Cross-Core Microarchitectural Side Channel Attacks and Countermeasures
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Future EW Capabilities
CRITICAL UNCLASSIFIED INFORMATION Future EW Capabilities COL Daniel Holland, ACM-EW Director [email protected] 706-791-8476 CRITICAL17 UNCLASSIFIEDAug 2021 INFORMATION Future Army EW Capabilities AISR Target identification, geo-location, and advanced non-kinetic effects delivery for the MDO fight. HELIOS (MDSS) Altitude 60k’ EW Planning and Management Tool LOS 500 kms (nadir 18 kms) HADES (MDSS) Altitude 40k+’ UAV LOS 400 kms Spectrum Analyzer MFEW Air Large MFEW Air Small Altitude 15k-25k’ Altitude 2500-8000’ LOS 250-300 kms LOS 100-150 kms C2 Counter Fire XX Radar SAM SRBM MEMSS C2 TT Radar Tech Effects CP TA Radar C2 AISR – Aerial ISR DEA – Defensive Electromagnetic Attack GSR- Ground Surveillance Radar TA Radar ERCA – Extended Range Cannon Artillery FLOT – Forward Line of Troops IFPC – Indirect Fire Protection Capability GMLS-ER – Guided Multiple Launch Rocket System Extended Rng UGS HADES – High Accuracy Detection & Exploitation System HELIOS – High altitude Extended range Long endurance Intel Observation System LOS – Line of Sight MDSS – Multi-Domain Sensor System MEMSS - Modular Electromagnetic Spectrum System TLS EAB MFEW – Multifunction Electromagnetic Warfare Ground to Air TLS BCT M-SHORAD – Mobile Short Range Air Defense Close fight TLS – Terrestrial Layer System 30km 70km 150km TT – Target Tracking 500km FLOT THREAT TA – Target Acquisition PrSM Ver 14.6 – 30 Jul 21 155mm ERCA GMLS-ER UGS – Unmanned Ground System AREA UNCLASSIFIED Electronic Warfare Planning and Management Tool (EWPMT) Electromagnetic Warfare/Spectrum -

Electromagnetic Side Channels of an FPGA Implementation of AES
Electromagnetic Side Channels of an FPGA Implementation of AES Vincent Carlier, Herv´e Chabanne, Emmanuelle Dottax and Herv´e Pelletier SAGEM SA Abstract. We show how to attack an FPGA implementation of AES where all bytes are processed in parallel using differential electromag- netic analysis. We first focus on exploiting local side channels to isolate the behaviour of our targeted byte. Then, generalizing the Square at- tack, we describe a new way of retrieving information, mixing algebraic properties and physical observations. Keywords: side channel attacks, DEMA, FPGA, AES hardware im- plementation, Square attack. 1 Introduction Side channel attacks first appear in [Koc96] where timing attacks are de- scribed. This kind of attack tends to retrieve information from the secret items stored inside a device by observing its behaviour during a crypto- graphical computation. In a timing attack, the adversary measures the time taken to perform the computations and deduces additionnal information about the cryptosystems. Similarly, power analysis attacks are introduced in [KJJ99] where the attacker wants to discover the secrets by analysing the power consumption. Smart cards are targets of choice as their power is sup- plied externally. Usually we distinguish Simple Power Analysis (SPA), that tries to gain information directly from the power consumption, and Differ- ential Power Analysis (DPA) where a large number of traces are acquired and statistically processed. Another side channel is the one that exploits the Electromagnetic (EM) emanations. Indeed, these emanations are correlated with the current flowing through the device. EM leakage in a PC environ- ment where eavesdroppers reconstruct video screens has been known for a 1 long time [vE85], see also [McN] for more references. -

Conductive Concrete’ Shields Electronics from EMP Attack
‘Conductive concrete’ shields electronics from EMP attack November 14, 2016 Credit: Craig Chandler/University Communication/University of Nebraska-Lincoln An attack via a burst of electromagnetic energy could cripple vital electronic systems, threatening national security and critical infrastructure, such as power grids and data centers. The technology is ready for commercialization, and the University of Nebraska-Lincoln has signed an agreement to license this shielding technology to American Business Continuity Group LLC, a developer of disaster-resistant structures. Electromagnetic energy is everywhere. It travels in waves and spans a wide spectrum, from sunlight, radio waves and microwaves to X- rays and gamma rays. But a burst of electromagnetic waves caused by a high-altitude nuclear explosion or an EMP device could induce electric current and voltage surges that cause widespread electronic failures. "EMP is very lethal to electronic equipment," said Tuan, professor of civil engineering. "We found a key ingredient that dissipates wave energy. This technology oöers a lot of advantages so the construction industry is very interested." EMP-shielding concrete stemmed from Tuan and Nguyen's partnership to study concrete that conducts electricity. They ñrst developed their patented conductive concrete to melt snow and ice from surfaces, such as roadways and bridges. They also recognized and conñrmed it has another important property – the ability to block electromagnetic energy. Their technology works by both absorbing and reòecting electromagnetic waves. The team replaced some standard concrete aggregates with their key ingredient – magnetite, a mineral with magnetic properties that absorbs microwaves like a sponge. Their patented recipe includes carbon and metal components for better absorption as well as reòection. -
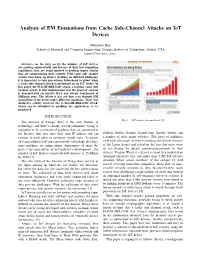
Analysis of EM Emanations from Cache Side-Channel Attacks on Iot Devices
Analysis of EM Emanations from Cache Side-Channel Attacks on IoT Devices Moumita Dey School of Electrical and Computer Engineering, Georgia Institute of Technology, Atlanta, USA [email protected] Abstract— As the days go by, the number of IoT devices are growing exponentially and because of their low computing capabilities, they are being targeted to perform bigger attacks that are compromising their security. With cache side channel attacks increasing on devices working on different platforms, it is important to take precautions beforehand to detect when a cache side channel attack is performed on an IoT device. In this paper, the FLUSH+RELOAD attack, a popular cache side channel attack, is first implemented and the proof of concept is demonstrated on GnuPG RSA and bitcnts benchmark of MiBench suite. The effects it has are then seen through EM emanations of the device under different conditions. There was distinctive activity observed due to FLUSH+RELOAD attack, which can be identified by profiling the applications to be monitored. INTRODUCTION Fig. 1. IoT devices demand trend [1] The Internet of Things (IoT) is the next frontier in technology, and there’s already several companies trying to capitalize it. Its a network of products that are connected to the Internet, thus they have their own IP address and can GitHub, Netflix, Shopify, SoundCloud, Spotify, Twitter, and connect to each other to automate simple tasks. As prices a number of other major websites. This piece of malicious of semiconductor fall and connectivity technology develops, code took advantage of devices running out-of-date versions more machines are going online. -

Key Update Countermeasure for Correlation-Based Side-Channel Attacks
Key Update Countermeasure for Correlation-Based Side-Channel Attacks Yutian Gui, Suyash Mohan Tamore, Ali Shuja Siddiqui & Fareena Saqib Journal of Hardware and Systems Security ISSN 2509-3428 J Hardw Syst Secur DOI 10.1007/s41635-020-00094-x 1 23 Your article is protected by copyright and all rights are held exclusively by Springer Nature Switzerland AG. This e-offprint is for personal use only and shall not be self- archived in electronic repositories. If you wish to self-archive your article, please use the accepted manuscript version for posting on your own website. You may further deposit the accepted manuscript version in any repository, provided it is only made publicly available 12 months after official publication or later and provided acknowledgement is given to the original source of publication and a link is inserted to the published article on Springer's website. The link must be accompanied by the following text: "The final publication is available at link.springer.com”. 1 23 Author's personal copy Journal of Hardware and Systems Security https://doi.org/10.1007/s41635-020-00094-x Key Update Countermeasure for Correlation-Based Side-Channel Attacks Yutian Gui1 · Suyash Mohan Tamore1 · Ali Shuja Siddiqui1 · Fareena Saqib1 Received: 14 January 2020 / Accepted: 13 April 2020 © Springer Nature Switzerland AG 2020 Abstract Side-channel analysis is a non-invasive form of attack that reveals the secret key of the cryptographic circuit by analyzing the leaked physical information. The traditional brute-force and cryptanalysis attacks target the weakness in the encryption algorithm, whereas side-channel attacks use statistical models such as differential analysis and correlation analysis on the leaked information gained from the cryptographic device during the run-time. -

Method for Effectiveness Assessment of Electronic Warfare Systems In
S S symmetry Article Method for Effectiveness Assessment of Electronic Warfare Systems in Cyberspace Seungcheol Choi 1, Oh-Jin Kwon 1,* , Haengrok Oh 2 and Dongkyoo Shin 3 1 Department of Electrical Engineering, Sejong University, 209 Neungdong-ro, Gwangjin-gu, Seoul 05006, Korea; [email protected] 2 Agency for Defense Development (ADD), Seoul 05771, Korea; [email protected] 3 Department of Computer Engineering, Sejong University, 209 Neungdong-ro, Gwangjin-gu, Seoul 05006, Korea; [email protected] * Correspondence: [email protected] Received: 27 November 2020; Accepted: 16 December 2020; Published: 18 December 2020 Abstract: Current electronic warfare (EW) systems, along with the rapid development of information and communication technology, are essential elements in the modern battlefield associated with cyberspace. In this study, an efficient evaluation framework is proposed to assess the effectiveness of various types of EW systems that operate in cyberspace, which is recognized as an indispensable factor affecting modern military operations. The proposed method classifies EW systems into primary and sub-categories according to EWs’ types and identifies items for the measurement of the effectiveness of each EW system by considering the characteristics of cyberspace for evaluating the damage caused by cyberattacks. A scenario with an integrated EW system incorporating two or more different types of EW equipment is appropriately provided to confirm the effectiveness of the proposed framework in cyber electromagnetic warfare. The scenario explicates an example of assessing the effectiveness of EW systems under cyberattacks. Finally, the proposed method is demonstrated sufficiently by assessing the effectiveness of the EW systems using the scenario. -

Physical Key Extraction Attacks On
contributed articles DOI:10.1145/2851486 needs to never output it or anything that Computers broadcast their secrets via may reveal it. (The operating system may be misused to allow someone else’s inadvertent physical emanations that process to peek into the program’s are easily measured and exploited. memory or files, though we are getting better at avoiding such attacks, too.) BY DANIEL GENKIN, LEV PACHMANOV, ITAMAR PIPMAN, Yet programs’ control over their ADI SHAMIR, AND ERAN TROMER own outputs is a convenient fiction, for a deeper reason. The hardware run- ning the program is a physical object and, as such, interacts with its envi- ronment in complex ways, including Physical electric currents, electromagnetic fields, sound, vibrations, and light emissions. All these “side channels” may depend on the computation per- Key Extraction formed, along with the secrets within it. “Side-channel attacks,” which ex- ploit such information leakage, have been used to break the security of nu- merous cryptographic implementa- Attacks on PCs tions; see Anderson,2 Kocher et al.,19 and Mangard et al.23 and references therein. Side channels on small devices. Many past works addressed leakage from small devices (such as smart- cards, RFID tags, FPGAs, and simple embedded devices); for such devices, CRYPTOGRAPHY IS UBIQUITOUS. Secure websites and physical key extraction attacks have financial, personal communication, corporate, and been demonstrated with devastating effectiveness and across multiple phys- national secrets all depend on cryptographic algorithms ical channels. For example, a device’s operating correctly. Builders of cryptographic systems power consumption is often correlated with the computation it is currently ex- have learned (often the hard way) to devise algorithms ecuting. -

Electromagnetic Spectrum Superiority Strategy
Our task is to ensure that American military superiority endures, and in combination with other elements of national power, is ready to protect Americans against sophisticated challenges to national security. — 2017 National Security Strategy It is the policy of the United States to use radiofrequency spectrum (spectrum) as efficiently and effectively as possible to help meet our economic, national security, science, safety, and other Federal mission goals now and in the future. — Presidential Memorandum on Developing a Sustainable Spectrum Strategy for America’s Future, October 25, 2018 2020 Department of Defense Electromagnetic Spectrum Superiority Strategy Foreword The Nation has entered an age of warfighting wherein U.S. dominance in air, land, sea, space, cyberspace, and the electromagnetic spectrum (EMS) is challenged by peer and near peer adversaries. These challenges have exposed the cross-cutting reliance of U.S. Forces on the EMS, and are driving a change in how the DoD approaches activities in the EMS to maintain an all-domain advantage. EMS challenges go well beyond the military battlespace. The EMS is being repurposed for commercial mobile broadband technologies to bolster economic growth and prosperity, which further restricts DoD’s freedom of action. These sophisticated technologies represent new opportunities for the Department and our national economy. However, they also present new challenges across the competition continuum as the electromagnetic operational environment becomes increasingly congested, contested, and constrained (i.e., complex). The Department is transitioning from the traditional consideration of electromagnetic warfare (EW) as separable from spectrum management to a unified treatment of these activities as Electromagnetic Spectrum Operations (EMSO). -

FM 3-12 Cyberspace and Electromagnetic Warfare
FM 3-12 CYBERSPACE OPERATIONS AND ELECTROMAGNETIC WARFARE AUGUST 2021 DISTRIBUTION RESTRICTION: Approved for public release; distribution is unlimited. This publication supersedes FM 3-12, dated 11 April 2017. HEADQUARTERS, DEPARTMENT OF THE ARMY This publication is available at the Army Publishing Directorate site (https://armypubs.army.mil), and the Central Army Registry site (https://atiam.train.army.mil/catalog/dashboard). Foreword Over the past two decades of persistent conflict, the Army has deployed its most capable communications systems ever. During this time, U.S. forces have continued to dominate cyberspace and the electromagnetic spectrum while conducting counterinsurgency operations in Afghanistan and Iraq against enemies and adversaries who lack the ability to challenge our technological superiority. However, in recent years, regional peers have demonstrated formidable capabilities in hybrid operational environments. These capabilities threaten the Army’s dominance in both cyberspace and the electromagnetic spectrum. The Department of Defense information network-Army is an essential warfighting platform that is a critical element of the command and control system and foundational to success in Army operations. Effectively operating, securing, and defending the network to maintain trust in its confidentiality, integrity, and availability is essential to commanders’ success at all echelons. A commander who cannot access or trust communications and information systems or the data they carry risks the loss of lives, loss of critical resources, or mission failure. At the same time, our adversaries and enemies are also increasingly reliant on networks and networked weapons systems. The Army, as part of the joint force, must be prepared to exploit or deny our adversaries and enemies the operational advantages that these networks and systems provide. -

EMP) Effect on Surveillance Unmanned Aerial Vehicles (Uavs
Study of electromagnetic pulse (EMP) effect on surveillance unmanned aerial vehicles (UAVs) Samuel Ibeobi, Xuchao Pan Department of Mechanical Engineering, Nanjing University of Science and Technology, Nanjing, Jiangsu Province, China 1Corresponding author E-mail: [email protected], [email protected] Received 10 February 2021; accepted 1 March 2021 DOI https://doi.org/10.21595/jmeacs.2021.21926 Copyright © 2021 Samuel Ibeobi, et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract. The contemporary deployment of unmanned aerial vehicles (UAVs) for commercial purposes and electromagnetic pulse (EMP) threat to mechatronic devices necessitates the study of EMP on surveillance UAVs. This research paper describes the effect of EMP interference on the structure, communication and cabling circuit of the UAV. This was achieved using the CST microwave studio with an induced plane wave referring to MIL-STD464 and applying the transmission line matric solver method. The cable field coupling for bi-directional, uni-directional radiation and uni-directional irradiation were carried out with a constant resistive load of 50 Ω and the induced coupling currents and voltages, current in space domain, TLM mesh is obtained indicating the susceptibility of the UAV under different conditions of EMP interference and the electromagnetic distribution in the UAV circuit layout. Experimentally, the UAV is setup with an EMP generator and its response was observed at 12 m, 10 m and 8 m from the radiation source with the corresponding field strengths. Keywords: CST, electromagnetic interference, induced coupling, UAV. -

Active Electromagnetic Attacks on Secure Hardware
UCAM-CL-TR-811 Technical Report ISSN 1476-2986 Number 811 Computer Laboratory Active electromagnetic attacks on secure hardware A. Theodore Markettos December 2011 15 JJ Thomson Avenue Cambridge CB3 0FD United Kingdom phone +44 1223 763500 http://www.cl.cam.ac.uk/ c 2011 A. Theodore Markettos This technical report is based on a dissertation submitted March 2010 by the author for the degree of Doctor of Philosophy to the University of Cambridge, Clare Hall. Technical reports published by the University of Cambridge Computer Laboratory are freely available via the Internet: http://www.cl.cam.ac.uk/techreports/ ISSN 1476-2986 Active electromagnetic attacks on secure hardware A. Theodore Markettos Summary The field of side-channel attacks on cryptographic hardware has been extensively studied. In many cases it is easier to derive the secret key from these attacks than to break the cryptography itself. One such side- channel attack is the electromagnetic side-channel attack, giving rise to electromagnetic analysis (EMA). EMA, when otherwise known as ‘TEMPEST’ or ‘compromising eman- ations’, has a long history in the military context over almost the whole of the twentieth century. The US military also mention three related at- tacks, believed to be: HIJACK (modulation of secret data onto conducted signals), NONSTOP (modulation of secret data onto radiated signals) and TEAPOT (intentional malicious emissions). In this thesis I perform a fusion of TEAPOT and HIJACK/NONSTOP techniques on secure integrated circuits. An attacker is able to introduce one or more frequencies into a cryptographic system with the intention of forcing it to misbehave or to radiate secrets. -
TEMPEST Font Protects Text Data Against RF Electromagnetic Attack
ISSN 1330-3651 (Print), ISSN 1848-6339 (Online) https://doi.org/10.17559/TV-20180325143031 Original scientific paper TEMPEST Font Protects Text Data against RF Electromagnetic Attack Ireneusz KUBIAK Abstract: Nowadays an electromagnetic penetration process of electronic devices has a big significance. Processed information in electronic form could be protected in different ways. Very often used methods limit the levels of valuable emissions. But such methods could not always be implemented in commercial devices. A new solution (soft tempest) is proposed. The solution is based on TEMPEST font. The font does not possess distinctive features. This phenomenon causes that at an output of Side Channel Attack the possibilities of recognition of each character which appears on the reconstructed image for sources in the form of graphic lines (VGA and DVI) are limited. In this way the TEMPEST font protects processed data against electromagnetic penetration not only for VGA and DVI standards. The data are protected during printing them on laser printers too. Keywords: digital image processing; digital signal processing; eavesdropping process; protection of information; soft TEMPEST; valuable (sensitive) emission 1 INTRODUCTION processed information against electromagnetic penetration. A shielding is a very popular method which limits levels of Protection of information against electromagnetic electromagnetic disturbances from IT devices [2, 17]. penetration process is a very important challenge. To Other method consists in filtering electric video signals protect information various methods and solutions are Fig. 1, [18, 19]. used. Most popular solution is a restricted access to space where classified information is processed [1, 2]. However, electronic devices are sources of electromagnetic emissions.