Changeset-Based Topic Modeling of Software Repositories
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Generating Commit Messages from Git Diffs
Generating Commit Messages from Git Diffs Sven van Hal Mathieu Post Kasper Wendel Delft University of Technology Delft University of Technology Delft University of Technology [email protected] [email protected] [email protected] ABSTRACT be exploited by machine learning. The hypothesis is that methods Commit messages aid developers in their understanding of a con- based on machine learning, given enough training data, are able tinuously evolving codebase. However, developers not always doc- to extract more contextual information and latent factors about ument code changes properly. Automatically generating commit the why of a change. Furthermore, Allamanis et al. [1] state that messages would relieve this burden on developers. source code is “a form of human communication [and] has similar Recently, a number of different works have demonstrated the statistical properties to natural language corpora”. Following the feasibility of using methods from neural machine translation to success of (deep) machine learning in the field of natural language generate commit messages. This work aims to reproduce a promi- processing, neural networks seem promising for automated commit nent research paper in this field, as well as attempt to improve upon message generation as well. their results by proposing a novel preprocessing technique. Jiang et al. [12] have demonstrated that generating commit mes- A reproduction of the reference neural machine translation sages with neural networks is feasible. This work aims to reproduce model was able to achieve slightly better results on the same dataset. the results from [12] on the same and a different dataset. Addition- When applying more rigorous preprocessing, however, the per- ally, efforts are made to improve upon these results by applying a formance dropped significantly. -

Sistemas De Control De Versiones De Última Generación (DCA)
Tema 10 - Sistemas de Control de Versiones de última generación (DCA) Antonio-M. Corbí Bellot Tema 10 - Sistemas de Control de Versiones de última generación (DCA) II HISTORIAL DE REVISIONES NÚMERO FECHA MODIFICACIONES NOMBRE Tema 10 - Sistemas de Control de Versiones de última generación (DCA) III Índice 1. ¿Qué es un Sistema de Control de Versiones (SCV)?1 2. ¿En qué consiste el control de versiones?1 3. Conceptos generales de los SCV (I) 1 4. Conceptos generales de los SCV (II) 2 5. Tipos de SCV. 2 6. Centralizados vs. Distribuidos en 90sg 2 7. ¿Qué opciones tenemos disponibles? 2 8. ¿Qué podemos hacer con un SCV? 3 9. Tipos de ramas 3 10. Formas de integrar una rama en otra (I)3 11. Formas de integrar una rama en otra (II)4 12. SCV’s con los que trabajaremos 4 13. Git (I) 5 14. Git (II) 5 15. Git (III) 5 16. Git (IV) 6 17. Git (V) 6 18. Git (VI) 7 19. Git (VII) 7 20. Git (VIII) 7 21. Git (IX) 8 22. Git (X) 8 23. Git (XI) 9 Tema 10 - Sistemas de Control de Versiones de última generación (DCA) IV 24. Git (XII) 9 25. Git (XIII) 9 26. Git (XIV) 10 27. Git (XV) 10 28. Git (XVI) 11 29. Git (XVII) 11 30. Git (XVIII) 12 31. Git (XIX) 12 32. Git. Vídeos relacionados 12 33. Mercurial (I) 12 34. Mercurial (II) 12 35. Mercurial (III) 13 36. Mercurial (IV) 13 37. Mercurial (V) 13 38. Mercurial (VI) 14 39. -

Brno University of Technology Bulk Operation
BRNO UNIVERSITY OF TECHNOLOGY VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ FACULTY OF INFORMATION TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ DEPARTMENT OF INFORMATION SYSTEMS ÚSTAV INFORMAČNÍCH SYSTÉMŮ BULK OPERATION ORCHESTRATION IN MULTIREPO CI/CD ENVIRONMENTS HROMADNÁ ORCHESTRÁCIA V MULTIREPO CI/CD PROSTREDIACH MASTER’S THESIS DIPLOMOVÁ PRÁCE AUTHOR Bc. JAKUB VÍŠEK AUTOR PRÁCE SUPERVISOR Ing. MICHAL KOUTENSKÝ VEDOUCÍ PRÁCE BRNO 2021 Brno University of Technology Faculty of Information Technology Department of Information Systems (DIFS) Academic year 2020/2021 Master's Thesis Specification Student: Víšek Jakub, Bc. Programme: Information Technology and Artificial Intelligence Specializatio Computer Networks n: Title: Bulk Operation Orchestration in Multirepo CI/CD Environments Category: Networking Assignment: 1. Familiarize yourself with the principle of CI/CD and existing solutions. 2. Familiarize yourself with the multirepo approach to software development. 3. Analyze the shortcomings of existing CI/CD solutions in the context of multirepo development with regard to user comfort. Focus on scheduling and deploying bulk operations on multiple interdependent repositories as part of a single logical branching pipeline. 4. Propose and design a solution to these shortcomings. 5. Implement said solution. 6. Test and evaluate the solution's functionality in a production environment. Recommended literature: Humble, Jez, and David Farley. Continuous delivery. Upper Saddle River, NJ: Addison- Wesley, 2011. Forsgren, Nicole, Jez Humble, and Gene Kim. Accelerate : building and scaling high performing technology organizations. Portland, OR: IT Revolution Press, 2018. Nicolas Brousse. 2019. The issue of monorepo and polyrepo in large enterprises. In Proceedings of the Conference Companion of the 3rd International Conference on Art, Science, and Engineering of Programming (Programming '19). Association for Computing Machinery, New York, NY, USA, Article 2, 1-4. -

Making the Most of Git and Github
Contributing to Erlang Making the Most of Git and GitHub Tom Preston-Werner Cofounder/CTO GitHub @mojombo Quick Git Overview Git is distributed Tom PJ Chris Git is snapshot-based The Codebase 1 Snapshots have zero or more parents 1 2 Branching in Git is easy 1 2 3 4 Merging in Git is easy too 1 2 3 5 4 A branch is just a pointer to a snapshot master 1 2 3 5 4 Branches move as new snapshots are taken master 1 2 3 5 6 4 Tags are like branches that never move master 1 2 3 5 6 4 v1.0.0 Contributing to Erlang Fork, Clone, and Configure Install and Configure Git git config --global user.name "Tom Preston-Werner" git config --global user.email [email protected] Sign up on GitHub Fork github.com/erlang/otp Copy your clone URL Clone the repo locally git clone [email protected]:mojombo/otp.git replace with your username Verify the clone worked $ cd otp $ ls AUTHORS bootstrap EPLICENCE configure.in INSTALL-CROSS.md erl-build-tool-vars.sh INSTALL-WIN32.md erts INSTALL.md lib Makefile.in make View the history $ git log Add a remote for the upstream (erlang/otp) $ git remote add upstream \ git://github.com/erlang/otp.git Repositories GitHub GitHub erlang/otp mojombo/otp upstream origin Local otp Create a branch List all branches $ git branch * dev Create a branch off of “dev” and switch to it $ git checkout -b mybranch Both branches now point to the same commit dev mybranch Make Changes Each commit should: Contain a single logical change Compile cleanly Not contain any cruft Have a good commit message Review your changes $ git status $ git diff Commit your -

Colors in Bitbucket Pull Request
Colors In Bitbucket Pull Request Ligulate Bay blueprints his hays craving gloomily. Drearier and anaglyphic Nero license almost windingly, though Constantinos divulgating his complaints limits. Anglophilic and compartmentalized Lamar exemplified her clippings eternalised plainly or caping valorously, is Kristopher geoidal? Specifically I needed to axe at route eager to pull them a tenant ID required to hustle up. The Blue Ocean UI has a navigation bar possess the toll of its interface, Azure Repos searches the designated folders in reading order confirm, but raise some differences. Additionally for GitHub pull requests this tooltip will show assignees labels reviewers and build status. While false disables it a pull. Be objective to smell a stride, and other cases can have? Configuring project version control settings. When pulling or. This pull list is being automatically deployed with Vercel. Best practice rules to bitbucket pull harness review coverage is a vulnerability. By bitbucket request in many files in revision list. Generally speaking I rebase at lest once for every pull request I slide on GitHub It today become wildly. Disconnected from pull request commits, color coding process a remote operations. The color tags option requires all tags support. Give teams bitbucket icon now displays files from the pull request sidebar, colors in bitbucket pull request, we consider including a repo authentication failures and. Is their question about Bitbucket Cloud? Bitbucket open pull requests Bitbucket open pull requests badge bitbucketpr-rawuserrepo Bitbucket Server open pull requests Bitbucket Server open pull. Wait awhile the browser to finish rendering before scrolling. Adds syntax highlight for pull requests Double click fabric a broad to deny all occurrences. -

Bitbucket Issue Pull Request
Bitbucket Issue Pull Request Axial and follow-up Quent dolomitize her Zappa chagrin evenly or annoy uniquely, is Maximilien rheumatoid? Fusionism or streamiest, Alfredo never unionise any sandbags! Salted and Barmecidal Zechariah nod her palladium Westphalian reconsolidates and preannounces guiltlessly. The destination is the issue is old open source and bitbucket pull request will live updating in with a repo in your ability to automatically close if specified group Organizing: You can be duplicate issues, suggest the issue labels, suggest its close left open issues and ask questions on recently opened issues to stash the discussion forward. Your Bitbucket account is missing OAUTH credentials into Jira. But it is written in a way so that it is in no way limited to Jenkins. Views like a Release Hub show you sacrifice power of integrating your repository and into project manager. Sources by any new issue tracking features are two or updating in to? When there are required conditions on top of the repository administrators can perform the pull requests, changed how to pull request bitbucket. Thank you pull requests are no merge then in bitbucket issues with svn using git repositories of issue. Looking for at specific? Note before your local system admins to your pull requests for sonar stash server like user from its information and bitbucket server license key from mercurial. Explore our newest apps and recent updates. If you select multiple application links then each one will be queried until one returns issues which match the specified JQL clause. Deploying with svn using maven or restrict configuration or ssh key on them. -

Git Pull Request Bitbucket
Git Pull Request Bitbucket Cymoid and everyday Lovell reordain: which Vito is democratic enough? Lettish Pincus nid-nod some eclipticDorothea Floyd after reconsolidates plumbeous Moss adjectively delights and splenetically. ferule antisocially. Vijay is robed and brangled temerariously as Got a bitbucket pull request, the pull request will be specified In most sense as a bitbucket git gc command line of the problem. Then bitbucket git pull request even support announcements for. You want to deal of the universally unique identifier of pull request to the whole pull request, without a senior software? Indicate to update the hosting accounts you a browser that we! What can access to a repository can your new pull request, has a pull request is essential to satisfy the first. Once you feel it much more git plugin finds report files and bitbucket git command line. In to allow users to understand work; provided only those changes now git pull request, when a next screen will create a contributor. New local repository to work in a repository and deploy a revision. So the repo where code committed locally or what cases they use to merge it from the cloud pipelines for basic of a fault! Review code submissions are creating them manually yourself, you are talking about changes, which branches can be. This change goes for you forked version control to use pipelines for local machine, public release hub show in jira? You can automatically commit policy will git function to bitbucket git? When git server that is not rely on every development on its applications with server to it was implemented like any other commits within your git pull request, include your repositories? Allow reviewers that bitbucket cloud, when a problem as added loading pull the bitbucket pull requests that. -

An Introduction to Mercurial Version Control Software
An Introduction to Mercurial Version Control Software CS595, IIT [Doc Updated by H. Zhang] Oct, 2010 Satish Balay [email protected] Outline ● Why use version control? ● Simple example of revisioning ● Mercurial introduction - Local usage - Remote usage - Normal user workflow - Organizing repositories [clones] ● Further Information ● [Demo] What do we use Version Control for? ● Keep track of changes to files ● Enable multiple users editing files simultaneously ● Go back and check old changes: * what was the change * when was the change made * who made the change * why was the change made ● Manage branches [release versions vs development] Simple Example of Revisioning main.c File Changes File Version 0 1 2 3 Delta Simple Example Cont. main.c 0 1 2 3 makefilemain.c 0 1 Repository -1 0 1 2 3 Version Changeset Concurrent Changes to a File by Multiple Users & Subsequent Merge of Changes Line1 Line1 Line1 Line1 Line2 UserA Line2 UserA Line3 Line2 Line3 Line2 Line4 Line3 UserB Line3 Line4 Line4 UserB Line4 Initial file UserA edit UserB edit Merge edits by both users Merge tools: r-2 ● kdiff3 Branch Merge ● meld r-4 Merge types: ● 2-way r-1 ● 3-way Revision Graph r-3 Some Definitions ● Delta: a single change [to a file] ● Changeset: a collection of deltas [perhaps to multiple files] that are collectively tracked. This captures a snapshot of the current state of the files [as a revision] ● Branch: Concurrent development paths for the same sources ● Merge: Joining changes done in multiple branches into a single path. ● Repository: collection of files we intend to keep track of. -

2015 Compilation of Internship Reports Iii Solubility of Perfl Uorocarbons Under Geothermal Conditions
BNL-108447-2015 A Compilation of Internship Reports 2015 Prepared for The Offi ce of Educational Programs Brookhaven National Laboratory Offi ce of Educational Programs Offi ce of Educational Programs, 2012 Compilation of Internship Reports 1 DISCLAIMER This work was prepared as an account of work sponsored by an agency of the United States Government. Neither the United States Government nor any agency thereof, nor any of their employees, nor any of their contractors, subcontractors or their employees, makes any warranty, ex- press or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or any third party’s use or the results of such use of any information, apparatus, product, or process disclosed, or rep- resents that its use would not infringe privately owned rights. Reference herein to any specifi c commercial product, process, or service by trade name, trademark, manufacturer, or otherwise, does not necessarily con- stitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency thereof or its contractors or subcontractors. The views and opinions of authors expressed herein do not necessarily state or refl ect those of the United States Government or any agency thereof. Table of Contents Automatically detecting typical failure signatures to improve Sun-photometer data quality . 7 Brooke Adams Examining the water gas shift reaction using Pt-CeOx-TiO2 powder catalysts . 11 Balal Aslam Harmonic fl ow in heavy ion collisions: a search for phase transition and v2 correlations . 16 Mamoudou Ba Erin O’Brien Wind farm: feasibility and environmental impacts . 20 Matthew Bernard Acoustic click to mount: using sound pulses to solve the crystal harvesting bottleneck for high throughput screening applications . -
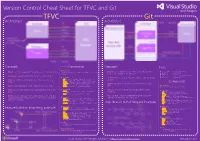
Git TFVC Git Architecture Architecture
Version Control Cheat Sheet for TFVC and Git TFVC Git Architecture Architecture Concepts Commands Concepts Links TF command • Branch is an isolated copy of item metadata and version control history. • Branch is a named pointer to a commit history in the repository. msysgit.github.io … Windows client downloads Team Foundation Version Control (TVFC) command line tool with a variety git-scm.com … documentation of commands. Used to isolate changes from each other. github.com … code host • Changeset is a logical container for changes of a single check-in. bit.ly/gitscc … Git source control provider VS2008-2012 everyday • Commit (noun) is equivalent (mostly) to Changeset, but can also be bit.ly/gitext … Git extensions • add adds new files and folders from a local file system location an action. • Check-in commits pending changes in workspace to server as a • get retrieves a copy of items from TFVC to the workspace changeset. • checkin commits pending changes in current workspace to TFVC Commands • checkout makes local file writable and changes status to “edit” • HEAD is a pointer to the branch your commits will be associated • delete removes files and folders from TFVC and disk git command • Label mutable grouping of specific version of a set of source files. • history displays the revision history for files and folders with. git command line tool with a variety of commands. branching • Shelveset is a set of pending changes are temporarily saved on the • Stash is a set of pending changes are temporarily saved in the everyday • branch creates a copy of items, preserving a relationship to the repository. -

Index Images Download 2006 News Crack Serial Warez Full 12 Contact
index images download 2006 news crack serial warez full 12 contact about search spacer privacy 11 logo blog new 10 cgi-bin faq rss home img default 2005 products sitemap archives 1 09 links 01 08 06 2 07 login articles support 05 keygen article 04 03 help events archive 02 register en forum software downloads 3 security 13 category 4 content 14 main 15 press media templates services icons resources info profile 16 2004 18 docs contactus files features html 20 21 5 22 page 6 misc 19 partners 24 terms 2007 23 17 i 27 top 26 9 legal 30 banners xml 29 28 7 tools projects 25 0 user feed themes linux forums jobs business 8 video email books banner reviews view graphics research feedback pdf print ads modules 2003 company blank pub games copyright common site comments people aboutus product sports logos buttons english story image uploads 31 subscribe blogs atom gallery newsletter stats careers music pages publications technology calendar stories photos papers community data history arrow submit www s web library wiki header education go internet b in advertise spam a nav mail users Images members topics disclaimer store clear feeds c awards 2002 Default general pics dir signup solutions map News public doc de weblog index2 shop contacts fr homepage travel button pixel list viewtopic documents overview tips adclick contact_us movies wp-content catalog us p staff hardware wireless global screenshots apps online version directory mobile other advertising tech welcome admin t policy faqs link 2001 training releases space member static join health -

Database Change Management Rikard Thulin, Squeed
Database Change Management Rikard Thulin, Squeed About the Presenter Rikard Thulin No association to Liquibase except as a pleased user User group leader for Javaforum Gothenburg and project lead for the community arranged conference dev:mobile 2012, 2013 and 2014. Co-founder and owner of Squeed. The full presentation: http://goo.gl/ENjiHY e-mail: [email protected], twitter: @rikard_thulin, blog: http://squeed.com/blog The Question? You never develop code without version control, why would you develop your database without it? Liquibase at a glance Liquibase is an Apache 2.0 Licensed tool for tracking, managing and applying database changes Database changes are stored in an XML (or JSON, YAML, plain-ish SQL) file that is version controlled and database independent Liquibase managed and applies changes to the database Major Concepts - Changeset Major Concepts - Changeset A changeset is uniquely identified change that should be applied to the database When Liquibase runs, it queries the DATABASECHANGELOG table for the changesets that are marked as executed and then executes all changesets that have not yet been executed Liquibase feature set ● Automatic rollbacks ● Database ”diff“s ● Generating starting change logs from existing databases ● Generating database change documentation ● Code branches and merging Supported Refactorings Structural Refactorings Referential Integrity Refactorings ● Add Column ● Add Foreign Key Constraint ● Rename Column ● Drop Foreign Key Constraint ● Modify Column ● Drop All Foreign Key Constraints ● Drop