COUNTER RELEASE 5: an Independent Review
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Aussie Classics Hits - 180 Songs
Available from Karaoke Home Entertainment Australia and New Zealand Aussie Classics Hits - 180 Songs 1 20 Good Reasons Thirsty Merc 2 Absolutely Everybody Vanessa Amorosi 3 Age Of Reason John Farnham 4 All I Do Daryl Braithwaite 5 All My Friends Are Getting Married Skyhooks 6 Am I Ever Gonna See Your Face Again The Angels 7 Amazing Alex Lloyd 8 Amazing Vanessa Amorosi 9 Animal Song Savage Garden 10 April Sun In Cuba Dragon 11 Are You Gonna Be My Girl Jet 12 Art Of Love Guy Sebastian, Jordin Sparks 13 Aussie Rules I Thank You For The Best Kevin Johnson Years Of Our Lives 14 Australian Boy Lee Kernaghan 15 Barbados The Models 16 Battle Scars Guy Sebastian, Lupe Fiasco 17 Bedroom Eyes Kate Ceberano 18 Before The Devil Knows You're Dead Jimmy Barnes 19 Before Too Long Paul Kelly, The Coloured Girls 20 Better Be Home Soon Crowded House 21 Better Than John Butler Trio 22 Big Mistake Natalie Imbruglia 23 Black Betty Spiderbait 24 Bluebird Kasey Chambers 25 Bopping The Blues Blackfeather 26 Born A Woman Judy Stone 27 Born To Try Delta Goodrem 28 Bow River Cold Chisel 29 Boys Will Be Boys Choir Boys 30 Breakfast At Sweethearts Cold Chisel 31 Burn For You John Farnham 32 Buses And Trains Bachelor Girl 33 Chained To The Wheel Black Sorrows 34 Cheap Wine Cold Chisel 35 Come On Aussie Come On Shannon Noll 36 Come Said The Boy Mondo Rock 37 Compulsory Hero 1927 38 Cool World Mondo Rock 39 Crazy Icehouse 40 Cry In Shame Johnny Diesel, The Injectors 41 Dancing With A Broken Heart Delta Goodrem 42 Devil Inside Inxs 43 Do It With Madonna The Androids 44 -

Customizable • Ease of Access Cost Effective • Large Film Library
CUSTOMIZABLE • EASE OF ACCESS COST EFFECTIVE • LARGE FILM LIBRARY www.criterionondemand.com Criterion-on-Demand is the ONLY customizable on-line Feature Film Solution focused specifically on the Post Secondary Market. LARGE FILM LIBRARY Numerous Titles are Available Multiple Genres for Educational from Studios including: and Research purposes: • 20th Century Fox • Foreign Language • Warner Brothers • Literary Adaptations • Paramount Pictures • Justice • Alliance Films • Classics • Dreamworks • Environmental Titles • Mongrel Media • Social Issues • Lionsgate Films • Animation Studies • Maple Pictures • Academy Award Winners, • Paramount Vantage etc. • Fox Searchlight and many more... KEY FEATURES • 1,000’s of Titles in Multiple Languages • Unlimited 24-7 Access with No Hidden Fees • MARC Records Compatible • Available to Store and Access Third Party Content • Single Sign-on • Same Language Sub-Titles • Supports Distance Learning • Features Both “Current” and “Hard-to-Find” Titles • “Easy-to-Use” Search Engine • Download or Streaming Capabilities CUSTOMIZATION • Criterion Pictures has the rights to over 15000 titles • Criterion-on-Demand Updates Titles Quarterly • Criterion-on-Demand is customizable. If a title is missing, Criterion will add it to the platform providing the rights are available. Requested titles will be added within 2-6 weeks of the request. For more information contact Suzanne Hitchon at 1-800-565-1996 or via email at [email protected] LARGE FILM LIBRARY A Small Sample of titles Available: Avatar 127 Hours 2009 • 150 min • Color • 20th Century Fox 2010 • 93 min • Color • 20th Century Fox Director: James Cameron Director: Danny Boyle Cast: Sam Worthington, Sigourney Weaver, Cast: James Franco, Amber Tamblyn, Kate Mara, Michelle Rodriguez, Zoe Saldana, Giovanni Ribisi, Clemence Poesy, Kate Burton, Lizzy Caplan CCH Pounder, Laz Alonso, Joel Moore, 127 HOURS is the new film from Danny Boyle, Wes Studi, Stephen Lang the Academy Award winning director of last Avatar is the story of an ex-Marine who finds year’s Best Picture, SLUMDOG MILLIONAIRE. -

Past Concerts and Events
Rochford Wines - past concerts and events 2021 23 January Sounds Better Together 20 March Wine Machine #1 21 March Wine Machine #2 17 April The Big 90s Party 18 April Vine Warp 24 April Grapevine Presents 2020 18 April The Big 90s Party 28 March Wine Machine 22 February A-ha & Rick Astley 1 February Elton John 31 January Elton John 10 January Cold Chisel 2019 9 November Rob Thomas 13 April The Big 80s Party 6 April Hot Dub Wine Machine 23 February ADOTG – Bryan Ferry 2018 9 December ADOTG – John Farnham 8 December ADOTG – John Farnham 24 November Grapevine Gathering 24 March Hot Dub Wine Machine 22 February AEOTG – Robbie Williams 10 February RNB Vine Days 2017 17 December Rochford Wines Family Christmas Day 16 December ADOTG – Human Nature 10 December ADOTG – KC & The Sunshine Band 26 November Wine Quest's Cuban Festival 2017 25 November Grapevine Gathering 18 November ADOTG – Stevie Nicks & The Pretenders 29 October Gertrude Opera presents Mozart’s The Magic Flute 27 October Gertrude Opera presents Mozart’s The Magic Flute 10 October Wedfest @ Rochford Wines 1 October ADOTG – Sir Elton John 16 June Rochford Wines presents Anthony Gerace 29 April Rochford Wines presents The Decibelles Up Close 8 April Cyndi Lauper & Blondie 2 April 2017 Yarra Valley Wine & Food Festival 1 April 2017 Yarra Valley Wine & Food Festival 1 April Twilight Concert - Bjorn Again 25 March Hot Dub Wine Machine 4 February ADOTG - Simple Minds & B52s 2016 18 December Rochford Wines Family Christmas Day 26 November ADOTG Garbage & The Temper Trap 13 November ADOTG -

Informe De La Comisión Hacia El Cierre De Guantánamo
OEA/Ser.L/V/II. Doc. 20/15 3 Junio 2015 Original: Inglés COMISIÓN INTERAMERICANA DE DERECHOS HUMANOS Hacia el cierre de Guantánamo 2015 www.cidh.org OAS Cataloging-in-Publication Data Inter-American Commission on Human Rights. Hacia el cierre de Guantánamo / Comisión Interamericana de Derechos Humanos. v. ; cm. (OAS. Documentos oficiales ; OEA/Ser.L) ISBN 978-0-8270-6422-5 1. Guantánamo Bay Detention Camp. 2. Prisoners of war--Legal status, laws, etc.--Cuba--Guantánamo Bay Naval Base. 3. Prisoners of war--United States. 4. Detention of persons--Cuba-- Guantánamo Bay Naval Base. I. Title. II. OAS. Documentos oficiales ; OEA/Ser.L/V/II. Doc.20/15 COMISIÓN INTERAMERICANA DE DERECHOS HUMANOS Miembros Rose-Marie Belle Antoine James L. Cavallaro* José de Jesús Orozco Henríquez Felipe González Tracy Robinson Rosa María Ortiz Paulo Vannuchi Secretario Ejecutivo Emilio Álvarez-Icaza Longoria Secretaria Ejecutiva Adjunta Elizabeth Abi-Mershed * Conforme a lo dispuesto en el artículo 17.2 del Reglamento de la Comisión, el Comisionado James L. Cavallaro, de nacionalidad estadounidense, no participó en el debate ni en la decisión del presente Informe. Aprobado por la Comisión Interamericana de Derechos Humanos el 3 de junio de 2015 ÍNDICE RESUMEN EJECUTIVO 9 CAPÍTULO 1 | INTRODUCCIÓN 15 A. Antecedentes 15 B. Metodología 16 C. Estructura del informe 17 D. Preparación y aprobación del informe 19 CAPÍTULO 2 | EVOLUCIÓN DE LAS INICIATIVAS DE LA CIDH RELATIVAS A GUANTÁNAMO 23 A. El mandato de la CIDH 23 B. Medidas cautelares 25 C. Resoluciones 29 D. Audiencias públicas 31 E. Sistema de peticiones individuales 32 F. -
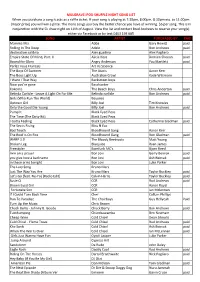
MULGRAVE IPOD SHUFFLE NIGHT SONG LIST When You Purchase a Song It Acts As a Raffle Ticket
MULGRAVE IPOD SHUFFLE NIGHT SONG LIST When you purchase a song it acts as a raffle ticket. If your song is playing at 7:30pm, 8:00pm, 8:30pm etc. to 11:00pm (major prize) you will win a prize. The more songs you buy the better chance you have of winning. $5 per song. This is in conjunction with the 5k draw night on 11th of August. View the list and contact Brad Andrews to reserve your song(s) either via Facebook or by text 0403 193 085 SONG ARTIST PURCHASED BY PAID Mamma Mia Abba Gary Hewitt paid Rolling In The Deep Adele Bon Andrews paid destination calibria Alex guadino Alex Pagliaro Empire State Of Mind, Part. II Alicia Keys Damien Sheean paid Bound for Glory Angry Anderson Paul Bartlett paid Parlez Vous Francais Art Vs Science The Boys Of Summer The Ataris Aaron Kerr The Boys Light Up Australian Crawl Kade Wilsmore I Want I That Way Backstreet boys Now you're gone Basshunter Kokomo The Beach Boys Chris Anderton paid Belinda Carlisle ‐ Leave A Light On For Me Belinda carlisle Bon Andrews paid Girls (Who Run The World) Beyonce Uptown Girl Billy Joel Tim Knowles Only the Good Die Young Billy Joel Bon Andrews paid Pump It Black Eyed Peas The Time (The Dirty Bit) Black Eyed Peas I Gotta Feeling Black Eyed Peas Catherine Gladman paid The Sea is Rising Bliss N Eso Bad Touch Bloodhound Gang Aaron Kerr The Roof Is On Fire Bloodhound Gang Ron Gladman paid WARP 1.9 The Bloody Beetroots Matt Young Broken Leg Bluejuice Ryan James Freestyler Bomfunk MC's Bjorn Reed livin on a prayer Bon Jovi Gerry Beiniak paid you give love a bad name Bon Jovi Ash Beiniak paid in these arms tonight Bon Jovi Luke Parker The Lazy Song Bruno Mars Just The Way You Are Bruno Mars Taylor Buckley paid Let's Go (feat. -

Reforming Primary and Secondary Education in Latin America and the Caribbean: an IDB Strategy
DOCUMENT RESUME ED 474 669 UD 035 422 AUTHOR Castro, Claudio de Moura; Navarro, Juan Carlos; Wolff, Laurence; Carnoy, Martin TITLE Reforming Primary and Secondary Education in Latin America and the Caribbean: An IDB Strategy. Sustainable Development Department Sector Strategy and Policy Papers Series. INSTITUTION Inter-American Development Bank, Washington, DC. REPORT NO EDU-113 PUB DATE 2000-05-01 NOTE 61p AVAILABLE FROM Publications, Education Unit, Inter-American Development Bank, 1300 New York Avenue, N.W., Washington, DC 20577. Tel: 202-623-2087; Fax: 202-623-1558; e-mail: sds/[email protected]; Web site: http://www.iadb.org/sds/edu. PUB TYPE Reports Evaluative (142) EDRS PRICE EDRS Price MF01/PC03 Plus Postage. DESCRIPTORS *Accountability; *Change Strategies; Computer Uses in Education; Cost Effectiveness; Decentralization; Early Childhood Education; *Educational Change; Educational Equity (Finance); Educational Technology; Elementary Secondary Education; Foreign Countries; Governance; Teacher Participation IDENTIFIERS Action Plans; *Caribbean; *Latin America; Reform Efforts ABSTRACT This report summarizes what is known about educational improvement in Latin America and provides objectives and strategies to guide the Inter-American Development Bank (IDB) in supporting primary and secondary education in Latin America and the Caribbean over the next decade. It is based on six background papers as well as a review of the lessons learned from recent regional and country experience. The papers are "The Need for Education Reform"; "Five Critical -

Karaoke Mietsystem Songlist
Karaoke Mietsystem Songlist Ein Karaokesystem der Firma Showtronic Solutions AG in Zusammenarbeit mit Karafun. Karaoke-Katalog Update vom: 13/10/2020 Singen Sie online auf www.karafun.de Gesamter Katalog TOP 50 Shallow - A Star is Born Take Me Home, Country Roads - John Denver Skandal im Sperrbezirk - Spider Murphy Gang Griechischer Wein - Udo Jürgens Verdammt, Ich Lieb' Dich - Matthias Reim Dancing Queen - ABBA Dance Monkey - Tones and I Breaking Free - High School Musical In The Ghetto - Elvis Presley Angels - Robbie Williams Hulapalu - Andreas Gabalier Someone Like You - Adele 99 Luftballons - Nena Tage wie diese - Die Toten Hosen Ring of Fire - Johnny Cash Lemon Tree - Fool's Garden Ohne Dich (schlaf' ich heut' nacht nicht ein) - You Are the Reason - Calum Scott Perfect - Ed Sheeran Münchener Freiheit Stand by Me - Ben E. King Im Wagen Vor Mir - Henry Valentino And Uschi Let It Go - Idina Menzel Can You Feel The Love Tonight - The Lion King Atemlos durch die Nacht - Helene Fischer Roller - Apache 207 Someone You Loved - Lewis Capaldi I Want It That Way - Backstreet Boys Über Sieben Brücken Musst Du Gehn - Peter Maffay Summer Of '69 - Bryan Adams Cordula grün - Die Draufgänger Tequila - The Champs ...Baby One More Time - Britney Spears All of Me - John Legend Barbie Girl - Aqua Chasing Cars - Snow Patrol My Way - Frank Sinatra Hallelujah - Alexandra Burke Aber Bitte Mit Sahne - Udo Jürgens Bohemian Rhapsody - Queen Wannabe - Spice Girls Schrei nach Liebe - Die Ärzte Can't Help Falling In Love - Elvis Presley Country Roads - Hermes House Band Westerland - Die Ärzte Warum hast du nicht nein gesagt - Roland Kaiser Ich war noch niemals in New York - Ich War Noch Marmor, Stein Und Eisen Bricht - Drafi Deutscher Zombie - The Cranberries Niemals In New York Ich wollte nie erwachsen sein (Nessajas Lied) - Don't Stop Believing - Journey EXPLICIT Kann Texte enthalten, die nicht für Kinder und Jugendliche geeignet sind. -

Songs by Title
Karaoke Song Book Songs by Title Title Artist Title Artist #1 Nelly 18 And Life Skid Row #1 Crush Garbage 18 'til I Die Adams, Bryan #Dream Lennon, John 18 Yellow Roses Darin, Bobby (doo Wop) That Thing Parody 19 2000 Gorillaz (I Hate) Everything About You Three Days Grace 19 2000 Gorrilaz (I Would Do) Anything For Love Meatloaf 19 Somethin' Mark Wills (If You're Not In It For Love) I'm Outta Here Twain, Shania 19 Somethin' Wills, Mark (I'm Not Your) Steppin' Stone Monkees, The 19 SOMETHING WILLS,MARK (Now & Then) There's A Fool Such As I Presley, Elvis 192000 Gorillaz (Our Love) Don't Throw It All Away Andy Gibb 1969 Stegall, Keith (Sitting On The) Dock Of The Bay Redding, Otis 1979 Smashing Pumpkins (Theme From) The Monkees Monkees, The 1982 Randy Travis (you Drive Me) Crazy Britney Spears 1982 Travis, Randy (Your Love Has Lifted Me) Higher And Higher Coolidge, Rita 1985 BOWLING FOR SOUP 03 Bonnie & Clyde Jay Z & Beyonce 1985 Bowling For Soup 03 Bonnie & Clyde Jay Z & Beyonce Knowles 1985 BOWLING FOR SOUP '03 Bonnie & Clyde Jay Z & Beyonce Knowles 1985 Bowling For Soup 03 Bonnie And Clyde Jay Z & Beyonce 1999 Prince 1 2 3 Estefan, Gloria 1999 Prince & Revolution 1 Thing Amerie 1999 Wilkinsons, The 1, 2, 3, 4, Sumpin' New Coolio 19Th Nervous Breakdown Rolling Stones, The 1,2 STEP CIARA & M. ELLIOTT 2 Become 1 Jewel 10 Days Late Third Eye Blind 2 Become 1 Spice Girls 10 Min Sorry We've Stopped Taking Requests 2 Become 1 Spice Girls, The 10 Min The Karaoke Show Is Over 2 Become One SPICE GIRLS 10 Min Welcome To Karaoke Show 2 Faced Louise 10 Out Of 10 Louchie Lou 2 Find U Jewel 10 Rounds With Jose Cuervo Byrd, Tracy 2 For The Show Trooper 10 Seconds Down Sugar Ray 2 Legit 2 Quit Hammer, M.C. -

Toward an Urban Cultural Studies: Henri Lefebvre and the Humanities Benjamin Fraser Toward an Urban Cultural Studies Henri Lefebvre and the Humanities
Toward an Urban Cultural Studies HISPANIC URBAN STUDIES BENJAMIN FRASER is Professor and Chair of Foreign Languages and Literatures in the Thomas Harriot College of Arts and Sciences at East Carolina University, North Carolina, US. He is the editor of the Journal of Urban Cultural Studies and the author, editor, and translator of book and arti- cle publications in Hispanic Studies, Cultural Studies, and Urban Studies. SUSAN LARSON is an Associate Professor of Spanish at the University of Kentucky, US. She is Senior Editor of the Arizona Journal of Hispanic Cultural Studies and works at the intersections of Spatial Theory and Literary, Film and Urban Studies. Toward an Urban Cultural Studies: Henri Lefebvre and the Humanities Benjamin Fraser Toward an Urban Cultural Studies Henri Lefebvre and the Humanities Benjamin Fraser TOWARD AN URBAN CULTURAL STUDIES Copyright © Benjamin Fraser, 2015. Softcover reprint of the hardcover 1st edition 2015 978-1-137-49855-7 All rights reserved. First published in 2015 by PALGRAVE MACMILLAN® in the United States—a division of St. Martin’s Press LLC, 175 Fifth Avenue, New York, NY 10010. Where this book is distributed in the UK, Europe and the rest of the world, this is by Palgrave Macmillan, a division of Macmillan Publishers Limited, registered in England, company number 785998, of Houndmills, Basingstoke, Hampshire RG21 6XS. Palgrave Macmillan is the global academic imprint of the above companies and has companies and representatives throughout the world. Palgrave® and Macmillan® are registered trademarks in the United States, the United Kingdom, Europe and other countries. ISBN 978-1-349-50524-1 ISBN 978-1-137-49856-4 (eBook) DOI 10.105 7/9781137498564 Library of Congress Cataloging-in-Publication Data Fraser, Benjamin. -
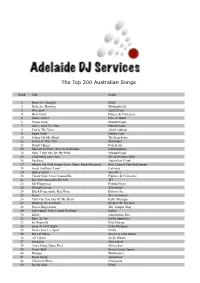
ADJS Top 200 Song Lists.Xlsx
The Top 200 Australian Songs Rank Title Artist 1 Need You Tonight INXS 2 Beds Are Burning Midnight Oil 3 Khe Sanh Cold Chisel 4 Holy Grail Hunter & Collectors 5 Down Under Men at Work 6 These Days Powderfinger 7 Come Said The Boy Mondo Rock 8 You're The Voice John Farnham 9 Eagle Rock Daddy Cool 10 Friday On My Mind The Easybeats 11 Living In The 70's Skyhooks 12 Dumb Things Paul Kelly 13 Sounds of Then (This Is Australia) GANGgajang 14 Baby I Got You On My Mind Powderfinger 15 I Honestly Love You Olivia Newton-John 16 Reckless Australian Crawl 17 Where the Wild Roses Grow (Feat. Kylie Minogue) Nick Cave & The Bad Seeds 18 Great Southern Land Icehouse 19 Heavy Heart You Am I 20 Throw Your Arms Around Me Hunters & Collectors 21 Are You Gonna Be My Girl JET 22 My Happiness Powderfinger 23 Straight Lines Silverchair 24 Black Fingernails, Red Wine Eskimo Joe 25 4ever The Veronicas 26 Can't Get You Out Of My Head Kylie Minogue 27 Walking On A Dream Empire Of The Sun 28 Sweet Disposition The Temper Trap 29 Somebody That I Used To Know Gotye 30 Zebra John Butler Trio 31 Born To Try Delta Goodrem 32 So Beautiful Pete Murray 33 Love At First Sight Kylie Minogue 34 Never Tear Us Apart INXS 35 Big Jet Plane Angus & Julia Stone 36 All I Want Sarah Blasko 37 Amazing Alex Lloyd 38 Ana's Song (Open Fire) Silverchair 39 Great Wall Boom Crash Opera 40 Woman Wolfmother 41 Black Betty Spiderbait 42 Chemical Heart Grinspoon 43 By My Side INXS 44 One Said To The Other The Living End 45 Plastic Loveless Letters Magic Dirt 46 What's My Scene The Hoodoo Gurus -

12/2008 Mechanical, Photocopying, Recording Without Prior Written Permission of Ukchartsplus
All rights reserved. No portion of this publication may be reproduced, stored in Issue 383 a retrieval system, posted on an Internet/Intranet web site, forwarded by email, or otherwise transmitted in any form or by any means, electronic, 27/12/2008 mechanical, photocopying, recording without prior written permission of UKChartsPlus Symbols: Platinum (600,000) Number 1 Gold (400,000) Silver (200,000) 12” Vinyl only 7” Vinyl only Download only Pre-Release For the week ending 27 December 2008 TW LW 2W Title - Artist Label (Cat. No.) High Wks 1 NEW HALLELUJAH - Alexandra Burke Syco (88697446252) 1 1 1 1 2 30 43 HALLELUJAH - Jeff Buckley Columbia/Legacy (88697098847) -- -- 2 26 3 1 1 RUN - Leona Lewis Syco ( GBHMU0800023) -- -- 12 3 4 9 6 IF I WERE A BOY - Beyoncé Columbia (88697401522) 16 -- 1 7 5 NEW ONCE UPON A CHRISTMAS SONG - Geraldine Polydor (1793980) 2 2 5 1 6 18 31 BROKEN STRINGS - James Morrison featuring Nelly Furtado Polydor (1792152) 29 -- 6 7 7 2 10 USE SOMEBODY - Kings Of Leon Hand Me Down (8869741218) 24 -- 2 13 8 60 53 LISTEN - Beyoncé Columbia (88697059602) -- -- 8 17 9 5 2 GREATEST DAY - Take That Polydor (1787445) 14 13 1 4 10 4 3 WOMANIZER - Britney Spears Jive (88697409422) 13 -- 3 7 11 7 5 HUMAN - The Killers Vertigo ( 1789799) 50 -- 3 6 12 13 19 FAIRYTALE OF NEW YORK - The Pogues featuring Kirsty MacColl Warner Bros (WEA400CD) 17 -- 3 42 13 3 -- LITTLE DRUMMER BOY / PEACE ON EARTH - BandAged : Sir Terry Wogan & Aled Jones Warner Bros (2564692006) 4 6 3 2 14 8 4 HOT N COLD - Katy Perry Virgin (VSCDT1980) 34 -- -

Lessons Learned from Mediation Processes from Pre-Talks to Implementation
From Pre-Talks to Implementation: LESSONS LEARNED FROM MEDIATION PROCESSES From Pre-Talks to Implementation: LESSONS LEARNED FROM MEDIATION PROCESSES Eemeli Isoaho, Suvi Tuuli This document has been produced with financial assistance from the Ministry for Foreign Affairs of Finland. The contents of this document are the sole responsibility of CMI. May 2013 Language editing by Stephen Thompson Graphic design by Hiekka Graphics. Printed by Yliopistonpaino. CMI INTRODUCTION Crisis Management Initiative (CMI) is a Finnish, independent, non-profit organisation that works to resolve conflict and build sustainable peace across the globe. Our tireless mediation and peacebuilding efforts are based on the strong belief that all conflicts can and should be resolved. As a private diplomacy organisation, CMI works to prevent and resolve violent conflict by involving all actors relevant to achieving sustainable peace. We do this by supporting regional mediation capacity and skills, by bringing together local actors and facilitating confidence-building dialogues, by strengthening the sustainability of peace through new approaches for conflict prevention, and by rapidly providing flexible mediation support at different stages of the peace process. Over the past years, CMI has built its capacity in peacebuilding and developed partner- ships with local and regional actors, including the European Union and the African Union. Founded in 2000 by President and Nobel Peace Prize Laureate Martti Ahtisaari, CMI has grown significantly in recent years. We now have a team of over 70 professionals dedicated to conflict prevention and resolution, and field offices in several regions of the world, in addition to our offices in Helsinki and Brussels. CMI has recently been recognised internationally as one of the most influential private diplomacy organ- isations.