Semantics of Programming Languages Computer Science Tripos, Part 1B 2008–9
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Administering Unidata on UNIX Platforms
C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta UniData Administering UniData on UNIX Platforms UDT-720-ADMU-1 C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Notices Edition Publication date: July, 2008 Book number: UDT-720-ADMU-1 Product version: UniData 7.2 Copyright © Rocket Software, Inc. 1988-2010. All Rights Reserved. Trademarks The following trademarks appear in this publication: Trademark Trademark Owner Rocket Software™ Rocket Software, Inc. Dynamic Connect® Rocket Software, Inc. RedBack® Rocket Software, Inc. SystemBuilder™ Rocket Software, Inc. UniData® Rocket Software, Inc. UniVerse™ Rocket Software, Inc. U2™ Rocket Software, Inc. U2.NET™ Rocket Software, Inc. U2 Web Development Environment™ Rocket Software, Inc. wIntegrate® Rocket Software, Inc. Microsoft® .NET Microsoft Corporation Microsoft® Office Excel®, Outlook®, Word Microsoft Corporation Windows® Microsoft Corporation Windows® 7 Microsoft Corporation Windows Vista® Microsoft Corporation Java™ and all Java-based trademarks and logos Sun Microsystems, Inc. UNIX® X/Open Company Limited ii SB/XA Getting Started The above trademarks are property of the specified companies in the United States, other countries, or both. All other products or services mentioned in this document may be covered by the trademarks, service marks, or product names as designated by the companies who own or market them. License agreement This software and the associated documentation are proprietary and confidential to Rocket Software, Inc., are furnished under license, and may be used and copied only in accordance with the terms of such license and with the inclusion of the copyright notice. -

DC Console Using DC Console Application Design Software
DC Console Using DC Console Application Design Software DC Console is easy-to-use, application design software developed specifically to work in conjunction with AML’s DC Suite. Create. Distribute. Collect. Every LDX10 handheld computer comes with DC Suite, which includes seven (7) pre-developed applications for common data collection tasks. Now LDX10 users can use DC Console to modify these applications, or create their own from scratch. AML 800.648.4452 Made in USA www.amltd.com Introduction This document briefly covers how to use DC Console and the features and settings. Be sure to read this document in its entirety before attempting to use AML’s DC Console with a DC Suite compatible device. What is the difference between an “App” and a “Suite”? “Apps” are single applications running on the device used to collect and store data. In most cases, multiple apps would be utilized to handle various operations. For example, the ‘Item_Quantity’ app is one of the most widely used apps and the most direct means to take a basic inventory count, it produces a data file showing what items are in stock, the relative quantities, and requires minimal input from the mobile worker(s). Other operations will require additional input, for example, if you also need to know the specific location for each item in inventory, the ‘Item_Lot_Quantity’ app would be a better fit. Apps can be used in a variety of ways and provide the LDX10 the flexibility to handle virtually any data collection operation. “Suite” files are simply collections of individual apps. Suite files allow you to easily manage and edit multiple apps from within a single ‘store-house’ file and provide an effortless means for device deployment. -

AEDIT Text Editor Iii Notational Conventions This Manual Uses the Following Conventions: • Computer Input and Output Appear in This Font
Quick Contents Chapter 1. Introduction and Tutorial Chapter 2. The Editor Basics Chapter 3. Editing Commands Chapter 4. AEDIT Invocation Chapter 5. Macro Commands Chapter 6. AEDIT Variables Chapter 7. Calc Command Chapter 8. Advanced AEDIT Usage Chapter 9. Configuration Commands Appendix A. AEDIT Command Summary Appendix B. AEDIT Error Messages Appendix C. Summary of AEDIT Variables Appendix D. Configuring AEDIT for Other Terminals Appendix E. ASCII Codes Index AEDIT Text Editor iii Notational Conventions This manual uses the following conventions: • Computer input and output appear in this font. • Command names appear in this font. ✏ Note Notes indicate important information. iv Contents 1 Introduction and Tutorial AEDIT Tutorial ............................................................................................... 2 Activating the Editor ................................................................................ 2 Entering, Changing, and Deleting Text .................................................... 3 Copying Text............................................................................................ 5 Using the Other Command....................................................................... 5 Exiting the Editor ..................................................................................... 6 2 The Editor Basics Keyboard ......................................................................................................... 8 AEDIT Display Format .................................................................................. -
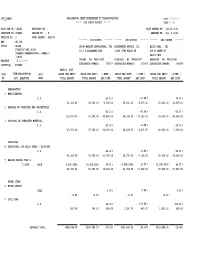
Bid Check Report * * * Time: 14:04
DOT_RGGB01 WASHINGTON STATE DEPARTMENT OF TRANSPORTATION DATE: 05/28/2013 * * * BID CHECK REPORT * * * TIME: 14:04 PS &E JOB NO : 11W101 REVISION NO : BIDS OPENED ON : Jun 26 2013 CONTRACT NO : 008498 REGION NO : 9 AWARDED ON : Jul 1 2013 VERSION NO : 2 WORK ORDER# : XL4078 ------- LOW BIDDER ------- ------- 2ND BIDDER ------- ------- 3RD BIDDER ------- HWY : SR 104 TITLE : SR104 ORION MARINE CONTRACTORS, INC. BLACKWATER MARINE, LLC QUIGG BROS., INC. KINGSTON TML SLIPS 1112 E ALEXANDER AVE 12019 76TH PLACE NE 819 W STATE ST DOLPHIN PRESERVATION - PHASE 4 98520-5934 11W101 PROJECT : NH-2013(079) TACOMA WA 984214102 KIRKLAND WA 980342437 ABERDEEN WA 985200281 COUNTY(S) : KITSAP CONTRACTOR NUMBER : 100767 CONTRACTOR NUMBER : 100874 CONTRACTOR NUMBER : 680000 ENGR'S. EST. ITEM ITEM DESCRIPTION UNIT PRICE PER UNIT/ PRICE PER UNIT/ % DIFF./ PRICE PER UNIT/ % DIFF./ PRICE PER UNIT/ % DIFF./ NO. EST. QUANTITY MEAS TOTAL AMOUNT TOTAL AMOUNT AMT.DIFF. TOTAL AMOUNT AMT.DIFF. TOTAL AMOUNT AMT.DIFF. PREPARATION 1 MOBILIZATION L.S. -25.20 % -25.48 % 40.00 % 25,000.00 18,700.00 -6,300.00 18,630.00 -6,370.00 35,000.00 10,000.00 2 REMOVAL OF STRUCTURE AND OBSTRUCTION L.S. -56.10 % -65.08 % -56.71 % 115,500.00 50,700.00 -64,800.00 40,338.00 -75,162.00 50,000.00 -65,500.00 3 DISPOSAL OF CREOSOTED MATERIAL L.S. -21.05 % -8.99 % -15.79 % 47,500.00 37,500.00 -10,000.00 43,228.35 -4,271.65 40,000.00 -7,500.00 STRUCTURE 4 STRUCTURAL LOW ALLOY STEEL - DOLPHINS L.S. -

COMMAND LINE CHEAT SHEET Presented by TOWER — the Most Powerful Git Client for Mac
COMMAND LINE CHEAT SHEET presented by TOWER — the most powerful Git client for Mac DIRECTORIES FILES SEARCH $ pwd $ rm <file> $ find <dir> -name "<file>" Display path of current working directory Delete <file> Find all files named <file> inside <dir> (use wildcards [*] to search for parts of $ cd <directory> $ rm -r <directory> filenames, e.g. "file.*") Change directory to <directory> Delete <directory> $ grep "<text>" <file> $ cd .. $ rm -f <file> Output all occurrences of <text> inside <file> (add -i for case-insensitivity) Navigate to parent directory Force-delete <file> (add -r to force- delete a directory) $ grep -rl "<text>" <dir> $ ls Search for all files containing <text> List directory contents $ mv <file-old> <file-new> inside <dir> Rename <file-old> to <file-new> $ ls -la List detailed directory contents, including $ mv <file> <directory> NETWORK hidden files Move <file> to <directory> (possibly overwriting an existing file) $ ping <host> $ mkdir <directory> Ping <host> and display status Create new directory named <directory> $ cp <file> <directory> Copy <file> to <directory> (possibly $ whois <domain> overwriting an existing file) OUTPUT Output whois information for <domain> $ cp -r <directory1> <directory2> $ curl -O <url/to/file> $ cat <file> Download (via HTTP[S] or FTP) Copy <directory1> and its contents to <file> Output the contents of <file> <directory2> (possibly overwriting files in an existing directory) $ ssh <username>@<host> $ less <file> Establish an SSH connection to <host> Output the contents of <file> using -

Top 15 ERP Software Vendors – 2010
Top 15 ERP Software Vendors – 2010 Profiles of the Leading ERP Vendors Find the best ERP system for your company. For more information visit Business-Software.com/ERP. About ERP Software Enterprise resource planning (ERP) is not a new concept. It was introduced more than 40 years ago, when the first ERP system was created to improve inventory control and management at manufacturing firms. Throughout the 70’s and 80’s, as the number of companies deploying ERP increased, its scope expanded quite a bit to include various production and materials management functions, although it was designed primarily for use in manufacturing plants. In the 1990’s, vendors came to realize that other types of business could benefit from ERP, and that in order for a business to achieve true organizational efficiency, it needed to link all its internal business processes in a cohesive and coordinated way. As a result, ERP was transformed into a broad-reaching environment that encompassed all activities across the back office of a company. What is ERP? An ERP system combines methodologies with software and hardware components to integrate numerous critical back-office functions across a company. Made up of a series of “modules”, or applications that are seamlessly linked together through a common database, an ERP system enables various departments or operating units such as Accounting and Finance, Human Resources, Production, and Fulfillment and Distribution to coordinate activities, share information, and collaborate. Key Benefits for Your Company ERP systems are designed to enhance all aspects of key operations across a company’s entire back-office – from planning through execution, management, and control. -

Avoiding the Top 10 Software Security Design Flaws
AVOIDING THE TOP 10 SOFTWARE SECURITY DESIGN FLAWS Iván Arce, Kathleen Clark-Fisher, Neil Daswani, Jim DelGrosso, Danny Dhillon, Christoph Kern, Tadayoshi Kohno, Carl Landwehr, Gary McGraw, Brook Schoenfield, Margo Seltzer, Diomidis Spinellis, Izar Tarandach, and Jacob West CONTENTS Introduction ..................................................................................................................................................... 5 Mission Statement ..........................................................................................................................................6 Preamble ........................................................................................................................................................... 7 Earn or Give, but Never Assume, Trust ...................................................................................................9 Use an Authentication Mechanism that Cannot be Bypassed or Tampered With .................... 11 Authorize after You Authenticate ...........................................................................................................13 Strictly Separate Data and Control Instructions, and Never Process Control Instructions Received from Untrusted Sources ........................................................................................................... 14 Define an Approach that Ensures all Data are Explicitly Validated .............................................16 Use Cryptography Correctly .................................................................................................................... -

Humidity Definitions
ROTRONIC TECHNICAL NOTE Humidity Definitions 1 Relative humidity Table of Contents Relative humidity is the ratio of two pressures: %RH = 100 x p/ps where p is 1 Relative humidity the actual partial pressure of the water vapor present in the ambient and ps 2 Dew point / Frost the saturation pressure of water at the temperature of the ambient. point temperature Relative humidity sensors are usually calibrated at normal room temper - 3 Wet bulb ature (above freezing). Consequently, it generally accepted that this type of sensor indicates relative humidity with respect to water at all temperatures temperature (including below freezing). 4 Vapor concentration Ice produces a lower vapor pressure than liquid water. Therefore, when 5 Specific humidity ice is present, saturation occurs at a relative humidity of less than 100 %. 6 Enthalpy For instance, a humidity reading of 75 %RH at a temperature of -30°C corre - 7 Mixing ratio sponds to saturation above ice. by weight 2 Dew point / Frost point temperature The dew point temperature of moist air at the temperature T, pressure P b and mixing ratio r is the temperature to which air must be cooled in order to be saturated with respect to water (liquid). The frost point temperature of moist air at temperature T, pressure P b and mixing ratio r is the temperature to which air must be cooled in order to be saturated with respect to ice. Magnus Formula for dew point (over water): Td = (243.12 x ln (pw/611.2)) / (17.62 - ln (pw/611.2)) Frost point (over ice): Tf = (272.62 x ln (pi/611.2)) / (22.46 - -

GNU Grep: Print Lines That Match Patterns Version 3.7, 8 August 2021
GNU Grep: Print lines that match patterns version 3.7, 8 August 2021 Alain Magloire et al. This manual is for grep, a pattern matching engine. Copyright c 1999{2002, 2005, 2008{2021 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, with no Front-Cover Texts, and with no Back-Cover Texts. A copy of the license is included in the section entitled \GNU Free Documentation License". i Table of Contents 1 Introduction ::::::::::::::::::::::::::::::::::::: 1 2 Invoking grep :::::::::::::::::::::::::::::::::::: 2 2.1 Command-line Options ::::::::::::::::::::::::::::::::::::::::: 2 2.1.1 Generic Program Information :::::::::::::::::::::::::::::: 2 2.1.2 Matching Control :::::::::::::::::::::::::::::::::::::::::: 2 2.1.3 General Output Control ::::::::::::::::::::::::::::::::::: 3 2.1.4 Output Line Prefix Control :::::::::::::::::::::::::::::::: 5 2.1.5 Context Line Control :::::::::::::::::::::::::::::::::::::: 6 2.1.6 File and Directory Selection:::::::::::::::::::::::::::::::: 7 2.1.7 Other Options ::::::::::::::::::::::::::::::::::::::::::::: 9 2.2 Environment Variables:::::::::::::::::::::::::::::::::::::::::: 9 2.3 Exit Status :::::::::::::::::::::::::::::::::::::::::::::::::::: 12 2.4 grep Programs :::::::::::::::::::::::::::::::::::::::::::::::: 13 3 Regular Expressions ::::::::::::::::::::::::::: 14 3.1 Fundamental Structure :::::::::::::::::::::::::::::::::::::::: -

HECO-UNIX-Top Cladding Screw Into the Timber
HECO-UNIX -top Cladding Screw THE UNIQUE CLADDING SCREW WITH CONTRACTION EFFECT APPLICATION EXAMPLES Façade construction Secure and reliable façade fixing Louvred façades 1 2 3 The variable pitch of the HECO-UNIX full The smaller thread pitch means that the Gap free axial fixing of the timber board thread takes hold boards are clamped firmly together via the HECO-UNIX full thread PRODUCT CHARACTERISTICS The HECO-UNIX-top Cladding Screw into the timber. The façade is secured axially via with contraction effect the thread, which increases the pull-out strength. HECO-UNIX-top full thread This results in fewer fastening points and an Timber façades are becoming increasingly popular ultimately more economical façade construction. Contraction effect thanks to the full in both new builds and renovations. This applica - Thanks to the full thread, the sole function of thread with variable thread pitch tion places high demands on fastenings. The the head is to fit the screw drive. As such, the Axial fixing of component façade must be securely fixed to the sub-structure HECO-UNIX-top façade screw has a small and the fixings should be invisible or attractive raised head, which allows simple, concealed Reduced spreading effect thanks to to look at. In addition, the structure must be installation preventing any water penetration the HECO-TOPIX ® tip permanently sound if it is constantly exposed to through the screw. The screws are made of the weather. The HECO-UNIX-top façade screw stainless steel A2, which safely eliminates the Raised countersunk head is the perfect solution to all of these requirements. -

Chapter 19 RECOVERING DIGITAL EVIDENCE from LINUX SYSTEMS
Chapter 19 RECOVERING DIGITAL EVIDENCE FROM LINUX SYSTEMS Philip Craiger Abstract As Linux-kernel-based operating systems proliferate there will be an in evitable increase in Linux systems that law enforcement agents must process in criminal investigations. The skills and expertise required to recover evidence from Microsoft-Windows-based systems do not neces sarily translate to Linux systems. This paper discusses digital forensic procedures for recovering evidence from Linux systems. In particular, it presents methods for identifying and recovering deleted files from disk and volatile memory, identifying notable and Trojan files, finding hidden files, and finding files with renamed extensions. All the procedures are accomplished using Linux command line utilities and require no special or commercial tools. Keywords: Digital evidence, Linux system forensics !• Introduction Linux systems will be increasingly encountered at crime scenes as Linux increases in popularity, particularly as the OS of choice for servers. The skills and expertise required to recover evidence from a Microsoft- Windows-based system, however, do not necessarily translate to the same tasks on a Linux system. For instance, the Microsoft NTFS, FAT, and Linux EXT2/3 file systems work differently enough that under standing one tells httle about how the other functions. In this paper we demonstrate digital forensics procedures for Linux systems using Linux command line utilities. The ability to gather evidence from a running system is particularly important as evidence in RAM may be lost if a forensics first responder does not prioritize the collection of live evidence. The forensic procedures discussed include methods for identifying and recovering deleted files from RAM and magnetic media, identifying no- 234 ADVANCES IN DIGITAL FORENSICS tables files and Trojans, and finding hidden files and renamed files (files with renamed extensions. -

Clostridium Difficile (C. Diff)
Living with C. diff Learning how to control the spread of Clostridium difficile (C. diff) This can be serious, I need to do something about this now! IMPORTANT C. diff can be a serious condition. If you or someone in your family has been diagnosed with C. diff, there are steps you can take now to avoid spreading it to your family and friends. This booklet was developed to help you understand and manage C. diff. Follow the recommendations and practice good hygiene to take care of yourself. C. diff may cause physical pain and emotional stress, but keep in mind that it can be treated. For more information on your C.diff infection, please contact your healthcare provider. i CONTENTS Learning about C. diff What is Clostridium difficile (C. diff)? ........................................................ 1 There are two types of C.diff conditions .................................................... 2 What causes a C. diff infection? ............................................................... 2 Who is most at risk to get C. diff? ............................................................ 3 How do I know if I have C. diff infection? .................................................. 3 How does C. diff spread from one person to another? ............................... 4 What if I have C. diff while I am in a healthcare facility? ............................. 5 If I get C. diff, will I always have it? ........................................................... 6 Treatment How is C. diff treated? ............................................................................. 7 Prevention How can the spread of C. diff be prevented in healthcare facilities? ............ 8 How can I prevent spreading C. diff (and other germs) to others at home? .. 9 What is good hand hygiene? .................................................................... 9 What is the proper way to wash my hands? ............................................ 10 What is the proper way to clean? .........................................................