Multistep Flood Inundation Forecasts with Resilient Backpropagation Neural Networks: Kulmbach Case Study
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Kommunale Partnerschaften Der Europäischen Metropolregion Nürnberg
Stadt Nürnberg Amt für Internationale Beziehungen Partnerkommunen von Städten, Gemeinden und Landkreisen in der Europäischen Metropolregion Nürnberg Stadt / Gemeinde Landkreis Partnerkommune Land Landkreis Adelsdorf Erlangen-Höchstadt, Uggiate Trevano Italien MFr Adelsdorf Erlangen-Höchstadt, Feldbach Österreich MFr Ahorn Coburg, OFr Irdning Österreich Ahorn Coburg, OFr Eisfeld Thüringen Allersberg Roth, MFr Saint-Céré Frankreich Altdorf b. Nürnberg Nürnberger Land, MFr Sehma Sachsen Altdorf b. Nürnberg Nürnberger Land, MFr Dunaharaszti Ungarn Altdorf b. Nürnberg Nürnberger Land, MFr Pfitsch Italien Altdorf b. Nürnberg Nürnberger Land, MFr Colbitz Sachsen-Anhalt Amberg kreisfrei, OPf Perigueux Frankreich Amberg kreisfrei, OPf Trikala Griechenland Amberg kreisfrei, OPf Desenzano del Garda Italien Amberg kreisfrei, OPf Bystrzyca Klodzka Polen Amberg kreisfrei, OPf Kranj Slowenien Amberg kreisfrei, OPf Usti nad Orilici Tschechien Amberg-Sulzbach Landkreis, OPf Canton Maintenon Frankreich Amberg-Sulzbach Landkreis, OPf Grafschaft Argyll Großbritannien Amberg-Sulzbach Landkreis, OPf Lkr. Sächsische Sachsen Schweiz Ammerndorf Fürth, MFr Dulliken Schweiz Ammerthal Amberg-Sulzbach, OPf Modiim Israel Ansbach kreisfrei, MFr Jingjiang China Ansbach Landkreis, MFr Jingjiang China Ansbach kreisfrei, MFr Anglet Frankreich Ansbach kreisfrei, MFr Fermo Italien Ansbach Landkreis, MFr Erzgebirgskreis Sachsen Ansbach Landkreis, MFr Mudanya Türkei Ansbach kreisfrei, MFr Bay City USA Arzberg Wunsiedel, Ofr Arzberg Österreich Arzberg Wunsiedel, Ofr Horní Slavkov -

Kulmbacher Bierwoche / Beer Week in Kulmbach Traditional 9 Day Festival ("Fifth Season") Starting in Last Week in July
AVE GERMAN WILL TRAVEL FEST IN BAYERN "Bei uns ist immer was los!" Kulmbacher Bierwoche / Beer Week in Kulmbach traditional 9 day festival ("fifth season") starting in last week in July Bierwoche (beer week) in Kulmbach July 30 - August 7, 2016: Kulmbacher is a traditional beer festival in the north of Bavaria. Just for one week in the year, master brewers of Kulmbacher brew their secret formula beer. 2016 sees in the 67th anniversary of this beer festival. Website: www.kulmbacher.de/de/bierwoche All about German beer For nine days starting in the last week of July, Kulmbach ( Kulmbach vacation rentals (/destination/kulmbach/vacalion rentals) I Kulmbach travel guide (/destinations/show/kulmbach) ) celebrates its "fifth season·. This year the Bierwoche takes place from the 26th of July to the 3rd of August. Bierwoche is Kulmbach's answer to Munich's Oktoberfest. With about 120,000 visitors per year this fair is the biggest fair worldwide that is only dedicated to beer. Whereas the Oktoberfest includes a lot of fun rides and carnival attractions and therefore has more the character of an amusement park, Kulmbach focuses on the essential: beer. Known as Germany's "secret beer capital", Kulmbach celebrates its Bierwoche for the 60s time this summer. The town is the home of four beer companies, that each put up a huge pavilion in the town center to sell their various special beer. Of course it is not only about drinking. The fair offers a great variety of typical Franconian food, which is generally quite hearty and mostly includes meat or sausages. -

Spatial Distribution of Perfluoroalkyl Acids in Surface Sediments of The
Science of the Total Environment 511 (2015) 145–152 Contents lists available at ScienceDirect Science of the Total Environment journal homepage: www.elsevier.com/locate/scitotenv Spatial distribution of perfluoroalkyl acids in surface sediments of the German Bight, North Sea Zhen Zhao a,b,c, Zhiyong Xie a,⁎, Jianhui Tang c,⁎, Gan Zhang b,RalfEbinghausa a Helmholtz-Zentrum Geesthacht, Centre for Materials and Coastal Research, Institute of Coastal Research, Max-Plank Street 1, 21502 Geesthacht, Germany b State Key Laboratory of Organic Geochemistry, Guangzhou Institute of Geochemistry, CAS, Kehua Road 511, Guangzhou 510631, China c Yantai Institute of Coastal Zone Research, CAS, Chunhui Road 17, Yantai 264003, China HIGHLIGHTS • Declining PFOA and PFOS levels implied the effect of regulating C8-based products • PFBA and PFBS occurred in the sediments of the German Bight • PFOS in marine sediment may present a risk for benthic organisms in the German Bight article info abstract Article history: Perfluoroalkyl acids (PFAAs) have been determined in the environment globally. However, studies on the occur- Received 22 October 2014 rence of PFAAs in marine sediment remain limited. In this study, 16 PFAAs are investigated in surface sediments Received in revised form 18 December 2014 from the German Bight, which provided a good overview of the spatial distribution. The concentrations of ΣPFAAs Accepted 19 December 2014 ranged from 0.056 to 7.4 ng/g dry weight. The highest concentration was found at the estuary of the River Ems, Available online xxxx which might be the result of local discharge source. Perfluorooctane sulfonic acid (PFOS) was the dominant com- Editor: Adrian Covaci pound, and the enrichment of PFOS in sediment might be strongly related to the compound structure itself. -

Kultbier Sucht Heimat: Wo "Keiler" Gebraut Wird | Mainpost.De
Kultbier sucht Heimat: Wo "Keiler" gebraut wird | mainpost.de http://www.mainpost.de/regional/main-spessart/Brauereien;art774,9510494 Regional Meine Themen Überregional Kickers Sport Freizeit Mediathek Anzeigen Service Mobil Shop Karriere Wetter Donnerstag, 02. März 2017 Würzburg Schweinfurt Bad Kissingen Rhön-Grabfeld Haßberge Kitzingen Main-Spessart Main-Tauber LOHR/KULMBACH Kultbier sucht Heimat: Wo "Keiler" gebraut wird Björn Kohlhepp 21. Februar 2017 18:00 Uhr Aktualisiert am: 25. Februar 2017 03:33 Uhr "Keiler Bier" - das erfolgreichste Weißbier Unterfrankens kommt heute teilweise aus Oberfranken. Das gefällt nicht jedem, schmecken tut's offenbar trotzdem. Foto: Björn Kohlhepp er zufällig einmal mit dem Zug durch Kulmbach kommt, etwa auf dem Weg nach Bayreuth, dem W fallen auf dem an der Zugstrecke gelegenen Gelände der Kulmbacher Brauerei womöglich sehr vertraut aussehende Bierkästen auf: „Keiler Bier“. Um sie herum sieht man Kästen von Biermarken wie Leikeim, EKU, Kulmbacher, Sternla, Mönchshof oder Kapuziner. Dass dort Keiler-Kästen stehen, verwundert nicht, schließlich gehört die Keiler Bier GmbH zur Würzburger Hofbräu, die wiederum Teil der Kulmbacher Brauerei AG ist. Das wirft jedoch die Frage auf, wo das ehemalige Lohrer Bier, jetzt „Keiler Bier“, eigentlich gebraut wird. In Kulmbach? Das wurde bisher nur gemunkelt. Zumindest beim recht neuen Kellerbier, einer trüben, typisch oberfränkischen Bierspezialität – laut Eigenwerbung „nach urtypischer Brautradition aus dem Spessart“ –, liegt der Verdacht nahe. Während man in Würzburg auf derlei Anfragen eher reserviert reagiert, schreibt Helga Metzel, Pressesprecherin der Kulmbacher Brauerei, ohne Umschweife auf unsere Anfrage: „Alle Keiler- Spezialitäten in der Bügelverschlussflasche werden in Kulmbach gebraut und auch abgefüllt.“ In der Bügelflasche gibt es das helle und dunkle Weizen, das Kellerbier und das Land-Pils. -

48. Newsletter Migration & Integration
48. Newsletter Migration & Integration Inhaltsverzeichnis . Aktuelle Situation im Landkreis . Corona-Krise: Survival-Kit für Männer unter Druck . Gemeinsam gegen Corona Video-Chat . Sprachkurse und Integrationsprojekte als Präsenzveranstaltungen . Deutschkursliste des Landkreises Oberallgäu . Weiterbildungsangebote von BILDUNG und BERUF . Informationen zum Masterstudiengang „Flucht, Migration, Gesellschaft“ . Webinar zum Thema Menschenhandel . Bayernweites Webinar durch das hauptamtliche Integrationslotsen-Projekt . Veranstaltungshinweis Engagiert für Integration . Hilfe bei häuslicher Gewalt . Sammelband – Migration, Religion, Gender und Bildung . BrückenBauen gUG – „Land der Kulturen“ goes feminine 48. Newsletter Migration & Integration – 5. Ausgabe 2020 Liebe Integrationsmitwirkende, Liebe Ehrenamtliche, Liebe Interessierte, den Beginn macht im aktuellen Newsletter die zahlenmäßige Darstellung der aktuellen Situation im Landkreis. Im weiteren Verlauf finden Sie wie gewohnt Aktuelles, Termine und Wissenswertes aus der Region, Bayern und der Welt sowie einige Informationen und Wissenswertes über die aktuelle Ausnahmesituation aufgrund des Coronavirus. Wir wünschen Ihnen viel Freude beim Lesen! Bei Fragen und Anregungen stehen wir Ihnen jederzeit zur Verfügung. Ihre Andrea Schmid Susanne Grimm Miriam Duran Hülya Dirlik Bildungsbüro Landkreis Oberallgäu Beauftragte für Migration Hauptamtliche und Integration Integrationslotsin - 1 - 48. Newsletter Migration & Integration – 5. Ausgabe 2020 Aktuelle Situation im Landkreis Quelle: Amt für -

Verband Für Landwirtschaftliche Fachbildung Kulmbach Mitteilungsblatt Juli 2021
Verband für landwirtschaftliche Fachbildung Kulmbach Mitteilungsblatt Juli 2021 Sehr geehrte Mitglieder, sehr geehrte Damen und Herren! Zum 1. Juli 2021 wurde die Neuausrichtung der Landwirtschaftsverwaltung an den Ämtern für Ernährung, Landwirtschaft und Forsten (ÄELF) in die Praxis umgesetzt. Die bisher selbständigen Landwirtschaftsämter Kulmbach und Coburg werden zu einer Einheit zusammengefasst. Dadurch werden die Führungsstrukturen verschlankt und Synergieeffekte erzielt. Die damit verbundenen personellen Veränderungen im Bereich der Landwirtschaft sind überschaubar. Viele der Mitarbeiter sind in den neuen Strukturen in ihrem Aufgabenspektrum verblieben. Außerdem waren mit dem bisherigen Arbeitsplatz keine gravierenden, örtlichen Veränderungen verbunden. Die Landwirte werden an den Dienststellen des Landwirtschaftsamtes in den Landkreisen Bad Staffelstein, Coburg, Kronach und Kulmbach weiterhin, wie gewohnt, ihren bekannten Ansprechpartner finden. Der Bereich Forsten wird durch die Neuausrichtung nur in Randbereichen tangiert. In der Landwirtschaft stehen nunmehr im Focus der Neuausrichtung verstärkt Themen wie: 1. Beratung der Unternehmensentwicklung, 2. Ressourcen, Umwelt und Klima, 3. Verbesserung Tierhaltung und Tierwohl, 4. Regional und Bio, 5. Alltagskompetenz und Ernährung, 6. Verankerung in der Gesellschaft. Der vlf und die Landwirtschaftsverwaltung sind seit mehr als 100 Jahren Partner in der Aus-, Fort-, und Weiterbildung sowie dem Wissenstransfer im land- und hauswirtschaftlichen Bereich. Sie profitieren gegenseitig voneinander -
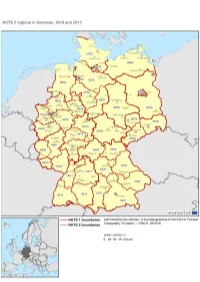
Nuts-Map-DE.Pdf
GERMANY NUTS 2013 Code NUTS 1 NUTS 2 NUTS 3 DE1 BADEN-WÜRTTEMBERG DE11 Stuttgart DE111 Stuttgart, Stadtkreis DE112 Böblingen DE113 Esslingen DE114 Göppingen DE115 Ludwigsburg DE116 Rems-Murr-Kreis DE117 Heilbronn, Stadtkreis DE118 Heilbronn, Landkreis DE119 Hohenlohekreis DE11A Schwäbisch Hall DE11B Main-Tauber-Kreis DE11C Heidenheim DE11D Ostalbkreis DE12 Karlsruhe DE121 Baden-Baden, Stadtkreis DE122 Karlsruhe, Stadtkreis DE123 Karlsruhe, Landkreis DE124 Rastatt DE125 Heidelberg, Stadtkreis DE126 Mannheim, Stadtkreis DE127 Neckar-Odenwald-Kreis DE128 Rhein-Neckar-Kreis DE129 Pforzheim, Stadtkreis DE12A Calw DE12B Enzkreis DE12C Freudenstadt DE13 Freiburg DE131 Freiburg im Breisgau, Stadtkreis DE132 Breisgau-Hochschwarzwald DE133 Emmendingen DE134 Ortenaukreis DE135 Rottweil DE136 Schwarzwald-Baar-Kreis DE137 Tuttlingen DE138 Konstanz DE139 Lörrach DE13A Waldshut DE14 Tübingen DE141 Reutlingen DE142 Tübingen, Landkreis DE143 Zollernalbkreis DE144 Ulm, Stadtkreis DE145 Alb-Donau-Kreis DE146 Biberach DE147 Bodenseekreis DE148 Ravensburg DE149 Sigmaringen DE2 BAYERN DE21 Oberbayern DE211 Ingolstadt, Kreisfreie Stadt DE212 München, Kreisfreie Stadt DE213 Rosenheim, Kreisfreie Stadt DE214 Altötting DE215 Berchtesgadener Land DE216 Bad Tölz-Wolfratshausen DE217 Dachau DE218 Ebersberg DE219 Eichstätt DE21A Erding DE21B Freising DE21C Fürstenfeldbruck DE21D Garmisch-Partenkirchen DE21E Landsberg am Lech DE21F Miesbach DE21G Mühldorf a. Inn DE21H München, Landkreis DE21I Neuburg-Schrobenhausen DE21J Pfaffenhofen a. d. Ilm DE21K Rosenheim, Landkreis DE21L Starnberg DE21M Traunstein DE21N Weilheim-Schongau DE22 Niederbayern DE221 Landshut, Kreisfreie Stadt DE222 Passau, Kreisfreie Stadt DE223 Straubing, Kreisfreie Stadt DE224 Deggendorf DE225 Freyung-Grafenau DE226 Kelheim DE227 Landshut, Landkreis DE228 Passau, Landkreis DE229 Regen DE22A Rottal-Inn DE22B Straubing-Bogen DE22C Dingolfing-Landau DE23 Oberpfalz DE231 Amberg, Kreisfreie Stadt DE232 Regensburg, Kreisfreie Stadt DE233 Weiden i. -

Bavarian Cloth Seals in Hungary Maxim Mordovin* Eötvös Loránd University, Faculty of Humanities, Institute of Archaeological Sciences
Hungarian Historical Review 6, no. 1 (2017): 82–110 Bavarian Cloth Seals in Hungary Maxim Mordovin* Eötvös Loránd University, Faculty of Humanities, Institute of Archaeological Sciences The import of cloth was one of the most important sectors of international trade throughout the European Middle Ages and early modern period. Its history and impact on medieval economies have been studied by scholars for quite a long time, creating the impression that there are no new sources waiting to be found. Improved methods of archaeological excavations, however, have produced data significant to the international trade connections. This data was hidden in small leaden seals that were attached to the textile fabrics indicating their quality and origin. In this paper, I examine the cloth seals originating from Bavaria that have been found so far in the Carpathian Basin and compare the information provided by them with that already known from the available written sources. This comparison leads to several important conclusions. Perhaps most importantly, the dating range of the known cloth seals can be convincingly limited within the fifteenth and sixteenth centuries for all the nineteen known textile production centers. Also, the cloth marked by these seals indicates that some serious changes arose in textile consumption at the end of the Middle Ages. In this study, I identify some new places of origin not mentioned in the written sources and trace their distribution in the medieval Kingdom of Hungary. Keywords: international trade, textile production, -

POWDER Veterinary Snrgeon. (Nhkminf!
•u c h a n a n R e c o r d . (NHKMINf! ? rU BUSHED EVERT THURSDAY, ---- i*Et----- IO H K O- H OLM ES. CARMIR. SMITH, NILES, M ICH., TERM S. S I .5 0 PER YEAR Has opened the most complete Undertaking Pari lore In Southern Michigan. PAYABLE IX ADVANCE* Burial Caskets and Cases,. ihehisismstes doe uns uumicim VOLUME XXIII. Draped and Plain, solid Walnut, Oak, Chestnut and Cedar, finished and line covered Caskets and Cases. Crape, Mummy and Broadcloth, Block OFFICE—InRecotdButtdlng.OakStreot and White SilkPlnsh, and Velvet covered Caskets A LUCKY BREAK. There was not the faintest spark of It Don’ t K ill Them. Hoxv Mollie Finney Got a H nsband. constantly on hand, coQuetry in her maimer, and she did The story of the Ntnv.'o'iudl.uid dog Perhaps the most romantic of all the TRIMMINGS. BTE. A. WYMAN. not disguise from him her deteiiniiia belonging tivHilaries Tupper, an Eighth tales of ancient Brunswick is that of Business Directory. tion never to marry. They often in Gold and Silver Plated, Bonton, Silk -and Em They were swinging in a hammock avenue restaurant proprietor, is one Mollie Finney and how she got a hus bossed flash, and Satin Combination Handles On the backpiazza wide, dulged in pleasant arguments on the that will startle a great many persons band. It was a wild beginning, but a add Tips. Knight of Pythons, Masonic, Odd Fel SABBATH SERVICES. subject, but lie failed to convince her lows and G. A. R. Trimmings and Plates o f the And they had no thought of loving who are studying the mysterious forces good old-fashioned ending. -

Amtsblatt Des Landkreises Bamberg
Landratsamt Bamberg Amtsblatt des Landkreises Bamberg Nr. 32 / 2021 vom 9. August 2021 Herausgeber: Landratsamt Bamberg Ludwigstraße 23 Telefon: 0951 85-0 E-Mail: [email protected]. Postfach, 96045 Bamberg Telefax: 0951 85-125 Internet: www.landkreis-bamberg. Inhaltsverzeichnis Aufgebot Sparbuch Seite 132 Haushaltssatzung des Zweckverbandes Berufsschulen Stadt und Landkreis Bamberg für das Haushaltsjahr 2021 Seite 132 Bundestagswahl am 26. September 2021; Bekanntmachung der zugelassenen Kreiswahlvorschläge Seite 133 - 135 Vollzug des Gesetzes über die Umweltverträglichkeitsprüfung (UVPG); Feststellung der Pflicht zur Umweltverträglichkeitsprüfung für den Betrieb einer Abwasserbehandlungsanlage (hier Kläranlage Burgebrach) durch die Verwaltungsgemeinschaft Burgebrach, Landkreis Bamberg; Bekanntgabe des Ergebnisses der Vorprüfung gemäß § 5 Abs. 1 UVPG Seite 135 Aufgebot Sparbuch Das Sparkassenbuch der Sparkasse Bamberg in Bamberg Nr. 3100240567 Harald Zorn ist zu Verlust gegangen. Es wird hiermit aufgeboten. Der/die Inhaber des Sparkassenbuches wird/werden aufgefordert, unter Vorlage der Sparurkunde seine/ihre Rechte binnen einer Frist von drei Monaten, von heute an gerechnet, bei der Sparkasse Bamberg oder de- ren Geschäftsstellen anzumelden; andernfalls das Sparkassenbuch für kraftlos erklärt wird. Bamberg, 26. Juli 2021 Sparkasse Bamberg ________________________________________________________________________________________ Haushaltssatzung des Zweckverbandes Berufsschulen Stadt und Landkreis Bamberg für das Haushaltsjahr 2021 -

Zone-Based, Robust Flood Evacuation Planning$
Zone-based, Robust Flood Evacuation PlanningI Sabine Buttner¨ a, Marc Goerigkb,∗ aTechnische Universit¨atKaiserslautern, Kaiserslautern, Germany bUniversity of Lancaster, Lancaster, United Kingdom Abstract We consider the problem to evacuate several regions due to river flooding, where suffi- cient time is given to plan ahead. To ensure a smooth evacuation procedure, our model includes the decision which regions to assign to which shelter, and when evacuation orders should be issued, such that roads do not become congested. Due to uncertainty in weather forecast, several possible scenarios are simultane- ously considered in a robust optimization framework. To solve the resulting integer program, we apply a Tabu search algorithm based on decomposing the problem into better tractable subproblems. Computational experiments on random instances and an instance based on Kulmbach, Germany, data show considerable improvement com- pared to an MIP solver provided with a strong starting solution. Keywords: Evacuation Planning, Flood Evacuation, Robust Optimization 1. Introduction World-wide, flood damages have been on the rise and will likely continue to pose a further increasing risk. The floods in June 2013 are estimated to amount to 12 billion Euro in losses [Re13], while the floods in India and Pakistan during September 2014 caused over 5 billion US$ and 665 fatalities alone [Re14]. Yearly losses within the EU are estimated to increase to over 23 billion Euro annually by 2050 [JHSF+14]. Due to highly sophisticated weather forecasts, floods do not hit us completely by surprise, and do not belong to the class of no-notice emergencies. Therefore, opera- tions research has great potential to prepare for and to mitigate flood effects. -

Robert Schumann a Youth Pilgrimage to Munich 1828
Robert Schumann Youth Pilgrimage Robert Schumann A Youth Pilgrimage to Munich 1828 Robert Schumann Youth Pilgrimage Introduction The young Schumann’s original sheets titled “Jünglings-Wallfarthen [Youth Pilgrimages]”, which he wrote down as a student in Heidelberg in 1830, are held at the Robert Schumann House in Zwickau. The nine journeys made between 1826 and 1830 took him to the following places: 1. Journey to Gotha, Eisenach, Weimar, Jena, 1826 2. Journey to Prague, 1827 3. Journey to Munich through Bavaria, 1828 4. Journey on the Rhine up to Heidelberg, 1829 5. Journey through Switzerland up to Venice, 1829 6. Journey through Baden to Strasbourg, 1830 7. Journey through Hesse to Frankfurt, 1830 8. Schwetzingen, Speyer, Worms and Rhenish Bavaria (Palatinate), 1830 9. Journey on the Rhine to Wesel and through Westphalia to Leipzig, 1830 The subsequent seven pages of prose text were titled “Erstes Gemählde. Reise nach Prag [First Picture. Journey to Prague]” but broke off in the middle of a sentence describing Colditz Castle. Unfortunately, Schumann never again got around to writing out his diary, kept in the form of keywords, as a continuous travel report. The slightly abridged version of Pilgrimage No. 3 below only covers the period between his departure from Zwickau and his stay in Munich. Legal notice Concept: Walter Müller, CH-8320 Fehraltorf Design/ prepress/print: Bucherer Druck AG, 8620 Wetzikon Photographs: Walter Müller Issue: July 2015 Robert Schumann Youth Pilgrimage Zwickau–Bayreuth Diary of Robert Schumann [Thursday, 24th April: Zwickau (departure early 01:00) – Plauen – Hof – reunion with Rosen1 – arrival Bayreuth evening 19:30 (Goldene Sonne Inn mediocre) Travel time: Zwickau–Hof 12 hours, Hof–Bayreuth 15 hours Friday, 25th April: Jean Paul’s tomb2 – deep pain – Rollwenzel Inn3 – Jean Paul’s study4 and chair – Hermitage5 – fond memory of Jean Paul – stroll to Fantasie Palace6 – monuments] 1 Gisbert Rosen, youth friend of Schumann, who started to study law together with him at the University of Leipzig.