Skewness to Test Normality for Mean Comparison
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Use of Proc Iml to Calculate L-Moments for the Univariate Distributional Shape Parameters Skewness and Kurtosis
Statistics 573 USE OF PROC IML TO CALCULATE L-MOMENTS FOR THE UNIVARIATE DISTRIBUTIONAL SHAPE PARAMETERS SKEWNESS AND KURTOSIS Michael A. Walega Berlex Laboratories, Wayne, New Jersey Introduction Exploratory data analysis statistics, such as those Gaussian. Bickel (1988) and Van Oer Laan and generated by the sp,ge procedure PROC Verdooren (1987) discuss the concept of robustness UNIVARIATE (1990), are useful tools to characterize and how it pertains to the assumption of normality. the underlying distribution of data prior to more rigorous statistical analyses. Assessment of the As discussed by Glass et al. (1972), incorrect distributional shape of data is usually accomplished conclusions may be reached when the normality by careful examination of the values of the third and assumption is not valid, especially when one-tail tests fourth central moments, skewness and kurtosis. are employed or the sample size or significance level However, when the sample size is small or the are very small. Hopkins and Weeks (1990) also underlying distribution is non-normal, the information discuss the effects of highly non-normal data on obtained from the sample skewness and kurtosis can hypothesis testing of variances. Thus, it is apparent be misleading. that examination of the skewness (departure from symmetry) and kurtosis (deviation from a normal One alternative to the central moment shape statistics curve) is an important component of exploratory data is the use of linear combinations of order statistics (L analyses. moments) to examine the distributional shape characteristics of data. L-moments have several Various methods to estimate skewness and kurtosis theoretical advantages over the central moment have been proposed (MacGillivray and Salanela, shape statistics: Characterization of a wider range of 1988). -

Concentration and Consistency Results for Canonical and Curved Exponential-Family Models of Random Graphs
CONCENTRATION AND CONSISTENCY RESULTS FOR CANONICAL AND CURVED EXPONENTIAL-FAMILY MODELS OF RANDOM GRAPHS BY MICHAEL SCHWEINBERGER AND JONATHAN STEWART Rice University Statistical inference for exponential-family models of random graphs with dependent edges is challenging. We stress the importance of additional structure and show that additional structure facilitates statistical inference. A simple example of a random graph with additional structure is a random graph with neighborhoods and local dependence within neighborhoods. We develop the first concentration and consistency results for maximum likeli- hood and M-estimators of a wide range of canonical and curved exponential- family models of random graphs with local dependence. All results are non- asymptotic and applicable to random graphs with finite populations of nodes, although asymptotic consistency results can be obtained as well. In addition, we show that additional structure can facilitate subgraph-to-graph estimation, and present concentration results for subgraph-to-graph estimators. As an ap- plication, we consider popular curved exponential-family models of random graphs, with local dependence induced by transitivity and parameter vectors whose dimensions depend on the number of nodes. 1. Introduction. Models of network data have witnessed a surge of interest in statistics and related areas [e.g., 31]. Such data arise in the study of, e.g., social networks, epidemics, insurgencies, and terrorist networks. Since the work of Holland and Leinhardt in the 1970s [e.g., 21], it is known that network data exhibit a wide range of dependencies induced by transitivity and other interesting network phenomena [e.g., 39]. Transitivity is a form of triadic closure in the sense that, when a node k is connected to two distinct nodes i and j, then i and j are likely to be connected as well, which suggests that edges are dependent [e.g., 39]. -

Use of Statistical Tables
TUTORIAL | SCOPE USE OF STATISTICAL TABLES Lucy Radford, Jenny V Freeman and Stephen J Walters introduce three important statistical distributions: the standard Normal, t and Chi-squared distributions PREVIOUS TUTORIALS HAVE LOOKED at hypothesis testing1 and basic statistical tests.2–4 As part of the process of statistical hypothesis testing, a test statistic is calculated and compared to a hypothesised critical value and this is used to obtain a P- value. This P-value is then used to decide whether the study results are statistically significant or not. It will explain how statistical tables are used to link test statistics to P-values. This tutorial introduces tables for three important statistical distributions (the TABLE 1. Extract from two-tailed standard Normal, t and Chi-squared standard Normal table. Values distributions) and explains how to use tabulated are P-values corresponding them with the help of some simple to particular cut-offs and are for z examples. values calculated to two decimal places. STANDARD NORMAL DISTRIBUTION TABLE 1 The Normal distribution is widely used in statistics and has been discussed in z 0.00 0.01 0.02 0.03 0.050.04 0.05 0.06 0.07 0.08 0.09 detail previously.5 As the mean of a Normally distributed variable can take 0.00 1.0000 0.9920 0.9840 0.9761 0.9681 0.9601 0.9522 0.9442 0.9362 0.9283 any value (−∞ to ∞) and the standard 0.10 0.9203 0.9124 0.9045 0.8966 0.8887 0.8808 0.8729 0.8650 0.8572 0.8493 deviation any positive value (0 to ∞), 0.20 0.8415 0.8337 0.8259 0.8181 0.8103 0.8206 0.7949 0.7872 0.7795 0.7718 there are an infinite number of possible 0.30 0.7642 0.7566 0.7490 0.7414 0.7339 0.7263 0.7188 0.7114 0.7039 0.6965 Normal distributions. -

Startips …A Resource for Survey Researchers
Subscribe Archives StarTips …a resource for survey researchers Share this article: How to Interpret Standard Deviation and Standard Error in Survey Research Standard Deviation and Standard Error are perhaps the two least understood statistics commonly shown in data tables. The following article is intended to explain their meaning and provide additional insight on how they are used in data analysis. Both statistics are typically shown with the mean of a variable, and in a sense, they both speak about the mean. They are often referred to as the "standard deviation of the mean" and the "standard error of the mean." However, they are not interchangeable and represent very different concepts. Standard Deviation Standard Deviation (often abbreviated as "Std Dev" or "SD") provides an indication of how far the individual responses to a question vary or "deviate" from the mean. SD tells the researcher how spread out the responses are -- are they concentrated around the mean, or scattered far & wide? Did all of your respondents rate your product in the middle of your scale, or did some love it and some hate it? Let's say you've asked respondents to rate your product on a series of attributes on a 5-point scale. The mean for a group of ten respondents (labeled 'A' through 'J' below) for "good value for the money" was 3.2 with a SD of 0.4 and the mean for "product reliability" was 3.4 with a SD of 2.1. At first glance (looking at the means only) it would seem that reliability was rated higher than value. -

Synthpop: Bespoke Creation of Synthetic Data in R
synthpop: Bespoke Creation of Synthetic Data in R Beata Nowok Gillian M Raab Chris Dibben University of Edinburgh University of Edinburgh University of Edinburgh Abstract In many contexts, confidentiality constraints severely restrict access to unique and valuable microdata. Synthetic data which mimic the original observed data and preserve the relationships between variables but do not contain any disclosive records are one possible solution to this problem. The synthpop package for R, introduced in this paper, provides routines to generate synthetic versions of original data sets. We describe the methodology and its consequences for the data characteristics. We illustrate the package features using a survey data example. Keywords: synthetic data, disclosure control, CART, R, UK Longitudinal Studies. This introduction to the R package synthpop is a slightly amended version of Nowok B, Raab GM, Dibben C (2016). synthpop: Bespoke Creation of Synthetic Data in R. Journal of Statistical Software, 74(11), 1-26. doi:10.18637/jss.v074.i11. URL https://www.jstatsoft. org/article/view/v074i11. 1. Introduction and background 1.1. Synthetic data for disclosure control National statistical agencies and other institutions gather large amounts of information about individuals and organisations. Such data can be used to understand population processes so as to inform policy and planning. The cost of such data can be considerable, both for the collectors and the subjects who provide their data. Because of confidentiality constraints and guarantees issued to data subjects the full access to such data is often restricted to the staff of the collection agencies. Traditionally, data collectors have used anonymisation along with simple perturbation methods such as aggregation, recoding, record-swapping, suppression of sensitive values or adding random noise to prevent the identification of data subjects. -

Parametric and Non-Parametric Statistics for Program Performance Analysis and Comparison Julien Worms, Sid Touati
Parametric and Non-Parametric Statistics for Program Performance Analysis and Comparison Julien Worms, Sid Touati To cite this version: Julien Worms, Sid Touati. Parametric and Non-Parametric Statistics for Program Performance Anal- ysis and Comparison. [Research Report] RR-8875, INRIA Sophia Antipolis - I3S; Université Nice Sophia Antipolis; Université Versailles Saint Quentin en Yvelines; Laboratoire de mathématiques de Versailles. 2017, pp.70. hal-01286112v3 HAL Id: hal-01286112 https://hal.inria.fr/hal-01286112v3 Submitted on 29 Jun 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Public Domain Parametric and Non-Parametric Statistics for Program Performance Analysis and Comparison Julien WORMS, Sid TOUATI RESEARCH REPORT N° 8875 Mar 2016 Project-Teams "Probabilités et ISSN 0249-6399 ISRN INRIA/RR--8875--FR+ENG Statistique" et AOSTE Parametric and Non-Parametric Statistics for Program Performance Analysis and Comparison Julien Worms∗, Sid Touati† Project-Teams "Probabilités et Statistique" et AOSTE Research Report n° 8875 — Mar 2016 — 70 pages Abstract: This report is a continuation of our previous research effort on statistical program performance analysis and comparison [TWB10, TWB13], in presence of program performance variability. In the previous study, we gave a formal statistical methodology to analyse program speedups based on mean or median performance metrics: execution time, energy consumption, etc. -

Bootstrapping Regression Models
Bootstrapping Regression Models Appendix to An R and S-PLUS Companion to Applied Regression John Fox January 2002 1 Basic Ideas Bootstrapping is a general approach to statistical inference based on building a sampling distribution for a statistic by resampling from the data at hand. The term ‘bootstrapping,’ due to Efron (1979), is an allusion to the expression ‘pulling oneself up by one’s bootstraps’ – in this case, using the sample data as a population from which repeated samples are drawn. At first blush, the approach seems circular, but has been shown to be sound. Two S libraries for bootstrapping are associated with extensive treatments of the subject: Efron and Tibshirani’s (1993) bootstrap library, and Davison and Hinkley’s (1997) boot library. Of the two, boot, programmed by A. J. Canty, is somewhat more capable, and will be used for the examples in this appendix. There are several forms of the bootstrap, and, additionally, several other resampling methods that are related to it, such as jackknifing, cross-validation, randomization tests,andpermutation tests. I will stress the nonparametric bootstrap. Suppose that we draw a sample S = {X1,X2, ..., Xn} from a population P = {x1,x2, ..., xN };imagine further, at least for the time being, that N is very much larger than n,andthatS is either a simple random sample or an independent random sample from P;1 I will briefly consider other sampling schemes at the end of the appendix. It will also help initially to think of the elements of the population (and, hence, of the sample) as scalar values, but they could just as easily be vectors (i.e., multivariate). -
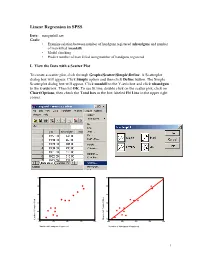
Linear Regression in SPSS
Linear Regression in SPSS Data: mangunkill.sav Goals: • Examine relation between number of handguns registered (nhandgun) and number of man killed (mankill) • Model checking • Predict number of man killed using number of handguns registered I. View the Data with a Scatter Plot To create a scatter plot, click through Graphs\Scatter\Simple\Define. A Scatterplot dialog box will appear. Click Simple option and then click Define button. The Simple Scatterplot dialog box will appear. Click mankill to the Y-axis box and click nhandgun to the x-axis box. Then hit OK. To see fit line, double click on the scatter plot, click on Chart\Options, then check the Total box in the box labeled Fit Line in the upper right corner. 60 60 50 50 40 40 30 30 20 20 10 10 Killed of People Number Number of People Killed 400 500 600 700 800 400 500 600 700 800 Number of Handguns Registered Number of Handguns Registered 1 Click the target button on the left end of the tool bar, the mouse pointer will change shape. Move the target pointer to the data point and click the left mouse button, the case number of the data point will appear on the chart. This will help you to identify the data point in your data sheet. II. Regression Analysis To perform the regression, click on Analyze\Regression\Linear. Place nhandgun in the Dependent box and place mankill in the Independent box. To obtain the 95% confidence interval for the slope, click on the Statistics button at the bottom and then put a check in the box for Confidence Intervals. -

Non Parametric Test: Chi Square Test of Contingencies
Weblinks http://www:stat.sc.edu/_west/applets/chisqdemo1.html http://2012books.lardbucket.org/books/beginning-statistics/s15-chi-square-tests-and-f- tests.html www.psypress.com/spss-made-simple Suggested Readings Siegel, S. & Castellan, N.J. (1988). Non Parametric Statistics for the Behavioral Sciences (2nd edn.). McGraw Hill Book Company: New York. Clark- Carter, D. (2010). Quantitative psychological research: a student’s handbook (3rd edn.). Psychology Press: New York. Myers, J.L. & Well, A.D. (1991). Research Design and Statistical analysis. New York: Harper Collins. Agresti, A. 91996). An introduction to categorical data analysis. New York: Wiley. PSYCHOLOGY PAPER No.2 : Quantitative Methods MODULE No. 15: Non parametric test: chi square test of contingencies Zimmerman, D. & Zumbo, B.D. (1993). The relative power of parametric and non- parametric statistics. In G. Karen & C. Lewis (eds.), A handbook for data analysis in behavioral sciences: Methodological issues (pp. 481- 517). Hillsdale, NJ: Lawrence Earlbaum Associates, Inc. Field, A. (2005). Discovering statistics using SPSS (2nd ed.). London: Sage. Biographic Sketch Description 1894 Karl Pearson(1857-1936) was the first person to use the term “standard deviation” in one of his lectures. contributed to statistical studies by discovering Chi square. Founded statistical laboratory in 1911 in England. http://www.swlearning.com R.A. Fisher (1890- 1962) Father of modern statistics was educated at Harrow and Cambridge where he excelled in mathematics. He later became interested in theory of errors and ultimately explored statistical problems like: designing of experiments, analysis of variance. He developed methods suitable for small samples and discovered precise distributions of many sample statistics. -

A Skew Extension of the T-Distribution, with Applications
J. R. Statist. Soc. B (2003) 65, Part 1, pp. 159–174 A skew extension of the t-distribution, with applications M. C. Jones The Open University, Milton Keynes, UK and M. J. Faddy University of Birmingham, UK [Received March 2000. Final revision July 2002] Summary. A tractable skew t-distribution on the real line is proposed.This includes as a special case the symmetric t-distribution, and otherwise provides skew extensions thereof.The distribu- tion is potentially useful both for modelling data and in robustness studies. Properties of the new distribution are presented. Likelihood inference for the parameters of this skew t-distribution is developed. Application is made to two data modelling examples. Keywords: Beta distribution; Likelihood inference; Robustness; Skewness; Student’s t-distribution 1. Introduction Student’s t-distribution occurs frequently in statistics. Its usual derivation and use is as the sam- pling distribution of certain test statistics under normality, but increasingly the t-distribution is being used in both frequentist and Bayesian statistics as a heavy-tailed alternative to the nor- mal distribution when robustness to possible outliers is a concern. See Lange et al. (1989) and Gelman et al. (1995) and references therein. It will often be useful to consider a further alternative to the normal or t-distribution which is both heavy tailed and skew. To this end, we propose a family of distributions which includes the symmetric t-distributions as special cases, and also includes extensions of the t-distribution, still taking values on the whole real line, with non-zero skewness. Let a>0 and b>0be parameters. -

A Survey on Data Collection for Machine Learning a Big Data - AI Integration Perspective
1 A Survey on Data Collection for Machine Learning A Big Data - AI Integration Perspective Yuji Roh, Geon Heo, Steven Euijong Whang, Senior Member, IEEE Abstract—Data collection is a major bottleneck in machine learning and an active research topic in multiple communities. There are largely two reasons data collection has recently become a critical issue. First, as machine learning is becoming more widely-used, we are seeing new applications that do not necessarily have enough labeled data. Second, unlike traditional machine learning, deep learning techniques automatically generate features, which saves feature engineering costs, but in return may require larger amounts of labeled data. Interestingly, recent research in data collection comes not only from the machine learning, natural language, and computer vision communities, but also from the data management community due to the importance of handling large amounts of data. In this survey, we perform a comprehensive study of data collection from a data management point of view. Data collection largely consists of data acquisition, data labeling, and improvement of existing data or models. We provide a research landscape of these operations, provide guidelines on which technique to use when, and identify interesting research challenges. The integration of machine learning and data management for data collection is part of a larger trend of Big data and Artificial Intelligence (AI) integration and opens many opportunities for new research. Index Terms—data collection, data acquisition, data labeling, machine learning F 1 INTRODUCTION E are living in exciting times where machine learning expertise. This problem applies to any novel application that W is having a profound influence on a wide range of benefits from machine learning. -

Appendix F.1 SAWG SPC Appendices
Appendix F.1 - SAWG SPC Appendices 8-8-06 Page 1 of 36 Appendix 1: Control Charts for Variables Data – classical Shewhart control chart: When plate counts provide estimates of large levels of organisms, the estimated levels (cfu/ml or cfu/g) can be considered as variables data and the classical control chart procedures can be used. Here it is assumed that the probability of a non-detect is virtually zero. For these types of microbiological data, a log base 10 transformation is used to remove the correlation between means and variances that have been observed often for these types of data and to make the distribution of the output variable used for tracking the process more symmetric than the measured count data1. There are several control charts that may be used to control variables type data. Some of these charts are: the Xi and MR, (Individual and moving range) X and R, (Average and Range), CUSUM, (Cumulative Sum) and X and s, (Average and Standard Deviation). This example includes the Xi and MR charts. The Xi chart just involves plotting the individual results over time. The MR chart involves a slightly more complicated calculation involving taking the difference between the present sample result, Xi and the previous sample result. Xi-1. Thus, the points that are plotted are: MRi = Xi – Xi-1, for values of i = 2, …, n. These charts were chosen to be shown here because they are easy to construct and are common charts used to monitor processes for which control with respect to levels of microbiological organisms is desired.