff Patrick Marlier Dave Dice Stephan Diestelhorst Pascal Felber Christof Fetzer Technische Universtat¨ Dresden, Germany Universite´ de Neuchatel,ˆ Switzerland Oracle Labs, USA Abstract these features from an application as needed. Examples in- Most multi-core architectures nowadays support dynamic volt- clude: accelerating the execution of key sections of code on age and frequency scaling (DVFS) to adapt their speed to the the critical path of multi-threaded applications [9]; boosting system’s load and save energy. Some recent architectures addi- time-critical operations or high-priority threads; or reducing tionally allow cores to operate at boosted speeds exceeding the the energy consumption of applications executing low-priority nominal base frequency but within their thermal design power. threads. Furthermore, workloads specifically designed to run In this paper, we propose a general-purpose library that on processors with heterogeneous cores (e.g., few fast and allows selective control of DVFS from user space to accelerate many slow cores) may take additional advantage of application- multi-threaded applications and expose the potential of hetero- level frequency scaling.