Regularizing Long Short Term Memory with 3D Human-Skeleton Sequences for Action Recognition
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
Numbers Game Dame
This Day In Sports 1973 — UCLA, led by Bill Walton, sets an NCAA record for consecutive victories with its 61st win, an 82-63 victory over Notre Numbers Game Dame. UCLA breaks the record of 60 set by San Francisco in 1956. C4 Antelope Valley Press, Sunday, January 27, 2019 FIGURE skating | U.S. CHAMPIONSHIPS Morning rush Cain, LeDuc win U.S. Valley Press news services from Breeders’ Cup Classic champion Accel- American snaps Germany’s 24-race erate for an emphatic victory in the final Rose settles for 3-shot lead at Torrey bobsled winning streak race before retirement for both horses. ST. MORITZ, Switzerland — Elana title, Chen in first Pines City of Light and Accelerate were neck- SAN DIEGO — Justin Rose had three Meyers Taylor of the United States won a and-neck on the lead as the 12-horse field Associated Press straight national title. big mistakes and still kept a three-shot lead World Cup women’s bobsled race Saturday, turned for home on a rainsoaked track and Ashley Cain and Tim- Saturday with a 3-under 69 at the Farmers ending Germany’s 24-race winning streak DETROIT — Nathan under a very dark, stormy sky. But Accel- Chen took the lead at othy LeDuc won the pairs Insurance Open. in World Cup and Olympic bobsled races Rose had six birdies and an eagle on an- erate didn’t fire, and City of Light under dating back to last season. the U.S. Figure Skating competition, and Madison jockey Javier Castellano simply took off. Championships with a other pristine day along the Pacific, and he Hubbell and Zach Dono- Schmidhofer wins super-G race, dazzling short program stretched his lead to six shots at one point Venezuela defends role as series Saturday and is in great hue won their second along the back nine of the South course. -

Olympic Winter Games Brain Teaser I
OLYMPIC WINTER GAMES BRAIN TEASER I Jason, Jennifer, Will, Marianne, Eddie, Graciela, and Yasmin are part of the United States Olympic team. They are each from a different state. (Hawaii, Alaska, Oregon, New Hampshire, Texas, New Mexico, and Utah) and they are also each competing in a different event (freestyle skiing, speedskating, figure skating, snowboarding, curling, skeleton, and ice hockey). Figure out the state each person is from and the event in which he or she is competing. The person competing in the snowboarding event is from New The person competing in the freestyle skiing event is from the England. This is his second time at the Games. Southwest. This is her third time at the Games. The person competing in the figure skating event is from the Yasmin and Graciela have never been to Utah before. Southwest. This is her second time at the Games. The person from Texas is not competing in the skeleton event. The person from Texas and her friend invited the person from Alaska to dinner. The person from Alaska thought it was a great Graciela and Eddie are not from New Mexico. idea, and she gladly accepted. Eddie has never been to Texas. Yasmin had lunch with someone she met. The person she met is competing in the figure skating event. Marianne did not compete in the curling or figure skating events. The person competing in the skeleton event is from a Rocky Mountain state. This is her third time at the Games. The person from New Mexico is not competing in the skeleton event. -

Mountain Bike Trail Development Concept Plan
Mountain Bike Trail Development Concept Plan Prepared by Rocky Trail Destination A division of Rocky Trail Entertainment Pty Ltd. ABN: 50 129 217 670 Address: 20 Kensington Place Mardi NSW 2259 Contact: [email protected] Ph 0403 090 952 In consultation with For: Lithgow City Council 2 Page Table of Contents 1 Project Brief ............................................................................................................................................. 6 1.1 Project Management ....................................................................................................................... 7 About Rocky Trail Destination .......................................................................................................... 7 Who we are ......................................................................................................................................... 7 What we do .......................................................................................................................................... 7 Key personnel and assets ................................................................................................................. 8 1.2 Project consultant .......................................................................................................................... 11 Project milestones 2020 .................................................................................................................. 11 2 Lithgow as a Mountain Bike Destination ........................................................................................... -

The Long-Term Athlete Development Plan for Snowboarding in Canada “It Takes 10 Years of Extensive Practice to Excel in Anything.” Introduction H
The Long-Term Athlete Development Plan for in Canada Table of Contents Foreword ......................................................................................... 2 Introduction ...................................................................................... 3 Where are we now? .......................................................................... 4 Where would we like to be? .............................................................. 5 How are we going to get there? ........................................................ 5 STEP 1: The 11 key factors influencing LTAD ................................. 6 STEP 2: The 8 stage Athlete Development Model ............................ 6 STEP 3: Putting it all in operation .................................................... 7 The 11 key factors influencing LTAD 1. The Ten-Year Rule .................................................................. 8 2. The FUNdamentals ................................................................. 9 3. Early and late specialization ...................................................10 4. Developmental Age ...............................................................11 5. Windows of opportunity ........................................................12 6. Physical, technical, tactical and psychological development ....................................................13 7. Periodization .........................................................................14 8. Calendar planning for competition .........................................15 -
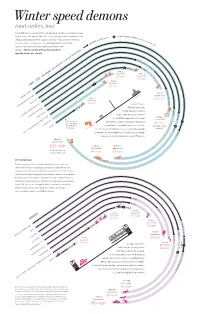
And Curlers, Too
Winter speed demons (and curlers, too) A downhill skier vs. a bobsled? A comically dressed curler vs. a brawny hockey player? Sure, each sport is dierent — some more graceful, others more death SOCHI AVERAGE ic) SPEE ital D (ev D ( ents defying, and all performed in varying conditions — but all share something PEE thr S oug GE h W A ed in common: the need for speed. e Washington Post analyzed the ER ne V sd A ay speeds of all major disciplines represented in the Sochi ) Olympics. is is how far and how fast an athlete typically travels per second: S now bo ar d c ro ss , 35 31 37 m mph m p ph h 37 feet per second 54 feet TOP SPEED: TOTAL DISTANCE TRAVELED PER SECOND 25 mph per second 37 mph 29 feet Cr. country per second MEN 20 mph S k 15-16mph i j u 73 feet m p i per second n g Capitol , DOWNHILL SKIER 16 feet 50 mph 5 per second 0 m p SKELETON 11 mph Johan Clarey, a h FOUR-MAN BOBSLED/LUGE French alpine skier, 6.5 mph h hit 101 mph while compet- p m 7 ing in a 2013 World Cup downhill 5 h p SKI JUMPER/SNOWBOARDFREESTYLE CROSSSKI CROSS 88 feet m SPEED SKATER event. At that speed, he could rocket 8 per second 5 Once released, from the U.S. Capitol to the Lincoln Memorial the curling stone 60 mph averages about — a distance of about two miles — in 1 minute FIGURE SKATER Ski jumper’s speed CURLER 3 to 4 mph. -

Canadian Sport Institute & BC Bobsleigh & Skeleton Association
Canadian Sport Institute & BC Bobsleigh & Skeleton Association (BCBSA) Athlete and Coach Nomination Criteria Criteria Approved September 6, 2016: CSI Pacific Representative Signature BCBSA Representative Signature CANADIAN SPORT INSTITUTE / PACIFICSPORT / BCBSA ATHLETE AND COACH NOMINATION PURPOSE The Canadian Sport Institute, through a partnership with the Province of BC and ViaSport, the network of PacificSport Centres, and BCBSA collaborates to deliver programs and services to place BC Athletes1 on National Teams, and ensure athletes and coaches have every advantage to win medals for Canada. The partners work jointly to encourage sport excellence and increase podium performances in communities throughout British Columbia. Canadian Sport Institute / PacificSport athlete and coach support for the Canadian Development and Provincial Development nomination focuses on athletes and teams 5-12 years from the Podium, identified by the sport specific Podium Pathway (see Figure 1 below) and Gold Medal Profile. These athletes and teams represent both the next generation (5-8 years from Podium) and future generations (9-12 years from Podium) of Olympic and Paralympic (or World Championship) medalists. Support may be focussed more toward the future generation (9-12 years from Podium) for some targeted Paralympic sports depending on the quality of the next generation (5-8 years from Podium) of athletes and teams. Figure 1 PSO/NSO/CSI/PacSport Supported 1 In general a BC athlete is defined as an athlete born, developed, and/or trained/centralized (for a minimum of three months) in British Columbia. DETAILS Through the above partnership, and with the above purpose in mind, BCBSA may nominate athletes and their coaches who meet specific criteria for Canadian Sport Institute / PacificSport athlete or coach registration. -

Games Pg21-66.Revised 8/27/01 3:53 PM Page 21 Games Pg21-66.Revised 8/27/01 3:53 PM Page 22 Games Pg21-66.Revised 8/27/01 3:53 PM Page 23
Games pg21-66.revised 8/27/01 3:53 PM Page 21 Games pg21-66.revised 8/27/01 3:53 PM Page 22 Games pg21-66.revised 8/27/01 3:53 PM Page 23 LET THE GAMES BEGIN • HISTORY Fact Sheet Winter Sports History Utah Resources What do mining and skiing have in common? Both were important factors in the growth of Utah. Both are included in the exciting history of Park City. Silver Mining At one time, Park City mines were some of the richest in the United States! Silver mines, discovered in Park City, brought wealth, power, influence and opportunity to a few lucky men. While most miners remained poor and worked in dangerous conditions underground, a few used luck, hard work and knowledge to become extremely rich! One of these miners was Thomas Kearns. Kearns was a teenager when he left home to seek his fortune in the mines. After arriving in Park City, he first worked as a mucker (a poor worker who shoveled ore into the underground ore wagons). He used his knowledge of mining and ore veins to stake a claim in a mine that he thought might be rich in silver. His hunch proved to be correct, and he became a millionaire! The Silver King Mine, in Park City, provided this Irish Catholic miner with great wealth and power. At the beginning of the 1900’s, successful miners like, Thomas Kearns, changed the image of downtown Salt Lake City by building fabulous mansions on South Temple. The Kearns Mansion, an elegant reminder of Park City’s exciting past, was donated to the state and is now Utah’s Governor’s Mansion. -

Physiological Contributions to Successful Downhill Mountain Bike Performance
PHYSIOLOGICAL CONTRIBUTIONS TO SUCCESSFUL DOWNHILL MOUNTAIN BIKE PERFORMANCE EDINBURGH NAPIER UNIVERSITY, MSC BY RESEARCH SUZANNE L. HADDEN A THESIS SUBMITTED IN PARTIAL FULFILMENT OF THE REQUEST OF EDINBURGH NAPIER UNIVERSITY, FOR THE AWARD OF MASTER OF SCIENCE BY RESEARCH. JUNE 2011 ABSTRACT Purpose: To, one, investigate the anatomical and physiological attributes of Downhill mountain bike athletes and, two, to determine the influence of these inherent physiological attributes on Downhill race performance. Methods: The study consisted of two testing components; laboratory- and field-based testing. Laboratory study: An anthropometric profile was determined from seven trained and competitive DH athletes (age 21 ± 5 years). Peak power output and time to peak power were determined by six, 6-second maximal sprints, performed on an SRM stationary ergometer. Cadence was restricted during five sprints (60, 80, 100, 120 and 140 rpm) to determine optimal cadence for achieving peak power. Field study: Twelve trained and competitive DH athletes (age 20 ± 5 years) performed two timed runs of a National Championship DH course. Heart rate was recorded and two GPS units (attached to the bicycle and helmet) recorded speed (kmhr-1), distance (m), time (seconds) and impacts (g). Results: Laboratory study: DH cyclists have predominantly mesomorphic somatotypes (mean somatotype values, 2.1,4.7,3.0) with a mean sum of 8 skinfolds, 68.7 ± 19.8 mm. Sprint testing revealed peak power output (23.36 ± 2.12 Wkg-1) was achieved at restricted cadence of 110 rpm and time to peak power output was 1.5 ± 0.9 seconds. Field study: DH race run time was 178.57 ± 12.10 seconds. -
Numbers Game Had Been Paid $25 for Playing in a Semipro Baseball Game
THIS DAY IN SPORTS 1913 — Jim Thorpe gives up his track medals from the 1912 Olympic games as a result of having been a professional. He NUMBERS GAME had been paid $25 for playing in a semipro baseball game. C4 Antelope Valley Press, Sunday, January 26, 2020 Planner Busch puts team back in contention at Rolex COMING UP IN THE VALLEY By JENNA FRYER was responsible for the crash. Associated Press PREPARING Castroneves appeared to be ANTELOPE VALLEY COLLEGE (Junior College) Reigning NASCAR ■ M Basketball: Wednesday vs. L.A. Valley, 7 p.m. DAYTONA BEACH, Fla. — furious as he sat inside his cock- Champion Kyle ■ W Basketball: Wednesday vs. L.A. Valley, 5 p.m. Kyle Busch drove his Lexus pit awaiting repairs. He finally Busch signs ■ back to the lead lap at the Rolex climbed from the car when Baseball: Feb. 1 vs Imperial Valley (DH), noon autographs ■ Softball: Wednesday vs. Mt. San Antonio, 2:30 p.m. 24 of Daytona — a move that before the Rolex the team realized it needed a ■ M Golf: Today at Pt. Conception Tourn., TBA changed team strategy and got 24 hour auto lengthy repair to the radiator. ■ W Tennis: Tuesday at Rio Hondo, 2 p.m. the reigning NASCAR champi- race at Daytona The Brazilian was animat- ■ Track: Feb. 7 at Battle of the Regions in Bakersfield on pulled from the car to keep International ed as he discussed the incident ■ M Volleyball: Thursday vs. Irvine Valley, 6 p.m. him fresh. Speedway on with teammates Ricky Tay- Saturday in Daytona UNIVERSITY OF ANTELOPE VALLEY (NAIA) Busch was scheduled to lor and Alexander Rossi, who ■ Beach, Fla. -

MMW Runnin' Club!
October 1st Vol. 13 MMW RUNNIN’ CLUB! Back in the Saddle by Various “Runners” We’re back! Hello dedicated members, followers, and How do Runners get through the forest? fans! After a brief summertime hiatus, we are back full They take the phycho path! force for your entertainment and to motivate you to keep those legs moving as we enter the longest season Did you hear about the survivor who ran for of Montana weather. three hours but only moved two feet? He only had two feet! We would like to say that we were too busy running to get this newsletter out this last couple of months, so How did the barber get away from the Zombies? that is what we are going to say. He took a short cut! We were too busy running to get this newsletter to Why do Zombies run in circles? you these last couple of months. Because its hard to run in squares! There were those who did not want to stop running If you are being haunted by 10 Ghosts what time to put together this esteemed publication, but those is it? people aren’t on the Runnin’ Club Newsletter Staff. 10 after 1! The quarom was clearly behind getting this tricky treat out to our adoring readers. So, we are going to What did the Ghoul carbo-load on before the big give you what you have been so sorely missing these race? last couple of months: Spookgetti! That’s right, Halloween themed runnin’ jokes! Why didn’t the skeleton join the MMW Runnin’ Club? Bonus Points if you can find all 5 spiders hiding out! He didn’t have the guts! Race Preview by Mark Stelling October is notorious for mass consumption of November 3rd – Mount Jumbo Elk Ramble pumpkin spice lattes, but all that extra time spent sipping a seasonal brew does not mean we can slack Slots may be full, but there is no harm in getting on on our running. -

2018 Winter Olympic Games Listings
2018 WINTER OLYMPIC GAMES LISTINGS NBC, NBCSN, CNBC, USA Network, Olympic Channel: Home of Team USA, NBCOlympics.com, and the NBC Sports app NBC Primetime and “Primetime Plus” Coverage Live Across All Time Zones NBCSN Will Present Live Primetime Coverage 24-Hours, Seven Platforms, Every Olympic Sport – Subject to Change – • These listings, which are subject to change, offer daily highlights of the XXIII Olympic Winter Games from PyeongChang, South Korea, programming across NBC, NBCSN, CNBC, USA Network, Olympic Channel: Home of Team USA, NBCOlympics.com, and the NBC Sports app. During the PyeongChang Games, please consult NBCOlympics.com for the most complete daily listings. • For the first time ever at a Winter Olympics, NBC will broadcast Olympic primetime competition live across all time zones. Whether daytime, primetime or “Primetime Plus” (formerly the late night show). For NBC, all times listed are ET unless otherwise noted. • On the following days, viewers in the Mountain and Pacific time zones will receive an additional 30 minutes in their respective primetime windows: Feb. 10, Feb. 13-14, Feb. 17, Feb. 19, Feb. 21 and Feb. 23. • On the following days, viewers in the Pacific time zone will receive an additional 30 minutes in their primetime window: Feb. 12, Feb. 15-16, Feb. 18, Feb. 20 and Feb. 22. • The cable channels, NBCSN, CNBC, USA Network and Olympic Channel: Home of Team USA, are live across during the PyeongChang Games. For NBCSN, CNBC, USA Network and Olympic Channel: Home of Team USA all times listed are ET. • During the PyeongChang Games, NBCOlympics.com will have the most up-to- date listings and information. -

Gender Difference in Mountain Biking on Display Mike Lloyd1 Keywords
sites: new series · vol 14 no 2 · 2017 DOI: http://dx.doi.org/10.11157/sites-vol14iss2id370 – article – ‘SKILLS TO PAY THE BILLS’: Gender differenCe in Mountain BikinG on displaY Mike Lloyd1 aBstraCt This paper analyses a short video showing the opening of a skills area in a mountain bike park. After the official ribbon cutting by the mayor, we watch nearly twenty mountain bikers putting in some showy runs. Amongst this, there are only three women riders, and in contrast to a core group of young male riders, they appear to ride very cautiously. Given this contrast, a possible reaction to the video is that it is ‘sexist’, giving the message that women are less competent at mountain biking, bolstering an existing view that ‘mountain biking is for men’. Clearly, a single video needs to be treated with caution, nonetheless, the gender difference is stark. However, by considering the specif- ics of mountain biking skills, and its ‘interactional ecology’ the interpretive point made from the video is that the assumption of gender difference may need ‘undoing’. This is pursued not by conceptual discussion, but by showing what can be made of the video in analysing key visual fragments. Additionally, the details of the video are supplemented by reference to one other key piece of cycling research, and one other ‘natural video record’ of mountain biking practice. The paper contributes to the growing recognition of the value of video data in the ethnographic analysis of mobile interactive practices. Keywords: mountain biking; display; gender; video introduCtion New Zealand is fast becoming something of a mountain biking paradise.