R Or Python: a Programmer’S Response
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Mastering Machine Learning with Scikit-Learn
www.it-ebooks.info Mastering Machine Learning with scikit-learn Apply effective learning algorithms to real-world problems using scikit-learn Gavin Hackeling BIRMINGHAM - MUMBAI www.it-ebooks.info Mastering Machine Learning with scikit-learn Copyright © 2014 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: October 2014 Production reference: 1221014 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78398-836-5 www.packtpub.com Cover image by Amy-Lee Winfield [email protected]( ) www.it-ebooks.info Credits Author Project Coordinator Gavin Hackeling Danuta Jones Reviewers Proofreaders Fahad Arshad Simran Bhogal Sarah -

The R and Omegahat Projects in Statistical Computing
The R and Omegahat Projects in Statistical Computing Brian D. Ripley [email protected] http://www.stats.ox.ac.uk/∼ripley Outline • Statistical Computing – History – S – R • Application and Comparisons – Web servers – Embedding — Medieval Chant – R vs S-PLUS • Omegahat and Component Systems – The Omegahat project – Components — GGobi – The future? Statistical Computing and S Scene-setting: Statistical Computing 1980 Mainly Fortran programming, or PL/I (SAS). Batch computing (SAS, BMDP, SPSS, Genstat) with restricted range of platforms. Some small interactive systems (GLIM 3.77, Minitab). Very poor interactive graphics (2400 baud to a Tektronix storage tube if you were lucky). Flatbed and drum plotters, microfilm for publication-quality output off-line. Mainly home-brew solutions in research. (GLIM macros?) 1990 PCs become widespread, but FPUs still uncommon. Sun etc workstations available for researchers, and for teaching in a few places. Graphics could be pretty good (postscript printers, ca 1000 × 1000 pixel screens), but often was not, and mono text terminals were still widespread. C was beginning to be used, as more portable than Fortran. (Few PC Fortran compilers then and now.) Still SAS, SPSS etc as batch programs. S beginning to be make an impact on research and teaching. 2001 Little spread in machine speed (min 500MHz, max 1.5GHz), fast FPUs are universal. Colour everywhere, usually 24-bit colour. The video-games generation is now at university. Few people would dream of writing a complete program for a research idea: prototype and distribute in a higher-level language such as S or Matlab or Gauss or Ox or ... -

Supplementary Materials
Tomic et al, SIMON, an automated machine learning system reveals immune signatures of influenza vaccine responses 1 Supplementary Materials: 2 3 Figure S1. Staining profiles and gating scheme of immune cell subsets analyzed using mass 4 cytometry. Representative gating strategy for phenotype analysis of different blood- 5 derived immune cell subsets analyzed using mass cytometry in the sample from one donor 6 acquired before vaccination. In total PBMC from healthy 187 donors were analyzed using 7 same gating scheme. Text above plots indicates parent population, while arrows show 8 gating strategy defining major immune cell subsets (CD4+ T cells, CD8+ T cells, B cells, 9 NK cells, Tregs, NKT cells, etc.). 10 2 11 12 Figure S2. Distribution of high and low responders included in the initial dataset. Distribution 13 of individuals in groups of high (red, n=64) and low (grey, n=123) responders regarding the 14 (A) CMV status, gender and study year. (B) Age distribution between high and low 15 responders. Age is indicated in years. 16 3 17 18 Figure S3. Assays performed across different clinical studies and study years. Data from 5 19 different clinical studies (Study 15, 17, 18, 21 and 29) were included in the analysis. Flow 20 cytometry was performed only in year 2009, in other years phenotype of immune cells was 21 determined by mass cytometry. Luminex (either 51/63-plex) was performed from 2008 to 22 2014. Finally, signaling capacity of immune cells was analyzed by phosphorylation 23 cytometry (PhosphoFlow) on mass cytometer in 2013 and flow cytometer in all other years. -

Installing Python Ø Basics of Programming • Data Types • Functions • List Ø Numpy Library Ø Pandas Library What Is Python?
Python in Data Science Programming Ha Khanh Nguyen Agenda Ø What is Python? Ø The Python Ecosystem • Installing Python Ø Basics of Programming • Data Types • Functions • List Ø NumPy Library Ø Pandas Library What is Python? • “Python is an interpreted high-level general-purpose programming language.” – Wikipedia • It supports multiple programming paradigms, including: • Structured/procedural • Object-oriented • Functional The Python Ecosystem Source: Fabien Maussion’s “Getting started with Python” Workshop Installing Python • Install Python through Anaconda/Miniconda. • This allows you to create and work in Python environments. • You can create multiple environments as needed. • Highly recommended: install Python through Miniconda. • Are we ready to “play” with Python yet? • Almost! • Most data scientists use Python through Jupyter Notebook, a web application that allows you to create a virtual notebook containing both text and code! • Python Installation tutorial: [Mac OS X] [Windows] For today’s seminar • Due to the time limitation, we will be using Google Colab instead. • Google Colab is a free Jupyter notebook environment that runs entirely in the cloud, so you can run Python code, write report in Jupyter Notebook even without installing the Python ecosystem. • It is NOT a complete alternative to installing Python on your local computer. • But it is a quick and easy way to get started/try out Python. • You will need to log in using your university account (possible for some schools) or your personal Google account. Basics of Programming Indentations – Not Braces • Other languages (R, C++, Java, etc.) use braces to structure code. # R code (not Python) a = 10 if (a < 5) { result = TRUE b = 0 } else { result = FALSE b = 100 } a = 10 if (a < 5) { result = TRUE; b = 0} else {result = FALSE; b = 100} Basics of Programming Indentations – Not Braces • Python uses whitespaces (tabs or spaces) to structure code instead. -

The Split-Apply-Combine Strategy for Data Analysis
JSS Journal of Statistical Software April 2011, Volume 40, Issue 1. http://www.jstatsoft.org/ The Split-Apply-Combine Strategy for Data Analysis Hadley Wickham Rice University Abstract Many data analysis problems involve the application of a split-apply-combine strategy, where you break up a big problem into manageable pieces, operate on each piece inde- pendently and then put all the pieces back together. This insight gives rise to a new R package that allows you to smoothly apply this strategy, without having to worry about the type of structure in which your data is stored. The paper includes two case studies showing how these insights make it easier to work with batting records for veteran baseball players and a large 3d array of spatio-temporal ozone measurements. Keywords: R, apply, split, data analysis. 1. Introduction What do we do when we analyze data? What are common actions and what are common mistakes? Given the importance of this activity in statistics, there is remarkably little research on how data analysis happens. This paper attempts to remedy a very small part of that lack by describing one common data analysis pattern: Split-apply-combine. You see the split-apply- combine strategy whenever you break up a big problem into manageable pieces, operate on each piece independently and then put all the pieces back together. This crops up in all stages of an analysis: During data preparation, when performing group-wise ranking, standardization, or nor- malization, or in general when creating new variables that are most easily calculated on a per-group basis. -

Hadley Wickham, the Man Who Revolutionized R Hadley Wickham, the Man Who Revolutionized R · 51,321 Views · More Stats
12/15/2017 Hadley Wickham, the Man Who Revolutionized R Hadley Wickham, the Man Who Revolutionized R · 51,321 views · More stats Share https://priceonomics.com/hadley-wickham-the-man-who-revolutionized-r/ 1/10 12/15/2017 Hadley Wickham, the Man Who Revolutionized R “Fundamentally learning about the world through data is really, really cool.” ~ Hadley Wickham, prolific R developer *** If you don’t spend much of your time coding in the open-source statistical programming language R, his name is likely not familiar to you -- but the statistician Hadley Wickham is, in his own words, “nerd famous.” The kind of famous where people at statistics conferences line up for selfies, ask him for autographs, and are generally in awe of him. “It’s utterly utterly bizarre,” he admits. “To be famous for writing R programs? It’s just crazy.” Wickham earned his renown as the preeminent developer of packages for R, a programming language developed for data analysis. Packages are programming tools that simplify the code necessary to complete common tasks such as aggregating and plotting data. He has helped millions of people become more efficient at their jobs -- something for which they are often grateful, and sometimes rapturous. The packages he has developed are used by tech behemoths like Google, Facebook and Twitter, journalism heavyweights like the New York Times and FiveThirtyEight, and government agencies like the Food and Drug Administration (FDA) and Drug Enforcement Administration (DEA). Truly, he is a giant among data nerds. *** Born in Hamilton, New Zealand, statistics is the Wickham family business: His father, Brian Wickham, did his PhD in the statistics heavy discipline of Animal Breeding at Cornell University and his sister has a PhD in Statistics from UC Berkeley. -
Cheat Sheet Pandas Python.Indd
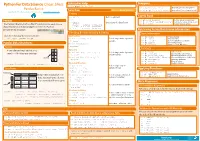
Python For Data Science Cheat Sheet Asking For Help Dropping >>> help(pd.Series.loc) Pandas Basics >>> s.drop(['a', 'c']) Drop values from rows (axis=0) Selection Also see NumPy Arrays >>> df.drop('Country', axis=1) Drop values from columns(axis=1) Learn Python for Data Science Interactively at www.DataCamp.com Getting Sort & Rank >>> s['b'] Get one element -5 Pandas >>> df.sort_index() Sort by labels along an axis Get subset of a DataFrame >>> df.sort_values(by='Country') Sort by the values along an axis The Pandas library is built on NumPy and provides easy-to-use >>> df[1:] Assign ranks to entries Country Capital Population >>> df.rank() data structures and data analysis tools for the Python 1 India New Delhi 1303171035 programming language. 2 Brazil Brasília 207847528 Retrieving Series/DataFrame Information Selecting, Boolean Indexing & Setting Basic Information Use the following import convention: By Position (rows,columns) Select single value by row & >>> df.shape >>> import pandas as pd >>> df.iloc[[0],[0]] >>> df.index Describe index Describe DataFrame columns 'Belgium' column >>> df.columns Pandas Data Structures >>> df.info() Info on DataFrame >>> df.iat([0],[0]) Number of non-NA values >>> df.count() Series 'Belgium' Summary A one-dimensional labeled array a 3 By Label Select single value by row & >>> df.sum() Sum of values capable of holding any data type b -5 >>> df.loc[[0], ['Country']] Cummulative sum of values 'Belgium' column labels >>> df.cumsum() >>> df.min()/df.max() Minimum/maximum values c 7 Minimum/Maximum index -
![R Generation [1] 25](https://docslib.b-cdn.net/cover/5865/r-generation-1-25-805865.webp)
R Generation [1] 25
IN DETAIL > y <- 25 > y R generation [1] 25 14 SIGNIFICANCE August 2018 The story of a statistical programming they shared an interest in what Ihaka calls “playing academic fun language that became a subcultural and games” with statistical computing languages. phenomenon. By Nick Thieme Each had questions about programming languages they wanted to answer. In particular, both Ihaka and Gentleman shared a common knowledge of the language called eyond the age of 5, very few people would profess “Scheme”, and both found the language useful in a variety to have a favourite letter. But if you have ever been of ways. Scheme, however, was unwieldy to type and lacked to a statistics or data science conference, you may desired functionality. Again, convenience brought good have seen more than a few grown adults wearing fortune. Each was familiar with another language, called “S”, Bbadges or stickers with the phrase “I love R!”. and S provided the kind of syntax they wanted. With no blend To these proud badge-wearers, R is much more than the of the two languages commercially available, Gentleman eighteenth letter of the modern English alphabet. The R suggested building something themselves. they love is a programming language that provides a robust Around that time, the University of Auckland needed environment for tabulating, analysing and visualising data, one a programming language to use in its undergraduate statistics powered by a community of millions of users collaborating courses as the school’s current tool had reached the end of its in ways large and small to make statistical computing more useful life. -

Pandas: Powerful Python Data Analysis Toolkit Release 0.25.3
pandas: powerful Python data analysis toolkit Release 0.25.3 Wes McKinney& PyData Development Team Nov 02, 2019 CONTENTS i ii pandas: powerful Python data analysis toolkit, Release 0.25.3 Date: Nov 02, 2019 Version: 0.25.3 Download documentation: PDF Version | Zipped HTML Useful links: Binary Installers | Source Repository | Issues & Ideas | Q&A Support | Mailing List pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language. See the overview for more detail about whats in the library. CONTENTS 1 pandas: powerful Python data analysis toolkit, Release 0.25.3 2 CONTENTS CHAPTER ONE WHATS NEW IN 0.25.2 (OCTOBER 15, 2019) These are the changes in pandas 0.25.2. See release for a full changelog including other versions of pandas. Note: Pandas 0.25.2 adds compatibility for Python 3.8 (GH28147). 1.1 Bug fixes 1.1.1 Indexing • Fix regression in DataFrame.reindex() not following the limit argument (GH28631). • Fix regression in RangeIndex.get_indexer() for decreasing RangeIndex where target values may be improperly identified as missing/present (GH28678) 1.1.2 I/O • Fix regression in notebook display where <th> tags were missing for DataFrame.index values (GH28204). • Regression in to_csv() where writing a Series or DataFrame indexed by an IntervalIndex would incorrectly raise a TypeError (GH28210) • Fix to_csv() with ExtensionArray with list-like values (GH28840). 1.1.3 Groupby/resample/rolling • Bug incorrectly raising an IndexError when passing a list of quantiles to pandas.core.groupby. DataFrameGroupBy.quantile() (GH28113). -

Statistics with Free and Open-Source Software
Free and Open-Source Software • the four essential freedoms according to the FSF: • to run the program as you wish, for any purpose • to study how the program works, and change it so it does Statistics with Free and your computing as you wish Open-Source Software • to redistribute copies so you can help your neighbor • to distribute copies of your modified versions to others • access to the source code is a precondition for this Wolfgang Viechtbauer • think of ‘free’ as in ‘free speech’, not as in ‘free beer’ Maastricht University http://www.wvbauer.com • maybe the better term is: ‘libre’ 1 2 General Purpose Statistical Software Popularity of Statistical Software • proprietary (the big ones): SPSS, SAS/JMP, • difficult to define/measure (job ads, articles, Stata, Statistica, Minitab, MATLAB, Excel, … books, blogs/posts, surveys, forum activity, …) • FOSS (a selection): R, Python (NumPy/SciPy, • maybe the most comprehensive comparison: statsmodels, pandas, …), PSPP, SOFA, Octave, http://r4stats.com/articles/popularity/ LibreOffice Calc, Julia, … • for programming languages in general: TIOBE Index, PYPL, GitHut, Language Popularity Index, RedMonk Rankings, IEEE Spectrum, … • note that users of certain software may be are heavily biased in their opinion 3 4 5 6 1 7 8 What is R? History of S and R • R is a system for data manipulation, statistical • … it began May 5, 1976 at: and numerical analysis, and graphical display • simply put: a statistical programming language • freely available under the GNU General Public License (GPL) → open-source -

A History of R (In 15 Minutes… and Mostly in Pictures)
A history of R (in 15 minutes… and mostly in pictures) JULY 23, 2020 Andrew Zief!ler Lunch & Learn Department of Educational Psychology RMCC University of Minnesota LATIS Who am I and Some Caveats Andy Zie!ler • I teach statistics courses in the Department of Educational Psychology • I have been using R since 2005, when I couldn’t put Me (on the EPSY faculty board) SAS on my computer (it didn’t run natively on a Me Mac), and even if I could have gotten it to run, I (everywhere else) couldn’t afford it. Some caveats • Although I was alive during much of the era I will be talking about, I was not working as a statistician at that time (not even as an elementary student for some of it). • My knowledge is second-hand, from other people and sources. Statistical Computing in the 1970s Bell Labs In 1976, scientists from the Statistics Research Group were actively discussing how to design a language for statistical computing that allowed interactive access to routines in their FORTRAN library. John Chambers John Tukey Home to Statistics Research Group Rick Becker Jean Mc Rae Judy Schilling Doug Dunn Introducing…`S` An Interactive Language for Data Analysis and Graphics Chambers sketch of the interface made on May 5, 1976. The GE-635, a 36-bit system that ran at a 0.5MIPS, starting at $2M in 1964 dollars or leasing at $45K/month. ’S’ was introduced to Bell Labs in November, but at the time it did not actually have a name. The Impact of UNIX on ’S' Tom London Ken Thompson and Dennis Ritchie, creators of John Reiser the UNIX operating system at a PDP-11. -

Changes on CRAN 2014-07-01 to 2014-12-31
NEWS AND NOTES 192 Changes on CRAN 2014-07-01 to 2014-12-31 by Kurt Hornik and Achim Zeileis New packages in CRAN task views Bayesian BayesTree. Cluster fclust, funFEM, funHDDC, pgmm, tclust. Distributions FatTailsR, RTDE, STAR, predfinitepop, statmod. Econometrics LinRegInteractive, MSBVAR, nonnest2, phtt. Environmetrics siplab. Finance GCPM, MSBVAR, OptionPricing, financial, fractal, riskSimul. HighPerformanceComputing GUIProfiler, PGICA, aprof. MachineLearning BayesTree, LogicForest, hdi, mlr, randomForestSRC, stabs, vcrpart. MetaAnalysis MAVIS, ecoreg, ipdmeta, metaplus. NumericalMathematics RootsExtremaInflections, Rserve, SimplicialCubature, fastGHQuad, optR. OfficialStatistics CoImp, RecordLinkage, rworldmap, tmap, vardpoor. Optimization RCEIM, blowtorch, globalOptTests, irace, isotone, lbfgs. Phylogenetics BAMMtools, BoSSA, DiscML, HyPhy, MPSEM, OutbreakTools, PBD, PCPS, PHYLOGR, RADami, RNeXML, Reol, Rphylip, adhoc, betapart, dendextend, ex- pands, expoTree, jaatha, kdetrees, mvMORPH, outbreaker, pastis, pegas, phyloTop, phyloland, rdryad, rphast, strap, surface, taxize. Psychometrics IRTShiny, PP, WrightMap, mirtCAT, pairwise. ReproducibleResearch NMOF. Robust TEEReg, WRS2, robeth, robustDA, robustgam, robustloggamma, robustreg, ror, rorutadis. Spatial PReMiuM. SpatioTemporal BayesianAnimalTracker, TrackReconstruction, fishmove, mkde, wildlifeDI. Survival DStree, ICsurv, IDPSurvival, MIICD, MST, MicSim, PHeval, PReMiuM, aft- gee, bshazard, bujar, coxinterval, gamboostMSM, imputeYn, invGauss, lsmeans, multipleNCC, paf, penMSM, spBayesSurv,