Determining Urban Emotions: a Case Study Around Majitar, East District, Sikkim
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
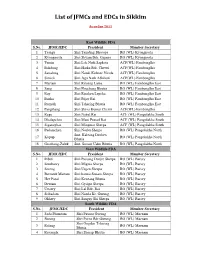
List of Jfmcs and Edcs in Sikkim
,©≥¥ ض *&-#≥ °Æ§ %$#≥ ©Æ 3©´´©≠ !≥ ØÆ *°Æ East Wildlife FDA S.No. JFMC/EDC President Member Secretary 1 Tsangu Shri Tamding Dhotopa RO (WL) Kyongnosla 2 Kyongnosla Shri Shyam Bdr. Gajmer RO (WL) Kyongnosla 3 Tumin Shri Lok Nath Sapkota ACF(WL) Fambonglho 4 Rakdong Shri Harka Bdr. Chettri ACF(WL) Fambonglho 5 Samdong Shri Nandi Kishore Nirola ACF(WL) Fambonglho 6 Simick Shri Jaga Nath Adhikari ACF(WL) Fambonglho 7 Martam Shri Rinzing Lama RO (WL) Fambonglho East 8 Sang Shri Phuchung Bhutia RO (WL) Fambonglho East 9 Ray Shri Rinchen Lepcha. RO (WL) Fambonglho East 10 Ranka Shri Bijay Rai RO (WL) Fambonglho East 11 Rumtek Shri Tshering Bhutia RO (WL) Fambonglho East 12 Pangthang Shri Shiva Kumar Chettri ACF(WL) Fambonglho 13 Regu Shri Nakul Rai ACF (WL) Pangolakha South 14 Dhalapchen Shri Mani Prasad Rai ACF (WL) Pangolakha South 15 Siganaybas Shri Mingmar Sherpa ACF (WL) Pangolakha South 16 Padamchen Shri Norbu Sherpa RO (WL) Pangolakha North Smt. Kalzang Dechen 17 Kupup RO (WL) Pangolakha North Bhutia 18 Gnathang-Zaluk Smt. Sonam Uden Bhutia RO (WL) Pangolakha North West Wildlife FDA S.No. JFMC/EDC President Member Secretary 1 Ribdi Shri Passang Dorjee Sherpa RO (WL) Barsey 2 Sombarey Shri Migma Sherpa RO (WL) Barsey 3 Soreng Shri Urgen Sherpa RO (WL) Barsey 4 Bermoik Martam Shri karma Sonam Sherpa RO (WL) Barsey 5 Hee Patal Shri Kenzang Bhutia RO (WL) Barsey 6 Dentam Shri Gyalpo Sherpa RO (WL) Barsey 7 Uttarey Shri Lal Bdr. Rai RO (WL) Barsey 8 Sribadam Shri Nanda Kr. Gurung RO (WL) Barsey 9 Okhrey Shri Sangay Shi Sherpa RO (WL) Barsey South Wildlife FDA S.No. -

Sl No Name of Schools
LIST OF SCHOOLS FOR GREEN SCHOOL PROGRAMME TRANINING VENUE: FOREST CONFERENCE HALL, DEORALI DATE: 12th OCTOBER 2017 Time: 10:00 a.m. EAST SIKKIM SL NO NAME OF SCHOOLS 1 4 MILE JHS 2 ADAMPOOL JHS 3 ASSAM LINGZEY SSS 4 BARAPATHING JHS 5 BERING JHS 6 BHASMEY JHS 7 BHUSUK JHS 8 BOJOGHARI SSS 9 BORDANG JHS 10 BURTUK JHS 11 CHEWRIBOTEY JHS 12 CHUBA JHS 13 CHUJACHEN SSS 14 DALAPCHEN SS 15 DAMLAKHA JHS 16 DOCHUM JHS 17 DUGA SS 18 ENCHEY SSS 19 GANCHUNG JHS 20 GAUCHARAN JHS 21 KAMBAL JHS 22 KAPUTHANG PS 23 LINGDING JHS 24 LINGDOK SSS 25 LINGTAM SS 26 LOWER BURTUK PS 27 LOWER NANDOK JHS 28 LOWER SUMIN SS 29 LUING upgradation SS 30 LUMSEY JHS 31 MAJITAR SS 32 MARTAM SS 33 MARTAM YANGTHANG JHS 34 MERUNG PS 35 MODERN SSS 36 MULUKEY JHS 37 NAMCHEYBONG SS 38 NAMONG ARITHANG JHS 39 NAMPHONG JHS 40 NANDOK SS 41 NIMTAR JHS 42 NIMTHANG PS 43 NORTH REGU JHS 44 PABYUICK SS SL NO NAME OF SCHOOLS 45 PACHAK SS 46 PACHEY SAMSING PS 47 PACHEY SS 48 PADAMCHEY SS 49 PAKYONG JHS 50 PANGTHANG JHS 51 PATUK CHANDEY JHS 52 PENLONG SS 53 PHADAMCHEN SS 54 PHALAICHADARA JHS 55 RALAP SS 56 REY MINDU JHS 57 ROLEP SS 58 RONGLI JHS 59 RORATHANG SS 60 RUMTEK SSS 61 SAKYONG CHISOPANI JHS 62 SAMA LINGDUM JHS 63 SAMDONG SSS 64 SAMDUR PS 65 SAMLICK MARCHAK(DUGO BHUTIA MEMORIAL) JHS 66 SIRWANI SS 67 SOUTH REGU JHS 68 SUMIN LINGZEY SS 69 SUMIN MANGTHANG JHS 70 SURYODAYA JHS 71 TADONG SSS 72 TAREYTHANG SS 73 TARPIN SS 74 TASHI NAMGYAL SSS 75 THENGU PS 76 TITRIBOTEY PS 77 TUMIN DHANBARI JHS 78 TUMIN NAMRANG JHS 79 TUMIN SS 80 YALLI PS LIST OF SCHOOLS FOR GREEN SCHOOL PROGRAMME TRANINING VENUE: FOREST CONFERENCE HALL, DEORALI DATE: 12th OCTOBER 2017 Time: 10:00 a.m. -

Annual Report 2007 – 2008
Annual Report 2007 – 2008 Human Resource Development Department Government of Sikkim Table of Contents I. AIMS AND OBJECTIVES OF THE DEPARTMENT ............................................................................... 3 II. CATEGORIES OF INSTITUTIONS AND OTHER STATISTICS .................................................................... 3 III. ENGINEERING CELL ............................................................................................................................ 5 IV. SANSKRIT EDUCATION IN SIKKIM ...................................................................................................... 6 V. LANGUAGE SECTION ........................................................................................................................... 7 VI. SCHOLARSHIP SECTION .................................................................................................................... 10 VI. EXAMINATION SECTION................................................................................................................... 12 VIII. DISTRICT INSTITUTE OF EDUCATION & TRAINING (DIET) .............................................................. 14 IX. STATE INSTITUTE OF EDUCATION (SCERT / SIE) ............................................................................... 16 X. SARVA SHIKSHA ABHIYAN (SSA) ........................................................................................................ 18 XI. VOCATIONAL EDUCATION IN SIKKIM .............................................................................................. -

List of the Hindu Mandirs in Sikkim: (336)
LIST OF THE HINDU MANDIRS IN SIKKIM: (336) EAST: Sl. No. Name Location District/Sub-Division 1. Aho Ongkeshwar Mandir Aho Gangtok 2. Amba Mandir. Amba Pakyong. 3. Aritar- Rhenock Durga Mandir Aritar Rongli. 4. Aritar Sarva Janik Shiva Mandir Aritar Rongli. 5. Bara Pathing Mandir Bara Pathing Pakyong 6. Bhanugram Krishna Mandir Bhanugram Gangtok 7. Burtuk Shiva Temple Burtuk Gangtok. 8. Beyga Devi Mandir Beyga Pakyong. 9. Biring Durga Mandir. Biring Pakyong. 10. Chenje Singha Devi Mandir Chenje Gangtok 11. Changey Singha Devi Mandir Changey Pakyong. 12. Chujachen Shivalaya Mandir Chujachen Pakyong. 13. Chota Singtam Shiva Mandir Chota Shing Gangtok. 14. Centre Pandam Shiva Mandir. Centre Pandam Gangtok. 15. Chandmari Shiva Mandir. Chandmari Gangtok. 16. Duga Bimsen Mandir. Duga Gangtok. 17. Duga Krishna Mandir. Duga Gangtok 18. Dikiling Pacheykhani Shivalaya Mandir. Dikiling Pakyong. 19. Dikiling Pacheykhani Radha Krishna Mandir. Dikiling Pakyong. 20. Dikchu Shiva Mandir Dikchu Gangtok 21. Dara Gaon Shiva Mandir. Assam Lingzey Gangtok. 22. Dolepchan Durga Mandir Dolepchan Rongli. 23. Gangtok Thakurbari Mandir. Gangtok Bazaar Gangtok. 24. Jalipool Durga Mandir Jalipool Gangtok 25. Khamdong-Aritar Shiva Mandir Aritar Gangtok 26. Khamdong Durga Mandir. Khamdong Gangtok. 27. Khamdong Krishna Mandir. Khamdong Gangtok. 28. Khesay Durga Mandir U. Khesey Gangtok 29. Kambal Shiva Mandir. Kambol Gangtok. 30. Kamary Durga Mandir Kamary Pakyong. 31. Kokoley Guteshwar Shiva Mandir Kokoley Gangtok 32. Luing Thami Durga Mandir. Thami Danra Gangtok. 33. Lingtam Durga Mandir. Lingtam Rongli. 34. Lingtam Devi Mandir. Lingtam Rongli. 35. Luing Mahadev Shiva Mandir. Luing Gangtok. 36. Lower Samdong Hareshwar Shiva Mandir. Lower Samdong Gangtok 37. Lamaten Mata Mandir Lamaten Pakyong. -

List of the Churches in Sikkim. (168)
LIST OF THE CHURCHES IN SIKKIM. (168) EAST: Sl. No. Name / Address 1. Gangtok Church, below Gangtok Bazaar (Oldest) 2. Rhenock EPCS Church, Aritar Rhenock (Oldest) 3. Phambong Church (Oldest) 4. Basilakha Himalayan Crusade Pentecostal Church, Basilakha 5. Chagey Himalayan Pentecostal Church 6. Dekiling Church, Pakyong 7. Duga Bethal Christian Fellowship Church 8. Gangtok Holi Cross Church, N.H. 9. Goucharan Church, Ranipul 10. Kadamta EPCS Church, 11. Khamdong Church, Khamdong 12. Lanmaiten, EPCS Church 13. Lingtam IPC Church, 14. Majitar Church, Majitar 15. Namcheybung Pentecostal Church 16. Naitam Church, Palum 17. Pakyong St. Thomas Church, Pakyong 18. Padamchey all Saint Church, Padamchey 19. Rhenock Dokshing Catholic Church 20. Rakdong Church, Rakdong 21. Rongli Church, Rongli 22. Rorathang Church, Rorathang 23. Rolep Pongtu Church 24. Ranipul Himalayan Church, Ranipul 25. Rangpo Pentecostal Fellowship Church, Rangpo 26. Sang EPCS Church, Sang 27. Saramsa Tambutar Church 28. Singtam Shileh Christian Church, Singtam 29. Sirwani IPC Church, Sirwani 30. Singtam Himalayan Free Church, Singtam 31. Tadong C.E.R.C.S. Church, Tadong 32. Tadong St. Pauls Church, Tadong 33. Tsalumthang Church, Pakyong 34. Tarpin Rorathang Church, Rorathang 35. Ellin Church, Lower Rakdong 36. Shiloh Church, Lower Rakdong 37. A.G.Church, Development Area 38. Baptist Church, Karthok Namcheybong 39. IC Church, Karthok Namcheybong 40. Bethel Church, Karthok 41. EPCS Church, Karthok 42. Emmanuel Pentecostal Church, Rhenock. District: NORTH: 1. Mangan Himalayan Free Church (Oldest Church) 2. Mangan EPCS Church, Mangan 3. Mangshila EPCS Church 4. Rangrang Baptist Church (Damaged during earthquake of 18th Sept. 2011) 5. Shagyong EPCS Church, Lower Dzongu 6. -

GANGTOK (Civil Appellate Jurisdiction)
THE HIGH COURT OF SIKKIM : GANGTOK (Civil Appellate Jurisdiction) ------------------------------------------------------------------------------- SINGLE BENCH: THE HON’BLE MR. JUSTICE BHASKAR RAJ PRADHAN, JUDGE ------------------------------------------------------------------------------------------------------------------ MAC APPEAL No.06 of 2019 The Branch Manager, National Insurance Company Limited, Having its Branch Office at Opposite Old Tourism Department, P.O. & P.S. Sardar/Gangtok, East Sikkim – 737101. (Insurer of Mahindra & Mahindra (MAXX) Passenger Carriage Jeep bearing Registration No.SK-01-J-2576. Gangtok, East Sikkim. ….. Appellant/Insurer Versus 1. Mr. Arjun Bhandari, S/o Late Govinda Bhandari, 2. Mrs. Ran Maya Bhandari, W/o Mr. Arjun Bhandari, Both residents of: House No.551, Syapley, Sarderay Secondary School West Pendam, GPU, Block Development Office, Duga, P.O. Sakhu, P.S. Singtam, East Sikkim. ....Respondent Nos.1 & 2/Claimant Nos.1 & 2. 3. Mr. Kishore Rai, S/o Sukbir Rai, Permanent Resident of: West Pendam, West Pendam GPU, Block Development Office, Duga, P.O. Sakhu, P.S. Singtam, East Sikkim – 737134. (Owner of: Mahindra & Mahindra (MAXX) Passenger Carriage Jeep bearing Registration No.SK-01-J-2576, driven by one Shri. Sandip Kumar Pathak, employed by the present Respondent No.2.) …..Respondent No.3/Owner. 2 MAC Appeal No. 06 of 2019 Branch Manager v. Arjun Bhandari & Ors. Appeal under Section 173 of the Motor Vehicles Act, 1988. ------------------------------------------------------------------------------- Appearance: Mr. Thupden G. Bhutia, Advocate for the Appellant. Mr. Ajay Rathi and Mr. Bhushan Nepal, Advocates for Respondent Nos.1 and 2. Mr. Sushant Subba, Advocate for Respondent No.3. ----------------------------------------------------------------------- Date of hearing : 22.09.2020 Date of judgment : 21.10.2020 J U D G M E N T Bhaskar Raj Pradhan, J. -

Disaster Management Plan-(2020-21) East Sikkim-737101
DISASTER MANAGEMENT PLAN-(2020-21) EAST SIKKIM-737101 Prepared by: District Disaster Management Authority, East District Collectorate, East Sichey, Gangtok 1 FOREWORD Recent disasters, including the Earthquake which occurred on 18th September 2011 have compelled us to review our Disaster Management Plan and make it more stakeholders friendly. It is true that all the disasters have been dealt significantly by the state ensuring least damage to the human life and property. However, there is a need to generate a system which works automatically during crisis and is based more on the need of the stakeholders specially the community. Further a proper co-ordination is required to manage disasters promptly. Considering this we have made an attempt to prepare a Disaster Management Plan in different versions to make it more user-friendly. While the comprehensive Disaster Management Plan based on vulnerability mapping and GIS Mapping and minute details of everything related to management of disasters is underway, we are releasing this booklet separately on the Disaster Management Plan which is basically meant for better coordination among the responders. The Incident Command System is the part of this booklet which has been introduced for the first time in the East District. This booklet is meant to ensure a prompt and properly coordinated effort to respond any crisis. A due care has been taken in preparing this booklet, however any mistakes will be immediately looked into. All the stakeholders are requested to give their feedback and suggestions for further improvements. Lastly, I want to extend my sincere thanks to the Government, the higher authorities and the Relief Commissioner for the support extended to us and especially to my team members including ADM/R, SDM/Gangtok, District Project Officer and Training Officer for the hard work they have put in to prepare this booklet. -
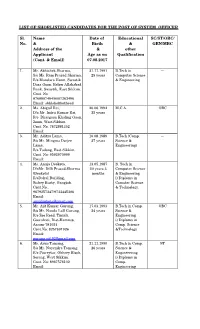
LIST of SHORLISTED CANDIDATES for the POST of SYSTEM OFFICER Sl. No. Name & Address of the Applicant (C
LIST OF SHORLISTED CANDIDATES FOR THE POST OF SYSTEM OFFICER Sl. Name Date of Educational SC/ST/OBC/ No. & Birth & GEN/MBC Address of the & other Applicant Age as on Qualification (Cont. & Email) 07.08.2017 1. Mr. Abhishek Sharma, 21.11.1991 B.Tech in --- S/o Mr. Ram Prasad Sharma, 25 years Computer Science R/o Mandara Heem, Swastik & Engineering Dara Goan, Below Allahabad Bank, Swastik, East Sikkim. Cont. No: 8768907494/8001262496 Email: abhishekhothead 2. Ms. Abigail Rai, 20.06.1992 M.C.A. OBC D/o Mr. Indra Kumar Rai, 25 years R/o Dhargaon Khaling Gaon, Zoom, West Sikkim. Cont. No. 7872881352 Email: 3. Mr. Aditya Lama, 10.08.1989 B.Tech (Comp. --- S/o Mr. Mingma Dorjee 27 years Science & Lama, Engineering) R/o Tadong, East Sikkim. Cont. No: 9593970999 Email: 4. Ms. Anuja Deokota, 13.05.1987 B. Tech in D/oMr. Dilli Prasad Sharma 30 years 3 Computer Science (Deokota) months & Engineering R/oDahal Building, i) Diploma in Sichey Busty, Gangtok. Comuter Science Cont.No.: & Technology. 9679257247/9733445306 Email: [email protected] 5. Mr. Ajit Kumar Gurung, 17.03.1993 B.Tech in Comp. OBC S/o Mr. Nanda Lall Gurung, 24 years Science & R/o Zoo Road, Tiniali, Engineering Guwahati, Dist-Kamrup, i) Diploma in Assam-781024 Comp. Science Cont.No: 8257891926 &Technology Email: [email protected] 6. Mr. Arun Tamang, 21.11.1990 B.Tech in Comp. ST S/o Mr. Nayendra Tamang, 26 years Science & R/o Piureytar, Okhrey Block, Engineeering Soreng, West Sikkim. i) Diploma in Cont. No: 8967576102 Comp. -
GOVERNMENT of SIKKIM HUMAN RESOURCE DEVELOPMENT DEPARTMENT GANGTOK O.O. No: 1748/DIR/HRDD(SE) Dated: 17/12/2014 OFFICE ORDER
GOVERNMENT OF SIKKIM HUMAN RESOURCE DEVELOPMENT DEPARTMENT GANGTOK O.O. No: 1748/DIR/HRDD(SE) Dated: 17/12/2014 OFFICE ORDER With the approval of the Government, the following Primary Teachers are hereby transferred and posted to the respective place of posting mentioned against their names. Sl. Name of the Designation Present Place of Proposed Place of No. Personnel Posting Posting Mr. Amrit Man PRT Lower Tanak PS, Zitlang JHS, East 1 Basnet South Mr. A.P. Sherpa PRT Okhrey SS, West Taryang PS, North 2 Mr. Abhi Narayan PRT Phong SS, South Dzongu Namprik 3 Sharma SS, North Mr. Anil Sharma PRT Tharpu SSS, West Damlakha JHS, 4 East Mr. Arjun Kumar PRT Turung SS, South Wok SS, South 5 Silwal Mr. Augustine PRT Gaucharan JHS, East Passi JHS, South 6 Lepcha Mr. B.B. Chettri PRT Hee-Patal JHS, West Parakha JHS, East 7 Mr. B.K. Pradhan PRT Duga SS, East Subuk PS, South 8 Mr. B.R. Subba PRT Sawaney PS, East Kubinday PS, 9 South Mr. Badri Pradhan PRT Namcheybong SS, Amba Taza SS, 10 East East Mr. Bal Krishna PRT Simkharka PS, South Anden PS, West 11 Basnet Mr. Bansi Das PRT Guptigaon PS, South Malabasey JHS, 12 Gurung West Mr. Bed Nedhi PRT Sokpay JHS, South Lungyam JHS, 13 Tiwari West Mr. Bed Nidhi PRT Tadong PS North, Pakyong JHS, East 14 Bastola Mr. Bhakta Bdr. PRT Pathing JHS, South Basilakha PS, East 15 Gurung Mr. Bhanu Pradhan PRT Sardarey Syapley SS, Khechepari SSS, 16 East West Mr. Bhawani PRT Sakyong SS, West Lower Shyari SS, 17 Shankar Sharma East Mr. -

Damage Pattern During Sikkim, India Earthquake of September 18, 2011
Damage Pattern during Sikkim, India Earthquake of September 18, 2011 M.L. Sharma, B.K. Maheshwari, Y. Singh & A. Sinvhal Indian Institute of Technology Roorkee, Uttarakhand, India ABSTRACT: There was wide spread ground failure and structural damage during the recent Sikkim Earthquake (Magnitude ML = 6.9) of September 18, 2011. Soon after the earthquake, authors visited different parts of Sikkim located in North-East Part of Himalaya in India and carried out the damage survey during September 25-29, 2011. The extensive survey was carried out in the Gangtok City, Capital of the Sikkim state. The team visited all 4 districts of Sikkim i.e. East Sikkim, North Sikkim, South Sikkim and West Sikkim. The main objective of the survey was to observe the effects of 18th September earthquake and aftershocks on build environment in terms of seismological, geotechnical and structural damages. The paper presents the damage pattern correlating it with level of shaking and epicentral distances at different locations. It was found that many buildings damaged due to poor design and workmanship though level of shaking was not very high. Keywords: Sikkim Earthquake, Damages, Intensity of Shaking 1. INTRODUCTION Performance of structures and ground during earthquakes need to be examined for understanding the behaviour of these structures under seismic loads. Past earthquakes have caused widespread damage in the world (Day 2002). Recent Indian earthquakes include Killari (1993), Jabalpur (1997), Chamoli (1999), Bhuj (2001), Sumatra (2004), Kashmir (2005) and Sikkim (2006). For further details, refer to Earthquake reports (DEQ, IIT Roorkee) India being a densely populated country, effects of these disasters are significant in terms of casualties and economic losses. -

Annual Saree Sale Chakung Moves to Gangtok, Wants Goley Back
01 April, 2004; NOW! 1 Bharat Sanchar Thursday, 01 April, 2004 Vol. 3 No. 05 Gangtok Rs. 3 Air-Conditioned Nigam Ltd. a Govt. of India enterprise Grocery Shop Office of the General Manager Telecom for Provisional Goods, Dry Gangtok : Sikkim Fruits & All Hotel NOTICE Requirements (for kitchen) WHOLE-SALES All BSNL subscribers are hereby informed that all tel- RETAIL-SALES ephone numbers in Gangtok at the most reasonable prices beginning 222, 223, 224 and 225 are being changed in a phased manner to now be- gin 20, ie is the second Rajdeep Spectrum Color Lab Building, Near Amar/ number of these phones will Chaman Garage, Sevoke Road, Siliguri henceforth be “0.” ph: 2640799, 2640599 KALIMPONG Bhandari’s REMEMBERS Chakung moves to Gangtok, bazaar THE yatra ROERICHS SARIKAH ATREYA TURN TO pg 5 wants Goley back GANGTOK, 31 March: “Yo pali, FOR DETAILS Congress lai jitauno parchha hai,” a female voice speaks from behind a circle of party faithfuls and curious onlookers even as the former Chief TAMANGS Minister greets a totally bemused and perplexed lady sitting behind a WANT sewing machine inside a tailoring shop at the MG Marg. An assistant hands over a khada to Nar Bahadur MORE Bhandari, who puts it around the TURN TO pg 4 lady’s neck and with folded hands FOR DETAILS seeks support for the Congress. In the next shop, the exercise is repeated. The SPCC [I] president, flanked by a group of party mem- CHEWANG bers, with a party Standard leading DADUL LASHES ahead, seeks every shop along the commercial hub of the capital, thus OUT AGAINST marking the official start to the Con- gress’ canvassing from here today. -

Chunu Maya Giri-Geography.Pdf
WATER RESOURCE MANAGEMENT IN SOUTH SIKKIM: COMMUNITY PARTICIPATION AND INSTITUTIONAL PRACTICES A Thesis Submitted To Sikkim University In Partial Fulfilment of the Requirement for the Degree of Doctor of Philosophy By Chhunu Maya Giri Department of Geography School of Human Sciences Sikkim University 6th Mile Tadong, Gangtok- 737102 July, 2018 AKNOWLEDGEMENT “Thank you God for giving me the strength to keep going”. I am grateful to you for all your many untold blessing upon me without which I could not have finished my Thesis. Firstly, I would like to express my deep and humble gratitude to my supervisor Dr. Sohel Firdos, Associate Professor, Department of Geography for his consistence guidance, comprehensive evaluation, enthusiastic encouragement and useful critique throughout my research work. Without whom it was not possible to complete my Thesis. Besides my supervisor, I am heartily grateful to the other teachers of the department for their immense support and valuable suggestions during the course. Similarly, my sincere thank also goes to Mr. Tulshi Sharma, Lab Assistant for his unconditional support for my lab work. Without whom my lab work could not have completed. I thank all the staff member of Central Library (Sikkim University), Central Library Kolkata, Sikkim State Central Library, Gangtok who had helped me to access material for my research work. My gratitude also goes to officials of the Department of PHE Government of Sikkim Namchi, Department of RMDD Government of Sikkim Namchi and Gangtok, Meteorological Department Gangtok, Department of Agriculture and Horticulture Government of Sikkim Namchi, Department of Forest, Headquarter Gangtok and DESME Government of Sikkim for providing me valuable secondary data and information related to my Thesis.