Genome-Wide Identification, Characterization, And
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Plasma Membrane Ca2+–Atpase in Rat and Human Odontoblasts Mediates Dentin Mineralization
biomolecules Article Plasma Membrane Ca2+–ATPase in Rat and Human Odontoblasts Mediates Dentin Mineralization Maki Kimura 1,†, Hiroyuki Mochizuki 1,†, Ryouichi Satou 2, Miyu Iwasaki 2, Eitoyo Kokubu 3, Kyosuke Kono 1, Sachie Nomura 1, Takeshi Sakurai 1, Hidetaka Kuroda 1,4,† and Yoshiyuki Shibukawa 1,*,† 1 Department of Physiology, Tokyo Dental College, 2-9-18, Kanda-Misaki-cho, Chiyoda-ku, Tokyo 101-0061, Japan; [email protected] (M.K.); [email protected] (H.M.); [email protected] (K.K.); [email protected] (S.N.); [email protected] (T.S.); [email protected] (H.K.) 2 Department of Epidemiology and Public Health, Tokyo Dental College, Chiyodaku, Tokyo 101-0061, Japan; [email protected] (R.S.); [email protected] (M.I.) 3 Department of Microbiology, Tokyo Dental College, Chiyodaku, Tokyo 101-0061, Japan; [email protected] 4 Department of Dental Anesthesiology, Kanagawa Dental University, 1-23, Ogawacho, Kanagawa, Yokosuka-shi 238-8570, Japan * Correspondence: [email protected] † These authors contributed equally to this study. Abstract: Intracellular Ca2+ signaling engendered by Ca2+ influx and mobilization in odontoblasts is critical for dentinogenesis induced by multiple stimuli at the dentin surface. Increased Ca2+ is exported by the Na+–Ca2+ exchanger (NCX) and plasma membrane Ca2+–ATPase (PMCA) to Citation: Kimura, M.; Mochizuki, H.; maintain Ca2+ homeostasis. We previously demonstrated a functional coupling between Ca2+ Satou, R.; Iwasaki, M.; Kokubu, E.; extrusion by NCX and its influx through transient receptor potential channels in odontoblasts. Kono, K.; Nomura, S.; Sakurai, T.; Although the presence of PMCA in odontoblasts has been previously described, steady-state levels of Kuroda, H.; Shibukawa, Y. -

Crystal Structures of the Gastric Proton Pump Reveal the Mechanism for Proton Extrusion
Life Science Research Frontiers 2018 Research Frontiers 2018 Crystal structures of the gastric proton pump reveal the mechanism for proton extrusion After intaking food, the pH inside our stomach phosphorylation (P), and actuator (A) domains reaches around 1. This acidic environment, (Fig. 2(a)). The β-subunit has a single TM helix and generated by the gastric proton pump H+,K+-ATPase a large ectodomain with three of the six N-linked [1], is indispensable for food digestion and is also glycosylation sites visualized in the structure. The an important barrier to pathogen invasion via the electron density maps define the binding mode of oral route. However, excess stomach acidification vonoprazan (now available for clinical treatment) and induces ulcers, which considerably impair the health SCH28080 (a prototype of P-CAB), and the residues of those affected. Acid suppression in combination coordinating them, in a luminal-facing conduit that with antibiotics is a widely recognized treatment to extends to the cation-binding site (Figs. 2(b) and 2(c)). eradicate Helicobactor pylori, a strong risk factor for The binding sites of these P-CABs were previously gastric cancer. Proton pump inhibitors (PPIs) and a thought to overlap owing to similar inhibitory actions. recently developed class of acid suppressants called Our structures show that they do indeed partially K+-competitive acid blockers (P-CABs) are commonly overlap but are also distinct. The binding mode used for the treatment of acid-related diseases. of P-CABs determined in the crystal structure is Gastric H+,K+-ATPase therefore continues to be a consistent with mutagenesis studies, providing prominent target for the treatment of excess stomach the molecular basis for P-CAB binding to H+,K+- acidification. -

Molecular Regulation and Physiology of the H ,K -Atpases in Kidney
Molecular Regulation and Physiology of the H؉,K؉-ATPases in Kidney Juan Codina and Thomas D. DuBose Jr Two H؉,K؉-adenosine triphosphatase (ATPase) proteins participate in K؉ absorption and ؉ ؉ ؉ H secretion in the renal medulla. Both the gastric (HK␣1) and colonic (HK␣2)H,K - ATPases have been localized and characterized by a number of techniques, and are known to be highly regulated in response to acid-base and electrolyte disturbances. Both ATPases are dimers of composition ␣/ that localize to the apical membrane and both interact with the tetraspanin protein CD63. Although CD63 interacts with the carboxy-terminus of the subunit of the colonic H؉,K؉-ATPase, it interacts with the -subunit of the gastric-␣ H؉,K؉-ATPase. Pharmacologically, both ATPases are distinct; for example, the gastric H؉,K؉-ATPase is inhibited by Sch-28080, but the colonic H؉,K؉-ATPase is inhibited by .ouabain (a classic inhibitor of the Na؉-pump) and is completely insensitive to Sch-28080 The ␣-subunit of the colonic H؉,K؉-ATPase is the only subunit of the X؉,K؉-ATPase superfamily that has 3 different splice variants that emerge by deletion or elongation of the amino-terminus. The messenger RNA and protein of one of these splice variants (HK␣2C)is specifically up-regulated in newborn rats and becomes undetectable in adult rats. There- fore, HK␣2, in addition to its role in potassium and acid-base homeostasis, appears to play a significant role in early growth and development. Finally, because chronic hypokalemia appears to be the most potent stimulus for upregulation of HK␣2, we propose that the HK␣2 participates importantly in the maintenance of chronic metabolic alkalosis. -

SAENGWILAI, P.: Effects of Root Hair Length on Potassium Acquisition
Klinsawang et al.: Effects of root hair length on potassium acquisition in rice - 1609 - EFFECTS OF ROOT HAIR LENGTH ON POTASSIUM ACQUISITION IN RICE (ORYZA SATIVA L.) KLINSAWANG, S.1 – SUMRANWANICH, T.1 – WANNARO, A.1 – SAENGWILAI, P.1,2* 1Department of Biology, Faculty of Science, Mahidol University Rama VI Road, Bangkok 10400, Thailand 2Center of Excellence on Environmental Health and Toxicology (EHT) Bangkok, Thailand *Corresponding author e-mail: [email protected] (phone: +66-9-1725-4817) (Received 12th Oct 2017; accepted 20th Feb 2018) Abstract. Potassium (K) deficiency limits rice production worldwide. It has been shown that variation in root traits, such as root hair length, influences ion uptake in many plant species. In this study, we explored natural variation of root hair length of twelve rice varieties in a roll-up system. We found a large phenotypic variation for root hair traits ranging from 0.14 to 0.21 mm. Niaw San-pah-tawng and most upland varieties had long root hairs while lowland varieties had short root hairs. Six lowland varieties contrasting in root hair length were planted in pots under high and low K concentrations. K stress was found to decrease average biomass by 60.93% and K tissue content by 66%. Root to shoot ratio was not affected by K stress. Correlation analysis indicated that long root hair was associated with reduced percentage of leaf senescence, enhanced plant biomass, and improved tissue K content under low K condition. Our results suggest that long root hair could be a useful trait for plant breeding to improve K acquisition in rice. -

A Model of Mitochonrial Calcium Induced Calcium
A MODEL OF MITOCHONRIAL CALCIUM INDUCED CALCIUM RELEASE DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Balbir Thomas, The Ohio State University 2007 Dissertation Committee: Approved by David Terman, Adviser Douglas R. Pfeiffer Adviser Edward Overman Biophysics Graduate Program Christopher P. Fall ABSTRACT Cytoplasmic calcium plays a dual role in cellular physiology. On one hand it acts as a second messenger in intra-cellular signalling, and on the other hand it is also the trigger for calcium dependent apopotosis. A mechanistic explanation of this dual role of cytoplasmic calcium was proposed by Ichas and Mazat. Their hypothesis involved the permeability transition pore was based on the observation that the permeability transition pore can exist in multiple conductance states. Specifically there exist a persistent high conductance state and a transitory low conductance state. Ichas et.al. also observed that the low conductance state is opened by a rise in mitochondrial matrix pH, in contrast to what was already know about the high conductance state, which opens in response to prolonged elevation of mitochondrial calcium. In this dissertation we build a detailed, physiological model of the mitochondrial switch between calcium signalling and cell death based on a simple three state model of the permeability transition pore. This model agrees with the substance of the Ichas and Mazat hypothesis and provides a substrate for further modeling to study the spatial and temporal dynamics of mitochondrial involvement in intracellular calcium signalling, and the interaction of mitochondria and endoplasmic reticulum during this process. -

Molecular Cloning and Sequence of Cdna Encoding the Plasma
Proc. Nad. Acad. Sci. USA Vol. 86, 1234-1238, February 1989 Botany Molecular cloning and sequence of cDNA encoding the plasma membrane proton pump (H+-ATPase) of Arabidopsis thaliana (cation pumps/nucleotide sequence/amino add homology/oligonucleotide screening/transmembrane segments) JEFFREY F. HARPER, TERRY K. SUROWY*, AND MICHAEL R. SUSSMAN Department of Horticulture, University of Wisconsin, 1575 Linden Drive, Madison, WI 53706 Communicated by Luis Sequeira, November 14, 1988 ABSTRACT In plants, the transport of solutes across the synthesized an oligonucleotide probe to screen an oat cDNA plasma membrane is driven by a proton pump (H -ATPase) library and then used a purified oat clone to isolate a that produces an electric potential and pH gradient. We have full-length A. thaliana cDNA clone. Here we provide evi- isolated and sequenced a full-length cDNA clone that encodes dence for the presence of at least two genes encoding plasma this enzyme inArabidopsis thaiana. The protein predicted from membrane proton pumps in A. thaliana and report the its nucleotide sequence encodes 959 amino acids and has a predicted amino acid sequence from one. molecular mass of 104,207 Da. The plant protein shows structural features common to a family of cation-translocating MATERIALS AND METHODS ATPases found in the plasma membrane of prokaryotic and eukaryotic cells, with the greatest overall identity in amino acid Plants. A. thaliana L. cv. Columbia and Avena sativa L. sequence (36%) to the H+-ATPase observed in the plasma cv. Gary (oat) were plant materials used in this study. Unless membrane of fungi. The structure predicted from a hydropa- otherwise noted, standard molecular techniques were per- thy plot contains at least eight transmembrane segments, with formed according to Maniatis et al. -

Targeting Oncogenic Notch Signaling with SERCA Inhibitors Luca Pagliaro, Matteo Marchesini and Giovanni Roti*
Pagliaro et al. J Hematol Oncol (2021) 14:8 https://doi.org/10.1186/s13045-020-01015-9 REVIEW Open Access Targeting oncogenic Notch signaling with SERCA inhibitors Luca Pagliaro, Matteo Marchesini and Giovanni Roti* Abstract P-type ATPase inhibitors are among the most successful and widely prescribed therapeutics in modern pharmacol- ogy. Clinical transition has been safely achieved for H+/K+ ATPase inhibitors such as omeprazole and Na+/K+-ATPase 2 inhibitors like digoxin. However, this is more challenging for Ca +-ATPase modulators due to the physiological role of 2 2 Ca + in cardiac dynamics. Over the past two decades, sarco-endoplasmic reticulum Ca +-ATPase (SERCA) modula- 2 tors have been studied as potential chemotherapy agents because of their Ca +-mediated pan-cancer lethal efects. Instead, recent evidence suggests that SERCA inhibition suppresses oncogenic Notch1 signaling emerging as an alternative to γ-secretase modulators that showed limited clinical activity due to severe side efects. In this review, we focus on how SERCA inhibitors alter Notch1 signaling and show that Notch on-target-mediated antileukemia proper- 2 ties of these molecules can be achieved without causing overt Ca + cellular overload. Keywords: SERCA , T cell acute lymphoblastic leukemia, Thapsigargin, Notch signaling, NOTCH1, CAD204520, T-ALL Background metalloprotease (ADAM-10 or TACE/ADAM-17). Te NOTCH receptors are transmembrane cell-surface pro- resulting short-lived protein fragments are substrates teins that control cell to cell communication, embryo- -

Learning List 1. Eukaryotic Cells (Plant and Animal Cells) Have a Cell Membrane, Cytoplasm and Genetic Material Enclosed in a Nucleus
Learning List 1. Eukaryotic cells (plant and animal cells) have a cell membrane, cytoplasm and genetic material enclosed in a nucleus. 2. Prokaryotic cells contain cytoplasm, cell membrane and a cell wall. The genetic material is not in a nucleus but a single loop. 3. Prokaryotic cells can contain plasmids. 4. Prokaryotic cells are much smaller than eukaryotic cells. 5. Animal cells contain nucleus, cytoplasm, cell membrane, mitochondria and ribosomes. 6. Plant cells also contain chloroplasts, a vacuole and a cell wall. 7. Plant cell walls are made of cellulose. 8. Most animal cells differentiate at an early stage (become specialised) 9. Most plant cells retain the ability to differentiate throughout their life. 10. Cells can be specialised to carry out a particular function e.g. sperm cells, nerve cells, muscle cells, root hair cells, xylem and phloem cells. Cells All living things are made of ________________. Cells can either be ____________________ or ________________________. Plants and animal cells are _________________________. Label the diagram of a plant and animal cell. Compare the structure of a plant and animal cell Bacteria are _______________________ cells. Label the diagram of a bacterial cell. Complete the Venn Diagram to compare eukaryotic and prokaryotic cells Eukaryotic Prokaryotic Function of cell organelles Learning List – Microscopes 1. Light microscopes use light and lenses to form an image of a specimen. 2. Light microscopes are used to se nuclei, chloroplasts, cell wall, cell membrane and mitochondria. Electron microscopes use electrons to form an image. 3. Stains are used to make the specimen visible. 4. Electron microscopes have a higher magnification. -

Dissecting Hierarchies Between Light, Sugar and Auxin Action Underpinning Root and Root Hair Growth
plants Article Dissecting Hierarchies between Light, Sugar and Auxin Action Underpinning Root and Root Hair Growth Judith García-González 1,2,†, Jozef Lacek 1,† and Katarzyna Retzer 1,* 1 Laboratory of Hormonal Regulations in Plants, Institute of Experimental Botany, Czech Academy of Sciences, 165 02 Prague, Czech Republic; [email protected] (J.G.-G.); jozefl[email protected] (J.L.) 2 Department of Experimental Plant Biology, Faculty of Science, Charles University, 128 00 Prague, Czech Republic * Correspondence: [email protected] † Those authors contributed equally to this work. Abstract: Plant roots are very plastic and can adjust their tissue organization and cell appearance during abiotic stress responses. Previous studies showed that direct root illumination and sugar supplementation mask root growth phenotypes and traits. Sugar and light signaling where further connected to changes in auxin biosynthesis and distribution along the root. Auxin signaling un- derpins almost all processes involved in the establishment of root traits, including total root length, gravitropic growth, root hair initiation and elongation. Root hair plasticity allows maximized nutrient uptake and therefore plant productivity, and root hair priming and elongation require proper auxin availability. In the presence of sucrose in the growth medium, root hair emergence is partially rescued, but the full potential of root hair elongation is lost. With our work we describe a combinatory study showing to which extent light and sucrose are antagonistically influencing root length, but additively affecting root hair emergence and elongation. Furthermore, we investigated the impact of the loss of PIN-FORMED2, an auxin efflux carrier mediating shootward auxin transporter, on the establishment of root traits in combination with all growth conditions. -

SERCA in Genesis of Arrhythmias: What We Already Know and What Is New?
Review 43 SERCA in genesis of arrhythmias: what we already know and what is new? Nilüfer Erkasap Department of Physiology, Medical Faculty, Eskiflehir Osmangazi University, Eskiflehir, Turkey ABSTRACT This review mainly focuses on the structure, function of the sarco(endo)plasmic reticulum calcium pump (SERCA) and its role in genesis of arrhythmias. SERCA is a membrane protein that belongs to the family of P-type ion translocating ATPases and pumps free cytosolic calcium into intracellular stores. Active transport of Ca2+ is achieved, according to the E1-E2 model, changing of SERCA structure by Ca2+. The affinity of Ca2+ -binding sites varies from high (E1) to low (E2). Three different SERCA genes were identified-SERCA1, SERCA2, and SERCA3. SERCA is mainly represented by the SERCA2a isoform in the heart. In heart muscle, during systole, depolarization triggers the release of Ca2+ from the sarcoplasmic reticulum (SR) and starts contraction. During diastole, muscle relaxation occurs as Ca2+ is again removed from cytosol, predominantly by accumulation into SR via the action of SERCA2a. The main regulator of SERCA2a is phospholamban and another regulator proteolipid of SERCA is sarcolipin. There are a lot of studies on the effect of decreased and/or increased SERCA activity in genesis of arrhythmia. Actually both decrease and increase of SERCA activity in the heart result in some pathological mechanisms such as heart failure and arrhythmia. (Anadolu Kardiyol Derg 2007: 7 Suppl 1; 43-6) Key words: sarco(endo)plasmic reticulum, SERCA, arrhythmia, calcium channels Introduction from cytosol, predominantly by accumulation into sarcoplasmic reticulum via the action of sarco(endo)plasmic reticulum Cardiac physiology is a major area of research in basic and Ca ATPase (SERCA). -

Endoplasmic Reticulum Potassium–Hydrogen Exchanger and Small
Research Article 625 Endoplasmic reticulum potassium–hydrogen exchanger and small conductance calcium-activated potassium channel activities are essential for ER calcium uptake in neurons and cardiomyocytes Malle Kuum1,2,3, Vladimir Veksler2,3, Joanna Liiv1, Renee Ventura-Clapier2,3 and Allen Kaasik1,* 1Department of Pharmacology, Centre of Excellence for Translational Medicine, University of Tartu, Ravila 19, Tartu EE-51014, Estonia 2INSERM, U-769, 5, rue Jean-Baptiste Clement, Chaˆtenay-Malabry F-92296, France 3Universite´ Paris-Sud, 5, rue Jean-Baptiste Clement, Chaˆtenay-Malabry F-92296, France *Author for correspondence ([email protected]) Accepted 12 September 2011 Journal of Cell Science 125, 625–633 ß 2012. Published by The Company of Biologists Ltd doi: 10.1242/jcs.090126 Summary Calcium pumping into the endoplasmic reticulum (ER) lumen is thought to be coupled to a countertransport of protons through sarcoplasmic/endoplasmic reticulum calcium ATPase (SERCA) and the members of the ClC family of chloride channels. However, pH in the ER lumen remains neutral, which suggests a mechanism responsible for proton re-entry. We studied whether cation–proton exchangers could act as routes for such a re-entry. ER Ca2+ uptake was measured in permeabilized immortalized hypothalamic neurons, primary rat cortical neurons and mouse cardiac fibers. Replacement of K+ in the uptake solution with Na+ or tetraethylammonium led to a strong inhibition of Ca2+ uptake in neurons and cardiomyocytes. Furthermore, inhibitors of the potassium–proton exchanger (quinine or propranolol) but not of the sodium–proton exchanger reduced ER Ca2+ uptake by 56–82%. Externally added nigericin, a potassium– + proton exchanger, attenuated the inhibitory effect of propranolol. -
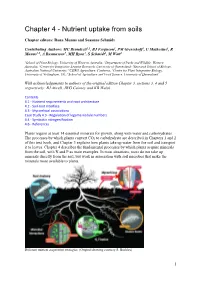
Nutrient Uptake from Soils
Chapter 4 - Nutrient uptake from soils Chapter editors: Rana Munns and Susanne Schmidt Contributing Authors: MC Brundrett1,2, BJ Ferguson3, PM Gressshoff3, U Mathesius5, R Munns1,6, A Rasmussen7, MH Ryan1, S Schmidt8, M Watt5 1School of Plant Biology, University of Western Australia; 2Department of Parks and Wildlife, Western Australia; 3Centre for Integrative Legume Research, University of Queensland; 5Research School of Biology, Australian National University; 6CSIRO Agriculture, Canberra; 7Centre for Plant Integrative Biology, University of Nottingham, UK; 8School of Agriculture and Food Science, University of Queensland With acknowledgements to authors of the original edition Chapter 3, sections 3, 4 and 5 respectively: BJ Atwell, JWG Cairney and KB Walsh Contents 4.1 - Nutrient requirements and root architecture 4.2 - Soil-root interface 4.3 - Mycorrhizal associations Case Study 4.3 - Regulation of legume nodule numbers 4.4 - Symbiotic nitrogen fixation 4.6 - References Plants require at least 14 essential minerals for growth, along with water and carbohydrates. The processes by which plants convert CO2 to carbohydrate are described in Chapters 1 and 2 of this text book, and Chapter 3 explains how plants take up water from the soil and transport it to leaves. Chapter 4 describes the fundamental processes by which plants acquire minerals from the soil, with N and P as main examples. In most situations, roots do not take up minerals directly from the soil, but work in association with soil microbes that make the minerals more available to plants. Different nutrient acquisition strategies. (Original drawing courtesy S. Buckley) 1 This chapter first explains the concept of plant nutrition, then describes the various root structures and symbioses with microorganisms that allow plants to take up essential nutrients.