Download.Oracle.Com/Javase/1.4.2/Docs/Api/Java/Awt/Component.Html 9
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
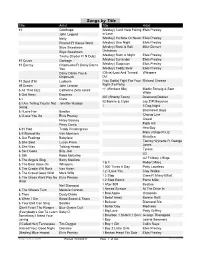
Songs by Title
Songs by Title Title Artist Title Artist #1 Goldfrapp (Medley) Can't Help Falling Elvis Presley John Legend In Love Nelly (Medley) It's Now Or Never Elvis Presley Pharrell Ft Kanye West (Medley) One Night Elvis Presley Skye Sweetnam (Medley) Rock & Roll Mike Denver Skye Sweetnam Christmas Tinchy Stryder Ft N Dubz (Medley) Such A Night Elvis Presley #1 Crush Garbage (Medley) Surrender Elvis Presley #1 Enemy Chipmunks Ft Daisy Dares (Medley) Suspicion Elvis Presley You (Medley) Teddy Bear Elvis Presley Daisy Dares You & (Olivia) Lost And Turned Whispers Chipmunk Out #1 Spot (TH) Ludacris (You Gotta) Fight For Your Richard Cheese #9 Dream John Lennon Right (To Party) & All That Jazz Catherine Zeta Jones +1 (Workout Mix) Martin Solveig & Sam White & Get Away Esquires 007 (Shanty Town) Desmond Dekker & I Ciara 03 Bonnie & Clyde Jay Z Ft Beyonce & I Am Telling You Im Not Jennifer Hudson Going 1 3 Dog Night & I Love Her Beatles Backstreet Boys & I Love You So Elvis Presley Chorus Line Hirley Bassey Creed Perry Como Faith Hill & If I Had Teddy Pendergrass HearSay & It Stoned Me Van Morrison Mary J Blige Ft U2 & Our Feelings Babyface Metallica & She Said Lucas Prata Tammy Wynette Ft George Jones & She Was Talking Heads Tyrese & So It Goes Billy Joel U2 & Still Reba McEntire U2 Ft Mary J Blige & The Angels Sing Barry Manilow 1 & 1 Robert Miles & The Beat Goes On Whispers 1 000 Times A Day Patty Loveless & The Cradle Will Rock Van Halen 1 2 I Love You Clay Walker & The Crowd Goes Wild Mark Wills 1 2 Step Ciara Ft Missy Elliott & The Grass Wont Pay -

Mary Anne Radmacher
May your walls know joy, may every room hold laughter, and every window open to great possibility. -- Mary Anne Radmacher (From Lauri’s front yard) The older I get the faster the year goes. Where did this year go? Oh, yes, it’s been a unique and crazy one! Who would have thought we would be living through a pandemic? I was thinking about the word “JOY.” Each year we put up huge sign in our front yard that spells out the word JOY. It twinkles with lights and is one of my favorite decorations to put up every year. I will admit it has been harder for me to find JOY over the last few months. I know many who are or have been sick with COVID-19 and two in our circle have lost their life to COVID over the last month. What is Joy? The definition of JOY according by the Webster Dictionary: 1a: the emotion evoked by well-being, success, or good fortune or by the prospect of possessing what one desires: DELIGHT b: the expression or exhibition of such emotion: GAIETY 2: a state of happiness or felicity: BLISS 3: a source or cause of delight Robert Holden, Ph.D., with The Happiness Project, recognizes these “5 Qualities of Joyful People.” “Do You Recognize These Qualities in Yourself?” 1. JOY IS CONSTANT When people tune in to the feeling of joy, what often emerges is an awareness that this joy is somehow always with us. Joy is quietly, invisibly ever-present. It is not “out there,” and it is not “in here”; rather, it is simply everywhere we are. -

BBO Orientation Packet
ACADEMY OF CANINE BEHAVIOR Basic Behavior and Obedience Class Orientation: FOCUS: Conditioning Markers. 1. Your dog will never take responsibility for getting trained. You must take the responsibility for educating your dog. This means that you must also take the responsibility of learning to communicate with your dog. Without communication there can be no education. 2. In the canine world there are no such things as equals; you will either lead or follow. A dog’s reasoning ability is similar to that of a two-year old child. A two-year old child does not make an effective leader; you must be the leader. 3. Every time you interact with your dog, they are learning something. If you are not teaching them the right behavior, they are learning the wrong behavior. 4. Negative attention is still attention. If the only way your dog can get your attention is be being bad, you will train them to act bad for attention. Remember to always reward your dog for good behavior. Pay attention when they are doing something right and let them know you like that behavior. 5. The consistency of your dog’s behavior, good or bad, will mirror the consistency of your training. If you train your dog by repeating the command ten times, you can expect the dog to respond 10% of the time. 6. A dog’s concept of right and wrong are very different from ours. Do not expect the dog to know what you may think is right or wrong. 7. If you are correcting the dog, are you certain the dog understand why it is being corrected? Have you educated and then generalized the concept? 8. -

Samādhi in Buddhism
SAMĀDHI IN BUDDHISM Phra Bramgunaborn (Bhikkhu P. A. Payutto) Lecture delivered at Wat Dhammaram, Chicago, U.S.A. on May 6, 1996 Translated by Janet Chan Edited by Susan Kirchhoff Contents Samādhi in Buddhism .................................................. 1 I. The Correct Way of Practicing Meditation ............................. 3 1. Samādhi for Mental Energy ........................................................ 6 2. Samādhi for Happiness and Tranquillity................................... 12 3. Samādhi for Clear Mind and Cultivation of Wisdom ............... 16 Attendant Benefits.............................................................................. 19 II. Techniques to Prevent and Overcome the Potential Misuses of Samādhi ......................................... 25 1. Maintaining the Five Controlling Faculties in Equilibrium ...... 25 2. Attuning the Practice to Conform to the Threefold Training .... 28 Contentment ....................................................................................... 29 The Foundation of Mindfulness ......................................................... 33 Conclusion.......................................................................................... 35 Appendix ............................................................................................ 38 SAMĀDHI IN BUDDHISM∗ As I have learned from different sources, people in the West have shown an increasing interest in Buddhism and particularly in samādhi. For this reason I feel it necessary for us to have a clear comprehension -

Psychosocial Adaptation to Pregnancy Regina Lederman • Karen Weis
Psychosocial Adaptation to Pregnancy Regina Lederman • Karen Weis Psychosocial Adaptation to Pregnancy Seven Dimensions of Maternal Role Development Third Edition Regina Lederman Karen Weis University of Texas United States Air Force Galveston, TX School of Aerospace USA Medicine, Brooks-City Base [email protected] TX, USA [email protected] [email protected] [email protected] 1st Ed., Prentice Hall - November 1984 2nd Ed., Churchill Livingstone (Springer Publishing) - 1 Mar 1996 ISBN 978-1-4419-0287-0 e-ISBN 978-1-4419-0288-7 DOI 10.1007/978-1-4419-0288-7 Springer Dordrecht Heidelberg London New York Library of Congress Control Number: 2009933092 © Springer Science+Business Media, LLC 2009 All rights reserved. This work may not be translated or copied in whole or in part without the written permission of the publisher (Springer Science+Business Media, LLC, 233 Spring Street, New York, NY 10013, USA), except for brief excerpts in connection with reviews or scholarly analysis. Use in connection with any form of information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed is forbidden. The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identified as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights. Printed on acid-free paper Springer is part of Springer Science+Business Media (www.springer.com) Preface The subject of this book is the psychosocial development of gravid women, both primigravid and multigravid women. -

The Song of a City and the Pearl of Peace No
Sermon #1818 Metropolitan Tabernacle Pulpit 1 THE SONG OF A CITY AND THE PEARL OF PEACE NO. 1818 A SERMON DELIVERED ON LORD’S-DAY MORNING, JANUARY 4, 1885, BY C. H. SPURGEON, AT THE METROPOLITAN TABERNACLE, NEWINGTON. “You will keep him in perfect peace, whose mind is stayed on You: because he trusts in You.” Isaiah 26:3. THIS is no dry, didactic statement, but a verse from a song. We are among the poets of revelation, who did not compose ballads for the passing hour, but made sonnets for the people of God to sing in lat- er days. I quote to you a stanza from “the song of a city.” Judah has not before thus chanted before her God, but she has much to learn, and one day she shall learn this psalm also—“We have a strong city; salvation will God appoint for walls and bulwarks.” Into the open country the adversary easily advances, but walled cities are a check upon the invading foe. Those people who had been hurried to and fro as captives, and had frequently been robbed of their property by invaders, were glad when they saw built among them a city, a well-defended city, which would be the center of their race, and the shield of their nation. This song of a city may, however, belong to us as much as to the men of Judah, and we may throw into it a deeper sense of which they were not aware. We were once unguarded from spiritual evil, and we spent our days in constant fear, but the Lord has found for us a city of defense, a castle of refuge. -

A Multimodal Discourse Analysis of a Yoruba Song-Drama
Journal of Education and Training Studies Vol. 3, No.5; September2015 ISSN 2324-805XE-ISSN 2324-8068 Published by Redfame Publishing URL: http://jets.redfame.com A Multimodal Discourse Analysis of a Yoruba Song-drama Olateju Moji. A Correspondence: Olateju Moji. A, Department of English, Obafemi Awolowo University, Ile-Ife, Nigeria Received: May 29, 2015 Accepted: June 10, 2015 Online Published: July 6, 2015 doi:10.11114/jets.v3i5.933 URL:http://dx.doi.org/10.11114/jets.v3i5.933 Abstract This paper presents a multimodal discourse analysis of a story that has been turned into a Yoruba song-drama, highlighting the ideational, interpersonal and textual aspects of the song-drama. The data is a short song-drama meant to teach children importunity, determination and hard work through persistence. The multimodal and narrative conventions used for analysis according to Kress and van Leeuwen (2001), show the need for cooperation and determination in a world that is characterized by individualism. The study reveals that, at the ideational level, information, anticipation, request and insistence are prominent features. At the interpersonal level, the study reveals that the song-drama is a metaphor for the possibility of a better life for the poor and needy in a society full of oppression and selfishness, while the textual level reveals the distribution of information in the different modes- song, drama, and paralinguistic expressions. The study concludes that pedagogically, storytelling, re-telling, writing and rewriting have the capacity to improve pupils’ vocabulary development. ESL teachers could creatively use video watching (which has replaced story telling), storytelling and retelling to launch the present day ESL learners into 21st century critical thinking and learning activities. -

OONGBESSIONAL. RECORD-Senl\.TE. 1923
1-894. OONGBESSIONAL. RECORD-SENl\.TE. 1923 and telephone service-to the Committee on In.terstate and For Also, two petitions n favor of fraternal society and college eign Commerce. journals-to the Committee on the Post-Office and Post-Roads. By Mr. HOPKINS of Illinois: Pe.tition of citizens of Illinois Also, petition of H. L. Wolf and 144·others in the interest of for the removal of the duty on -books printed in the English lap. fraternal soCiety and college journals-to the Committee on the guage-to the Committee on Ways and Means. Post-Office and Post-Roads.. Also, three petitions of the citizens of Illinois to admit fra By Mr. UPDEGRAFF: Petition of Cottonwood Camp, No. ternal society and college journals to the mails as second-class 238, of Modern Woodsmen of America, of Lime Spring, Iowa, mail matter-to the Committee on the Post-Office and Post for a law giving to the fraternal beneficiary press the same pos Roads. tage classification as that enjoyed by other newspapers and By Mr. HUDSON: Petition from citizens of Osage Mission, periodicals-to the Committee on the Post-Office and Post-Roads. K ans., asking for the admission to the mails as second-class mat Also, petition of C. N. Flagler and 80 others, of Lime Spring, ter papers of benevolent and literary organizations-to the Com Iowa, for :11anderson-Hainer bill, to admit as second~class mail mittee on the Post-Office and Post-Roads. matter the periodical publications of benevolent and frateTnal . Also, petitions from citizens of Howard, Kans., in favor of the societies-to the Committee on the Post-Office and Post-roads• Manderson-Hainer bill-to the Committee on the Post-Office ByMr. -

MCA Discography
MCA-1 Discography by David Edwards, Mike Callahan & Patrice Eyries © 2018 by Mike Callahan MCA Discography Note: When MCA discontinued Decca, Uni, Kapp and their subsidiary labels in late 1972, they started the new MCA label by consolidating artists from those old labels into the new label. Starting in 1973, MCA reissued hundreds of albums from all of those labels with new catalog numbers under the new MCA imprint. They started these reissues in the MCA-1 reissue series, which ran to MCA-299. MCA MCA-1 Reissue Series: MCA 1 - Loretta Lynn’s Greatest Hits - Loretta Lynn [1973] Reissue of Decca DL7 5000. Don't Come Home A Drinkin'/Before I'm Over You/If You're Not Gone Too Long/Dear Uncle Sam/Other Woman/Wine Women And Song//You Ain't Woman Enough/Blue Kentucky Girl/Success/Home You're Tearin' Down/Happy Birthday MCA 2 - This Is Jerry Wallace - Jerry Wallace [1973] Reissue of Decca DL7 5294. After You/She'll Remember/The Greatest Love/In The Misty Moonlight/New Orleans In The Rain/Time//The Morning After/I Can't Take It Any More/The Hands Of The Man/To Get To You/There She Goes MCA 3 - Rick Nelson in Concert - Rick Nelson [1973] Reissue of Decca DL7 5162. Come On In/Hello Mary Lou, Goodbye Heart/Violets Of Dawn/Who Cares About Tomorrow-Promises/She Belongs To Me/If You Gotta Go, Go Now//I'm Walkin'/Red Balloon/Louisiana Man/Believe What You Say/Easy To Be Free/I Shall Be Released MCA 4 - Sousa Marches in Hi-Fi - Goldman Band [1973] Reissue of Decca DL7 8807. -

Songs by Artist
Songs by Artist Karaoke Collection Title Title Title +44 18 Visions 3 Dog Night When Your Heart Stops Beating Victim 1 1 Block Radius 1910 Fruitgum Co An Old Fashioned Love Song You Got Me Simon Says Black & White 1 Fine Day 1927 Celebrate For The 1st Time Compulsory Hero Easy To Be Hard 1 Flew South If I Could Elis Comin My Kind Of Beautiful Thats When I Think Of You Joy To The World 1 Night Only 1st Class Liar Just For Tonight Beach Baby Mama Told Me Not To Come 1 Republic 2 Evisa Never Been To Spain Mercy Oh La La La Old Fashioned Love Song Say (All I Need) 2 Live Crew Out In The Country Stop & Stare Do Wah Diddy Diddy Pieces Of April 1 True Voice 2 Pac Shambala After Your Gone California Love Sure As Im Sitting Here Sacred Trust Changes The Family Of Man 1 Way Dear Mama The Show Must Go On Cutie Pie How Do You Want It 3 Doors Down 1 Way Ride So Many Tears Away From The Sun Painted Perfect Thugz Mansion Be Like That 10 000 Maniacs Until The End Of Time Behind Those Eyes Because The Night 2 Pac Ft Eminem Citizen Soldier Candy Everybody Wants 1 Day At A Time Duck & Run Like The Weather 2 Pac Ft Eric Will Here By Me More Than This Do For Love Here Without You These Are Days 2 Pac Ft Notorious Big Its Not My Time Trouble Me Runnin Kryptonite 10 Cc 2 Pistols Ft Ray J Let Me Be Myself Donna You Know Me Let Me Go Dreadlock Holiday 2 Pistols Ft T Pain & Tay Dizm Live For Today Good Morning Judge She Got It Loser Im Mandy 2 Play Ft Thomes Jules & Jucxi So I Need You Im Not In Love Careless Whisper The Better Life Rubber Bullets 2 Tons O Fun -

Partially Examined Summaries
Partially Examined Summaries The Bodhisattva's Brain: Buddhism Naturalized by Owen Flanagan Introduction The following summary is meant to serve as a guide for listeners of the The Partially Examined Life, a podcast in which a few participants periodically read and discuss a philosophical text. In what follows I give a basic summary of Owen Flanagan’s The Bodhisattva’s Brain. This summary does not follow the structure of the text exactly; rather, it distills its main points and organizes them thematically. -- Wes Alwan The Summary Motivation, Structure, and Method (From the Preface and Introduction). Motivation Flanagan’s interest in Buddhism developed out of a chance invitation to have a discussion with the Dalai Lama and other scientists and philosophers; and because of subsequent hyperbolic publicity to the effect that neuroscience was in the process of empirically demonstrating that Buddhism leads to happiness. Structure The book has two parts: • Part I: Can neuroscience tell us whether Buddhism makes its adherents happy? Can neuroscience study such things? • Part II: What is “naturalized Buddhism,” and why might it be of interest to scientific naturalists and analytic philosophers? Method Flanagan will proceed on the assumption of philosophical naturalism to a form Buddhism that “after subtracting what is psychologically and sociologically understandable, but that epistemically speaking is incredible superstition and magical thinking, would be what I call “Buddhism naturalized,” or something in its vicinity.” His methodology will also embrace anachronism (ancient texts bear on modern problems), ethnocentrism (we can judge whether these texts are adequate to the problems of our own time and place), and a cosmopolitan style (an ironic, skeptical but sensitive attitude towards all forms of life, including one’s own). -

Bbmak to Brooks & Dunn
Sound Extreme Entertainment Karaoke Show with Host 828-551-3519 [email protected] www.SoundExtreme.net In The Style Of Title Genre BBMak Out Of My Heart (Into Your Head) Pop / Rock BBMak Still On Your Side Pop / Rock Beach Boys, The Barbara Ann Country & Pop Beach Boys, The Be True To Your School Country & Pop Beach Boys, The California Girls Country & Pop Beach Boys, The Fun, Fun, Fun Country & Pop Beach Boys, The Getcha Back Pop / Rock Beach Boys, The Good Vibrations Country & Pop Beach Boys, The Help Me Rhonda Country & Pop Beach Boys, The I Get Around Country & Pop Beach Boys, The Kokomo Country & Pop Beach Boys, The Little Deuce Coupe Country & Pop Beach Boys, The Little Saint Nick Country & Pop Beach Boys, The Rock And Roll Music Country & Pop Beach Boys, The Sloop John B Oldies Beach Boys, The Surfer Girl Pop / Rock Beach Boys, The Surfin' USA Country & Pop Beach Boys, The Wouldn't It Be Nice Pop Beastie Boys, The You Gotta) Fight For Your Right (To Party) Country & Pop Beatles, The A Hard Day's Night Country & Pop Beatles, The All My Loving Oldies Beatles, The All You Need Is Love Pop / Rock Beatles, The And I Love Her Oldies Beatles, The Back In The USSR Oldies Beatles, The Can't Buy Me Love Country & Pop Beatles, The Come Together Country & Pop Beatles, The Day Tripper Pop Beatles, The Do You Want To Know A Secret Pop / Rock Beatles, The Drive My Car Oldies Beatles, The Eight Days A Week Country & Pop Beatles, The Eleanor Rigby Pop Beatles, The Free As A Bird Oldies Sound Extreme Entertainment www.SoundExtreme.net www.SoundExtremeWeddings.com www.CrocodileSmile.net 360 King Rd.