Live Distributed Objects
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Vol. 47, No. 2 June 2018 a New Star Appears in Europe Page 14 Journal
Online PDF: ISSN 233333-9063 Vol. 47, No. 2 June 2018 Journal of the International Planetarium Society A New Star Appears in Europe Page 14 Reach for the stars... and beyond. ZEISS powerdome IV // INSPIRATION MADE BY ZEISS True Hybrid with brilliant stars and perfect renderings from a single source ZEISS powerdome IV brings many new features to your star theater: an integrated planetarium for earthbound and extraterrestrial astronomy with seamless transitions between optical and digital star fields (True Hybrid) | The universe from Earth via the solar system and Milky Way galaxy to the very edge of the observable space | Stereo projection | 8k performance | 10 bit color depth for smooth gradients | HEVC codec for efficient video renderings free of artifacts | All constellation figures, individually and in groups without any mutual overlapping | Telescope function for deep-sky imagery applying Astronomy Visualization Metadata | Complete image set of all Messier objects | Customizable polar lights, comets with gas and dust tails, and shooting stars with a great variety of parameters for location, brightness, colors and appearance | Simulation of day and night with dusk and dawn coloring of sky and panorama images | Customizable weather effects such as clouds, rain, fog, snow, rainbow, halos, air and light pollution effects | Digital rights management to secure your productions | Remote service for quick help, and much more from the only company serving planetariums for nearly a century. www.zeiss.com/planetariums zeiss-ad_pdIV_letter_x3.indd -

Ultra-Large-Scale Sites
Ultra-large-scale Sites <working title> – Scalability, Availability and Performance in Social Media Sites (picture from social network visualization?) Walter Kriha With a forword by << >> Walter Kriha, Scalability and Availability Aspects…, V.1.9.1 page 1 03/12/2010 Copyright <<ISBN Number, Copyright, open access>> ©2010 Walter Kriha This selection and arrangement of content is licensed under the Creative Commons Attribution License: http://creativecommons.org/licenses/by/3.0/ online: www.kriha.de/krihaorg/ ... <a rel="license" href="http://creativecommons.org/licenses/by/3.0/de/"><img alt="Creative Commons License" style="border-width:0" src="http://i.creativecommons.org/l/by/3.0/de/88x31.png" /></a><br /><span xmlns:dc="http://purl.org/dc/elements/1.1/" href="http://purl.org/dc/dcmitype/Text" property="dc:title" rel="dc:type"> Building Scalable Social Media Sites</span> by <a xmlns:cc="http://creativecommons.org/ns#" href="wwww.kriha.de/krihaorg/books/ultra.pdf" property="cc:attributionName" rel="cc:attributionURL">Walter Kriha</a> is licensed under a <a rel="license" href="http://creativecommons.org/licenses/by/3.0/de/">Creative Commons Attribution 3.0 Germany License</a>.<br />Permissions beyond the scope of this license may be available at <a xmlns:cc="http://creativecommons.org/ns#" href="www.kriha.org" rel="cc:morePermissions">www.kriha.org</a>. Walter Kriha, Scalability and Availability Aspects…, V.1.9.1 page 2 03/12/2010 Acknowledgements <<master course, Todd Hoff/highscalability.com..>> Walter Kriha, Scalability and Availability Aspects…, V.1.9.1 page 3 03/12/2010 ToDo’s - The role of ultra fast networks (Infiniband) on distributed algorithms and behaviour with respect to failure models - more on group behaviour from Clay Shirky etc. -

Database Replication in Large Scale Systemsa4paper
Universidade do Minho Escola de Engenharia Departamento de Informática Dissertação de Mestrado Mestrado em Engenharia Informática Database Replication in Large Scale Systems Miguel Gonçalves de Araújo Trabalho efectuado sob a orientação do Professor Doutor José Orlando Pereira Junho 2011 Partially funded by project ReD – Resilient Database Clusters (PDTC / EIA-EIA / 109044 / 2008). ii Declaração Nome: Miguel Gonçalves de Araújo Endereço Electrónico: [email protected] Telefone: 963049012 Bilhete de Identidade: 12749319 Título da Tese: Database Replication in Large Scale Systems Orientador: Professor Doutor José Orlando Pereira Ano de conclusão: 2011 Designação do Mestrado: Mestrado em Engenharia Informática É AUTORIZADA A REPRODUÇÃO INTEGRAL DESTA TESE APENAS PARA EFEITOS DE INVESTIGAÇÃO, MEDIANTE DECLARAÇÃO ESCRITA DO INTERESSADO, QUE A TAL SE COMPROMETE. Universidade do Minho, 30 de Junho de 2011 Miguel Gonçalves de Araújo iii iv Experience is what you get when you didn’t get what you wanted. Randy Pausch (The Last Lecture) vi Acknowledgments First of all, I want to thank Prof. Dr. José Orlando Pereira for accepting being my adviser and for encouraging me to work on the Distributed Systems Group at University of Minho. His availability, patient and support were crucial on this work. I would also like to thank Prof. Dr. Rui Oliveira for equal encouragement on joining the group. A special thanks to my parents for all support throughout my journey and particularly all the incentives to keep on with my studies. I thank to my friends at the group that joined me on this important stage of my stud- ies. A special thank to Ricardo Coelho, Pedro Gomes and Ricardo Gonçalves for all the discussions and exchange of ideas, always encouraging my work. -

Examining Surprise Billing: Protecting Patients from Financial Pain Hearing
EXAMINING SURPRISE BILLING: PROTECTING PATIENTS FROM FINANCIAL PAIN HEARING BEFORE THE SUBCOMMITTEE ON HEALTH, EMPLOYMENT, LABOR, AND PENSIONS COMMITTEE ON EDUCATION AND LABOR U.S. HOUSE OF REPRESENTATIVES ONE HUNDRED SIXTEENTH CONGRESS FIRST SESSION HEARING HELD IN WASHINGTON, DC, APRIL 2, 2019 Serial No. 116–14 Printed for the use of the Committee on Education and Labor ( Available via the World Wide Web: www.govinfo.gov or Committee address: https://edlabor.house.gov U.S. GOVERNMENT PUBLISHING OFFICE 36–589PDF WASHINGTON : 2019 VerDate Mar 15 2010 11:59 Nov 19, 2019 Jkt 000000 PO 00000 Frm 00001 Fmt 5011 Sfmt 5011 C:\USERS\NWILLIAMS\ONEDRIVE - US HOUSE OF REPRESENTATIVES\DESKTOP\3658 EDL-011-D with DISTILLER COMMITTEE ON EDUCATION AND LABOR ROBERT C. ‘‘BOBBY’’ SCOTT, Virginia, Chairman Susan A. Davis, California Virginia Foxx, North Carolina, Rau´ l M. Grijalva, Arizona Ranking Member Joe Courtney, Connecticut David P. Roe, Tennessee Marcia L. Fudge, Ohio Glenn Thompson, Pennsylvania Gregorio Kilili Camacho Sablan, Tim Walberg, Michigan Northern Mariana Islands Brett Guthrie, Kentucky Frederica S. Wilson, Florida Bradley Byrne, Alabama Suzanne Bonamici, Oregon Glenn Grothman, Wisconsin Mark Takano, California Elise M. Stefanik, New York Alma S. Adams, North Carolina Rick W. Allen, Georgia Mark DeSaulnier, California Francis Rooney, Florida Donald Norcross, New Jersey Lloyd Smucker, Pennsylvania Pramila Jayapal, Washington Jim Banks, Indiana Joseph D. Morelle, New York Mark Walker, North Carolina Susan Wild, Pennsylvania James Comer, Kentucky Josh Harder, California Ben Cline, Virginia Lucy McBath, Georgia Russ Fulcher, Idaho Kim Schrier, Washington Van Taylor, Texas Lauren Underwood, Illinois Steve Watkins, Kansas Jahana Hayes, Connecticut Ron Wright, Texas Donna E. -

First Assignment
Second Assignment – Tutorial lecture INF5040 (Open Distributed Systems) Faraz German ([email protected]) Department of Informatics University of Oslo October 17, 2016 Group Communication System Services provided by group communication systems: o Abstraction of a Group o Multicast of messages to a Group o Membership of a Group o Reliable messages to a Group o Ordering of messages sent to a Group o Failure detection of members of the Group o A strong semantic model of how messages are handled when changes to the Group membership occur 2 Spread An open source toolkit that provides a high performance messaging service that is resilient to faults across local and wide area networks. Does not support very large groups, but does provide a strong model of reliability and ordering Integrates a membership notification service into the stream of messages Supports multiple link protocols and multiple client interfaces The client interfaces provided with Spread include native interfaces for Java and C. o Also non native Pearl, Python and Ruby interfaces Spread Provides different types of messaging services to applications o Messages to entire groups of recipients o Membership information about who is currently alive and reachable Provides both ordering and reliability guarantees Level of service When an application sends a Spread message, it chooses a level of service for that message. The level of service selected controls what kind of ordering and reliability are provided to that message. Spread Service Type Ordering Reliability UNRELIABLE -

Best Practice Assessment of Software Technologies for Robotics
Best Practice Assessment of Software Technologies for Robotics Azamat Shakhimardanov Jan Paulus Nico Hochgeschwender Michael Reckhaus Gerhard K. Kraetzschmar February 28, 2010 Abstract The development of a complex service robot application is a very difficult, time-consuming, and error-prone exercise. The need to interface to highly heterogeneous hardware, to run the final distributed software application on a ensemble of often heterogeneous computational devices, and to integrate a large variety of different computational approaches for solving particular functional aspects of the application are major contributing factors to the overall complexity of the task. While robotics researchers have focused on developing new methods and techniques for solving many difficult functional problems, the software industry outside of robotics has developed a tremendous arsenal of new software technologies to cope with the ever-increasing requirements of state-of-the-art and innovative software applications. Quite a few of these techniques have the potential to solve problems in robotics software development, but uptake in the robotics community has often been slow or the new technologies were almost neglected altogether. This paper identifies, reviews, and assesses software technologies relevant to robotics. For the current document, the assessment is scientifically sound, but neither claimed to be complete nor claimed to be a full-fledged quantitative and empirical evaluation and comparison. This first version of the report focuses on an assessment of technologies -

Database Management Systems Ebooks for All Edition (
Database Management Systems eBooks For All Edition (www.ebooks-for-all.com) PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sun, 20 Oct 2013 01:48:50 UTC Contents Articles Database 1 Database model 16 Database normalization 23 Database storage structures 31 Distributed database 33 Federated database system 36 Referential integrity 40 Relational algebra 41 Relational calculus 53 Relational database 53 Relational database management system 57 Relational model 59 Object-relational database 69 Transaction processing 72 Concepts 76 ACID 76 Create, read, update and delete 79 Null (SQL) 80 Candidate key 96 Foreign key 98 Unique key 102 Superkey 105 Surrogate key 107 Armstrong's axioms 111 Objects 113 Relation (database) 113 Table (database) 115 Column (database) 116 Row (database) 117 View (SQL) 118 Database transaction 120 Transaction log 123 Database trigger 124 Database index 130 Stored procedure 135 Cursor (databases) 138 Partition (database) 143 Components 145 Concurrency control 145 Data dictionary 152 Java Database Connectivity 154 XQuery API for Java 157 ODBC 163 Query language 169 Query optimization 170 Query plan 173 Functions 175 Database administration and automation 175 Replication (computing) 177 Database Products 183 Comparison of object database management systems 183 Comparison of object-relational database management systems 185 List of relational database management systems 187 Comparison of relational database management systems 190 Document-oriented database 213 Graph database 217 NoSQL 226 NewSQL 232 References Article Sources and Contributors 234 Image Sources, Licenses and Contributors 240 Article Licenses License 241 Database 1 Database A database is an organized collection of data. -

An Information-Driven Architecture for Cognitive Systems Research
An Information-Driven Architecture for Cognitive Systems Research Sebastian Wrede Dipl.-Inform. Sebastian Wrede AG Angewandte Informatik Technische Fakultät Universität Bielefeld email: [email protected] Abdruck der genehmigten Dissertation zur Erlangung des akademischen Grades Doktor-Ingenieur (Dr.-Ing.). Der Technischen Fakultät der Universität Bielefeld am 09.07.2008 vorgelegt von Sebastian Wrede, am 27.11.2008 verteidigt und genehmigt. Gutachter: Prof. Dr. Gerhard Sagerer, Universität Bielefeld Assoc. Prof. Bruce A. Draper, Colorado State University Prof. Dr. Christian Bauckhage, Universität Bonn Prüfungsausschuss: Prof. Dr. Helge Ritter, Universität Bielefeld Dr. Robert Haschke, Universität Bielefeld Gedruckt auf alterungsbeständigem Papier nach ISO 9706 An Information-Driven Architecture for Cognitive Systems Research Der Technischen Fakultät der Universität Bielefeld zur Erlangung des Grades Doktor-Ingenieur vorgelegt von Sebastian Wrede Bielefeld – Juli 2008 Acknowledgments Conducting research on a computer science topic and writing a thesis in a collaborative research project where the thesis results are at the same time the basis for scientific innovation in the very same project is a truly challenging experience - both for the author as well as its colleagues. Even though, working in the VAMPIRE EU project was always fun. Consequently, I would first like to thank all the people involved in this particular project for their commitment and cooperation. Among all the people supporting me over my PhD years, I need to single out two persons that were of particular importance. First of all, I would like to thank my advisor Christian Bauckhage for his inspiration and his ongoing support from the early days in the VAMPIRE project up to his final com- ments on this thesis manuscript. -

Architecture of the Focus 3D Telemodeling Tool
NISTIR 7322 Architecture of the Focus 3D Telemodeling Tool Arthur F. Griesser, Ph.D. NISTIR 7322 Architecture of the Focus 3D Telemodeling Tool Arthur F. Griesser, Ph.D. Semiconductor Electronics Devision Electronics and Electrical Engineering Laboratory August 2005 U.S. DEPARTMENT OF COMMERCE Carlos M. Gutierrez, Secretary TECHNOLOGY ADMINISTRATION Michelle O’Neill, Acting Under Secretary of Commerce for Technology NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY William A. Jeffrey, Director Architecture of the Focus 3D Telemodeling Tool Abstract A high level design of the Focus 3D modeling tool is presented. Infrastructure components are selected in the light of the functional and non functional requirements of the Focus project. A description of how these components will fit together is provided, and architectural alternatives are considered. Table of Contents Overview..................................................................................................................................................................... 4 Frameworks................................................................................................................................................................ 4 Change Distribution..................................................................................................................................................... 5 GUI Toolkit.................................................................................................................................................................. -
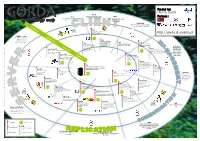
Replication Suite Er Op Jmanage E D4.3 Ore He Pr D6.4C In-C E T
Fun ded by: FP6 IST2 004758 TPC-W TPC-B Industry standard benchmark TPC-C Partners : GGORDAORDA Simple benchmark used for loading simulating a web application Industry standard benchmark implementations while testing simulating a write-intensive OLTP tteechchnonolologgyy mmapap application PolePosition Micro-benchmark collection used for sc IEN measuring overhead of the GAPI ena L T rios C Carob http://carob.continuent.org C/C++ binding to the middleware wrapper http://gorda.di.uminho.pt RDBMS and SQL plat The GORDA project targets D4.4 relational database form ODBC management systems s The standard database exposing a SQL interface JDBC Jade Other access interface in the MA Windows platform is Standard database access http://jade.objectweb.org Proprietary database interface in the Java platform access interfaces (DBMS supported natively or Autonomic management pack through Carob environment Centralized . specific or Perl, PHP, s r Management Python, etc) are Fractal Oracle Berkley DB age supported natively or Observation and wne http://fractal.objectweb.org N http://oss.oracle.com/berkeley-db.html through Carob e o s D5.4 control of the v i t Work-in-progress native Modular, extensible and programming c replicated database e language agnostic component model p implementation A system from a es Apache Derby int http://db.apache.org/derby e GORDA Management central location heir r rf Reference implementation of Interfaces for deploying and f t ac managing replicated database G o GORDA protocols in a flexible es y t R management systems -

Formation Flying Test Bed Data Analysis Software Programming Project
Project Number: SJB-GPS3 Worcester Polytechnic Institute 100 Institute Road, Worcester, MA 01609 Formation Flying Test Bed Data Analysis Software Programming Project A Preliminary Qualifying Project Proposal: Submitted to the Faculty of the WORCESTER POLYTECHNIC INSTITUTE In partial fulfillment of the requirements for the Degree of Bachelor of Science By ___________________________________ Ye Wang ___________________________________ Cody Holemo Date: October 14, 2004 NASA Mentors WPI Advisors Richard Burns Stephen Bitar [email protected] [email protected] ______________________________ Dave Gaylor Fred Looft [email protected] [email protected] ______________________________ This document represents the work of WPI students. The opinions expressed in this report are not necessarily those of the Goddard Space Flight Center or the National Aeronautics and Space Administration Abstract Our senior design project related to software development for the Formation Flying Test Bed (FFTB) at the National Aeronautics and Space Administration’s (NASA) Goddard Space Flight Center (GSFC). Our project consisted of enhancing existing software tools that provide real-time data plotting and data communication for the FFTB. The existing software tools consisted of a simulation plotting package and the software created by the 2003 WPI project team. We improved the data communications of the FFTB by implementing a middleware communications system to replace point-to-point connections. We also developed a real-time plotting application that utilized -
A Robust Group Communication Library for Grid Environments
MojaveComm: A Robust Group Communication Library for Grid Environments Cristian T¸˘apus¸, David Noblet, and Jason Hickey Computer Science Department California Institute of Technology {crt,dnoblet,jyh}@cs.caltech.edu Abstract use of such relaxed semantics often requires the user to have a deep understanding of the underlying system in order to This paper introduces a fault-tolerant group communi- write correct applications. The alternative is to adopt a cation protocol that is aimed at grid and wide area environ- strict consistency model, such as sequential consistency [8], ments. The protocol has two layers. The lower layer pro- which preserves the order of accesses specified by the pro- vides a total order of messages in one group, while the up- grams. It is widely accepted that this is the simplest pro- per layer provides an ordering of messages accross groups. gramming model for data consistency. In practice, the se- The protocol can be used to implement sequential consis- quential consistency model has been reluctantly adopted tency. To prove the correctness of our protocol we have used due to concerns about its performance. However, recent a combination of model checking and mathematical proofs. work in compilers for parallel languages [7] has shown that The paper also presents the behavior of our implementation sequential consistency is a feasible alternative. Our work of the protocol in a simulated environment. introduces a communication infrastructure that enables the implementation of the sequential consistency model in a distributed environment. 1. Introduction Consensus protocols play an important role in maintain- ing consistency of replicated data and in solving the prob- Distributed systems, historically, have proved to be both lem of concurrent accesses to shared resources in the GRID.