Mouse Carf Knockout Project (CRISPR/Cas9)
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Curcumin Alters Gene Expression-Associated DNA Damage, Cell Cycle, Cell Survival and Cell Migration and Invasion in NCI-H460 Human Lung Cancer Cells in Vitro
ONCOLOGY REPORTS 34: 1853-1874, 2015 Curcumin alters gene expression-associated DNA damage, cell cycle, cell survival and cell migration and invasion in NCI-H460 human lung cancer cells in vitro I-TSANG CHIANG1,2, WEI-SHU WANG3, HSIN-CHUNG LIU4, SU-TSO YANG5, NOU-YING TANG6 and JING-GUNG CHUNG4,7 1Department of Radiation Oncology, National Yang‑Ming University Hospital, Yilan 260; 2Department of Radiological Technology, Central Taiwan University of Science and Technology, Taichung 40601; 3Department of Internal Medicine, National Yang‑Ming University Hospital, Yilan 260; 4Department of Biological Science and Technology, China Medical University, Taichung 404; 5Department of Radiology, China Medical University Hospital, Taichung 404; 6Graduate Institute of Chinese Medicine, China Medical University, Taichung 404; 7Department of Biotechnology, Asia University, Taichung 404, Taiwan, R.O.C. Received March 31, 2015; Accepted June 26, 2015 DOI: 10.3892/or.2015.4159 Abstract. Lung cancer is the most common cause of cancer CARD6, ID1 and ID2 genes, associated with cell survival and mortality and new cases are on the increase worldwide. the BRMS1L, associated with cell migration and invasion. However, the treatment of lung cancer remains unsatisfactory. Additionally, 59 downregulated genes exhibited a >4-fold Curcumin has been shown to induce cell death in many human change, including the DDIT3 gene, associated with DNA cancer cells, including human lung cancer cells. However, the damage; while 97 genes had a >3- to 4-fold change including the effects of curcumin on genetic mechanisms associated with DDIT4 gene, associated with DNA damage; the CCPG1 gene, these actions remain unclear. Curcumin (2 µM) was added associated with cell cycle and 321 genes with a >2- to 3-fold to NCI-H460 human lung cancer cells and the cells were including the GADD45A and CGREF1 genes, associated with incubated for 24 h. -

Cerebral Small Vessel Disease Genomics and Its Implications Across the Lifespan Muralidharan Sargurupremraj, Hideaki Suzuki, Xueqiu Jian, Chloé Sarnowski, Tavia E
Cerebral small vessel disease genomics and its implications across the lifespan Muralidharan Sargurupremraj, Hideaki Suzuki, Xueqiu Jian, Chloé Sarnowski, Tavia E. Evans, Joshua C Bis, Gudny Eiriksdottir, Saori Sakaue, Natalie Terzikhan, Mohamad Habes, et al. To cite this version: Muralidharan Sargurupremraj, Hideaki Suzuki, Xueqiu Jian, Chloé Sarnowski, Tavia E. Evans, et al.. Cerebral small vessel disease genomics and its implications across the lifespan. Nature Communica- tions, Nature Publishing Group, 2020, 11, 10.1038/s41467-020-19111-2. hal-03121357 HAL Id: hal-03121357 https://hal.archives-ouvertes.fr/hal-03121357 Submitted on 26 Jan 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License ARTICLE https://doi.org/10.1038/s41467-020-19111-2 OPEN Cerebral small vessel disease genomics and its implications across the lifespan Muralidharan Sargurupremraj et al.# White matter hyperintensities (WMH) are the most common brain-imaging feature of cer- ebral small vessel disease (SVD), hypertension being the main known risk factor. Here, we identify 27 genome-wide loci for WMH-volume in a cohort of 50,970 older individuals, fi 1234567890():,; accounting for modi cation/confounding by hypertension. -

Biomedical Robots. Application to Translational Medicine
Biomedical robots. Application to translational medicine. Enrique J. deAndrés-Galiana Supervisors: Prof. Juan Luis Fernández-Martínez & Prof. Oscar Luaces This dissertation is submitted under the PhD program of Mathematics and Statistics May 2016 RESUMEN DEL CONTENIDO DE TESIS DOCTORAL 1.- Título de la Tesis Español/Otro Idioma: Inglés: Diseño de robots biomédicos. Aplicaciones en Biomedical robots. Application to translational medicina traslacional. medicine. 2.- Autor Nombre: Enrique Juan de Andrés Galiana DNI/Pasaporte/NIE: Programa de Doctorado: Matemáticas y Estadística. Órgano responsable: Departamento de Matemáticas. RESUMEN (en español) Esta tesis trata sobre el análisis y diseño de robots biomédicos y su aplicación a la medicina traslacional. Se define un robot biomédico como el conjunto de técnicas provenientes de la matemática aplicada, estadística y ciencias de la computación capaces de analizar datos biomédicos de alta dimensionalidad, aprender dinámicamente de dichos datos, extraer nuevo BIS - conocimiento e hipótesis de trabajo, y finalmente realizar predicciones con su incertidumbre asociada, cara a la toma de decisiones biomédicas. Se diseñan y analizan diferentes algorit- 010 - mos de aprendizaje, de reducción de la dimensión y selección de atributos, así como técnicas de optimización global, técnicas de agrupamiento no supervisado, clasificación y análisis de VOA incertidumbre. Dichas metodologías se aplican a datos a pie de hospital y de expresión génica - en predicción de fenotipos para optimización del diagnóstico, pronóstico, tratamiento y análisis de toxicidades. MAT - Se muestra que es posible establecer de modo sencillo el poder discriminatorio de las variables FOR pronóstico, y que dichos problemas de clasificación se aproximan a un comportamiento linealmente separable cuando se reduce la dimensión al conjunto de variables principales que definen el alfabeto del problema biomédico y están por tanto relacionadas con su génesis. -

Assessment of Network Module Identification Across Complex Diseases
ANALYSIS https://doi.org/10.1038/s41592-019-0509-5 Assessment of network module identification across complex diseases Sarvenaz Choobdar1,2,20, Mehmet E. Ahsen3,117, Jake Crawford4,117, Mattia Tomasoni 1,2, Tao Fang5, David Lamparter1,2,6, Junyuan Lin7, Benjamin Hescott8, Xiaozhe Hu7, Johnathan Mercer9,10, Ted Natoli11, Rajiv Narayan11, The DREAM Module Identification Challenge Consortium12, Aravind Subramanian11, Jitao D. Zhang 5, Gustavo Stolovitzky 3,13, Zoltán Kutalik2,14, Kasper Lage 9,10,15, Donna K. Slonim 4,16, Julio Saez-Rodriguez 17,18, Lenore J. Cowen4,7, Sven Bergmann 1,2,19,21* and Daniel Marbach 1,2,5,21* Many bioinformatics methods have been proposed for reducing the complexity of large gene or protein networks into relevant subnetworks or modules. Yet, how such methods compare to each other in terms of their ability to identify disease-relevant modules in different types of network remains poorly understood. We launched the ‘Disease Module Identification DREAM Challenge’, an open competition to comprehensively assess module identification methods across diverse protein–protein interaction, signaling, gene co-expression, homology and cancer-gene networks. Predicted network modules were tested for association with complex traits and diseases using a unique collection of 180 genome-wide association studies. Our robust assessment of 75 module identification methods reveals top-performing algorithms, which recover complementary trait- associated modules. We find that most of these modules correspond to core disease-relevant pathways, which often com- prise therapeutic targets. This community challenge establishes biologically interpretable benchmarks, tools and guidelines for molecular network analysis to study human disease biology. omplex diseases involve many genes and molecules that inter- assessed on in silico generated benchmark graphs11. -

Multiclass Analysis of Gene Expression Data the Protein Process
Critical Dynamic Processes in the Pathogenesis of Cancer Multiclass Analysis of Gene Expression Data Robert Stengel March 27, 2006 ! Background ! Small, round, blue-cell tumor example ! Analysis of colon cancer, metastases, and normal tissue presented at the Institute for Advanced Study Putative Paradigm for The Protein Process Microarray Analysis: Expression Level Infers Cell Function & Carcinogenesis ! Up-regulation in tumor cells – Causal input (tumor enhancing gene) – Defensive response (tumor suppressor gene) – Bystander effect – Tissue effect – Artifact ! Down-regulation in tumor cells – Present, but mutated (and, therefore, not detected) – Eliminated or suppressed by tumor growth – Tissue effect – Artifact Models of Gene Microarray Classification Interaction Objectives ! Inhibition and amplification are multigene effects !Class comparison ! Effects of over/underexpression depend on regulatory pathway and sign of interaction – Identify expression profiles (feature sets) for predefined classes !Class prediction – Develop mathematical function/algorithm that predicts class membership for a novel expression profile !Class discovery – Identify new classes, sub-classes, or features related to classification objectives 200 150 Tumor Typical Pairs of Colon Cancer Normal 100 Characteristics of D14657 Microarray Expression Levels 5 0 0 Classification Features -50 (Alon, Notterman, Levine et al, 1999) -20 -10 0 1 0 2 0 3 0 4 0 M94363 ! Samples not well differentiated in individual transcript clusters (overlapping) 250 200 150 Tumor Normal -

Mouse Carf Conditional Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Carf Conditional Knockout Project (CRISPR/Cas9) Objective: To create a Carf conditional knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Carf gene (NCBI Reference Sequence: NM_139150 ; Ensembl: ENSMUSG00000026017 ) is located on Mouse chromosome 1. 15 exons are identified, with the ATG start codon in exon 2 and the TAA stop codon in exon 15 (Transcript: ENSMUST00000187978). Exon 4 will be selected as conditional knockout region (cKO region). Deletion of this region should result in the loss of function of the Mouse Carf gene. To engineer the targeting vector, homologous arms and cKO region will be generated by PCR using BAC clone RP23-85G22 as template. Cas9, gRNA and targeting vector will be co-injected into fertilized eggs for cKO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Mice homozygous for a null allele have aberrant learning and memory. Exon 4 starts from about 14.71% of the coding region. The knockout of Exon 4 will result in frameshift of the gene. The size of intron 3 for 5'-loxP site insertion: 1021 bp, and the size of intron 4 for 3'-loxP site insertion: 15401 bp. The size of effective cKO region: ~561 bp. The cKO region does not have any other known gene. Page 1 of 8 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele gRNA region 5' gRNA region 3' 1 4 5 15 Targeting vector Targeted allele Constitutive KO allele (After Cre recombination) Legends Exon of mouse Carf Homology arm cKO region loxP site Page 2 of 8 https://www.alphaknockout.com Overview of the Dot Plot Window size: 10 bp Forward Reverse Complement Sequence 12 Note: The sequence of homologous arms and cKO region is aligned with itself to determine if there are tandem repeats. -

(12) Patent Application Publication (10) Pub. No.: US 2009/0269772 A1 Califano Et Al
US 20090269772A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2009/0269772 A1 Califano et al. (43) Pub. Date: Oct. 29, 2009 (54) SYSTEMS AND METHODS FOR Publication Classification IDENTIFYING COMBINATIONS OF (51) Int. Cl. COMPOUNDS OF THERAPEUTIC INTEREST CI2O I/68 (2006.01) CI2O 1/02 (2006.01) (76) Inventors: Andrea Califano, New York, NY G06N 5/02 (2006.01) (US); Riccardo Dalla-Favera, New (52) U.S. Cl. ........... 435/6: 435/29: 706/54; 707/E17.014 York, NY (US); Owen A. (57) ABSTRACT O'Connor, New York, NY (US) Systems, methods, and apparatus for searching for a combi nation of compounds of therapeutic interest are provided. Correspondence Address: Cell-based assays are performed, each cell-based assay JONES DAY exposing a different sample of cells to a different compound 222 EAST 41ST ST in a plurality of compounds. From the cell-based assays, a NEW YORK, NY 10017 (US) Subset of the tested compounds is selected. For each respec tive compound in the Subset, a molecular abundance profile from cells exposed to the respective compound is measured. (21) Appl. No.: 12/432,579 Targets of transcription factors and post-translational modu lators of transcription factor activity are inferred from the (22) Filed: Apr. 29, 2009 molecular abundance profile data using information theoretic measures. This data is used to construct an interaction net Related U.S. Application Data work. Variances in edges in the interaction network are used to determine the drug activity profile of compounds in the (60) Provisional application No. 61/048.875, filed on Apr. -

Chronic Low-Level Domoic Acid Exposure Alters Gene Transcription
Aquatic Toxicology 155 (2014) 151–159 Contents lists available at ScienceDirect Aquatic Toxicology j ournal homepage: www.elsevier.com/locate/aquatox Chronic low-level domoic acid exposure alters gene transcription and impairs mitochondrial function in the CNS a b c b Emma M. Hiolski , Preston S. Kendrick , Elizabeth R. Frame , Mark S. Myers , b b b b Theo K. Bammler , Richard P. Beyer , Federico M. Farin , Hui-wen Wilkerson , a b c,∗ Donald R. Smith , David J. Marcinek , Kathi A. Lefebvre a University of California, Santa Cruz, CA 95064, United States b University of Washington, Seattle, WA 98112, United States c NOAA Northwest Fisheries Science Center, Seattle, WA 98112, United States a r a t i b s c l e i n f o t r a c t Article history: Domoic acid is an algal-derived seafood toxin that functions as a glutamate agonist and exerts excitotox- Received 1 April 2014 icity via overstimulation of glutamate receptors (AMPA, NMDA) in the central nervous system (CNS). At Received in revised form 9 June 2014 high (symptomatic) doses, domoic acid is well-known to cause seizures, brain lesions and memory loss; Accepted 13 June 2014 however, a significant knowledge gap exists regarding the health impacts of repeated low-level (asymp- Available online 20 June 2014 tomatic) exposure. Here, we investigated the impacts of low-level repetitive domoic acid exposure on gene transcription and mitochondrial function in the vertebrate CNS using a zebrafish model in order to: Keywords: (1) identify transcriptional biomarkers of exposure; and (2) examine potential pathophysiology that may Domoic acid occur in the absence of overt excitotoxic symptoms. -
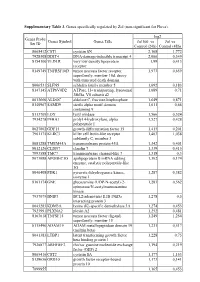
Supplementary Table 3. Genes Specifically Regulated by Zol (Non-Significant for Fluva)
Supplementary Table 3. Genes specifically regulated by Zol (non-significant for Fluva). log2 Genes Probe Genes Symbol Genes Title Zol100 vs Zol vs Set ID Control (24h) Control (48h) 8065412 CST1 cystatin SN 2,168 1,772 7928308 DDIT4 DNA-damage-inducible transcript 4 2,066 0,349 8154100 VLDLR very low density lipoprotein 1,99 0,413 receptor 8149749 TNFRSF10D tumor necrosis factor receptor 1,973 0,659 superfamily, member 10d, decoy with truncated death domain 8006531 SLFN5 schlafen family member 5 1,692 0,183 8147145 ATP6V0D2 ATPase, H+ transporting, lysosomal 1,689 0,71 38kDa, V0 subunit d2 8013660 ALDOC aldolase C, fructose-bisphosphate 1,649 0,871 8140967 SAMD9 sterile alpha motif domain 1,611 0,66 containing 9 8113709 LOX lysyl oxidase 1,566 0,524 7934278 P4HA1 prolyl 4-hydroxylase, alpha 1,527 0,428 polypeptide I 8027002 GDF15 growth differentiation factor 15 1,415 0,201 7961175 KLRC3 killer cell lectin-like receptor 1,403 1,038 subfamily C, member 3 8081288 TMEM45A transmembrane protein 45A 1,342 0,401 8012126 CLDN7 claudin 7 1,339 0,415 7993588 TMC7 transmembrane channel-like 7 1,318 0,3 8073088 APOBEC3G apolipoprotein B mRNA editing 1,302 0,174 enzyme, catalytic polypeptide-like 3G 8046408 PDK1 pyruvate dehydrogenase kinase, 1,287 0,382 isozyme 1 8161174 GNE glucosamine (UDP-N-acetyl)-2- 1,283 0,562 epimerase/N-acetylmannosamine kinase 7937079 BNIP3 BCL2/adenovirus E1B 19kDa 1,278 0,5 interacting protein 3 8043283 KDM3A lysine (K)-specific demethylase 3A 1,274 0,453 7923991 PLXNA2 plexin A2 1,252 0,481 8163618 TNFSF15 tumor necrosis -

ALS2CR8 Rabbit Pab Antibody
ALS2CR8 rabbit pAb antibody Catalog No : Source: Concentration : Mol.Wt. (Da): A10526 Rabbit 1 mg/ml 80698 Applications WB,IHC,ELISA Reactivity Human Dilution WB: 1:500 - 1:2000. IHC: 1:100 - 1:300. ELISA: 1:40000. Not yet tested in other applications. Storage -20°C/1 year Specificity ALS2CR8 Polyclonal Antibody detects endogenous levels of ALS2CR8 protein. Source / Purification The antibody was affinity-purified from rabbit antiserum by affinity- chromatography using epitope-specific immunogen. Immunogen The antiserum was produced against synthesized peptide derived from human ALS2CR8. AA range:311-360 Uniprot No Q8N187 Alternative names ALS2CR8; CARF; Amyotrophic lateral sclerosis 2 chromosomal region candidate gene 8 protein; Calcium-response factor; CaRF; Testis development protein NYD-SP24 Form Liquid in PBS containing 50% glycerol, 0.5% BSA and 0.02% sodium azide. Clonality Polyclonal Isotype IgG Conjugation Background function:May be a transcription factor., Other ALS2CR8, Amyotrophic lateral sclerosis 2 chromosomal region candidate gene 8 protein Produtc Images: Application Key: WB-Western IP-Immunoprecipitation IHC-Immunohistochemistry ChIP-Chromatin Immunoprecipitation IF-Immunofluorescence F-Flow Cytometry E-P-ELISA-Peptide A AAB Biosciences Products www.aabsci.cn FOR RESEARCH USE ONLY. NOT FOR HUMAN OR DIAGNOSTIC USE. Species Cross-Reactivity Key: H-Human M-Mouse R-Rat Hm-Hamster Mk-Monkey Vir-Virus Mi-Mink C-Chicken Dm-D. melanogaster X-Xenopus Z-Zebrafish B-Bovine Dg-Dog Pg-Pig Sc-S. cerevisiae Ce-C. elegans Hr-Horse All-All Species Expected Trademarks All product names and trademarks are the property of their respective owners. Regulatory Disclaimer For life science research only. -

Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations Fall 2010 Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress Renuka Nayak University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Computational Biology Commons, and the Genomics Commons Recommended Citation Nayak, Renuka, "Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress" (2010). Publicly Accessible Penn Dissertations. 1559. https://repository.upenn.edu/edissertations/1559 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/1559 For more information, please contact [email protected]. Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress Abstract Genes interact in networks to orchestrate cellular processes. Here, we used coexpression networks based on natural variation in gene expression to study the functions and interactions of human genes. We asked how these networks change in response to stress. First, we studied human coexpression networks at baseline. We constructed networks by identifying correlations in expression levels of 8.9 million gene pairs in immortalized B cells from 295 individuals comprising three independent samples. The resulting networks allowed us to infer interactions between biological processes. We used the network to predict the functions of poorly-characterized human genes, and provided some experimental support. Examining genes implicated in disease, we found that IFIH1, a diabetes susceptibility gene, interacts with YES1, which affects glucose transport. Genes predisposing to the same diseases are clustered non-randomly in the network, suggesting that the network may be used to identify candidate genes that influence disease susceptibility. -

1 Novel Expression Signatures Identified by Transcriptional Analysis
ARD Online First, published on October 8, 2009 as 10.1136/ard.2009.108043 Ann Rheum Dis: first published as 10.1136/ard.2009.108043 on 7 October 2009. Downloaded from Novel expression signatures identified by transcriptional analysis of separated leukocyte subsets in SLE and vasculitis 1Paul A Lyons, 1Eoin F McKinney, 1Tim F Rayner, 1Alexander Hatton, 1Hayley B Woffendin, 1Maria Koukoulaki, 2Thomas C Freeman, 1David RW Jayne, 1Afzal N Chaudhry, and 1Kenneth GC Smith. 1Cambridge Institute for Medical Research and Department of Medicine, Addenbrooke’s Hospital, Hills Road, Cambridge, CB2 0XY, UK 2Roslin Institute, University of Edinburgh, Roslin, Midlothian, EH25 9PS, UK Correspondence should be addressed to Dr Paul Lyons or Prof Kenneth Smith, Department of Medicine, Cambridge Institute for Medical Research, Addenbrooke’s Hospital, Hills Road, Cambridge, CB2 0XY, UK. Telephone: +44 1223 762642, Fax: +44 1223 762640, E-mail: [email protected] or [email protected] Key words: Gene expression, autoimmune disease, SLE, vasculitis Word count: 2,906 The Corresponding Author has the right to grant on behalf of all authors and does grant on behalf of all authors, an exclusive licence (or non-exclusive for government employees) on a worldwide basis to the BMJ Publishing Group Ltd and its Licensees to permit this article (if accepted) to be published in Annals of the Rheumatic Diseases and any other BMJPGL products to exploit all subsidiary rights, as set out in their licence (http://ard.bmj.com/ifora/licence.pdf). http://ard.bmj.com/ on October 2, 2021 by guest. Protected copyright. 1 Copyright Article author (or their employer) 2009.