A Functional Framework for Content Management
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

User Office, Proposal Handling and Analysis Software
NOBUGS2002/031 October 11, 2002 Session Key: PB-1 User office, proposal handling and analysis software Jörn Beckmann, Jürgen Neuhaus Technische Universität München ZWE FRM-II D-85747 Garching, Germany [email protected] At FRM-II the installation of a user office software is under consideration, supporting tasks like proposal handling, beam time allocation, data handling and report creation. Although there are several software systems in use at major facilities, most of them are not portable to other institutes. In this paper the requirements for a modular and extendable user office software are discussed with focus on security related aspects like how to prevent a denial of service attack on fully automated systems. A suitable way seems to be the creation of a web based application using Apache as webserver, MySQL as database system and PHP as scripting language. PRESENTED AT NOBUGS 2002 Gaithersburg, MD, U.S.A, November 3-5, 2002 1 Requirements of user office software At FRM-II a user office will be set up to deal with all aspects of business with guest scientists. The main part is the handling and review of proposals, allocation of beam time, data storage and retrieval, collection of experimental reports and creation of statistical reports about facility usage. These requirements make off-site access to the user office software necessary, raising some security concerns which will be addressed in chapter 2. The proposal and beam time allocation process is planned in a way that scientists draw up a short description of the experiment including a review of the scientific background and the impact results from the planned experiment might have. -

Indice General
i Indice general 4. Apache Lenya 1.4: Arquitectura 1 4.1. Introduccion .................................... 1 4.1.1. Arquitectura del sistema ......................... 1 4.1.2. Arquitectura del gestor de contenidos ................. 2 4.2. Conceptos basicos ................................ 4 4.2.1. Modulos .................................. 4 4.2.2. Polimor smo de las publicaciones .................... 4 4.2.2.1. El protocolo fallback:// .................... 6 4.3. La capa de presentacion ............................. 6 4.3.1. Los sitemaps de Lenya .......................... 6 4.3.1.1. El espacio de URIs ....................... 6 4.3.1.2. Proceso de una peticion .................... 8 4.4. La capa de gestion ................................ 11 4.4.1. Marco de casos de uso .......................... 11 4.4.1.1. Introduccion .......................... 11 4.4.1.2. Descripciondel funcionamiento ................ 13 4.4.1.3. Implementacionde un caso de uso .............. 13 4.4.2. Control de acceso ............................. 16 4.4.2.1. De niciones basicas ...................... 17 4.4.2.2. Componentes .......................... 18 4.4.2.3. Los mecanismos de autorizaciony autenticacion ...... 19 4.4.3. Flujo de trabajo ............................. 19 4.4.3.1. La de niciondel ujo de trabajo ............... 21 4.4.3.2. Personalizaciondel ujo de trabajo ............. 23 4.4.4. Noti caciones ............................... 23 4.5. La capa de repositorio .............................. 24 4.5.1. Acceso al repositorio ........................... 24 4.5.1.1. Control optimista de concurrencia .............. 24 4.5.1.2. Check-In y Check-Out ..................... 25 4.5.2. Control de versiones ........................... 25 4.6. Arquitectura fsica ................................ 25 4.6.1. Estructura de directorios de una publicacion ............. 25 4.6.2. Estructura de directorios de un modulo ................ 27 ii 4.6.2.1. -

An Interdisciplinary Journal
FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISMFast Capitalism FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM ISSNFAST XXX-XXXX CAPITALISM FAST Volume 1 • Issue 1 • 2005 CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM -

Zope Documentation Release 5.3
Zope Documentation Release 5.3 The Zope developer community Jul 31, 2021 Contents 1 What’s new in Zope 3 1.1 What’s new in Zope 5..........................................4 1.2 What’s new in Zope 4..........................................4 2 Installing Zope 11 2.1 Prerequisites............................................... 11 2.2 Installing Zope with zc.buildout .................................. 12 2.3 Installing Zope with pip ........................................ 13 2.4 Building the documentation with Sphinx ............................... 14 3 Configuring and Running Zope 15 3.1 Creating a Zope instance......................................... 16 3.2 Filesystem Permissions......................................... 17 3.3 Configuring Zope............................................. 17 3.4 Running Zope.............................................. 18 3.5 Running Zope (plone.recipe.zope2instance install)........................... 20 3.6 Logging In To Zope........................................... 21 3.7 Special access user accounts....................................... 22 3.8 Troubleshooting............................................. 22 3.9 Using alternative WSGI server software................................. 22 3.10 Debugging Zope applications under WSGI............................... 26 3.11 Zope configuration reference....................................... 27 4 Migrating between Zope versions 37 4.1 From Zope 2 to Zope 4 or 5....................................... 37 4.2 Migration from Zope 4 to Zope 5.0.................................. -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Guide to Open Source Solutions
White paper ___________________________ Guide to open source solutions “Guide to open source by Smile ” Page 2 PREAMBLE SMILE Smile is a company of engineers specialising in the implementing of open source solutions OM and the integrating of systems relying on open source. Smile is member of APRIL, the C . association for the promotion and defence of free software, Alliance Libre, PLOSS, and PLOSS RA, which are regional cluster associations of free software companies. OSS Smile has 600 throughout the World which makes it the largest company in Europe - specialising in open source. Since approximately 2000, Smile has been actively supervising developments in technology which enables it to discover the most promising open source products, to qualify and assess them so as to offer its clients the most accomplished, robust and sustainable products. SMILE . This approach has led to a range of white papers covering various fields of application: Content management (2004), portals (2005), business intelligence (2006), PHP frameworks (2007), virtualisation (2007), and electronic document management (2008), as well as PGIs/ERPs (2008). Among the works published in 2009, we would also cite “open source VPN’s”, “Firewall open source flow control”, and “Middleware”, within the framework of the WWW “System and Infrastructure” collection. Each of these works presents a selection of best open source solutions for the domain in question, their respective qualities as well as operational feedback. As open source solutions continue to acquire new domains, Smile will be there to help its clients benefit from these in a risk-free way. Smile is present in the European IT landscape as the integration architect of choice to support the largest companies in the adoption of the best open source solutions. -
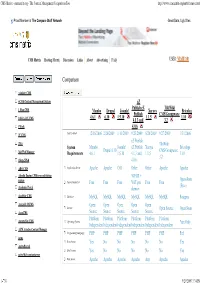
CMS Matrix - Cmsmatrix.Org - the Content Management Comparison Tool
CMS Matrix - cmsmatrix.org - The Content Management Comparison Tool http://www.cmsmatrix.org/matrix/cms-matrix Proud Member of The Compare Stuff Network Great Data, Ugly Sites CMS Matrix Hosting Matrix Discussion Links About Advertising FAQ USER: VISITOR Compare Search Return to Matrix Comparison <sitekit> CMS +CMS Content Management System eZ Publish eZ TikiWiki 1 Man CMS Mambo Drupal Joomla! Xaraya Bricolage Publish CMS/Groupware 4.6.1 6.10 1.5.10 1.1.5 1.10 1024 AJAX CMS 4.1.3 and 3.2 1Work 4.0.6 2F CMS Last Updated 12/16/2006 2/26/2009 1/11/2009 9/23/2009 8/20/2009 9/27/2009 1/31/2006 eZ Publish 2flex TikiWiki System Mambo Joomla! eZ Publish Xaraya Bricolage Drupal 6.10 CMS/Groupware 360 Web Manager Requirements 4.6.1 1.5.10 4.1.3 and 1.1.5 1.10 3.2 4Steps2Web 4.0.6 ABO.CMS Application Server Apache Apache CGI Other Other Apache Apache Absolut Engine CMS/news publishing 30EUR + system Open-Source Approximate Cost Free Free Free VAT per Free Free (Free) Academic Portal domain AccelSite CMS Database MySQL MySQL MySQL MySQL MySQL MySQL Postgres Accessify WCMS Open Open Open Open Open License Open Source Open Source AccuCMS Source Source Source Source Source Platform Platform Platform Platform Platform Platform Accura Site CMS Operating System *nix Only Independent Independent Independent Independent Independent Independent ACM Ariadne Content Manager Programming Language PHP PHP PHP PHP PHP PHP Perl acms Root Access Yes No No No No No Yes ActivePortail Shell Access Yes No No No No No Yes activeWeb contentserver Web Server Apache Apache -

Table of Content Plone Installation
Table of content 1. Plone Installation • Plone dependencies • Download Plone 4.3 Unified Installer • Install Plone 2. Install Baobab LIMS 3. Test your installation Plone Installation Here we describe how to install Plone onto the Ubuntu Linux system. For an installation in a different operating system check the Plone online documentation, here. The installation process requires users to have root privileges and a basic knowledge of Linux command lines using the Terminal. If you are not familiar with a UNIX operating system, read this tutorial Linux shell tutorial. Please note that a single line must be complete at a time. Plone dependencies Plone framework requires the installation of additional system packages. Without these packages available in your system, Plone will not compile. sudo apt-get install build-essential gcc python-dev git-core libffi-dev sudo apt-get install libpcre3 libpcre3-dev autoconf libtool pkg-config sudo apt-get install zlib1g-dev libssl-dev libexpat1-dev libxslt1.1 sudo apt-get install gnuplot libcairo2 libpango1.0-0 libgdk-pixbuf2.0-0 Download Plone 4.3 Unified Installer The Baobab LIMS is implemented and tested with Plone 4.3.11, a version released in 2016-09-12. You can download Plone 4.3.x by visiting the Plone site. Select and click on the Unified installer of your choice or use wget command line in your terminal with the path to the Plone version to install. Only Plone 4.3.11 can be used. wget --no-check-certificate https://launchpad.net/plone/4.3/4.3.11/+download/Plone- 4.3.11-r1-UnifiedInstaller.tgz Version 1.1 Installation If the download has been done from the Plone site, the installer would be located in the ~/Downloads directory. -

Using Wordpress to Manage Geocontent and Promote Regional Food Products
Farm2.0: Using Wordpress to Manage Geocontent and Promote Regional Food Products Amenity Applewhite Farm2.0: Using Wordpress to Manage Geocontent and Promote Regional Food Products Dissertation supervised by Ricardo Quirós PhD Dept. Lenguajes y Sistemas Informaticos Universitat Jaume I, Castellón, Spain Co-supervised by Werner Kuhn, PhD Institute for Geoinformatics Westfälische Wilhelms-Universität, Münster, Germany Miguel Neto, PhD Instituto Superior de Estatística e Gestão da Informação Universidade Nova de Lisboa, Lisbon, Portugal March 2009 Farm2.0: Using Wordpress to Manage Geocontent and Promote Regional Food Products Abstract Recent innovations in geospatial technology have dramatically increased the utility and ubiquity of cartographic interfaces and spatially-referenced content on the web. Capitalizing on these developments, the Farm2.0 system demonstrates an approach to manage user-generated geocontent pertaining to European protected designation of origin (PDO) food products. Wordpress, a popular open-source publishing platform, supplies the framework for a geographic content management system, or GeoCMS, to promote PDO products in the Spanish province of Valencia. The Wordpress platform is modified through a suite of plug-ins and customizations to create an extensible application that could be easily deployed in other regions and administrated cooperatively by distributed regulatory councils. Content, either regional recipes or map locations for vendors and farms, is available for syndication as a GeoRSS feed and aggregated with outside feeds in a dynamic web map. To Dad, Thanks for being 2TUF: MTLI 4 EVA. Acknowledgements Without encouragement from Dr. Emilio Camahort, I never would have had the confidence to ensure my thesis handled the topics I was most passionate about studying - sustainable agriculture and web mapping. -

UC Irvine UC Irvine Previously Published Works
UC Irvine UC Irvine Previously Published Works Title Dimethyl Fumarate Alleviates Dextran Sulfate Sodium-Induced Colitis, through the Activation of Nrf2-Mediated Antioxidant and Anti-inflammatory Pathways. Permalink https://escholarship.org/uc/item/7n185057 Journal Antioxidants (Basel, Switzerland), 9(4) ISSN 2076-3921 Authors Li, Shiri Takasu, Chie Lau, Hien et al. Publication Date 2020-04-24 DOI 10.3390/antiox9040354 Peer reviewed eScholarship.org Powered by the California Digital Library University of California antioxidants Article Dimethyl Fumarate Alleviates Dextran Sulfate Sodium-Induced Colitis, through the Activation of Nrf2-Mediated Antioxidant and Anti-nflammatory Pathways Shiri Li 1, Chie Takasu 1 , Hien Lau 1, Lourdes Robles 1, Kelly Vo 1, Ted Farzaneh 2, Nosratola D. Vaziri 3, Michael J. Stamos 1 and Hirohito Ichii 1,* 1 Department of Surgery, University of California, Irvine, CA 92868, USA; [email protected] (S.L.); [email protected] (C.T.); [email protected] (H.L.); [email protected] (L.R.); [email protected] (K.V.); [email protected] (M.J.S.) 2 Department of Pathology, University of California, Irvine, CA 92868, USA; [email protected] 3 Department of Medicine, University of California, Irvine, CA 92868, USA; [email protected] * Correspondence: [email protected]; Tel.: +1-714-456-8590; Fax: +1-714-456-8796 Received: 14 March 2020; Accepted: 22 April 2020; Published: 24 April 2020 Abstract: Oxidative stress and chronic inflammation play critical roles in the pathogenesis of ulcerative colitis (UC) and inflammatory bowel diseases (IBD). A previous study has demonstrated that dimethyl fumarate (DMF) protects mice from dextran sulfate sodium (DSS)-induced colitis via its potential antioxidant capacity, and by inhibiting the activation of the NOD-, LRR- and pyrin domain-containing protein 3 (NLRP3) inflammasome. -

The Application of Drupal to Website Development in Academic Libraries Cristina Tofan Eastern Kentucky University, [email protected]
Eastern Kentucky University Encompass Library Faculty and Staff aP pers and Presentations EKU Libraries January 2010 The Application of Drupal to Website Development in Academic Libraries Cristina Tofan Eastern Kentucky University, [email protected] Follow this and additional works at: http://encompass.eku.edu/faculty_staff Part of the Library and Information Science Commons Recommended Citation Tofan, Cristina, "The Application of Drupal to Website Development in Academic Libraries" (2010). Library Faculty and Staff aP pers and Presentations. Paper 2. http://encompass.eku.edu/faculty_staff/2 This is brought to you for free and open access by the EKU Libraries at Encompass. It has been accepted for inclusion in Library Faculty and Staff Papers and Presentations by an authorized administrator of Encompass. For more information, please contact [email protected]. The Application of Drupal to Website Development in Academic Libraries Cristina Tofan Eastern Kentucky University Libraries 1. Introduction Academic libraries think very carefully about how they design their website, because the website is the primary avenue to provide access to resources, do library instruction, promote collections, services and events, and connect with students, faculty and potential donors. Library websites are expected to be able to respond to two major types of needs: to offer high functionality to the patrons, and to allow librarians and library staff to participate in the un‐intermediated creation and publication of content. Web content management systems are software systems that provide tools for both. In the realm of open source content management systems, Drupal has the lead compared to other systems, in its adoption in libraries. -

What Is Open Source?
Putting OPen SOurce tO WOrk in the enterPriSe: A guide tO riSkS And OPPOrtunitieS © Copyright 2007 SAP AG. All rights reserved. HTML, XML, XHTML and W3C are trademarks or registered trademarks of W3C®, World Wide Web Consortium, No part of this publication may be reproduced or transmitted in Massachusetts Institute of Technology. any form or for any purpose without the express permission of SAP AG. The information contained herein may be changed Java is a registered trademark of Sun Microsystems, Inc. without prior notice. JavaScript is a registered trademark of Sun Microsystems, Inc., Some software products marketed by SAP AG and its distributors used under license for technology invented and implemented contain proprietary software components of other software by Netscape. vendors. MaxDB is a trademark of MySQL AB, Sweden. Microsoft, Windows, Excel, Outlook, and PowerPoint are registered trademarks of Microsoft Corporation. SAP, R/3, mySAP, mySAP.com, xApps, xApp, SAP NetWeaver, Duet, PartnerEdge, and other SAP products and services IBM, DB2, DB2 Universal Database, OS/2, Parallel Sysplex, mentioned herein as well as their respective logos are trademarks MVS/ESA, AIX, S/390, AS/400, OS/390, OS/400, iSeries, pSeries, or registered trademarks of SAP AG in Germany and in several xSeries, zSeries, System i, System i5, System p, System p5, System x, other countries all over the world. All other product and service System z, System z9, z/OS, AFP, Intelligent Miner, WebSphere, names mentioned are the trademarks of their respective compa- Netfinity, Tivoli, Informix, i5/OS, POWER, POWER5, POWER5+, nies. Data contained in this document serves informational OpenPower and PowerPC are trademarks or registered purposes only.