Fingerspelling Detection in American Sign Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sign Language Typology Series
SIGN LANGUAGE TYPOLOGY SERIES The Sign Language Typology Series is dedicated to the comparative study of sign languages around the world. Individual or collective works that systematically explore typological variation across sign languages are the focus of this series, with particular emphasis on undocumented, underdescribed and endangered sign languages. The scope of the series primarily includes cross-linguistic studies of grammatical domains across a larger or smaller sample of sign languages, but also encompasses the study of individual sign languages from a typological perspective and comparison between signed and spoken languages in terms of language modality, as well as theoretical and methodological contributions to sign language typology. Interrogative and Negative Constructions in Sign Languages Edited by Ulrike Zeshan Sign Language Typology Series No. 1 / Interrogative and negative constructions in sign languages / Ulrike Zeshan (ed.) / Nijmegen: Ishara Press 2006. ISBN-10: 90-8656-001-6 ISBN-13: 978-90-8656-001-1 © Ishara Press Stichting DEF Wundtlaan 1 6525XD Nijmegen The Netherlands Fax: +31-24-3521213 email: [email protected] http://ishara.def-intl.org Cover design: Sibaji Panda Printed in the Netherlands First published 2006 Catalogue copy of this book available at Depot van Nederlandse Publicaties, Koninklijke Bibliotheek, Den Haag (www.kb.nl/depot) To the deaf pioneers in developing countries who have inspired all my work Contents Preface........................................................................................................10 -

A Lexicostatistic Survey of the Signed Languages in Nepal
DigitalResources Electronic Survey Report 2012-021 ® A Lexicostatistic Survey of the Signed Languages in Nepal Hope M. Hurlbut A Lexicostatistic Survey of the Signed Languages in Nepal Hope M. Hurlbut SIL International ® 2012 SIL Electronic Survey Report 2012-021, June 2012 © 2012 Hope M. Hurlbut and SIL International ® All rights reserved 2 Contents 0. Introduction 1.0 The Deaf 1.1 The deaf of Nepal 1.2 Deaf associations 1.3 History of deaf education in Nepal 1.4 Outside influences on Nepali Sign Language 2.0 The Purpose of the Survey 3.0 Research Questions 4.0 Approach 5.0 The survey trip 5.1 Kathmandu 5.2 Surkhet 5.3 Jumla 5.4 Pokhara 5.5 Ghandruk 5.6 Dharan 5.7 Rajbiraj 6.0 Methodology 7.0 Analysis and results 7.1 Analysis of the wordlists 7.2 Interpretation criteria 7.2.1 Results of the survey 7.2.2 Village signed languages 8.0 Conclusion Appendix Sample of Nepali Sign Language Wordlist (Pages 1–6) References 3 Abstract This report concerns a 2006 lexicostatistical survey of the signed languages of Nepal. Wordlists and stories were collected in several towns of Nepal from Deaf school leavers who were considered to be representative of the Nepali Deaf. In each city or town there was a school for the Deaf either run by the government or run by one of the Deaf Associations. The wordlists were transcribed by hand using the SignWriting orthography. Two other places were visited where it was learned that there were possibly unique sign languages, in Jumla District, and also in Ghandruk (a village in Kaski District). -

The 5 Parameters of ASL Before You Begin Sign Language Partner Activities, You Need to Learn the 5 Parameters of ASL
The 5 Parameters of ASL Before you begin Sign Language Partner activities, you need to learn the 5 Parameters of ASL. You will use these parameters to describe new vocabulary words you will learn with your partner while completing Language Partner activities. Read and learn about the 5 Parameters below. DEFINITION In American Sign Language (ASL), we use the 5 Parameters of ASL to describe how a sign behaves within the signer’s space. The parameters are handshape, palm orientation, movement, location, and expression/non-manual signals. All five parameters must be performed correctly to sign the word accurately. Go to https://www.youtube.com/watch?v=FrkGrIiAoNE for a signed definition of the 5 Parameters of ASL. Don’t forget to turn the captions on if you are a beginning ASL student. Note: The signer’s space spans the width of your elbows when your hands are on your hips to the length four inches above your head to four inches below your belly button. Imagine a rectangle drawn around the top half of your body. TYPES OF HANDSHAPES Handshapes consist of the manual alphabet and other variations of handshapes. Refer to the picture below. TYPES OF ORIENTATIONS Orientation refers to which direction your palm is facing for a particular sign. The different directions are listed below. 1. Palm facing out 2. Palm facing in 3. Palm is horizontal 4. Palm faces left/right 5. Palm toward palm 6. Palm up/down TYPES OF MOVEMENT A sign can display different kinds of movement that are named below. 1. In a circle 2. -

Alignment Mouth Demonstrations in Sign Languages Donna Jo Napoli
Mouth corners in sign languages Alignment mouth demonstrations in sign languages Donna Jo Napoli, Swarthmore College, [email protected] Corresponding Author Ronice Quadros, Universidade Federal de Santa Catarina, [email protected] Christian Rathmann, Humboldt-Universität zu Berlin, [email protected] 1 Mouth corners in sign languages Alignment mouth demonstrations in sign languages Abstract: Non-manual articulations in sign languages range from being semantically impoverished to semantically rich, and from being independent of manual articulations to coordinated with them. But, while this range has been well noted, certain non-manuals remain understudied. Of particular interest to us are non-manual articulations coordinated with manual articulations, which, when considered in conjunction with those manual articulations, are semantically rich. In which ways can such different articulators coordinate and what is the linguistic effect or purpose of such coordination? Of the non-manual articulators, the mouth is articulatorily the most versatile. We therefore examined mouth articulations in a single narrative told in the sign languages of America, Brazil, and Germany. We observed optional articulations of the corners of the lips that align with manual articulations spatially and temporally in classifier constructions. The lips, thus, enhance the message by giving redundant information, which should be particularly useful in narratives for children. Examination of a single children’s narrative told in these same three sign languages plus six other sign languages yielded examples of one type of these optional alignment articulations, confirming our expectations. Our findings are coherent with linguistic findings regarding phonological enhancement and overspecification. Keywords: sign languages, non-manual articulation, mouth articulation, hand-mouth coordination 2 Mouth corners in sign languages Alignment mouth demonstration articulations in sign languages 1. -
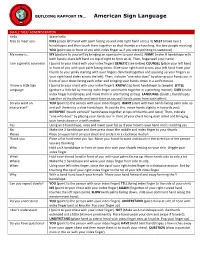
Building Rapport in American Sign Language.Pdf
BUILDING RAPPORT IN… American Sign Language SMALL TALK/ ADMINISTRATION Hello Wave hello Nice to meet you NICE (place left hand with palm facing up and slide right hand across it) MEET (make two 1 handshapes and then touch them together so that thumbs are touching, like two people meeting) YOU (point out in front of you with index finger as if you were pointing to someone) My name is… MY (gesture to yourself by bringing an open palm to your chest). NAME (make H handshape with both hands; place left hand on top of right to form an X). Then, fingerspell your name. I am a genetic counselor I (point to your chest with your index finger) GENETIC (see below) COUNSEL (place your left hand in front of you with your palm facing down. Slide your right hand across your left hand from your thumb to your pinky starting with your fingers clenched together and opening up your fingers as your right hand slides across the left). Then, indicate “one who does” by placing your hands our in front of your chest facing each other and bringing your hands down in a swift motion. I know a little Sign I (point to your chest with your index finger). KNOW (tap bent handshape to temple). LITTLE Language (gesture a little bit by moving index finger and thumb together in a pinching motion). SIGN (make index finger handshapes and move them in alternating circles). LANGUAGE (touch L handshapes together at the thumbs and twist them as you pull hands away from each other). -

Advocacy Notes
Advocacy Notes Question from the field: We are a small school district and only offer an ASL interpreter for students with hearing loss, but more and more students are now using spoken language. Are there interpreting services or supports that we need to offer these students who do not use ASL? Depending on a student’s mode of communication, there are various options available for providing access in the educational setting. For the students who are receiving access to spoken language earlier and have better hearing technology, ASL is often not their primary language. There are language options and communication strategies available for families whose children have hearing 1 loss . Families may decide to use any of or a combination of the following: • Spoken Language - developing the use of spoken language in the primary language of the family and/or education system using the mouth and vocal cords • American Sign Language (ASL) - a complete language system that uses signs with the hands combined with facial expression and body posture. ASL includes visual attention, eye contact and fingerspelling. • Manually Coded English (MCE) - the use of signs that represent English words. Many of the signs are borrowed from ASL, but use the word order, grammar, and sentence structure of English. • Cued Speech - a system of hand signals to help the listener with hearing loss identify the differences in speech sounds that are difficult to discriminate through listening. • Conceptually Accurate Signed English (CASE)/Pidgin Sign English (PSE) - a mix of ASL signs used in English word order. • Simultaneous Communication - used in order to speak out loud while signing using CASE or PSE. -

Hand-To-Hand Combat, Or Mouth-To-Mouth Resuscitation?
BEHAVIORAL AND BRAIN SCIENCES (2003) 26, 199–260 Printed in the United States of America From mouth to hand: Gesture, speech, and the evolution of right-handedness Michael C. Corballis Department of Psychology, University of Auckland, Private Bag 92019, Auckland, New Zealand. [email protected] Abstract: The strong predominance of right-handedness appears to be a uniquely human characteristic, whereas the left-cerebral dom- inance for vocalization occurs in many species, including frogs, birds, and mammals. Right-handedness may have arisen because of an association between manual gestures and vocalization in the evolution of language. I argue that language evolved from manual gestures, gradually incorporating vocal elements. The transition may be traced through changes in the function of Broca’s area. Its homologue in monkeys has nothing to do with vocal control, but contains the so-called “mirror neurons,” the code for both the production of manual reaching movements and the perception of the same movements performed by others. This system is bilateral in monkeys, but pre- dominantly left-hemispheric in humans, and in humans is involved with vocalization as well as manual actions. There is evidence that Broca’s area is enlarged on the left side in Homo habilis, suggesting that a link between gesture and vocalization may go back at least two million years, although other evidence suggests that speech may not have become fully autonomous until Homo sapiens appeared some 170,000 years ago, or perhaps even later. The removal of manual gesture as a necessary component of language may explain the rapid advance of technology, allowing late migrations of Homo sapiens from Africa to replace all other hominids in other parts of the world, including the Neanderthals in Europe and Homo erectus in Asia. -

DQP TISLR 10 Fingerspelling Rates
Rates of fingerspelling in American Sign Language David Quinto-Pozos Department of Linguistics, University of Texas-Austin TISLR 10; Purdue University Methodology Introduction Main points Signers: 2 deaf native users of ASL (Kevin & James) Information in the text (examples of items that were fingerspelled): • Faster rates than previously reported Fingerspelling used often in American Sign Language (ASL) • Where Don lived (various states and cities such as Idaho, Indiana, and Means: 5-8 letters per second (125 – 200 ms/ltr) • Morford & MacFarlane (2003); corpus of 4,111 signs (27 signers) Task: deliver an ASL narrative (originally created in English) about Dallas) and worked (e.g. Gallaudet University, Model Secondary School • 8.7% of signs in casual signing the life of a Deaf leader in the US Deaf community (Don Petingill) for the Deaf, etc.) • 4.8% of signs in formal signing • Donʼs involvement in the Deaf community including advocacy work • Signers can differ in rates: Some signers are faster • 5.8% of signs in narrative signing Three audiences per signer: school children (ages 9-10) (e.g. for the Texas Commission for the Deaf) fingerspellers than other signers plus two audiences of adults • Anecdotes about Donʼs life (e.g., Donʼs joke-telling & humor) • Padden & Gansauls (2003) • 10% - 15% of signs in discourse • “Long” words are fingerspelled faster than “short” • > 50% of native signers fingerspelled 20% of time words • non-native signers: lower frequency of fingerspelling General Description of the Data: Reasons for “short” vs. “long” -

The Two Hundred Years' War in Deaf Education
THE TWO HUNDRED YEARS' WAR IN DEAF EDUCATION A reconstruction of the methods controversy By A. Tellings PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/146075 Please be advised that this information was generated on 2020-04-15 and may be subject to change. THE TWO HUNDRED YEARS* WAR IN DEAF EDUCATION A reconstruction of the methods controversy By A. Tellings THE TWO HUNDRED YEARS' WAR IN DEAF EDUCATION A reconstruction of the methods controversy EEN WETENSCHAPPELIJKE PROEVE OP HET GEBIED VAN DE SOCIALE WETENSCHAPPEN PROEFSCHRIFT TER VERKRIJGING VAN DE GRAAD VAN DOCTOR AAN DE KATHOLIEKE UNIVERSITEIT NIJMEGEN, VOLGENS BESLUIT VAN HET COLLEGE VAN DECANEN IN HET OPENBAAR TE VERDEDIGEN OP 5 DECEMBER 1995 DES NAMIDDAGS TE 3.30 UUR PRECIES DOOR AGNES ELIZABETH JACOBA MARIA TELLINGS GEBOREN OP 9 APRIL 1954 TE ROOSENDAAL Dit onderzoek werd verricht met behulp van subsidie van de voormalige Stichting Pedon, NWO Mediagroep Katholieke Universiteit Nijmegen PROMOTOR: Prof.Dr. A.W. van Haaften COPROMOTOR: Dr. G.L.M. Snik 1 PREFACE The methods controversy in deaf education has fascinated me since I visited the International Congress on Education of the Deaf in Hamburg (Germany) in 1980. There I was struck by the intemperate emotions by which the methods controversy is attended. This book is an attempt to understand what this controversy really is about I would like to thank first and foremost Prof.Wouter van Haaften and Dr. -

8. Classifiers
158 II. Morphology 8. Classifiers 1. Introduction 2. Classifiers and classifier categories 3. Classifier verbs 4. Classifiers in signs other than classifier verbs 5. The acquisition of classifiers in sign languages 6. Classifiers in spoken and sign languages: a comparison 7. Conclusion 8. Literature Abstract Classifiers (currently also called ‘depicting handshapes’), are observed in almost all sign languages studied to date and form a well-researched topic in sign language linguistics. Yet, these elements are still subject to much debate with respect to a variety of matters. Several different categories of classifiers have been posited on the basis of their semantics and the linguistic context in which they occur. The function(s) of classifiers are not fully clear yet. Similarly, there are differing opinions regarding their structure and the structure of the signs in which they appear. Partly as a result of comparison to classifiers in spoken languages, the term ‘classifier’ itself is under debate. In contrast to these disagreements, most studies on the acquisition of classifier constructions seem to consent that these are difficult to master for Deaf children. This article presents and discusses all these issues from the viewpoint that classifiers are linguistic elements. 1. Introduction This chapter is about classifiers in sign languages and the structures in which they occur. Classifiers are reported to occur in almost all sign languages researched to date (a notable exception is Adamorobe Sign Language (AdaSL) as reported by Nyst (2007)). Classifiers are generally considered to be morphemes with a non-specific meaning, which are expressed by particular configurations of the manual articulator (or: hands) and which represent entities by denoting salient characteristics. -

Fingerspelling in American Sign Language
FINGERSPELLING IN AMERICAN SIGN LANGUAGE: A CASE STUDY OF STYLES AND REDUCTION by Deborah Stocks Wager A thesis submitted to the faculty of The University of Utah in partial fulfillment of the requirements for the degree of Master of Arts Department of Linguistics The University of Utah August 2012 Copyright © Deborah Stocks Wager 2012 All Rights Reserved The University of Utah Graduate School STATEMENT OF THESIS APPROVAL The thesis of Deborah Stocks Wager has been approved by the following supervisory committee members: Marianna Di Paolo , Chair 5/10/12 Date Approved Aaron Kaplan , Member 5/10/12 Date Approved Sherman Wilcox , Member 5/10/12 Date Approved and by Edward Rubin , Chair of the Department of Linguistics and by Charles A. Wight, Dean of The Graduate School. ABSTRACT Fingerspelling in American Sign Language (ASL) is a system in which 26 one- handed signs represent the letters of the English alphabet and are formed sequentially to spell out words borrowed from oral languages or letter sequences. Patrie and Johnson have proposed a distinction in fingerspelling styles between careful fingerspelling and rapid fingerspelling, which appear to correspond to clear speech and plain speech styles. The criteria for careful fingerspelling include indexing of fingerspelled words, completely spelled words, limited coarticulation, a slow signing rate, and even rhythm, while rapid fingerspelling involves lack of indexing, increased dropping of letters, coarticulation, a faster signing rate, and the first and last letter of the words being held longer. They further propose that careful fingerspelling is used for initial uses of all fingerspelled words in running signing, with rapid fingerspelling being used for second and further mentions of fingerspelled words. -

Download, Modify and Append It As They See fit
UC Berkeley Proceedings of the Annual Meeting of the Berkeley Linguistics Society Title The Cross-linguistic Distribution of Sign Language Parameters Permalink https://escholarship.org/uc/item/1kz4f6q7 Journal Proceedings of the Annual Meeting of the Berkeley Linguistics Society, 41(41) ISSN 2377-1666 Author Tatman, Rachael Publication Date 2015 DOI 10.20354/B4414110002 Peer reviewed eScholarship.org Powered by the California Digital Library University of California PROCEEDINGS OF THE FORTY-FIRST ANNUAL MEETING OF THE BERKELEY LINGUISTICS SOCIETY February 7-8, 2015 General Session Special Session Fieldwork Methodology Editors Anna E. Jurgensen Hannah Sande Spencer Lamoureux Kenny Baclawski Alison Zerbe Berkeley Linguistics Society Berkeley, CA, USA Berkeley Linguistics Society University of California, Berkeley Department of Linguistics 1203 Dwinelle Hall Berkeley, CA 94720-2650 USA All papers copyright c 2015 by the Berkeley Linguistics Society, Inc. All rights reserved. ISSN: 0363-2946 LCCN: 76-640143 Contents Acknowledgments . v Foreword . vii The No Blur Principle Effects as an Emergent Property of Language Systems Farrell Ackerman, Robert Malouf . 1 Intensification and sociolinguistic variation: a corpus study Andrea Beltrama . 15 Tagalog Sluicing Revisited Lena Borise . 31 Phonological Opacity in Pendau: a Local Constraint Conjunction Analysis Yan Chen . 49 Proximal Demonstratives in Predicate NPs Ryan B . Doran, Gregory Ward . 61 Syntax of generic null objects revisited Vera Dvořák . 71 Non-canonical Noun Incorporation in Bzhedug Adyghe Ksenia Ershova . 99 Perceptual distribution of merging phonemes Valerie Freeman . 121 Second Position and “Floating” Clitics in Wakhi Zuzanna Fuchs . 133 Some causative alternations in K’iche’, and a unified syntactic derivation John Gluckman . 155 The ‘Whole’ Story of Partitive Quantification Kristen A .