Source Han Mono Version 1.002 Readme (Released 2019
Total Page:16
File Type:pdf, Size:1020Kb
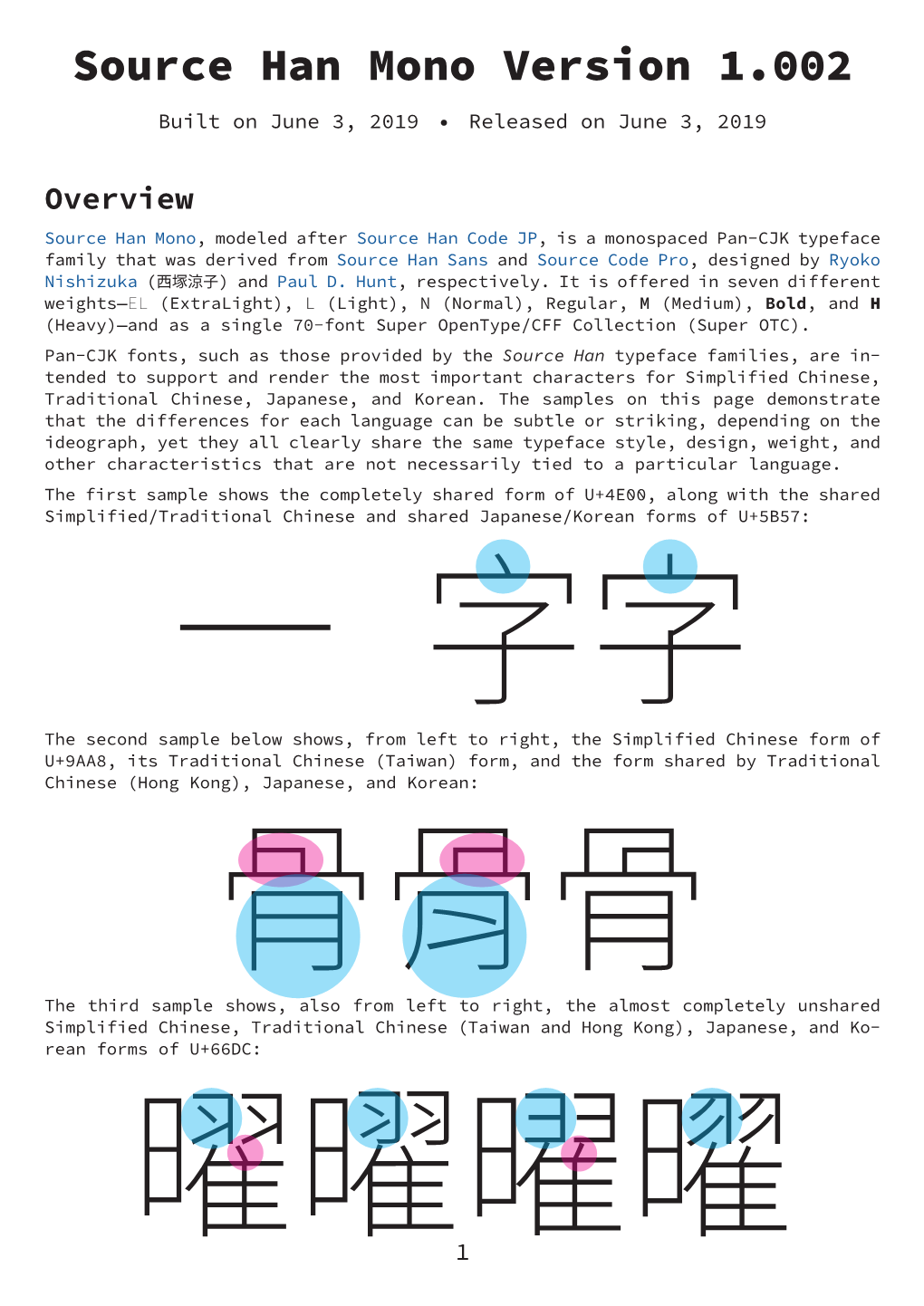
Load more
Recommended publications
-

Cloud Fonts in Microsoft Office
APRIL 2019 Guide to Cloud Fonts in Microsoft® Office 365® Cloud fonts are available to Office 365 subscribers on all platforms and devices. Documents that use cloud fonts will render correctly in Office 2019. Embed cloud fonts for use with older versions of Office. Reference article from Microsoft: Cloud fonts in Office DESIGN TO PRESENT Terberg Design, LLC Index MICROSOFT OFFICE CLOUD FONTS A B C D E Legend: Good choice for theme body fonts F G H I J Okay choice for theme body fonts Includes serif typefaces, K L M N O non-lining figures, and those missing italic and/or bold styles P R S T U Present with most older versions of Office, embedding not required V W Symbol fonts Language-specific fonts MICROSOFT OFFICE CLOUD FONTS Abadi NEW ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Abadi Extra Light ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Note: No italic or bold styles provided. Agency FB MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Agency FB Bold ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Note: No italic style provided Algerian MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ 01234567890 Note: Uppercase only. No other styles provided. Arial MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Italic ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Bold ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Bold Italic ABCDEFGHIJKLMNOPQRSTUVWXYZ -

IJRESS19-August2020
International Journal of Research in Economics and Social Sciences(IJRESS) Available online at: http://euroasiapub.org Vol. 10 Issue 8, August- 2020 ISSN(o): 2249-7382 | Impact Factor: 7.077 | (An open access scholarly, peer-reviewed, interdisciplinary, monthly, and fully refereed journal.) Importance of the number 0 and names for the number 0 in English Umarova Go’zalxon Teacher, Kokand State Pedagogical Institute, Uzbekistan Abdullayeva Marifatxon Teacher, Faculty of Preschool and Primary Education Annotatsiya: Maqolada 0 raqimining etimologiyasi, osiyodan yevropaga kirib kelishi, matematika va matematikadan boshqa fanlarga, yil jadvalida nol raqamining ahamiyati haqida fikr yuritiladi. Kalit so’zlar: ṣifr, matematik termin, kalkulyator, rim, arab raqamlari, elementar algebra Annotation: The article discusses the etymology of the number 0, its entry from Asia to Europe, the importance of the number zero in the table of the year, from mathematics and non-mathematics to other disciplines. Keywords: ṣifr, mathematical term, calculator, Roman, Arabic numerals, elementary algebra Аннотация: В статье обсуждается этимология числа 0, его проникновение из Азии в Европу, важность числа ноль в таблице года, от математики и нематематики до других дисциплин. Ключевые слова: ifr, математический термин, калькулятор, римские, арабские цифры, элементарная алгебра. The word zero came into the English language via French zéro from Italian zero, Italian contraction of Venetian zevero form of Italian zefiro via ṣafira or ṣifr.In pre-Islamic time the word ṣifr had the meaning "empty". Sifr evolved to mean zero when it was used to translate śūnya Sanskrit from India. The first known English use of zero was in 1598.[1]Depending on the context, there may be different words used for the number zero. -

The Not So Short Introduction to Latex2ε
The Not So Short Introduction to LATEX 2ε Or LATEX 2ε in 139 minutes by Tobias Oetiker Hubert Partl, Irene Hyna and Elisabeth Schlegl Version 4.20, May 31, 2006 ii Copyright ©1995-2005 Tobias Oetiker and Contributers. All rights reserved. This document is free; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version. This document is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this document; if not, write to the Free Software Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139, USA. Thank you! Much of the material used in this introduction comes from an Austrian introduction to LATEX 2.09 written in German by: Hubert Partl <[email protected]> Zentraler Informatikdienst der Universität für Bodenkultur Wien Irene Hyna <[email protected]> Bundesministerium für Wissenschaft und Forschung Wien Elisabeth Schlegl <noemail> in Graz If you are interested in the German document, you can find a version updated for LATEX 2ε by Jörg Knappen at CTAN:/tex-archive/info/lshort/german iv Thank you! The following individuals helped with corrections, suggestions and material to improve this paper. They put in a big effort to help me get this document into its present shape. -

Legacy Character Sets & Encodings
Legacy & Not-So-Legacy Character Sets & Encodings Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/cjkv/unicode/iuc15-tb1-slides.pdf Tutorial Overview dc • What is a character set? What is an encoding? • How are character sets and encodings different? • Legacy character sets. • Non-legacy character sets. • Legacy encodings. • How does Unicode fit it? • Code conversion issues. • Disclaimer: The focus of this tutorial is primarily on Asian (CJKV) issues, which tend to be complex from a character set and encoding standpoint. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations dc • GB (China) — Stands for “Guo Biao” (国标 guóbiâo ). — Short for “Guojia Biaozhun” (国家标准 guójiâ biâozhün). — Means “National Standard.” • GB/T (China) — “T” stands for “Tui” (推 tuî ). — Short for “Tuijian” (推荐 tuîjiàn ). — “T” means “Recommended.” • CNS (Taiwan) — 中國國家標準 ( zhôngguó guójiâ biâozhün) in Chinese. — Abbreviation for “Chinese National Standard.” 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • GCCS (Hong Kong) — Abbreviation for “Government Chinese Character Set.” • JIS (Japan) — 日本工業規格 ( nihon kôgyô kikaku) in Japanese. — Abbreviation for “Japanese Industrial Standard.” — 〄 • KS (Korea) — 한국 공업 규격 (韓國工業規格 hangug gongeob gyugyeog) in Korean. — Abbreviation for “Korean Standard.” — ㉿ — Designation change from “C” to “X” on August 20, 1997. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • TCVN (Vietnam) — Tiu Chun Vit Nam in Vietnamese. — Means “Vietnamese Standard.” • CJKV — Chinese, Japanese, Korean, and Vietnamese. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated What Is A Character Set? dc • A collection of characters that are intended to be used together to create meaningful text. -

Implementing Cross-Locale CJKV Code Conversion
Implementing Cross-Locale CJKV Code Conversion Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/ujip/unicode/iuc13-c2-paper.pdf ftp://ftp.oreilly.com/pub/examples/nutshell/ujip/unicode/iuc13-c2-slides.pdf Code Conversion Basics dc • Algorithmic code conversion — Within a single locale: Shift-JIS, EUC-JP, and ISO-2022-JP — A purely mathematical process • Table-driven code conversion — Required across locales: Chinese ↔ Japanese — Required when dealing with Unicode — Mapping tables are required — Can sometimes be faster than algorithmic code conversion— depends on the implementation September 10, 1998 Copyright © 1998 Adobe Systems Incorporated Code Conversion Basics (Cont’d) dc • CJKV character set differences — Different number of characters — Different ordering of characters — Different characters September 10, 1998 Copyright © 1998 Adobe Systems Incorporated Character Sets Versus Encodings dc • Common CJKV character set standards — China: GB 1988-89, GB 2312-80; GB 1988-89, GBK — Taiwan: ASCII, Big Five; CNS 5205-1989, CNS 11643-1992 — Hong Kong: ASCII, Big Five with Hong Kong extension — Japan: JIS X 0201-1997, JIS X 0208:1997, JIS X 0212-1990 — South Korea: KS X 1003:1993, KS X 1001:1992, KS X 1002:1991 — North Korea: ASCII (?), KPS 9566-97 — Vietnam: TCVN 5712:1993, TCVN 5773:1993, TCVN 6056:1995 • Common CJKV encodings — Locale-independent: EUC-*, ISO-2022-* — Locale-specific: GBK, Big Five, Big Five Plus, Shift-JIS, Johab, Unified Hangul Code — Other: UCS-2, UCS-4, UTF-7, UTF-8, -

Typotheque Elementar
Typotheque type specimen & OpenType feature specification. Please read before using the fonts. OpenType font family supporting Latin based European Elementar Std languages, with extensive typographic features. AB — Western European (1252 Latin 1) — Central European (1250 Latin 2) — Baltic (1257) — Turkish (1254) Designed by Gustavo Ferreira, 2002-2011 OpenType features in Elementar hiztvsgfq What is OpenType? OpenType is a cross-platform font format developed by Adobe and Microsoft. It has a potential to provide advanced typographic features such as multilingual character sets, ligatures, small capitals, various numeral styles, and contextual substitutions. OpenType, as the new industry standard, supports Unicode, which enables the fonts to contain a large number of characters. While PostScript fonts are a technically limited to a maximum of only 256 characters, OpenType fonts can have more than 65,000 glyphs. This means that a user does not need to have separate fonts for Western, Central European, Baltic, Cyrillic or Greek languages, but could have one single file which supports all these encodings. OpenType fonts work in all applications, however only some applications take advantage of the advanced OpenType features. Other applications will only use the first 256 characters. For more about OpenType information go to www.typotheque. com/opentype © 2011, Typotheque.com. For information purposes only. complete character set © 2011, Typotheque.com. For information purposes only. © 2011, Typotheque.com. For information purposes only. © 2011, Typotheque.com. For information purposes only. About the Font Elementar is a parametric font system designed to bring more typographic flexibility to digital screens. Elementar embraces and explores the unique properties of digital media: the pixel, the coarse resolution grid, and the dimension of time. -

As Seen in the Translation Industry
Chinese Language & Culture As seen in the translation industry Introduction Prior to one of the most important celebrations in Asia - the Lunar New Year, we decided to share our next piece of extraordinary information with you. We have chosen a country quite famous for itself with rich traditions, interesting history and at the same time very different from the modern western world. In our small e-book, we’ve combined something famous, something small, and a bit of professional advice. We are glad to introduce to you our Chinese Language & Culture week. Welcome to our world! Gergana Toleva (Global Marketing Manager) Paper cutting The art of paper cutting is one of the most intricate arts with paper we’ve ever seen. It is oftentimes called chuāng huā ( ), window flowers or window paper- cuts as it was窗花 used to decorate windows and doors, so the light can shine through the cutout and create wondrous effects. They are usually made of red paper and symbolize luck and happiness. About Chinese Fonts When it comes to Chinese language, we don’t need to quote Traditional Chinese was used prior to 1954. Traditional numbers and statistics to convince someone that it’s one Chinese is still used widely in Chinatowns outside of China, of the most widely used languages in the world. Everyone as well as in Hong-Kong, Taiwan and Macau, where it’s the knows that. It’s a beautiful and fascinating language, and it official written language. In Mainland China, it’s used only in looks so different than most western languages that we’re extremely formal cases. -

Package 'Showtextdb'
Package ‘showtextdb’ June 4, 2020 Type Package Title Font Files for the 'showtext' Package Version 3.0 Date 2020-05-31 Author Yixuan Qiu and authors/contributors of the included fonts. See file AUTHORS for details. Maintainer Yixuan Qiu <[email protected]> Description Providing font files that can be used by the 'showtext' package. Imports sysfonts (>= 0.7), utils Suggests curl License Apache License (>= 2.0) Copyright see file COPYRIGHTS RoxygenNote 7.1.0 NeedsCompilation no Repository CRAN Date/Publication 2020-06-04 08:10:02 UTC R topics documented: font_install . .2 google_fonts . .3 load_showtext_fonts . .4 source_han . .4 Index 6 1 2 font_install font_install Install Fonts to the ’showtextdb’ Package Description font_install() saves the specified font to the ‘fonts’ directory of the showtextdb package, so that it can be used by the showtext package. This function requires the curl package. font_installed() lists fonts that have been installed to showtextdb. NOTE: Since the fonts are installed locally to the package directory, they will be removed every time the showtextdb package is upgraded or re-installed. Usage font_install(font_desc, quiet = FALSE, ...) font_installed() Arguments font_desc A list that provides necessary information of the font for installation. See the Details section. quiet Whether to show the progress of downloading and installation. ... Other parameters passed to curl::curl_download(). Details font_desc is a list that should contain at least the following components: showtext_name The family name of the font that will be used in showtext. font_ext Extension name of the font files, e.g., ttf for TrueType, and otf for OpenType. regular_url URL of the font file for "regular" font face. -

Amazon Fulfillment Web Service Developer Guide Version 1.1 Amazon Fulfillment Web Service Developer Guide
Amazon Fulfillment Web Service Developer Guide Version 1.1 Amazon Fulfillment Web Service Developer Guide Amazon Fulfillment Web Service: Developer Guide Copyright © 2010 Amazon Web Services LLC or its affiliates. All rights reserved. Amazon Fulfillment Web Service Developer Guide Table of Contents Welcome ............................................................................................................................................................. 1 What©s New ........................................................................................................................................................ 4 Introduction to Amazon FWS ............................................................................................................................. 6 Programming Guide ........................................................................................................................................... 9 About Requests and Responses ............................................................................................................ 9 SOAP Requests ............................................................................................................................ 9 Query Requests .......................................................................................................................... 11 Request Authentication ............................................................................................................... 12 What Is Authentication? .................................................................................................... -

Proposal to Represent the Slashed Zero Variant of Empty
L2/15-268 Title: Proposal to Represent the Slashed Zero Variant of Empty Set Source: Barbara Beeton (American Mathematical Society), Asmus Freytag (ASMUS, Inc.), Laurențiu Iancu and Murray Sargent III (Microsoft Corporation) Status: Individual contribution Action: For consideration by the Unicode Technical Committee Date: 2015-10-30 Abstract As of Unicode Version 8.0, the symbol for empty set is encoded as the character U+2205 EMPTY SET, with no standardized variation sequences. In scientific publications, the symbol is typeset in one of three var- iant forms, chosen by notational style: a slashed circle, ∅, a slashed wide oval in the shape a letter, ∅, or a slashed narrow oval in the shape of a digit zero, . The slashed circle and the slashed zero forms are the most widely used, and correspond to the LaTeX commands \varnothing and \emptyset, respectively. Having one Unicode representation to map to, fonts that provide glyphs for more than one form of the symbol typically implement a stylistic variant or a mapping to a PUA code point. However, the wide- spread use of the slashed zero variant and its mapping to the main LaTeX command for the symbol, \emptyset, make it a candidate for a dedicated means to distinctly represent it in Unicode. This document evaluates three approaches for representing in Unicode the slashed zero variant of the empty set symbol and proposes a solution based on a variation sequence. Additional related characters resulting from the investigation and needed to complete the solution are also proposed for encoding. 1. The empty set symbol 1.1. Historical references The introduction of the modern symbol for the empty set is attributed to André Weil of the Nicholas Bourbaki group. -
FT8 Operating Guide V2
FT8 Operating Guide Weak signal HF DXing for technophiles by Gary Hinson ZL2iFB Version 2.37 Note: this document is occasionally updated. The definitive latest English version is maintained at https://www.g4ifb.com/FT8_Hinson_tips_for_HF_DXers.pdf Please use and share that URL or the shortcut bit.ly/FT8OP to stay current. Any archived copies, translations and extracts lurking elsewhere on the Web are not under my control and are probably out of date … but it’s possible they are even better than this version! FT8 Operating Guide FT8 Operating Guide By Gary Hinson ZL2iFB 1 Introduction and purpose of this document ............................................................................... 2 2 START HERE ............................................................................................................................... 3 3 Important: accurate timing ........................................................................................................ 5 4 Important: transmit levels ......................................................................................................... 8 5 Important: receive levels ......................................................................................................... 11 6 Other software settings ........................................................................................................... 14 7 How to respond to a CQ, or call a specific station ..................................................................... 17 8 How to call CQ ........................................................................................................................ -

Libertine's Xetex-Documentation
Manual for L L with XƎTEX Advantages of XeTex over classic LaTex, examples of configuration Deutse Version ebenfalls erhältli. P H P Libertine Open Fonts Projekt http://linuxlibertine.sf.net Berlin, den 21. MÄarz 2009 Inhaltsverzeichnis 1 Advantages of XeTex 3 2 Commands 3 3 Choosing OpenType-features 4 3.1 Leers: ..................................... 4 3.2 Numbers/Figures: ............................... 4 3.3 Ligatures: .................................... 4 4 Links 4 5 Appendix 5 2 1 Advantages of XeTex ² Full Unicode-support. You can enter all Unicode-Glyphs directly into the source code. ² Simple usability of TrueType- and OTF-Fonts ² Full OpenType-support: { automatic substitution of standard activated OpenType-features, i.e. ligatures su as ff, fi, , , fl,ffi, ffl,, , … { shiing from Stylistic Sets, i.e. old style figures, proportional figures, ÄÖÜ as trema-leers, substitution of german ß with ss { true GPOS-kerning 2 Commands e XeTex-interpreter is being invocated via xelatex instead of latex or pdflatex, example: xelatex Document.tex e output is a PDF-file, ergo analog to our example as Dokument.pdf Because the interpreter needs to know wi fonts to use and because XeTex needs some special paages, the document heading looks a lile bit different from usual. Following commands should be entered into the heading: \usepackage{xunicode} \usepackage{fontspec} \usepackage{xltxtra} In contrast, the definition of the input encoding (inputenc) is obsolete, because XeTex consi- ders UTF-8. Some examples found in the internet begin with following META-information: %!TEX TS-program = xetex %!TEX encoding = UTF-8 Unicode though this doesn’t seem to be obligatory. ere are different possibilities to tell XeTex, whi fonts to use locally or globally.