Linux and UNIX Cat Command Help and Examples
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Administering Unidata on UNIX Platforms
C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta UniData Administering UniData on UNIX Platforms UDT-720-ADMU-1 C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Notices Edition Publication date: July, 2008 Book number: UDT-720-ADMU-1 Product version: UniData 7.2 Copyright © Rocket Software, Inc. 1988-2010. All Rights Reserved. Trademarks The following trademarks appear in this publication: Trademark Trademark Owner Rocket Software™ Rocket Software, Inc. Dynamic Connect® Rocket Software, Inc. RedBack® Rocket Software, Inc. SystemBuilder™ Rocket Software, Inc. UniData® Rocket Software, Inc. UniVerse™ Rocket Software, Inc. U2™ Rocket Software, Inc. U2.NET™ Rocket Software, Inc. U2 Web Development Environment™ Rocket Software, Inc. wIntegrate® Rocket Software, Inc. Microsoft® .NET Microsoft Corporation Microsoft® Office Excel®, Outlook®, Word Microsoft Corporation Windows® Microsoft Corporation Windows® 7 Microsoft Corporation Windows Vista® Microsoft Corporation Java™ and all Java-based trademarks and logos Sun Microsystems, Inc. UNIX® X/Open Company Limited ii SB/XA Getting Started The above trademarks are property of the specified companies in the United States, other countries, or both. All other products or services mentioned in this document may be covered by the trademarks, service marks, or product names as designated by the companies who own or market them. License agreement This software and the associated documentation are proprietary and confidential to Rocket Software, Inc., are furnished under license, and may be used and copied only in accordance with the terms of such license and with the inclusion of the copyright notice. -
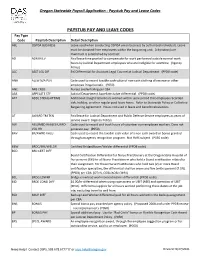
Oregon Statewide Payroll Application ‐ Paystub Pay and Leave Codes
Oregon Statewide Payroll Application ‐ Paystub Pay and Leave Codes PAYSTUB PAY AND LEAVE CODES Pay Type Code Paystub Description Detail Description ABL OSPOA BUSINESS Leave used when conducting OSPOA union business by authorized individuals. Leave must be donated from employees within the bargaining unit. A donation/use maximum is established by contract. AD ADMIN LV Paid leave time granted to compensate for work performed outside normal work hours by Judicial Department employees who are ineligible for overtime. (Agency Policy) ALC ASST LGL DIF 5% Differential for Assistant Legal Counsel at Judicial Department. (PPDB code) ANA ALLW N/A PLN Code used to record taxable cash value of non-cash clothing allowance or other employee fringe benefit. (P050) ANC NRS CRED Nurses credentialing per CBA ASA APPELATE STF Judicial Department Appellate Judge differential. (PPDB code) AST ADDL STRAIGHTTIME Additional straight time hours worked within same period that employee recorded sick, holiday, or other regular paid leave hours. Refer to Statewide Policy or Collective Bargaining Agreement. Hours not used in leave and benefit calculations. AT AWARD TM TKN Paid leave for Judicial Department and Public Defense Service employees as years of service award. (Agency Policy) AW ASSUMED WAGES-UNPD Code used to record and track hours of volunteer non-employee workers. Does not VOL HR generate pay. (P050) BAV BP/AWRD VALU Code used to record the taxable cash value of a non-cash award or bonus granted through an agency recognition program. Not PERS subject. (P050 code) BBW BRDG/BM/WELDR Certified Bridge/Boom/Welder differential (PPDB code) BCD BRD CERT DIFF Board Certification Differential for Nurse Practitioners at the Oregon State Hospital of five percent (5%) for all Nurse Practitioners who hold a Board certification related to their assignment. -

Small Group Instructional Diagnosis: Final Report
DOCUMENT RESUME JC 820 333 , ED 217 954 AUTHOR Clark, D. Joseph; Redmond, Mark V. TITLE Small Group Instructional Diagnosis: Final Report. INSTITUTION Washington Univ., Seattle. Dept. of Biology c Education. ., 'SPONS AGENCY Fund for the Improwsent of Postsecondary Education . (ED), Washington, D.C. , PUB DATE [82] NOTE 21p.; Appendices mentioned in the report are not _ included. EDRS PRICE , 401/PC01 Plus Postage. DESCRIPTORS *Course Evaluation; *Evaluation Methods; *Instructional Improvement; Postsecondary Education; *Student Evaluation of Teacher Performance;- tudent , Reaction; *Teacher Attitudes; Teacher Workshop IDENTIFIERS *Small group Instructional Diagnosis, ABSTRACT- A procedure for student evaluation andfeedback on faculty instruction was developed at the University of Washington. The system involved the use of,faculty members as facilitatorsin ,conducting Small Group Instructional Diagnosis (SGID) to generate student feedback to instructors about- the courses' strengths, areas needing improvement, and suggestions for bringing about these improvements. The SGID.procedure involves a number of steps:contact between the facilitator and instructor; classroomintervention to ascertain student opinions; a feedback session between facilitator and instructor; instructor. review of the SGID with the class;and ,a follow-up session between the facilitator and instructor.Following the development of the SGID process, handouts andvideotapes were produced to explain the procedure and the SGID technique was demonstrated in over 130 classes -

Penndot Form MV-409
MV-409 (3-18) www.dmv.pa.gov APPLICATION FOR CERTIFICATION OF For Department Use Only BureauP.O. Box of Motor 68697 Vehicles Harrisburg, • Vehicle PAInspection 17106-8697 Division OFFICIAL VEHICLE SAFETY INSPECTOR • PRINT OR TYPE ALL INFORMATION - MUST BE SUBMITTED TO AN APPROVED EDUCATIONAL FACILITY Applicant must be 18 years of age and have a valid operator’s license for each class of vehicle he/she intends to inspect. Applicant must also complete a lecture course at an approved educational facility, pass a written test and satisfactorily perform a complete inspection of a vehicle. upon successful completion of these courses, you will receive your certified safety inspection certification card in approximately 6 to 8 weeks from the date your class ended. The school has 35 days from the class ending date to submit the paperwork for processing. You may not begin inspecting until you receive your certification card. A APPLICANT INFORMATION Last Name First Name Middle Name Sex birth Date Driver’s License Number State r M r F Street Address City State County Zip Code Work Telephone Number Home Telephone Number Do you currently hold a valid out-of-state driver’s license? (If yes, attach a copy.) . r Yes r No *Contact PennDOT’s Vehicle Inspection Division at 717-787-2895 to establish an out-of-state mechanic record prior to completion of this class. List any restrictions on your driver’s license (if applicable): ______________________________________________________________ Do you currently hold a valid Pennsylvania driver’s license? . r Yes r No Have you held a Pennsylvania driver’s license in the past? . -

User Manual for Ox: an Attribute-Grammar Compiling System Based on Yacc, Lex, and C Kurt M
Computer Science Technical Reports Computer Science 12-1992 User Manual for Ox: An Attribute-Grammar Compiling System based on Yacc, Lex, and C Kurt M. Bischoff Iowa State University Follow this and additional works at: http://lib.dr.iastate.edu/cs_techreports Part of the Programming Languages and Compilers Commons Recommended Citation Bischoff, Kurt M., "User Manual for Ox: An Attribute-Grammar Compiling System based on Yacc, Lex, and C" (1992). Computer Science Technical Reports. 21. http://lib.dr.iastate.edu/cs_techreports/21 This Article is brought to you for free and open access by the Computer Science at Iowa State University Digital Repository. It has been accepted for inclusion in Computer Science Technical Reports by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. User Manual for Ox: An Attribute-Grammar Compiling System based on Yacc, Lex, and C Abstract Ox generalizes the function of Yacc in the way that attribute grammars generalize context-free grammars. Ordinary Yacc and Lex specifications may be augmented with definitions of synthesized and inherited attributes written in C syntax. From these specifications, Ox generates a program that builds and decorates attributed parse trees. Ox accepts a most general class of attribute grammars. The user may specify postdecoration traversals for easy ordering of side effects such as code generation. Ox handles the tedious and error-prone details of writing code for parse-tree management, so its use eases problems of security and maintainability associated with that aspect of translator development. The translators generated by Ox use internal memory management that is often much faster than the common technique of calling malloc once for each parse-tree node. -

LS-CAT: a Large-Scale CUDA Autotuning Dataset
LS-CAT: A Large-Scale CUDA AutoTuning Dataset Lars Bjertnes, Jacob O. Tørring, Anne C. Elster Department of Computer Science Norwegian University of Science and Technology (NTNU) Trondheim, Norway [email protected], [email protected], [email protected] Abstract—The effectiveness of Machine Learning (ML) meth- However, these methods are still reliant on compiling and ods depend on access to large suitable datasets. In this article, executing the program to do gradual adjustments, which still we present how we build the LS-CAT (Large-Scale CUDA takes a lot of time. A better alternative would be to have an AutoTuning) dataset sourced from GitHub for the purpose of training NLP-based ML models. Our dataset includes 19 683 autotuner that can find good parameters without compiling or CUDA kernels focused on linear algebra. In addition to the executing the program. CUDA codes, our LS-CAT dataset contains 5 028 536 associated A dataset consisting of the results for each legal combina- runtimes, with different combinations of kernels, block sizes and tion of hardware systems, and all other information that can matrix sizes. The runtime are GPU benchmarks on both Nvidia change the performance or the run-time, could be used to find GTX 980 and Nvidia T4 systems. This information creates a foundation upon which NLP-based models can find correlations the absolute optimal combination of parameters for any given between source-code features and optimal choice of thread block configuration. Unfortunately creating such a dataset would, as sizes. mentioned above, take incredibly long time, and the amount There are several results that can be drawn out of our LS-CAT of data required would make the dataset huge. -

User's Manual
USER’S MANUAL USER’S > UniQTM UniQTM User’s Manual Ed.: 821003146 rev.H © 2016 Datalogic S.p.A. and its Group companies • All rights reserved. • Protected to the fullest extent under U.S. and international laws. • Copying or altering of this document is prohibited without express written consent from Datalogic S.p.A. • Datalogic and the Datalogic logo are registered trademarks of Datalogic S.p.A. in many countries, including the U.S. and the E.U. All other brand and product names mentioned herein are for identification purposes only and may be trademarks or registered trademarks of their respective owners. Datalogic shall not be liable for technical or editorial errors or omissions contained herein, nor for incidental or consequential damages resulting from the use of this material. Printed in Donnas (AO), Italy. ii SYMBOLS Symbols used in this manual along with their meaning are shown below. Symbols and signs are repeated within the chapters and/or sections and have the following meaning: Generic Warning: This symbol indicates the need to read the manual carefully or the necessity of an important maneuver or maintenance operation. Electricity Warning: This symbol indicates dangerous voltage associated with the laser product, or powerful enough to constitute an electrical risk. This symbol may also appear on the marking system at the risk area. Laser Warning: This symbol indicates the danger of exposure to visible or invisible laser radiation. This symbol may also appear on the marking system at the risk area. Fire Warning: This symbol indicates the danger of a fire when processing flammable materials. -

91 Communication Option Kits
PowerFlex 7-Class and AFE Options Communication Option Kits Used with PowerFlex Drive Description Cat. No. 70 753/755 AFE BACnet/IP Option Module 20-750-BNETIP ✓ BACnet® MS/TP RS485 Communication Adapter 20-COMM-B ✓✓ Coaxial ControlNet™ Option Module 20-750-CNETC ✓ ControlNet™ Communication Adapter (Coax) 20-COMM-C ✓✓ (1) ✓ DeviceNet™ Option Module 20-750-DNET ✓ DeviceNet™ Communication Adapter 20-COMM-D ✓✓ (1) ✓ Dual-port EtherNet/IP Option Module 20-750-ENETR ✓ EtherNet/IP™ Communication Adapter 20-COMM-E ✓✓ (1) ✓ Dual-port EtherNet/IP™ Communication Adapter 20-COMM-ER ✓✓ HVAC Communication Adapter 20-COMM-H ✓✓ (1) ✓ CANopen® Communication Adapter 20-COMM-K ✓✓ (1) ✓ LonWorks® Communication Adapter 20-COMM-L ✓✓ (1) ✓ Modbus/TCP Communication Adapter 20-COMM-M ✓✓ (1) ✓ Profi bus DPV1 Option Module 20-750-PBUS ✓ Single-port Profi net I/O Option Module 20-750-PNET ✓ Dual-port Profi net I/O Option Module 20-750-PNET2P ✓ PROFIBUS™ DP Communication Adapter 20-COMM-P ✓✓ (1) ✓ ControlNet™ Communication Adapter (Fiber) 20-COMM-Q ✓✓ (1) ✓ Remote I/O Communication Adapter (2) 20-COMM-R ✓✓ (1) ✓ RS485 DF1 Communication Adapter 20-COMM-S ✓✓ (1) ✓ External Communications Kit Power Supply 20-XCOMM-AC-PS1 ✓✓✓ DPI External Communications Kit 20-XCOMM-DC-BASE ✓✓✓ External DPI I/O Option Board(3) 20-XCOMM-IO-OPT1 ✓✓✓ Compact I/O Module (3 Channel) 1769-SM1 ✓✓✓ (1) Requires a Communication Carrier Card (20-750-20COMM or 20-750-20COMM-F1). Refer to PowerFlex 750-Series Legacy Communication Compatibility for details. (2) This item has Silver Series status. (3) For use only with DPI External Communications Kits 20-XCOMM-DC-BASE. -

Unix Programmer's Manual
There is no warranty of merchantability nor any warranty of fitness for a particu!ar purpose nor any other warranty, either expressed or imp!ied, a’s to the accuracy of the enclosed m~=:crials or a~ Io ~helr ,~.ui~::~::.j!it’/ for ~ny p~rficu~ar pur~.~o~e. ~".-~--, ....-.re: " n~ I T~ ~hone Laaorator es 8ssumg$ no rO, p::::nS,-,,.:~:y ~or their use by the recipient. Furln=,, [: ’ La:::.c:,:e?o:,os ~:’urnes no ob~ja~tjon ~o furnish 6ny a~o,~,,..n~e at ~ny k:nd v,,hetsoever, or to furnish any additional jnformstjcn or documenta’tjon. UNIX PROGRAMMER’S MANUAL F~ifth ~ K. Thompson D. M. Ritchie June, 1974 Copyright:.©d972, 1973, 1974 Bell Telephone:Laboratories, Incorporated Copyright © 1972, 1973, 1974 Bell Telephone Laboratories, Incorporated This manual was set by a Graphic Systems photo- typesetter driven by the troff formatting program operating under the UNIX system. The text of the manual was prepared using the ed text editor. PREFACE to the Fifth Edition . The number of UNIX installations is now above 50, and many more are expected. None of these has exactly the same complement of hardware or software. Therefore, at any particular installa- tion, it is quite possible that this manual will give inappropriate information. The authors are grateful to L. L. Cherry, L. A. Dimino, R. C. Haight, S. C. Johnson, B. W. Ker- nighan, M. E. Lesk, and E. N. Pinson for their contributions to the system software, and to L. E. McMahon for software and for his contributions to this manual. -

UNIQUE E FLEXICR RETE XP P Polyme Er Modifie Ed Morta R
UNIQUE FLEXICRETE® XPP Polymer Modified Mortar Safety Data Sheet (Complies with OHSA 29 CFR 1910.1200) SECTION 1 ‐ PRODUCT IDENTIFICATION UNIQUE Paving Materials Corp. Information Telephone 3993 East 93rd Street Number Cleveland, Ohio 44105 ‐ USA (216) 341‐7711 www.uniquepavingmaterials.com Emergency Telephone Number (800) 424‐9300 Revision: April 3, 2015 UNIQUE Product Name Product # FLEXICRETE XP Polymer Modified Mortar N/A Product Use: Cementitious Mortar Section 2 – HAZARD IDENTIFICATION Physical Hazards Not Classified Health Hazards Skin corrosion / irritation Category 2 Serious Eye Damage Category 1 Carcinogenicity Category 1A Specific Target Organ Toxicity after Single Exposure Category 3 Specific Target Organ Toxicity after Repeated Exposure Category 1 OSHA defined hazards Not Classified Signal Word (GHS‐US): DANGER Hazard statement ‐ Causes skin irritation. Causes serious eye damage. May cause cancer. May cause respiratory irritation. May cause damage to organs (Lungs) through prolonged or repeated exposure. Form 205.136 (12-2015) 1 Page 3993 E. 93rd Street ι Cleveland, OH 44105 ι Phone 800.441.4880 ι Fax 216.341.8514 ι UniquePavingMaterials.com UNIQUE FLEXICRETE® XPP Polymer Modified Mortar Safety Data Sheet (Complies with OHSA 29 CFR 1910.1200) Precautionary statement Prevention ‐ Obtain special instructions before use. Do not handle until all safety precautions have been read and understood. Do not breathe dust. Wash thoroughly after handling. Use in a well‐ventilated area. Wear protective gloves/protective clothing/eye protection/face protection. Response ‐ If exposed or concerned: Get medical advice/attention. If in eyes: Rinse cautiously with water for several minutes. Remove contact lenses, if present and easy to do. Continue rinsing. -

Poolcomm Setup Wireless Capability with Water Quality Controllers
Poolcomm Setup Wireless Capability with Water Quality Controllers Contents Registration. .............................. .2 Cell/Satellite. ......................... .2 WIFI. .................................... .3 IMPORTANT SAFETY INSTRUCTIONS Basic safety precautions should always be followed, including the following: Failure to fol- low instructions can cause severe injury and/or death. This is the safety-alert symbol. When you see this symbol on your equipment or in this manual, look for one of the following signal words and be alert to the potential for personal injury. WARNING warns about hazards that could cause serious personal injury, death or ma- jor property damage and if ignored presents a potential hazard. CAUTION warns about hazards that will or can cause minor or moderate personal injury and/or property damage and if ignored presents a potential hazard. It can also make con- sumers aware of actions that are unpredictable and unsafe. Hayward Commercial Pool Products 10101 Molecular Drive, Suite 200 Rockville, MD 20850 www.haywardcommercialpool.com USE ONLY HAYWARD GENUINE REPLACEMENT PARTS To activate your new CAT 4000 wireless controller on the Poolcomm web site you must first create an account. Register PoolComm Account Go to www.poolcomm.com, and select the “Register Account” link on the top left of the page. Complete all the required company information and press “Register”. You will receive an email containing your 8- letter login in password. This can be changed to a password of your choice after your first login. Register New Unit Once logged in, select the “Register New Unit” tab. Next using the six digit serial number printed on the side of the controller, fill in all the information and then select “Register Unit”. -

RESPONDING to COMPLEXITY a Case Study on the Use of “Developmental Evaluation for Managing Adaptively”
RESPONDING TO COMPLEXITY A Case Study on the Use of “Developmental Evaluation for Managing Adaptively” A Master’s Capstone in partial fulfillment of the Master of Education in International Education at the University of Massachusetts Amherst Spring 2017 Kayla Boisvert Candidate to Master of Education in International Education University of Massachusetts Amherst Amherst, Massachusetts May 10, 2017 Abstract Over the past 15 years, the international development field has increasingly emphasized the need to improve aid effectiveness. While there have been many gains as a result of this emphasis, many critique the mechanisms that have emerged to enhance aid effectiveness, particularly claiming that they inappropriately force adherence to predefined plans and hold programs accountable for activities and outputs, not outcomes. However, with growing acceptance of the complexity of development challenges, different ways to design, manage, and evaluate projects are beginning to take hold that better reflect this reality. Many development practitioners explain that Developmental Evaluation (DE) and Adaptive Management (AM) offer alternatives to traditional management and monitoring and evaluation approaches that are better suited to address complex challenges. Both DE and AM are approaches for rapidly and systematically collecting data for the purpose of adapting projects in the face of complexity. There are many advocates for the use of DE and AM in complex development contexts, as well as some case studies on how these approaches are being applied. This study aims to build on existing literature that provides examples of how DE and AM are being customized to address complex development challenges by describing and analyzing how one non-governmental organization, Catalytic Communities (CatComm), working in the favelas of Rio de Janeiro, Brazil, uses DE for Managing Adaptively, a term we have used to name their approach to management and evaluation.