Strategies for Managing Timbre and Interaction in Automatic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MB1 Easy Touch-Style Bassics 20070929
Easy Touch-Style Bassics The Rapid Route to ‘Rhythm Bass’ and more ASDFASDF FDSAFDSA An original method for rapid learning of two-handed tapping on electric bass guitar*1 and megatar*2-type instruments by Henri DuPont and Traktor Topaz _____________________________________________________________ MOBIUS MEGATAR, LTD. *1 electric bass guitar must have six to eight strings to effectively utilize the method of play presented in this instructional book. *2 megatar, noun An instrument designed for two-handed touch-style play with one group of strings for bass and another group of strings for melody. page 2 Easy Touch-Style Bassics Mobius Megatar, Ltd. USA Contact: Mobius Megatar USA Post Office Box 989 Mount Shasta, CA 96067 (530) 926-1961 www.megatar.com ______________________________________ First Published in USA by Mobius Megatar USA 1999 Copyright 1999 by Action Marketing, Carson City Nevada, on behalf of Mobius Megatar, Ltd. All rights reserved. PUBLISHER’S NOTE: This publication is designed to provide an easy and accessible method for playing the ‘touch-style’ or ‘two-handed tapping’ method on amplified electric fretted instruments such as guitar or bass or the ‘megatar’ type instruments which have two groups of strings on one fretboard. This method is designed specifically for instruments which have eight or more strings, and can only be adapted to instruments with lesser numbers of strings by means of diligent effort on the part of the student. This method is provided ‘as-is’ and is believed to be a reliable method providing musical results in typical musicians, and providing compara- tively rapid advancement in mastering useful and musical technique. -

Bass Talk Multi String Bass Master GARRY GOODMAN
Bass Talk 9 Jan, 06 > 15 Jan, 06 2 Jan, 06 > 8 Jan, 06 03/01/2006 Entries by Topic All topics « Multi String Bass Master GARRY GOODMAN Control Panel I remember when I saw my first multi string bass. It was back in 1984 at a Edit your Blog Guitar Center here in Chicago. It was a Alembic 6 string. I remember taking it Build a Blog off the wall, sitting with it thinking “how in the hell do you play this thing. 14 View other Blogs years later I find myself sitting in my living room with a 6 string Ibanez saying View Profile the same thing. After climbing that mountain I decide to go back to the 4 string. I guess that’s were my heart is. Bass Links Kenn Smith Website But there are others who have DR Strings taking the multi string bass to ActiveBass.com great heights. Great players National Guitar such as Anthony Jackson, Bill Workshop Dickens and this months interviewee, Garry Goodman. Check it out! Alphonso Johnson Garry began playing bass in Carl Carter 1964 at the age of nine. He Conklin Guitar and became a full-time Basses professional bassist in the Victor Wooton 1970's. His venture in to multi Marcus Miller string instruments started in 1975 with the Chapman Stick You are not logged in. and later in 1978 he which to Log in a 7-string bass. Currently Garry plays a Tobias 7-string, Warrior 9- string and Adler 11-string bass and has developed a unique playing technique called “Percussive Harmonics”, expanding the tonal possibilities of modern electric bass. -

Downbeat.Com July 2015 U.K. £4.00
JULY 2015 2015 JULY U.K. £4.00 DOWNBEAT.COM DOWNBEAT ANTONIO SANCHEZ • KIRK WHALUM • JOHN PATITUCCI • HAROLD MABERN JULY 2015 JULY 2015 VOLUME 82 / NUMBER 7 President Kevin Maher Publisher Frank Alkyer Editor Bobby Reed Associate Editor Brian Zimmerman Contributing Editor Ed Enright Art Director LoriAnne Nelson Contributing Designer ĺDQHWDÎXQWRY£ Circulation Manager Kevin R. Maher Assistant to the Publisher Sue Mahal Bookkeeper Evelyn Oakes Bookkeeper Emeritus Margaret Stevens Editorial Assistant Stephen Hall ADVERTISING SALES Record Companies & Schools Jennifer Ruban-Gentile 630-941-2030 [email protected] Musical Instruments & East Coast Schools Ritche Deraney 201-445-6260 [email protected] Classified Advertising Sales Pete Fenech 630-941-2030 [email protected] OFFICES 102 N. Haven Road, Elmhurst, IL 60126–2970 630-941-2030 / Fax: 630-941-3210 http://downbeat.com [email protected] CUSTOMER SERVICE 877-904-5299 / [email protected] CONTRIBUTORS Senior Contributors: Michael Bourne, Aaron Cohen, Howard Mandel, John McDonough Atlanta: Jon Ross; Austin: Kevin Whitehead; Boston: Fred Bouchard, Frank- John Hadley; Chicago: John Corbett, Alain Drouot, Michael Jackson, Peter Margasak, Bill Meyer, Mitch Myers, Paul Natkin, Howard Reich; Denver: Norman Provizer; Indiana: Mark Sheldon; Iowa: Will Smith; Los Angeles: Earl Gibson, Todd Jenkins, Kirk Silsbee, Chris Walker, Joe Woodard; Michigan: John Ephland; Minneapolis: Robin James; Nashville: Bob Doerschuk; New Orleans: Erika Goldring, David Kunian, Jennifer Odell; New York: Alan Bergman, -

Appendix I. Search Strategy Ovid MEDLINE(R) and Epub
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) BMJ Open Appendix I. Search Strategy Ovid MEDLINE(R) and Epub Ahead of Print, In-Process & Other Non-Indexed Citations and Daily <1946 to July 12, 2019> Results =12 # Search Statement Results (((music or musical or harp or harps or recorder or recorders or synthesi?er* or tuba or tubas) adj3 (performer* or artist* or player* or student* or teacher* or instructor*)).mp. or ((Musician* or instrumentalist* or accordionist* or bagpiper* or bassist* or bassoonist or cellist* or conguera* or conguero* or drummer* or fiddler* or Flautist* or flutist or harpist* or guitarist* or keyboardist* or keytarist* or organist or organists or percussionist* or pipers or saxaphonist* or trumpeter or trumpeters or tubaist or tubist or vibraphonist* or vibraharpist* or violinist* or (Accordion* or alphorn* or alpenhorn* or alpine horn* or Bagpipe* or Balalaika or (Bandura* not (Bandura* adj4 (self efficacy or theor*))) or Banjo* or Bariton* or Bass guitar* or Bassoon* or Berimbau or Bongo or Bongos or Boom whacker* or boomwhacker* or Bouzouki* or Bugle* or Cello or Cellos or Chapman Stick* or Cimbalom or Clarinet* or Clavichord or Concertina* or (Conga not glycemi*) or Contrabass* or Cor anglais* or Cornet* or Cymbal or Cymbals or Didgeridoo* or Djembe or Double bass* or Drum or Drums or Dulcimer* or Euphoni* or Fiddle or Fiddles or Fifes or Flute or Flutes -

Bass Inside Magazine 2/1/04 2:16 PM
Garry Goodman in Bass Inside Magazine 2/1/04 2:16 PM No 18 February 2004 Garry Goodman Has He Created a Whole New Way of Doing Things? One of the by- products or effects of doing this magazine has had on me this past few years is that I have developed a strong hunger to find people who are actually doing something different, something innovative. Meeting that wish has not been easy. The Slap Technique is on 90% of all CD's we receive. As is the Yngwie Effect, with 6000 notes a minute, and of course the ever popular ‘Look How Very Smokin’ I Am Syndrome’. It is an old argument, stretching back to Paginini and beyond, I am sure. The pursuit for blinding technique and speed has throttled compositional skills. Attention and effort in trying to outplay everybody else, crowded out just plain fine song writing. And then along comes Garry Goodman. Has this gentleman perhaps developed a new way of doing things? Garry has a different way of playing bass that combines left hand tapping with http://www.bassinside.com/2004/february/garry.htm Page 1 of 11 Garry Goodman in Bass Inside Magazine 2/1/04 2:16 PM right hand tapping harmonics in an unsual fashion. The end reslt is different enough to take a serious look. Is the end effect of this technique the next step in the evolution of bass playing? Bass Inside: Would you say there are similarities between the touchstyle method of playing employed by players of the Chapman Stick and what you have developed here with Percussive Harmonics? If not, how is it different and how has it been adapted to the very different layout of the bass in comparison to the Stick itself? Garry: The technique I’ve developed is really nothing like the touch-style I would use on a Chapman Stick. -
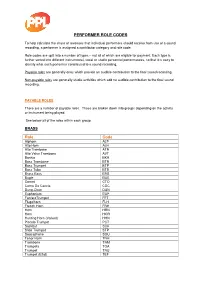
PERFORMER ROLE CODES Role Code
PERFORMER ROLE CODES To help calculate the share of revenues that individual performers should receive from use of a sound recording, a performer is assigned a contributor category and role code. Role codes are split into a number of types – not all of which are eligible for payment. Each type is further sorted into different instrumental, vocal or studio personnel performances, so that it is easy to identify what each performer contributed to a sound recording. Payable roles are generally ones which provide an audible contribution to the final sound recording. Non-payable roles are generally studio activities which add no audible contribution to the final sound recording. PAYABLE ROLES There are a number of payable roles. These are broken down into groups depending on the activity or instrument being played. See below all of the roles within each group. BRASS Role Code Alphorn ALP Alto Horn ALH Alto Trombone ATR Alto Valve Trombone AVT Bankia BKA Bass Trombone BTR Bass Trumpet BTP Bass Tuba BTB Brass Bass BRB Bugle BUE Cornet CTO Corno Da Caccia CDC Dung-Chen DUN Euphonium EUP FanfareTrumpet FFT Flugelhorn FLH French Horn FRH Horn HRN Horn HOR Hunting Horn (Valved) HHN Piccolo Trumpet PCT Sackbut SCK Slide Trumpet STP Sousaphone SOU Tenor Horn TNH Trombone TRM Trompeta TOA Trumpet TRU Trumpet (Eflat) TEF Tuba TUB ValveTrombone VTR ELECTRONICS Role Code Barrel Organ BRO Barrel Piano BPN Beat Box BBX DJ D_J DJ (Scratcher) SCT Emulator EMU Fairground Organ FGO Hurdy Gurdy HUR Musical Box BOX Ondioline OND Optigan OPG Polyphon PPN Programmer -

Introduction Into Playing the 12-String Tap-Guitar Text & Photos: Michael Koch
Introduction into playing the 12-string Tap-Guitar text & photos: Michael Koch Suitable to the tuning in 5ths and 4ths Crossed & Uncrossed EDITORIAL Dear all you musicians with heart and mind, in first line this short introduction into the topic 12-String Tap-Guitar shall support YOU. And it shall clarify you that it doesn't need to be super brilliant or outstanding intelligent to play this kind of guitar. Furthermore it's definitely not harder than play- ing another kind of instrument. Anyone who likes to be better, faster and greater than her/his idols has to practise, practise and practise again. There are even mani- acs who fly across the fingerboard of a ukulele - like Steve Vai on his guitar. But all musicians who are approachable to a wider array and rendition possibilities will find their own universe of amazing and fresh sounds inside the world of the Tap-Guitar. No matter if you play Pop, Rock, Hip-Hop, Funk, Progressive Rock, Metal, Jazz and so on - the instrument is an enrichment to all styles of music. "Just take your time and play the music you like the most!!!“ If this is to your appreciation there will be some people more who like it. This current BiusK feat AF, European Bassday 2010 introduction into playing the Tap-Guitar is to suggest you the playing technique, most significant chords and harmony patterns. It’s possible to listen to the associated tone examples by hearing the bass and melody strings at the same time (stereo) or divid- ed. Both signals had been recorded separately. -

Major Thirds: a Better Way to Tune Your Ipad
Proceedings of the International Conference on New Interfaces for Musical Expression, Baton Rouge, LA, USA, May 31-June 3, 2015 Major Thirds: A Better Way to Tune Your iPad Hans Anderson, Kin Wah Edward Lin, Natalie Agus and Simon Lui Singapore University of Technology and Design 8 Somapah Road Singapore 487372 {hans_anderson, edward_lin, natalie_agus}@mymail.sutd.edu.sg, [email protected] ABSTRACT Major 3rds tuning makes it much easier for the new Many new melodic instruments use a touch sensitive sur- users to learn to play it. In the remaining portion of face with notes arranged in a two-dimensional grid. Most the introduction we will briefly describe some of the related of these arrange notes in chromatic half-steps along the hor- commercially available instruments. In Section 2, we dis- izontal axis and in intervals of 4ths along the vertical axis. cuss the origins of the Major 3rds tuning and explains why Although many alternatives exist, this arrangement, which it is uniquely suited for use on touch-sensitive surfaces. In resembles that of a bass guitar, is quickly becoming the de Section 3, we summarise some key points about the imple- facto standard. In this study we present experimental ev- mentation of our own instrument. In Section 4, we outline idence that grid based instruments are significantly easier our experimental procedure and analyse the results. Fi- to play when we tune adjacent rows in Major 3rds rather nally, we suggest future work related to the study of note than 4ths. We have developed a grid-based instrument as arrangements and of iPad virtual instruments in general. -

Los Angeles Snapshots 1 MUSEUM
1 MUSEUM DIGITAL ARCHIVE NOW DIG THIS! ART & BLACK LOS ANGELES 1960–1980 Los Angeles Snapshots ROBERTO TEJADA 1. [COVER STORY: “SOUTH OF CHU LAI”] “A huge section of Los Angeles was virtually a city on fire,” reported theLos Angeles Times, “as flames from stores, industrial complexes and homes lit the night skies.”1 On August 11, 1965, when “rocks, bricks, and bottles” first erupted at the corner of 116th Street and Avalon Boulevard, and desperation unleashed scenes of uprising in Watts and elsewhere—with firebombs setting storefronts and overturned cars ablaze and law enforcement barricades confining the throng, followed by an escalating storm of tear-gas missiles, mass arrests, and slayings in what the Times at first called a “melee” and later “virtual guerilla warfare”—that day found staff reporter Rubén Salazar en route to his assignment in Vietnam to dispatch from the paper’s Saigon bureau. One of two Mexican Americans at the Times, Salazar found opportunity in Vietnam to remark on the crisis in Los Angeles. (A glaring omission during the Watts rebellion, the newspaper had never hired any African American journalists.) In an August 23 report, Salazar interviewed twenty-nine-year-old Marine Sergeant Harrison Madison, “a Negro formerly of Long Beach,” stationed in Chu Lai, South Vietnam, on the “racial trouble in Los Angeles.” The Marine at first denounces the revolt as unfounded: “Violence is never justified,” he claims, “when peaceful settlement is possible.”2 The wartime irony is not lost on Salazar, who in the same first paragraph describes the sergeant ordering his mortar section “to fire on nearby Viet Cong guerillas.” The rhetorical nuance builds with each paragraph in this brief report from the combat zone. -

An Exploration Into the Chapman Stick and Its Impact on Songwriting and Composition
An exploration into the Chapman stick and its impact on songwriting and composition Christopher Max Jones MA Songwriting Research methodologies and context MD PM7001 Word count 8,245 1 Abstract This research first reviewed the Chapman stick as a hybrid instrument by looking at the connection with four other instruments which are closely related to it. The review made use of a limited amount of literature, the reason being the lack of an extensive amount of material having been written with regard to this instrument. This is a result of the fact that the Chapman stick is relatively new, and so lacks history and tradition. I then extended the knowledge that has been gathered to this date by looking at the impact of the Chapman stick in the areas of songwriting and composition. Once I had ascertained the topics most pertinent, questionnaires and interviews were used in order to explore a small number of areas which formed the spine of my primary research. 2 Table of Contents Abstract ........................................................................................................................... 2 Introduction ..................................................................................................................... 5 Topic review ..................................................................................................................... 6 What is the Chapman stick? ..................................................................................................... 6 Structure of the instrument ..................................................................................................... -

DOWNLOAD the Working Musicians Dictionary of Terms.Pdf
Karl Aranjo is a guy hangin’ out in Southern California, doin’ the guitar thing! A graduate of the prestigious Berklee College of Music in Boston Massachuttes he was a protégé of the great William G. Leavitt, a world renown educator and creator of the Berklee method. Karl has also studied with many of the world's great players and has built a solid career as a performer, arranger, session player, sought after instructor and best selling author of five other guitar books including the highly acclaimed Guitar Buddy, Guitar Chord Guru and Guitar Scale Guru. Karl is a dedicated, experienced and passionate teacher and is the founder of GuitarU.com a distance learning company that takes all the guesswork and endless Google and Youtube searches out of internet guitar study. Musicians and teachers alike can count on GuitarU.com to provide unique, high quality, music school grade courses and lesson materials. GuitarU.com is not only for those who want to seriously study the art of modern guitar playing, but also offers lots of free stuff for a beginner o an experienced player who may want to get their feet wet r with our one of a kind multimedia course work. http://www.guitaru.com To Read Karl’s Music Education and Guitar Life Blog . http://www.karlaranjo.com Email [email protected]. A A-440- 1.) The tuning standard for the free world. This means that the note “A” is tuned to a frequency of 440 cycles per second (Hertz). AABA- 1.) The standard 32 bar song form as perfected in the Irving Berlin song I Got Rhythm. -

Master's Recital in Jazz Pedagogy: a Performance-Demonstration of Rhythm Section Instruments, Compositions and Arrangements by Josh Hakanson
University of Northern Iowa UNI ScholarWorks Dissertations and Theses @ UNI Student Work 2016 Master's recital in jazz pedagogy: A performance-demonstration of rhythm section instruments, compositions and arrangements by Josh Hakanson Josh Hakanson University of Northern Iowa Let us know how access to this document benefits ouy Copyright ©2016 Josh Hakanson Follow this and additional works at: https://scholarworks.uni.edu/etd Part of the Composition Commons, and the Music Pedagogy Commons Recommended Citation Hakanson, Josh, "Master's recital in jazz pedagogy: A performance-demonstration of rhythm section instruments, compositions and arrangements by Josh Hakanson" (2016). Dissertations and Theses @ UNI. 316. https://scholarworks.uni.edu/etd/316 This Open Access Thesis is brought to you for free and open access by the Student Work at UNI ScholarWorks. It has been accepted for inclusion in Dissertations and Theses @ UNI by an authorized administrator of UNI ScholarWorks. For more information, please contact [email protected]. MASTER’S RECITAL IN JAZZ PEDAGOGY: A PERFORMANCE-DEMONSTRATION OF RHYTHM SECTION INSTRUMENTS, COMPOSITIONS AND ARRANGEMENTS BY JOSH HAKANSON An Abstract of a Recital Submitted in Partial Fulfillment of the Requirements of the Degree Master of Music in Jazz Pedagogy Josh Hakanson University of Northern Iowa May 2016 ii APPROVAL PAGE This Recital Abstract by: Josh Hakanson Entitled: Master’s Recital in Jazz Pedagogy: A Performance-Demonstration of Rhythm Section Instruments, Compositions and Arrangements By Josh Hakanson Has been approved as meeting the thesis requirement for the Degree of Master of Music Jazz Pedagogy ___________ _____________________________________________________ Date Christopher Merz, Chair, Thesis Committee ___________ _____________________________________________________ Date Dr.