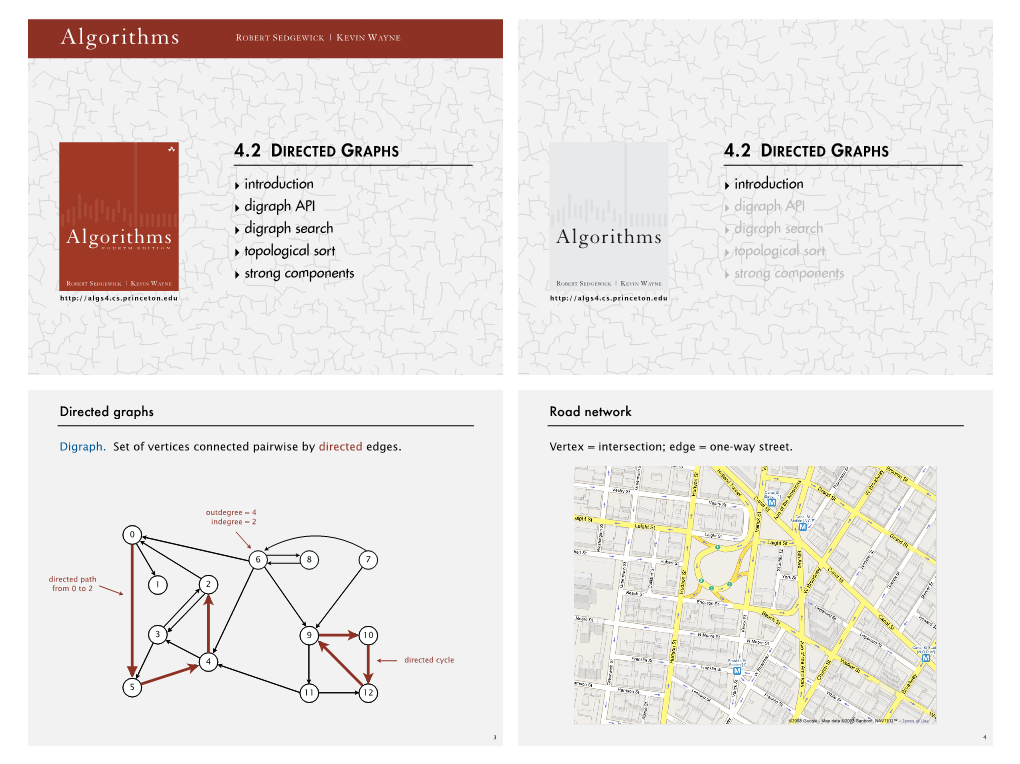
4.2 Directed Graphs 4.2 Directed Graphs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Applications of DFS
(b) acyclic (tree) iff a DFS yeilds no Back edges 2.A directed graph is acyclic iff a DFS yields no back edges, i.e., DAG (directed acyclic graph) , no back edges 3. Topological sort of a DAG { next 4. Connected components of a undirected graph (see Homework 6) 5. Strongly connected components of a drected graph (see Sec.22.5 of [CLRS,3rd ed.]) Applications of DFS 1. For a undirected graph, (a) a DFS produces only Tree and Back edges 1 / 7 2.A directed graph is acyclic iff a DFS yields no back edges, i.e., DAG (directed acyclic graph) , no back edges 3. Topological sort of a DAG { next 4. Connected components of a undirected graph (see Homework 6) 5. Strongly connected components of a drected graph (see Sec.22.5 of [CLRS,3rd ed.]) Applications of DFS 1. For a undirected graph, (a) a DFS produces only Tree and Back edges (b) acyclic (tree) iff a DFS yeilds no Back edges 1 / 7 3. Topological sort of a DAG { next 4. Connected components of a undirected graph (see Homework 6) 5. Strongly connected components of a drected graph (see Sec.22.5 of [CLRS,3rd ed.]) Applications of DFS 1. For a undirected graph, (a) a DFS produces only Tree and Back edges (b) acyclic (tree) iff a DFS yeilds no Back edges 2.A directed graph is acyclic iff a DFS yields no back edges, i.e., DAG (directed acyclic graph) , no back edges 1 / 7 4. Connected components of a undirected graph (see Homework 6) 5. -

Masters Thesis: an Approach to the Automatic Synthesis of Controllers with Mixed Qualitative/Quantitative Specifications
An approach to the automatic synthesis of controllers with mixed qualitative/quantitative specifications. Athanasios Tasoglou Master of Science Thesis Delft Center for Systems and Control An approach to the automatic synthesis of controllers with mixed qualitative/quantitative specifications. Master of Science Thesis For the degree of Master of Science in Embedded Systems at Delft University of Technology Athanasios Tasoglou October 11, 2013 Faculty of Electrical Engineering, Mathematics and Computer Science (EWI) · Delft University of Technology *Cover by Orestis Gartaganis Copyright c Delft Center for Systems and Control (DCSC) All rights reserved. Abstract The world of systems and control guides more of our lives than most of us realize. Most of the products we rely on today are actually systems comprised of mechanical, electrical or electronic components. Engineering these complex systems is a challenge, as their ever growing complexity has made the analysis and the design of such systems an ambitious task. This urged the need to explore new methods to mitigate the complexity and to create sim- plified models. The answer to these new challenges? Abstractions. An abstraction of the the continuous dynamics is a symbolic model, where each “symbol” corresponds to an “aggregate” of states in the continuous model. Symbolic models enable the correct-by-design synthesis of controllers and the synthesis of controllers for classes of specifications that traditionally have not been considered in the context of continuous control systems. These include qualitative specifications formalized using temporal logics, such as Linear Temporal Logic (LTL). Be- sides addressing qualitative specifications, we are also interested in synthesizing controllers with quantitative specifications, in order to solve optimal control problems. -

Efficient Graph Reachability Query Answering Using Tree Decomposition
Efficient Graph Reachability Query Answering using Tree Decomposition Fang Wei Computer Science Department, University of Freiburg, Germany Abstract. Efficient reachability query answering in large directed graphs has been intensively investigated because of its fundamental importance in many application fields such as XML data processing, ontology rea- soning and bioinformatics. In this paper, we present a novel indexing method based on the concept of tree decomposition. We show analytically that this intuitive approach is both time and space efficient. We demonstrate empirically the efficiency and the effectiveness of our method. 1 Introduction Querying and manipulating large scale graph-like data has attracted much atten- tion in the database community, due to the wide application areas of graph data, such as GIS, XML databases, bioinformatics, social network, and ontologies. The problem of reachability test in a directed graph is among the fundamental operations on the graph data. Given a digraph G = (V; E) and u; v 2 V , a reachability query, denoted as u ! v, ask: is there a path from u to v? One of the fundamental queries on biological networks is for instance, to find all genes whose expressions are directly or indirectly influenced by a given molecule [15]. Given the graph representation of the genes and regulation events, the question can also be reduced to the reachability query in a directed graph. Recently, tree decomposition methodologies have been successfully applied to solving shortest path query answering over undirected graphs [17]. Briefly stated, the vertices in a graph G are decomposed into a tree in which each node contains a set of vertices in G. -

Depth-First Search & Directed Graphs
Depth-first Search and Directed Graphs Story So Far • Breadth-first search • Using breadth-first search for connectivity • Using bread-first search for testing bipartiteness BFS (G, s): Put s in the queue Q While Q is not empty Extract v from Q If v is unmarked Mark v For each edge (v, w): Put w into the queue Q The BFS Tree • Can remember parent nodes (the node at level i that lead us to a given node at level i + 1) BFS-Tree(G, s): Put (∅, s) in the queue Q While Q is not empty Extract (p, v) from Q If v is unmarked Mark v parent(v) = p For each edge (v, w): Put (v, w) into the queue Q Spanning Trees • Definition. A spanning tree of an undirected graph G is a connected acyclic subgraph of G that contains every node of G . • The tree produced by the BFS algorithm (with (( u, parent(u)) as edges) is a spanning tree of the component containing s . • The BFS spanning tree gives the shortest path from s to every other vertex in its component (we will revisit shortest path in a couple of lectures) • BFS trees in general are short and bushy Spanning Trees • Definition. A spanning tree of an undirected graph G is a connected acyclic subgraph of G that contains every node of G . • The tree produced by the BFS algorithm (with (( u, parent(u)) as edges) is a spanning tree of the component containing s . • The BFS spanning tree gives the shortest path from s to every other vertex in its component (we will revisit shortest path in a couple of lectures) • BFS trees in general are short and bushy Generalizing BFS: Whatever-First If we change how we store -

9 the Graph Data Model
CHAPTER 9 ✦ ✦ ✦ ✦ The Graph Data Model A graph is, in a sense, nothing more than a binary relation. However, it has a powerful visualization as a set of points (called nodes) connected by lines (called edges) or by arrows (called arcs). In this regard, the graph is a generalization of the tree data model that we studied in Chapter 5. Like trees, graphs come in several forms: directed/undirected, and labeled/unlabeled. Also like trees, graphs are useful in a wide spectrum of problems such as com- puting distances, finding circularities in relationships, and determining connectiv- ities. We have already seen graphs used to represent the structure of programs in Chapter 2. Graphs were used in Chapter 7 to represent binary relations and to illustrate certain properties of relations, like commutativity. We shall see graphs used to represent automata in Chapter 10 and to represent electronic circuits in Chapter 13. Several other important applications of graphs are discussed in this chapter. ✦ ✦ ✦ ✦ 9.1 What This Chapter Is About The main topics of this chapter are ✦ The definitions concerning directed and undirected graphs (Sections 9.2 and 9.10). ✦ The two principal data structures for representing graphs: adjacency lists and adjacency matrices (Section 9.3). ✦ An algorithm and data structure for finding the connected components of an undirected graph (Section 9.4). ✦ A technique for finding minimal spanning trees (Section 9.5). ✦ A useful technique for exploring graphs, called “depth-first search” (Section 9.6). 451 452 THE GRAPH DATA MODEL ✦ Applications of depth-first search to test whether a directed graph has a cycle, to find a topological order for acyclic graphs, and to determine whether there is a path from one node to another (Section 9.7). -

An Efficient Reachability Indexing Scheme for Large Directed Graphs
1 Path-Tree: An Efficient Reachability Indexing Scheme for Large Directed Graphs RUOMING JIN, Kent State University NING RUAN, Kent State University YANG XIANG, The Ohio State University HAIXUN WANG, Microsoft Research Asia Reachability query is one of the fundamental queries in graph database. The main idea behind answering reachability queries is to assign vertices with certain labels such that the reachability between any two vertices can be determined by the labeling information. Though several approaches have been proposed for building these reachability labels, it remains open issues on how to handle increasingly large number of vertices in real world graphs, and how to find the best tradeoff among the labeling size, the query answering time, and the construction time. In this paper, we introduce a novel graph structure, referred to as path- tree, to help labeling very large graphs. The path-tree cover is a spanning subgraph of G in a tree shape. We show path-tree can be generalized to chain-tree which theoretically can has smaller labeling cost. On top of path-tree and chain-tree index, we also introduce a new compression scheme which groups vertices with similar labels together to further reduce the labeling size. In addition, we also propose an efficient incremental update algorithm for dynamic index maintenance. Finally, we demonstrate both analytically and empirically the effectiveness and efficiency of our new approaches. Categories and Subject Descriptors: H.2.8 [Database management]: Database Applications—graph index- ing and querying General Terms: Performance Additional Key Words and Phrases: Graph indexing, reachability queries, transitive closure, path-tree cover, maximal directed spanning tree ACM Reference Format: Jin, R., Ruan, N., Xiang, Y., and Wang, H. -

A Low Complexity Topological Sorting Algorithm for Directed Acyclic Graph
International Journal of Machine Learning and Computing, Vol. 4, No. 2, April 2014 A Low Complexity Topological Sorting Algorithm for Directed Acyclic Graph Renkun Liu then return error (graph has at Abstract—In a Directed Acyclic Graph (DAG), vertex A and least one cycle) vertex B are connected by a directed edge AB which shows that else return L (a topologically A comes before B in the ordering. In this way, we can find a sorted order) sorting algorithm totally different from Kahn or DFS algorithms, the directed edge already tells us the order of the Because we need to check every vertex and every edge for nodes, so that it can simply be sorted by re-ordering the nodes the “start nodes”, then sorting will check everything over according to the edges from a Direction Matrix. No vertex is again, so the complexity is O(E+V). specifically chosen, which makes the complexity to be O*E. An alternative algorithm for topological sorting is based on Then we can get an algorithm that has much lower complexity than Kahn and DFS. At last, the implement of the algorithm by Depth-First Search (DFS) [2]. For this algorithm, edges point matlab script will be shown in the appendix part. in the opposite direction as the previous algorithm. The algorithm loops through each node of the graph, in an Index Terms—DAG, algorithm, complexity, matlab. arbitrary order, initiating a depth-first search that terminates when it hits any node that has already been visited since the beginning of the topological sort: I. -

The Surprizing Complexity of Generalized Reachability Games Nathanaël Fijalkow, Florian Horn
The surprizing complexity of generalized reachability games Nathanaël Fijalkow, Florian Horn To cite this version: Nathanaël Fijalkow, Florian Horn. The surprizing complexity of generalized reachability games. 2010. hal-00525762v2 HAL Id: hal-00525762 https://hal.archives-ouvertes.fr/hal-00525762v2 Preprint submitted on 2 Feb 2012 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. The surprising complexity of generalized reachability games Nathanaël Fijalkow1,2 and Florian Horn1 1 LIAFA CNRS & Université Denis Diderot - Paris 7, France {nath,florian.horn}@liafa.jussieu.fr 2 ÉNS Cachan École Normale Supérieure de Cachan, France Abstract. Games on graphs provide a natural and powerful model for reactive systems. In this paper, we consider generalized reachability objectives, defined as conjunctions of reachability objectives. We first prove that deciding the winner in such games is PSPACE-complete, although it is fixed-parameter tractable with the number of reachability objectives as parameter. Moreover, we consider the memory requirements for both players and give matching upper and lower bounds on the size of winning strategies. In order to allow more efficient algorithms, we consider subclasses of generalized reachability games. We show that bounding the size of the reachability sets gives two natural subclasses where deciding the winner can be done efficiently. -

CS302 Final Exam, December 5, 2016 - James S
CS302 Final Exam, December 5, 2016 - James S. Plank Question 1 For each of the following algorithms/activities, tell me its running time with big-O notation. Use the answer sheet, and simply circle the correct running time. If n is unspecified, assume the following: If a vector or string is involved, assume that n is the number of elements. If a graph is involved, assume that n is the number of nodes. If the number of edges is not specified, then assume that the graph has O(n2) edges. A: Sorting a vector of uniformly distributed random numbers with bucket sort. B: In a graph with exactly one cycle, determining if a given node is on the cycle, or not on the cycle. C: Determining the connected components of an undirected graph. D: Sorting a vector of uniformly distributed random numbers with insertion sort. E: Finding a minimum spanning tree of a graph using Prim's algorithm. F: Sorting a vector of uniformly distributed random numbers with quicksort (average case). G: Calculating Fib(n) using dynamic programming. H: Performing a topological sort on a directed acyclic graph. I: Finding a minimum spanning tree of a graph using Kruskal's algorithm. J: Finding the minimum cut of a graph, after you have found the network flow. K: Finding the first augmenting path in the Edmonds Karp implementation of network flow. L: Processing the residual graph in the Ford Fulkerson algorithm, once you have found an augmenting path. Question 2 Please answer the following statements as true or false. A: Kruskal's algorithm requires a starting node. -

Lecture 16: Directed Graphs
Lecture 16: Directed Graphs BOS ORD JFK SFO DFW LAX MIA Courtesy of Goodrich, Tamassia and Olga Veksler Instructor: Yuzhen Xie Outline Directed Graphs Properties Algorithms for Directed Graphs DFS and BFS Strong Connectivity Transitive Closure DAG and Toppgological Ordering 2 Digraphs A digraph is a ggpraph whose E edges are all directed D Short for “directed graph” C Applications B one-way streets A flights task scheduling 3 Digraph Properties E D A graph G=(V,E) such that Each edge goes in one direction: C Ed(dge (A,B) goes from A to B, Edge (B,A) goes from B to A, B If G is simple, m < n*(n-1). A If we keep in-edges and out-edges in separate adjacency lists, we can perform listing of in-edges and out-edges in time proportional to their size OutgoingEdges(A): (A,C), (A,D), (A,B) IngoingEdges(A): (E,A),(B,A) We say that vertex w is reachable from vertex v if there is a directed path from v to w EiseahablefomAE is reachable from A E is not reachable from D 4 Algorithm DFS(G, v) Directed DFS Input digraph G and a start vertex v of G Output traverses vertices in G reachable from v We can specialize the setLabel(v, VISITED) traversal algorithms (DFS and for all e ∈ G.outgoingEdges(v) BFS) to digraphs by traversing edges only along w ← opposite(v,e) their direction if getLabel(w) = UNEXPLORED DFS(G, w) In the directed DFS algorithm, we have 3 four types of edges E discovery edges 4 bkdback edges D forward edges cross edges A directed DFS starting at a C 2 vertex s visits all the vertices reachable from s B 5 -

An Efficient Strongly Connected Components Algorithm In
An Efficient Strongly Connected Components Algorithm in the Fault Tolerant Model∗† Surender Baswana1, Keerti Choudhary2, and Liam Roditty3 1 Department of Computer Science and Engineering, IIT Kanpur, Kanpur, India [email protected] 2 Department of Computer Science and Engineering, IIT Kanpur, Kanpur, India [email protected] 3 Department of Computer Science, Bar Ilan University, Ramat Gan, Israel [email protected] Abstract In this paper we study the problem of maintaining the strongly connected components of a graph in the presence of failures. In particular, we show that given a directed graph G = (V, E) with n = |V | and m = |E|, and an integer value k ≥ 1, there is an algorithm that computes in O(2kn log2 n) time for any set F of size at most k the strongly connected components of the graph G \ F . The running time of our algorithm is almost optimal since the time for outputting the SCCs of G \ F is at least Ω(n). The algorithm uses a data structure that is computed in a preprocessing phase in polynomial time and is of size O(2kn2). Our result is obtained using a new observation on the relation between strongly connected components (SCCs) and reachability. More specifically, one of the main building blocks in our result is a restricted variant of the problem in which we only compute strongly connected com- ponents that intersect a certain path. Restricting our attention to a path allows us to implicitly compute reachability between the path vertices and the rest of the graph in time that depends logarithmically rather than linearly in the size of the path. -

Merkle Trees and Directed Acyclic Graphs (DAG) As We've Discussed, the Decentralized Web Depends on Linked Data Structures
Merkle trees and Directed Acyclic Graphs (DAG) As we've discussed, the decentralized web depends on linked data structures. Let's explore what those look like. Merkle trees A Merkle tree (or simple "hash tree") is a data structure in which every node is hashed. +--------+ | | +---------+ root +---------+ | | | | | +----+---+ | | | | +----v-----+ +-----v----+ +-----v----+ | | | | | | | node A | | node B | | node C | | | | | | | +----------+ +-----+----+ +-----+----+ | | +-----v----+ +-----v----+ | | | | | node D | | node E +-------+ | | | | | +----------+ +-----+----+ | | | +-----v----+ +----v-----+ | | | | | node F | | node G | | | | | +----------+ +----------+ In a Merkle tree, nodes point to other nodes by their content addresses (hashes). (Remember, when we run data through a cryptographic hash, we get back a "hash" or "content address" that we can think of as a link, so a Merkle tree is a collection of linked nodes.) As previously discussed, all content addresses are unique to the data they represent. In the graph above, node E contains a reference to the hash for node F and node G. This means that the content address (hash) of node E is unique to a node containing those addresses. Getting lost? Let's imagine this as a set of directories, or file folders. If we run directory E through our hashing algorithm while it contains subdirectories F and G, the content-derived hash we get back will include references to those two directories. If we remove directory G, it's like Grace removing that whisker from her kitten photo. Directory E doesn't have the same contents anymore, so it gets a new hash. As the tree above is built, the final content address (hash) of the root node is unique to a tree that contains every node all the way down this tree.